异构数据库的统一访问怎么搞?看完你就知道了!
随着网络技术应用的不断普及,网络的异构分布式信息系统正在迅速发展,Java以其平台无关性、移植性强,安全性高、稳定性好、分布式、面向对象等优点而成为网络应用开发的首选语言。在网络环境下,实现基于异种系统平台的数据库应用,必须提供一个独立于特定数据库管理系统的统一编程界面和一个基于SQL的通用的数据库访问方法。那么,异构数据库的统一访问该怎么弄?
其实这个问题可以分成两个部分来讨论。
问题1:是否有软件可以实现异构数据库的统一访问?例如select http://oracle.XXX from XXX ;where oralce.XXX.id=sqlserver.XXX.id
答:有软件可以实现,但要想实现异构数据库的统一访问,例如select http://oracle.XXX from XXX ;where oralce.XXX.id=sqlserver.XXX.id,首先要先明白这类数据计算运行的底层逻辑是什么。
①假如是同类型的通过异构数据库,直接进行左右关联,那这类数据的计算就是在运行软件/程序的服务器。
②假如只是数据的一个统一访问,然后进行OLAP关联分析,用BI工具就行。
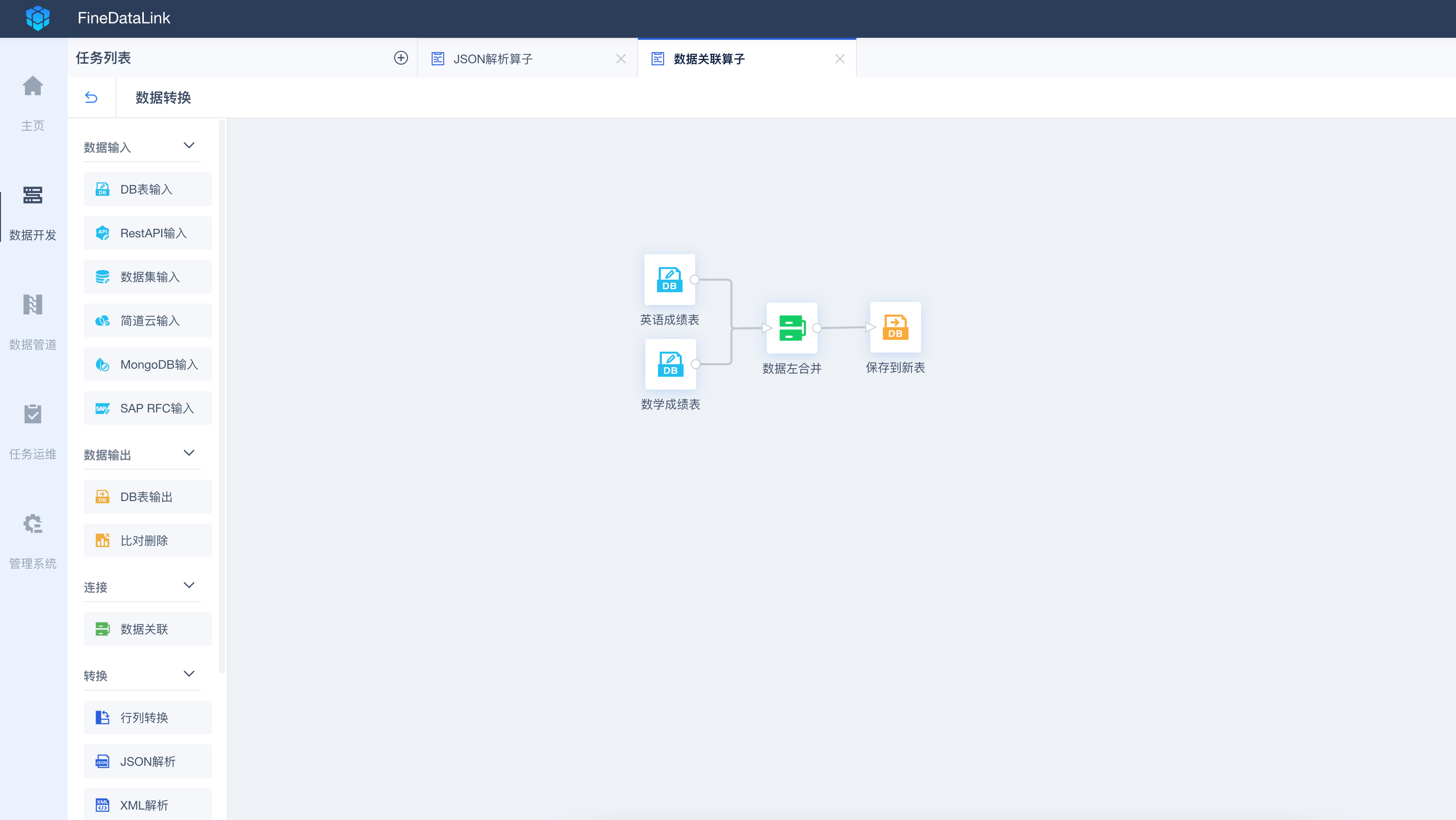
③假如是除了数据的统一访问,还需要进行数据的再次处理。那还是推荐通过专业的工具,将分布在不同网络、不同服务器上的不同种的异构数据库中的数据,集成到一个数据库,再进行处理,这样的话,就是统一将算力放到这个新的目标数据库中,同时也不会影响原有数据库的使用,也就是最常见的数仓搭建的方法。
但其实很多人,看到数仓搭建会比较排斥,甚至不愿意学习数仓搭建的方法,觉得这是大公司级别才会做的事情,其实不然,虽然没有普适的数仓搭建的方法,但是你可以根据你的数据库或者系统数据的体量,进行一定程度裁剪,搭建符合自己数据使用习惯的数仓就行。
现在这类市面上有很多工具,可以做到这点,开源的有kettle,商业的有FineDataLink,通过设置流程,很快就能完成异构数据库的数据迁移集成。(ps:需要说明,这类开源工具,在使用过程中,会容易出现数据库报错或者连接数不足等异常,且insert/update会占用大量的CPU资源,如果对数据要求高,不太推荐使用开源工具)
问题2:做一个分布式数据库是否可以实现这个功能?
答:可以。但最好是在异构数据库很多,数据量很大时,再去选择分布式数据库进行统一的数据存储,这样数据的存储能力和算力都会进一步提升,从而代替异构数据库的数据读取,但在这过程中还是需要将不同业务库的数据同步到这个分布式数据库中。
假如数据量单机数据库就能支撑,其实就没必要采用分布式数据库。
为什么呢?因为一般来说,分布式数据库都是由主节点+N个计算存储节点,具备可扩展、高可用(当部分节点失效时,其他节点能够接替它继续服务)的能力,因此一般购买成本、运维成本都比较高。所以,如果数据量单机数据库就能支撑,采用分布式数据库就比较“浪费”,性价比不如使用上面提到的数据集成工具高。
总而言之,在数字化时代下,大数据治理对企业数据建设的重要性不言而喻,然而实现的困难有时也让人望而却步,因此选择合适的技术和工具会达到事半功倍的效果。帆软FineDataLink——中国领先的低代码/高时效数据集成产品,能过为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。







 立即沟通
立即沟通

