都说Hadoop与大数据平台难懂?本文用大白话讲清楚
这篇hadoop的架构,全篇都是以大白话的形式,也算是为后面更加详细的每一部分开了个好头吧。
一、概念
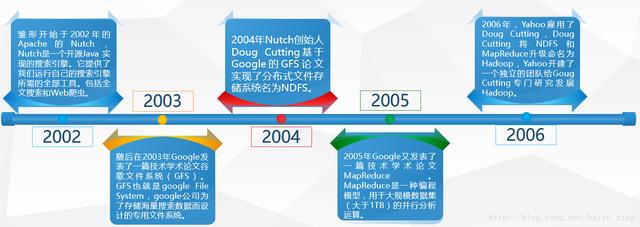
Hadoop诞生于2006年,一个分布式系统基础架构,由Apache基金会开发。Hadoop的主要目标是对分布式环境下的“大数据”以一种可靠、高效、可伸缩的方式处理。
Hadoop框架透明地为应用提供可靠性和数据移动。它实现了名为MapReduce的编程范式:应用程序被分割成许多小部分,而每个部分都能在集群中的任意节点上执行或重新执行。
Hadoop还提供了分布式文件系统,用以存储所有计算节点的数据,这为整个集群带来了非常高的带宽。MapReduce和分布式文件系统的设计,使得整个框架能够自动处理节点故障。它使应用程序与成千上万的独立计算的电脑和PB级的数据。
二、组成
1.Hadoop的核心组件
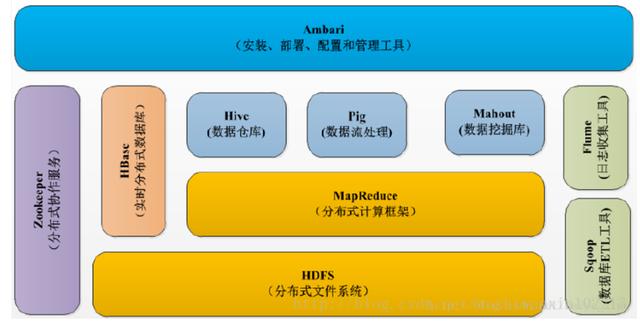
分析:Hadoop的核心组件分为:HDFS(分布式文件系统)、MapRuduce(分布式运算编程框架)、YARN(运算资源调度系统)
2.HDFS的文件系统
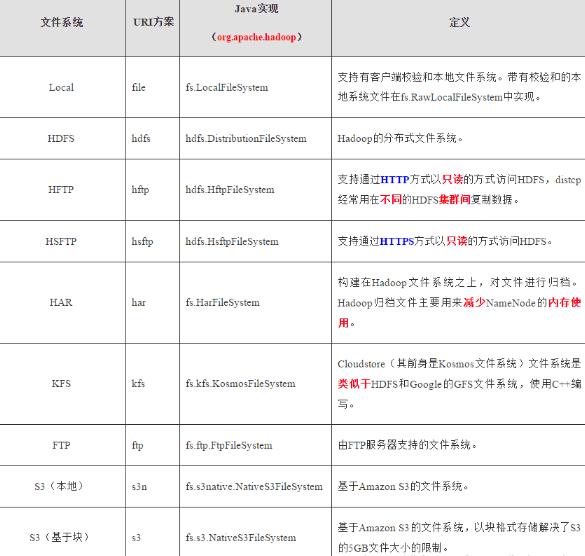
HDFS
1.定义
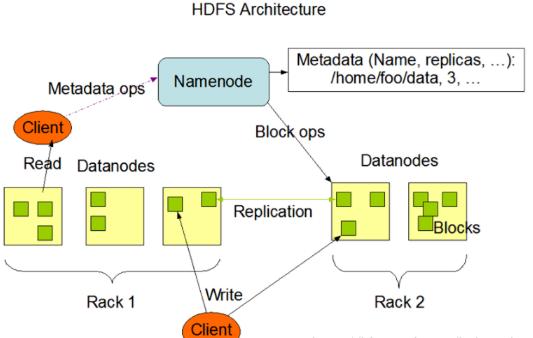
整个Hadoop的体系结构主要是通过HDFS(Hadoop分布式文件系统)来实现对分布式存储的底层支持,并通过MR来实现对分布式并行任务处理的程序支持。
HDFS是Hadoop体系中数据存储管理的基础。它是一个高度容错的系统,能检测和应对硬件故障,用于在低成本的通用硬件上运行。HDFS简化了文件的一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序。
MapReduce
1.定义
Hadoop MapReduce是google MapReduce 克隆版。
MapReduce是一种计算模型,用以进行大数据量的计算。其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce这样的功能划分,非常适合在大量计算机组成的分布式并行环境里进行数据处理。
2.组成
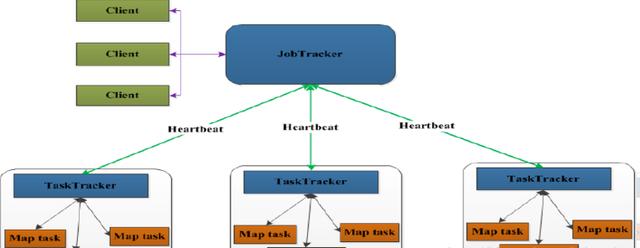
分析:
(1)JobTracker
JobTracker叫作业跟踪器,运行到主节点(Namenode)上的一个很重要的进程,是MapReduce体系的调度器。用于处理作业(用户提交的代码)的后台程序,决定有哪些文件参与作业的处理,然后把作业切割成为一个个的小task,并把它们分配到所需要的数据所在的子节点。
Hadoop的原则就是就近运行,数据和程序要在同一个物理节点里,数据在哪里,程序就跑去哪里运行。这个工作是JobTracker做的,监控task,还会重启失败的task(于不同的节点),每个集群只有唯一一个JobTracker,类似单点的NameNode,位于Master节点
(2)TaskTracker
TaskTracker叫任务跟踪器,MapReduce体系的最后一个后台进程,位于每个slave节点上,与datanode结合(代码与数据一起的原则),管理各自节点上的task(由jobtracker分配),
每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,运行Map Task和Reduce Task;并与JobTracker交互,汇报任务状态,
Map Task:解析每条数据记录,传递给用户编写的map(),并执行,将输出结果写入本地磁盘(如果为map-only作业,直接写入HDFS)。
Reducer Task:从Map Task的执行结果中,远程读取输入数据,对数据进行排序,将数据按照分组传递给用户编写的reduce函数执行。
Hive
1.定义
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
Hive是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
2.组成
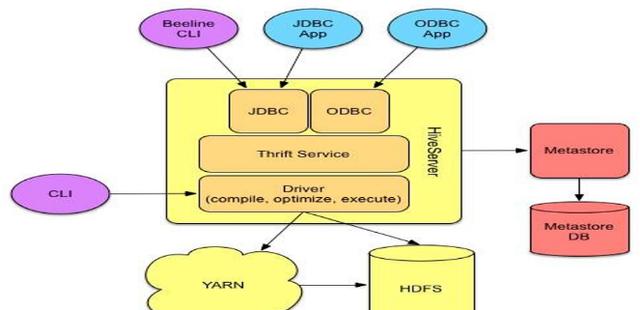
分析:Hive架构包括:CLI(Command Line Interface)、JDBC/ODBC、Thrift Server、WEB GUI、Metastore和Driver(Complier、Optimizer和Executor),这些组件分为两大类:服务端组件和客户端组件
3.Hive与传统数据库的异同
(1)查询语言
由于 SQL 被广泛的应用在数据仓库中,因此专门针对Hive的特性设计了类SQL的查询语言HQL。熟悉SQL开发的开发者可以很方便的使用Hive进行开发。
(2)数据存储位置
Hive是建立在Hadoop之上的,所有Hive的数据都是存储在HDFS中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
(3)数据格式
Hive中没有定义专门的数据格式,数据格式可以由用户指定,用户定义数据格式需要指定三个属性:列分隔符(通常为空格、”\t”、”\\\x001″)、行分隔符(”\n”)以及读取文件数据的方法(Hive中默认有三个文件格式TextFile,SequenceFile以及RCFile)。
(4)数据更新
由于Hive是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive中不支持
对数据的改写和添加,所有的数据都是在加载的时候中确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用INSERT INTO … VALUES添加数据,使用UPDATE … SET修改数据。
(5)索引
Hive在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些Key建立索引。Hive要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。
由于MapReduce的引入, Hive可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。
由于数据的访问延迟较高,决定了Hive不适合在线数据查询。
(6)执行
Hive中大多数查询的执行是通过Hadoop提供的MapReduce来实现的(类似select * from tbl的查询不需要MapReduce)。而数据库通常有自己的执行引擎。
(7)数据规模
由于Hive建立在集群上并可以利用MapReduce进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
(此处已添加小程序,请到今日头条客户端查看)
Hbase
1.定义
HBase – Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;
Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据;
Google Bigtable利用 Chubby作为协同服务,HBase利用Zookeeper作为协同服务。
2.组成
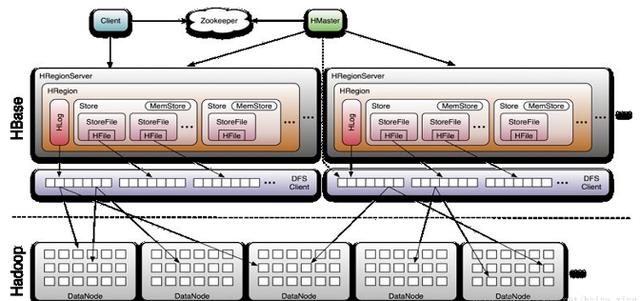
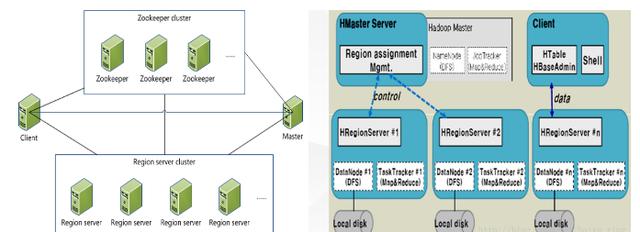
分析:从上图可以看出:Hbase主要由Client、Zookeeper、HMaster和HRegionServer组成,由Hstore作存储系统。
Client
HBase Client使用HBase的RPC机制与HMaster和HRegionServer进行通信,对于管理类操作,Client与 HMaster进行RPC;对于数据读写类操作,Client与HRegionServer进行RPC
Zookeeper
Zookeeper Quorum 中除了存储了 -ROOT- 表的地址和 HMaster 的地址,HRegionServer 也会把自己以 Ephemeral 方式注册到 Zookeeper 中,使得 HMaster 可以随时感知到各个HRegionServer 的健康状态。
三、Hadoop的应用实例
1.回顾Hadoop的整体架构
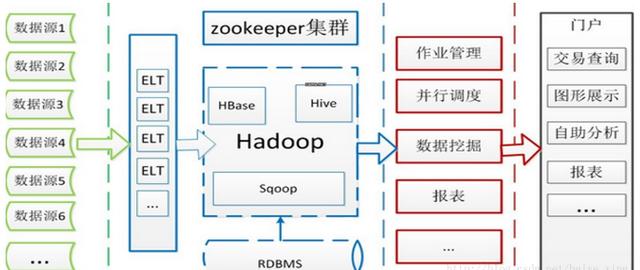
2.Hadoop的应用——流量查询系统
(1)流量查询系统总体框架
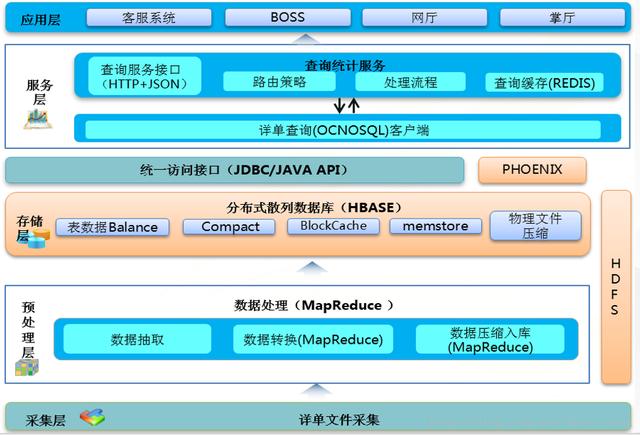
(2)流量查询系统总体流程
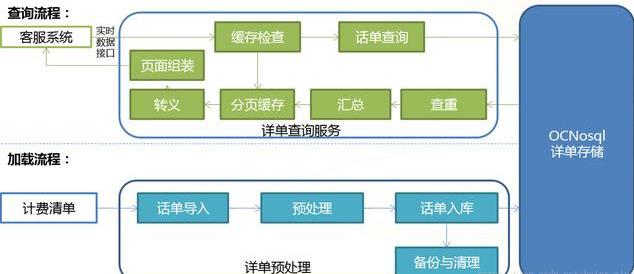
(3)流量查询系统数据预处理功能框架
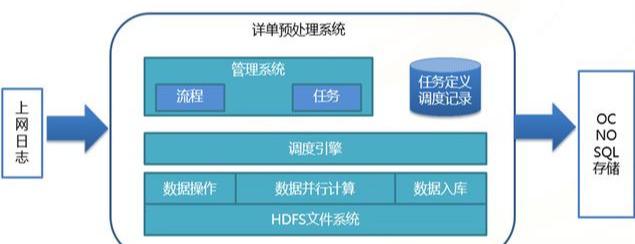
(4)流量查询系统数据预处理流程
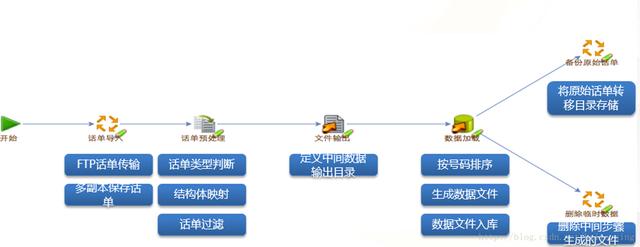
(5)流量查询NoSQL数据库功能框架
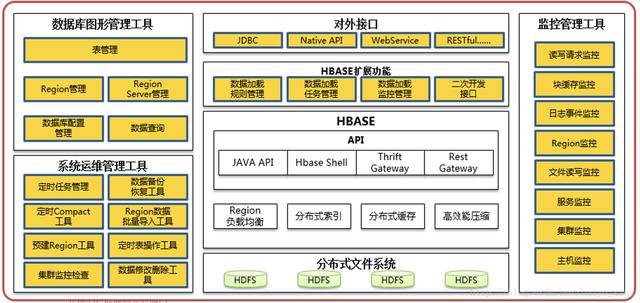
(6)流量查询服务功能框架
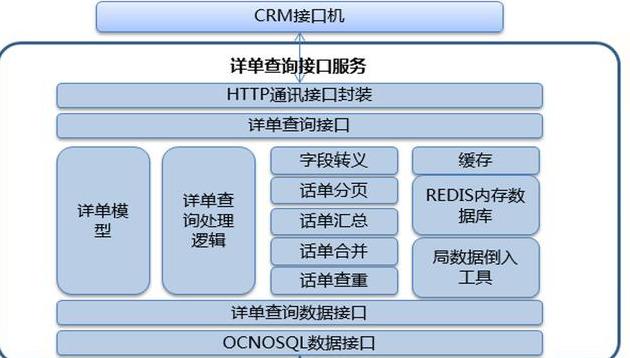
(7)实时流计算数据处理流程图
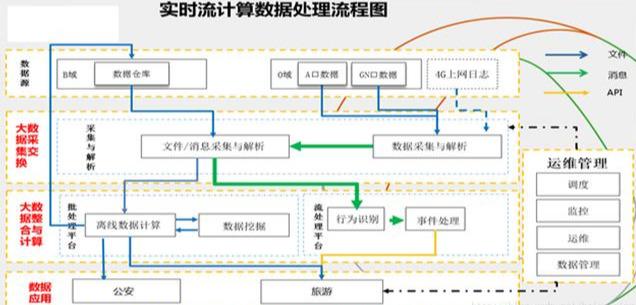




 立即沟通
立即沟通