关于数据建模之思考(三):数仓分层设计架构
本文接上期《谈谈关于数据建模的思考(一)》https://mp.weixin.qq.com/s/1NuRIAlof4VD8nspoLQJbQ,继续聊聊数据仓库模型!
数仓项目系列:
《详解数据仓库的实施步骤,实战扫盲系列!》
https://mp.weixin.qq.com/s/85Saztx-o1DrX12vh0M03Q
《如何做好一个BI项目的规划和需求定义?》
https://mp.weixin.qq.com/s/y3SuF4e-A6anQmW7Mn2b0w
《谈谈关于数据建模的思考(一)》
https://mp.weixin.qq.com/s/1NuRIAlof4VD8nspoLQJbQ
文 | 王保强
从传统的在线交易系统转换为基于主题的数据仓库系统,就涉及到从传统的第三范式设计到星型模型构建的过程,以及数据的抽取、转换、加载的过程,这个过程就是数据仓库的分层设计架构。
数据仓库分层架构的目标是什么?是为了实现维度建模,进而支撑决策分析目标。
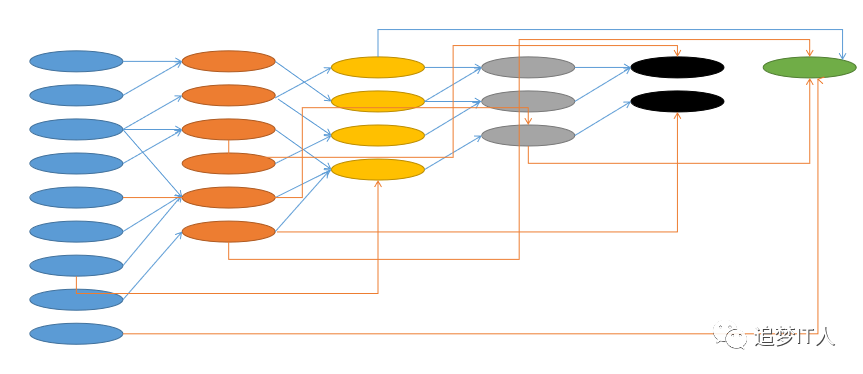
记得我刚入职移动公司的时候,主要负责经分系统,经分系统后台有将近10000张数据表,前台有数千张报表,对着这么一大堆数据茫然不知所措。那个时候对运营商业务一窍不通,文档资料不齐全,看文档呢又看的稀里糊涂,向合作伙伴请教多了呢又被翻白眼,于是一狠心决定对经分系统的代码通读一下。当时发现很多表的命名都有规则的,比如dwifc,dwstr,dwmid,dwctr,dwapp等等,后来了解到dwifc代表接口表,dwstr代表存储表,dwmid代表中间表,dwctr代表汇总表,dwapp代表应用表,dwtmp代表临时表等等,但是数万个之多应该先看哪些呢?再请教同事和合作伙伴。其实最常用的也就百十来个,锁定范围就好办了;再细细观察,_day,_mon,_sum_day等等表的业务逻辑其实差不太多,再次缩小范围;差不多看了半年多代码,这半年多再加上一些日常取数的工作,基本上也熟悉了业务,当然这个业务是基于技术语言解读的,还做了大量的笔记,相当于整理了一遍这上百张表的字段级血缘关系。
印象最深的是一张客户信息表,我足足阅读代码和分析了整整三个月,这张表前前后后涉及到七八十个上游的表,五六十个存储过程,层级大概有七八级,关键是层级还有些乱。还好代码注释写的还是比较规范,代码排版也还好,代码质量嘛,就不好说了,不过从阅读代码过程中也可以了解到整个客户表的设计和变更过程,也可以逐步体会到从最初的规范到最后的失控是如何形成的。
再回到为什么要做数据分层这个问题上来?
数据分层从关系型在线交易系统到面向主题的数据仓库系统,从范式建模到维度建模的必经之路。
数据分层是一套让我们的数据体系更有序的行之有效的数据组织和管理方法。数据分层不是银弹,也没有绝对标准,当然也不能包治百病,不能解决所有的数据问题,但是,数据分层却可以给我们带来如下的好处:
1、数据结构化更清晰:每一个数据分层都有它的作用域和职责,在使用表的时候能更方便地定位和理解。
2、数据血缘追踪:提供给外界使用的是一张业务表,但是这张业务表可能来源很多张表。如果有一张来源表出问题了,我们可以快速准确的定位到问题,并清楚每张表的作用范围。
3、增强数据复用能力:减少重复开发,通过数据分层规范化,开发一些通用的中间层数据,能够减少重复计算,提高单张业务表的使用率,提升系统的执行效率。
4、简化复杂的问题:把一个复杂的业务分成多个步骤实现,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。
5、减少业务的影响:业务可能会经常变化,这样做就不必改一次业务就需要重新接入数据。
6、统一数据口径:通过数据分层,提供统一的数据出口,统一对外输出的数据口径。
还是那句话,数据分层没有银弹,也没有标准,数据分层要结合当下的技术,当前的数据量,业务的复杂度通盘考量。在《DAMA数据管理知识体系指南中文版》中提到了操作型数据存储(ODS),数据仓库(DW),数据集市(DM),其实这就是数据分层的原始的指导建议,其中操作型数据存储是满足多个业务系统获取数据并制作操作型报表的需求,保留半年以内的明细准实时数据;数据仓库是为了管理决策、战略分析和计划提供单一整合点,保留长期的明细和汇总数据;数据集市是用于特定部门或公共分析需求并定制的,保留中期的明细和汇总数据,采用维度建模方式。
ODS层即操作数据存储:是最接近数据源中数据的一层,数据源中的数据,经过抽取、洗净、传输,也就说传说中的ETL之后,装入本层;一般来说ODS层的数据和源系统的数据是同构的,主要目的是简化后续数据加工处理的工作。从数据粒度上来说ODS层的数据粒度是最细的。ODS层的表通常包括两类,一个用于存储当前需要加载的数据,一个用于存储处理完后的历史数据。历史数据一般保存3-6个月后需要清除,以节省空间。但不同的项目要区别对待,如果源系统的数据量不大,可以保留更长的时间,甚至全量保存;数据在装入本层前需要做以下工作:去噪、去重、提脏、业务提取、单位统一、砍字段、业务判别。
数据仓库层(DW)层:数据仓库层是我们在做数据仓库时要核心设计的一层,本层将从 ODS 层中获得的数据按照主题建立各种数据模型,每一个主题对应一个宏观的分析领域,数据仓库层排除对决策无用的数据,提供特定主题的简明视图。在DW层会保存BI系统中所有的历史数据,例如保存10年的数据。
数据集市层(DM):存放的是轻度聚合的数据,也可以称为数据应用层,基于DW上的基础数据,整合汇总成分析某一个主题域的报表数据。主要是提供给数据产品和数据分析使用的数据,通常根据业务需求,划分成流量、订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。从数据粒度来说,这层的数据是汇总级的数据,也包括部分明细数据。从数据的时间跨度来说,通常是DW层的一部分,主要的目的是为了满足用户分析的需求,而从分析的角度来说,用户通常只需要分析近几年的即可。从数据的广度来说,仍然覆盖了所有业务数据。
在实际构建过程中,业界也在不断探索和完善数据分层架构,主要集中在DW层,将DW层又细分为 DWD(Data Warehouse Detail)层、DWM(Data Warehouse Middle)层和DWS(Data Warehouse Service)层。
数据明细层:DWD(Data Warehouse Detail)
该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证,在ODS的基础上对数据进行加工处理,提供更干净的数据。同时,为了提高数据明细层的易用性,该层会采用一些维度退化手法,当一个维度没有数据仓库需要的任何数据时,就可以退化维度,将维度退化至事实表中,减少事实表和维表的关联。例如:订单id,这种量级很大的维度,没必要用一张维度表来进行存储,而我们一般在进行数据分析时订单id又非常重要,所以我们将订单id冗余在事实表中,这种维度就是退化维度。
数据中间层:DWM(Data Warehouse Middle)
该层会在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工处理数据。简单来说,就是对通用的维度进行聚合操作,算出相应的统计指标,方便复用。
数据服务层:DWS(Data Warehouse Service)
该层数据表会相对比较少,大多都是宽表(一张表会涵盖比较多的业务内容,表中的字段较多)。按照主题划分,如订单、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP分析,数据分发等。
就像前文所述,数据分层要结合当下的数据量和技术,同时也是个不断探索的过程,窃以为移动经营分析系统经过了十几年的耕耘,在数据分层结构上还是比较合理的。
| 层级 | 说明 | 描述 |
| dwi
fc |
接口层 | 接口层对应上游业务系统传过来的业务数据,无论是全量、增量原封不动入库;同时验证和监控接口文件的质量、时间等。 |
| dw
str |
存储层 | 结合全量、增量条件与现有存储层数据进行融合,确保数据可以持久保存,即使后续数据处理环节有问题,也可以重算。 |
| dw
mid |
中间层 | 在存储层基础上进行数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工处理数据;对于海量数据的处理可能会存在多级中间层,以应对不同维度的处理要求。 |
| dw
ctr |
汇总层 | 融合多个中间层数据,基于主题形成事实表,比如用户事实表、渠道事实表、终端事实表、资产事实表等等,事实表一般是宽表,在本层上实现企业级数据的一致性。 |
| dw
app |
应用层 | 应用层通常是多维的报表层数据,应对前端BI报表展示。 |
END




 立即沟通
立即沟通