扫盲系列(9):数据仓库实践之表的分类
在数据仓库中,常见的表分类包括维度表、事实表和拉链表。
维度表
在数据仓库中,维度表是一类与事实表相关联的表格,主要用于对事实表中存储的数据进行统计、分析和报表生成。维度表通常包含一些与业务状态、代码解释和统计属性相关的信息,也称之为码表。
在数据仓库中,维度表用于描述事实表中的各个维度属性信息,例如产品、时间、地点、客户等,通常使用维度对事实表中的数据进行统计、聚合计算。维度表主要包含了维度表的主键、维度属性的描述信息以及一些状态码,例如未支付、已支付、发货中、已发货、已完成等,如下图,这些状态码通常需要与维度属性描述信息一起体现。

维度表示例
维度表的使用可以帮助用户快速准确地钻取、过滤和统计事实表中的数据,从而方便用户深入分析和理解数据背后的意义。在数据仓库的设计中,正确设计和使用维度表是非常重要的一步,需要根据业务需求和数据特点进行合理的分析和设计。
事实表
在数据仓库中,事实表是存储与业务对象相关的数据的主表,如下图。可以回顾文章《扫盲系列(3):数据仓库架构详解》,这里不再赘述。根据数据的生命周期和特点,数据仓库中的事实表可以分为不同类型,主要包括事务事实表、周期快照事实表和累积快照事实表。

事实表示例
1、事务事实表
事务事实表是一类常见的事实表类型,主要用于记录与业务对象相关的事务性数据,也称之为事务型事实表或基本事实表。
随着业务的不断发展,系统会不断产生事务性数据,例如交易流水、操作日志、出库入库记录等,这些数据在创建后就不会再变化,因此事务事实表的每条记录表示一个瞬时的事件。在数据仓库中,这类数据通常包含与业务对象相关的度量、日期、事实类型等字段信息。
为了提高查询效率和性能,事务事实表通常会通过聚集操作进行优化。聚集操作就是通过对事实表中的度量进行聚合,生成一张聚集表来快速查询和提高查询性能。聚集表通常包含常见的聚合函数,例如SUM、AVG等,可以加快数据计算和数据分析。
事务事实表常用于记录实时/近实时产生的事务性数据,通常需要实时地获取到数据并进行数据分析和处理,交易系统和设备监控系统等场景都是很好的应用场景。

事务事实表示例
2、周期快照事实表
周期快照事实表是一类常见的事实表类型,主要用于记录与业务对象相关的周期性变化数据,也称为快照事实表或周期事实表。
周期快照事实表的特点是随着业务周期性的推进而变化,记录某个时间段内的业务数据度量和状态度量的变化。周期性通常以年、月、周、日等为单位进行统计,业务对象可以是各个维度的组合。常用于统计与业务对象相关的周期性数据,例如年度销售额、季度利润等,同时也可以用于分析和预测未来趋势和变化。
周期快照事实表通常使用周期+状态度量的组合方式来记录数据,例如年累计订单数,每天是周期,订单总数是状态度量。在数据仓库中,这类数据通常包含与业务对象相关的度量、日期、周期、状态度量等字段信息。
为了方便快速查询和分析,周期快照事实表通常使用时间戳和状态字段来记录每个度量周期内的状态。同时,为了提高查询效率和性能,周期快照事实表也会通过聚集操作来优化。聚集表包含常见的聚合函数,例如SUM、AVG等,可以加快数据计算和数据分析。

周期快照事实表示例
3、累积快照事实表
累积快照事实表是一类常见的事实表类型,主要用于记录与业务对象相关的完全覆盖一个事实的生命周期、度量统计不确定周期的数据,也称为累计快照事实表或时间周期事实表。
与周期快照事实表不同,累积快照事实表没有确定的周期,而是针对一个业务对象完全覆盖一个事实的生命周期进行记录。例如,订单状态表就是一个典型的累积快照事实表,该表记录了订单的所有状态变化,如下单、出库、发货、交付等,同时该表中的数据不断更新,需要进行随机修改。累积快照事实表通常用于记录与某个业务对象相关的变化和状态历史,例如订单状态表、客户积分历史表等。这些表可以用于分析和预测未来趋势和变化,从而帮助业务决策。
为了记录一个事实的生命周期中的关键时间点,累积快照事实表通常会包含多个时间字段,例如订单状态表中的订单创建时间、订单取消时间、订单完成时间等。
同时,累积快照事实表只有一条记录,针对这条记录不断进行更新。每次更新时,旧的记录会被保留在历史记录中,以便回溯和分析。由于记录的更新和历史版本的保留,累积快照事实表需要更大的存储空间和更长的查询时间。

累积快照事实表示例
在文章《扫盲系列(10):数据仓库实践之累积快照事实表的实现方式》中,详细介绍了累积快照事实表的三种实现方式。这里不做展开。
拉链表
接下来介绍一种特殊的表——数仓拉链表。拉链表是一种常见的数据库设计思想,用于记录每条信息的生命周期,保留表数据的历史状态变化,可以保留每个版本的数据,从而实现数据的追溯和分析。
数仓拉链表通常采用顺序追加的方式,将数据的随机修改方式变为顺序追加。每当表中的一条数据发生变化时,数仓拉链表会新建一条记录,同时保留旧记录的状态,包括开始时间、结束时间等属性信息。新纪录和旧记录通过引用或记录ID进行关联,形成一个链表的结构,形象称之为拉链表。

拉链表示例
数仓拉链表的设计需要考虑许多因素,例如历史记录的数量、查询效率和数据量等,可以通过多种技术手段来优化。例如,可以使用分区表、分表、索引等技术来提高查询效率和性能,同时,数仓拉链表也需要进行定期的维护和清理,以避免数据的过多重复和冗余。例如,可以使用帆软软件推出的数据集成工具FineDataLink来创建数仓拉链表。FineDataLink可以从多种类型的数据源中获取历史记录并创建数仓拉链表,同时提供了ETL功能,帮助用户对数据进行清洗、转换和整合,并将处理后的结果存储到数仓拉链表中。FineDataLink还支持自定义拉链表字段和规则,以满足不同企业的需求。
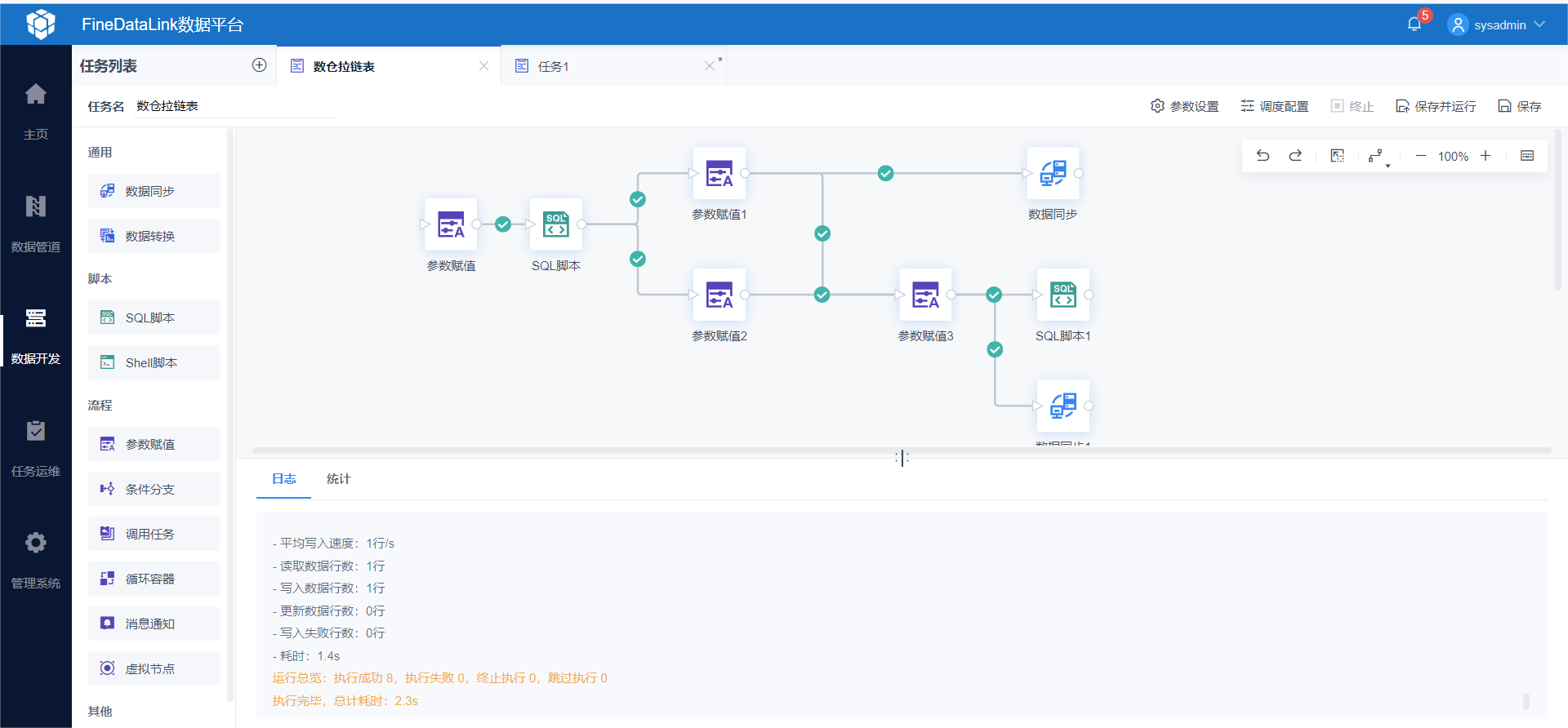
FineDataLink构建数仓拉链表示例
FineDataLink是一款低代码/高效率的ETL工具,同时也是一款数据集成工具,它可以帮助企业快速构建数据仓库,进行数据管理、数据分析和使用,提高数据治理效率和质量。同时,帆软FDL也支持开放API和服务接口,可以与其他数据工具和系统进行整合和拓展。







 立即沟通
立即沟通

