大数据时代,谁能抓住时代发展先机?实时数据采集帮助你!
大数据时代,谁掌握了足够的数据,谁就有可能掌握未来,而其中的数据采集就是将来的流动资产积累。几乎任何规模企业,顺应着大数据时代,每时每刻也都在产生大量的数据,但这些数据如何归集、提炼始终是一个困扰。而大数据技术的意义确实不在于掌握规模庞大的数据信息,而在于对这些数据进行智能处理,从中分析和挖掘出有价值的信息,但前提是如何获取大量有价值的数据。在这种大数据时代,如何抓住机会,占据数据的优势呢?比较好的一个回答和方式就是使用实时数据采集工具,一个好的实时数据采集工具不仅可以实时更新和收集合适的数据,还可以进一步辅助数据仓库的数据分析,提高公司的运转效率。
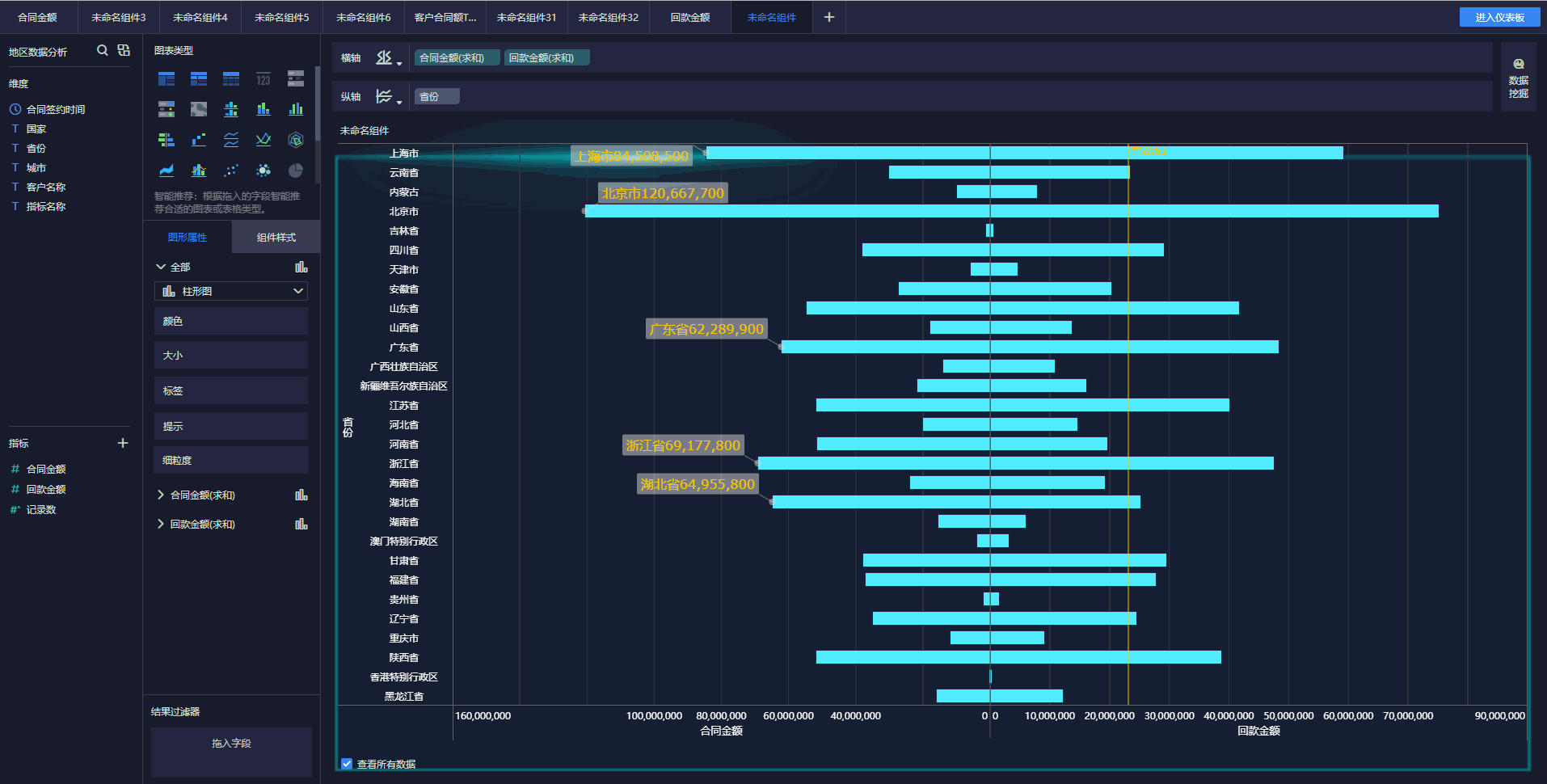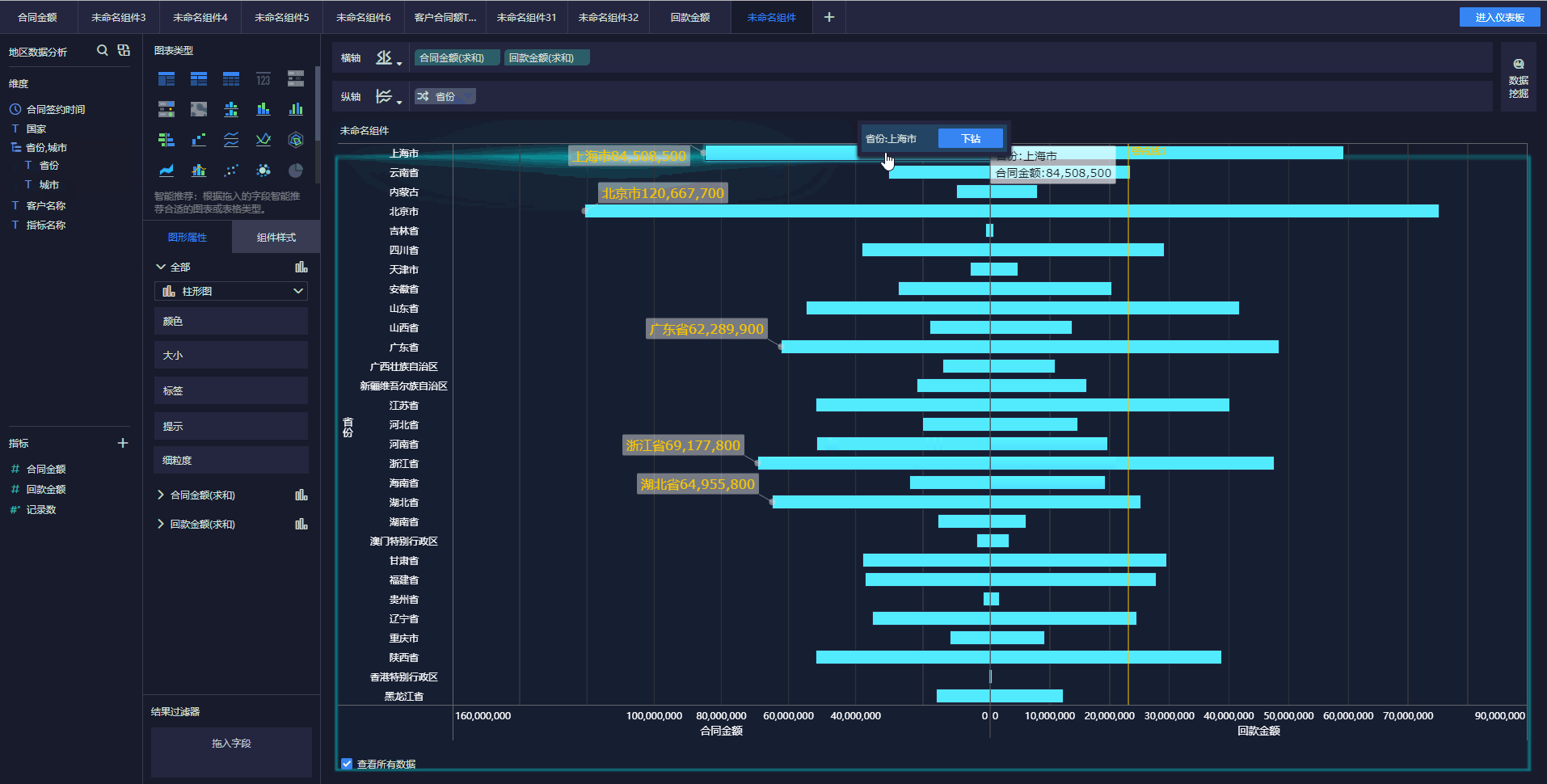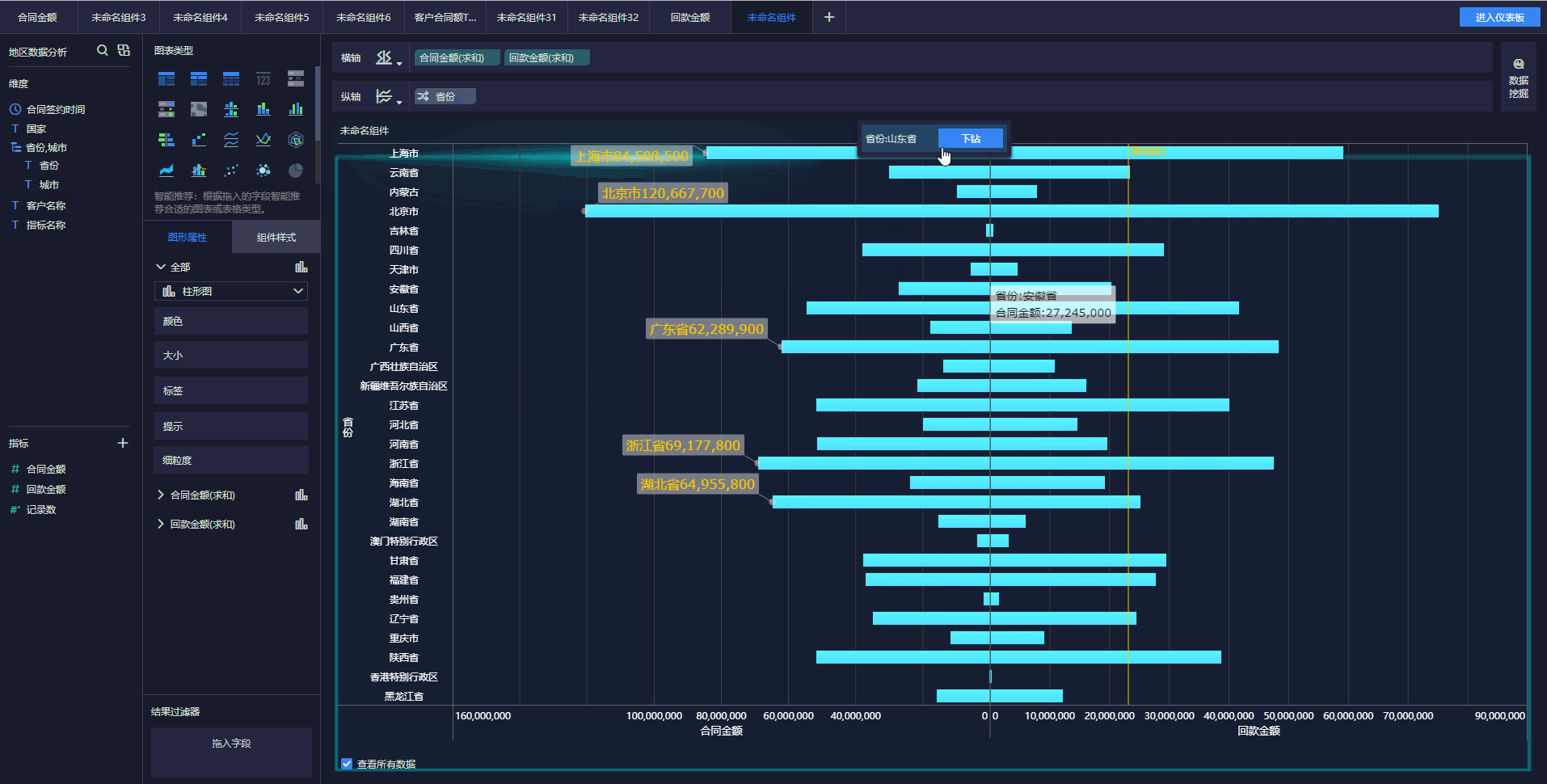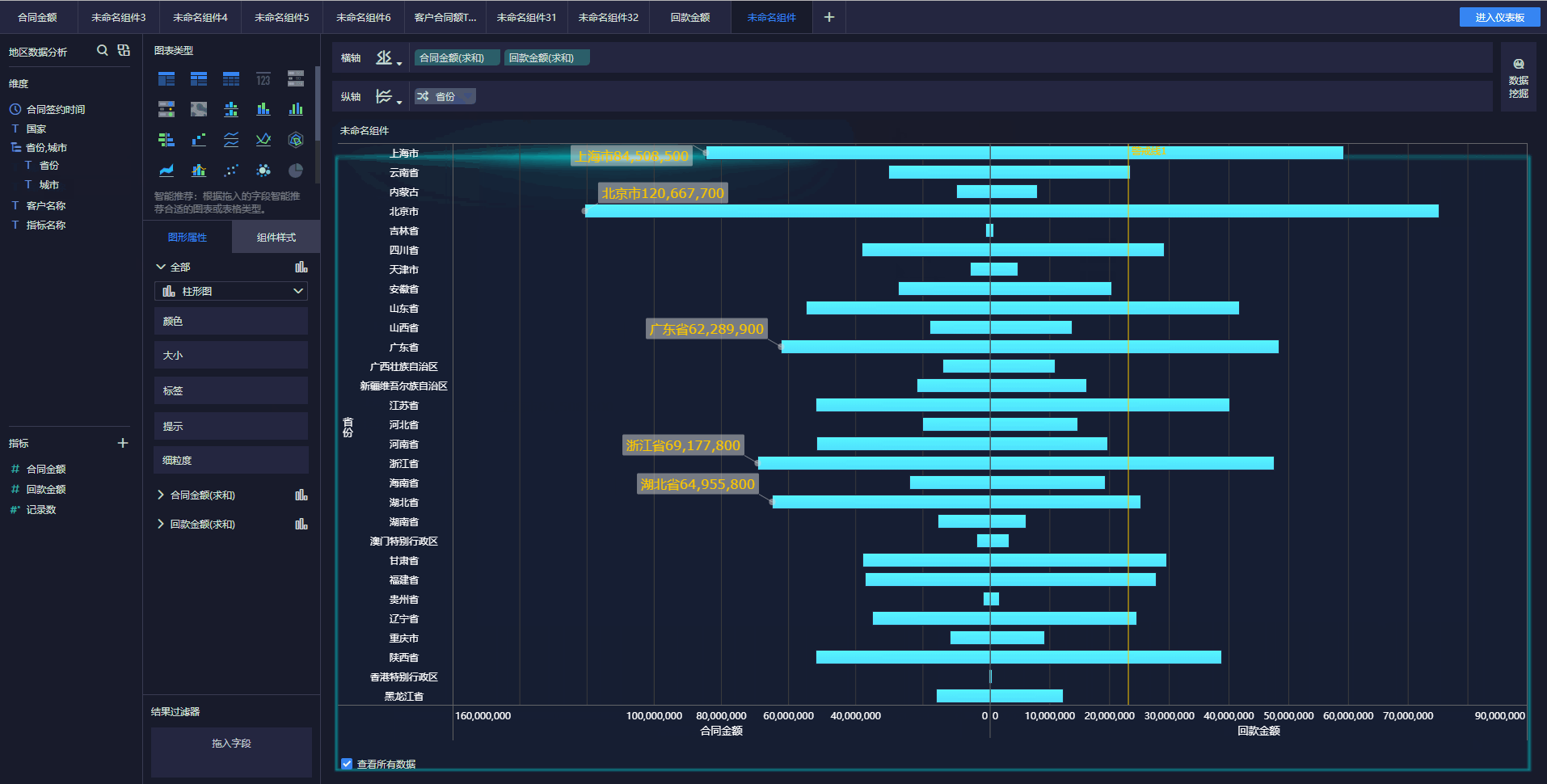
下面简单介绍几种实时数据采集工具。
1、离线搜集工具:ETL
在数据仓库的语境下,ETL基本上便是数据搜集的代表,包括数据的提取(Extract)、转换(Transform)和加载(Load)。在转换的过程中,需求针对具体的事务场景对数据进行治理,例如进行不合法数据监测与过滤、格式转换与数据规范化、数据替换、确保数据完整性等。
2、实时搜集工具:Flume/Kafka
实时搜集首要用在考虑流处理的事务场景,比方,用于记录数据仓库数据源的履行的各种操作活动,比方网络监控的流量办理、金融运用的股票记账和web服务器记录的用户访问行为。在流处理场景,数据搜集会成为Kafka的顾客,就像一个水坝一般将上游源源不断的数据拦截住,然后依据事务场景做对应的处理(例如去重、去噪、中心核算等),之后再写入到对应的数据存储中。
3、互联网搜集工具:Crawler,DPI等
Scribe是Facebook开发的数据(日志)搜集体系。又被称为网页蜘蛛,网络机器人,是一种按照一定的规矩,自动地抓取万维网信息的程序或者脚本,它支持图片、音频、视频等文件或附件的搜集。
除了网络中包含的内容之外,关于网络流量的搜集能够运用DPI或DFI等带宽办理技术进行处理。






 立即沟通
立即沟通

