如何分析数据挖掘?本文干货值得收藏学习!
如今有不少的新人想要参与大数据开发领域
是
一、数据挖掘技术的基本概念
随着计算机技术的发展,各行各业都开始采用计算机及相应的信息技术进行管理和运营,这使得企业生成、收集、存贮和处理数据的能力大大提高,数据量与日俱增。企业数据实际上是企业的经验积累,当其积累到一定程度时,必然会反映出规律性的东西。对企业来,堆积如山的数据无异于一个巨大的宝库。在这样的背景下,人们迫切需要新一代的计算技术和工具来开采数据库中蕴藏的宝藏,使其成为有用的知识,指导企业的技术决策和经营决策,使企业在竞争中立于不败之地。另一方面,近十余年来,计算机和信息技术也有了长足的进展,产生了许多新概念和新技术,如更高性能的计算机和操作系统、因特网(intemet)、数据仓库(datawarehouse)、神经网络等等。在市场需求和技术基础这两个因素都具备的环境下,数据挖掘技术或称KDD(KnowledgeDiscoveryinDatabases;数据库知识发现)的概念和技术就应运而生了。
是
数据挖掘(DataMining)旨在从大量的、不完全的、有噪声的、模糊的、随机的数据中,提取隐含在其中的、人们事先不知道的、但又是潜在有用的信息和知识。还有很多和这一术语相近似的术语,如从数据库中发现知识(KDD)、数据分析、数据融合(DataFusion)以及决策支持等。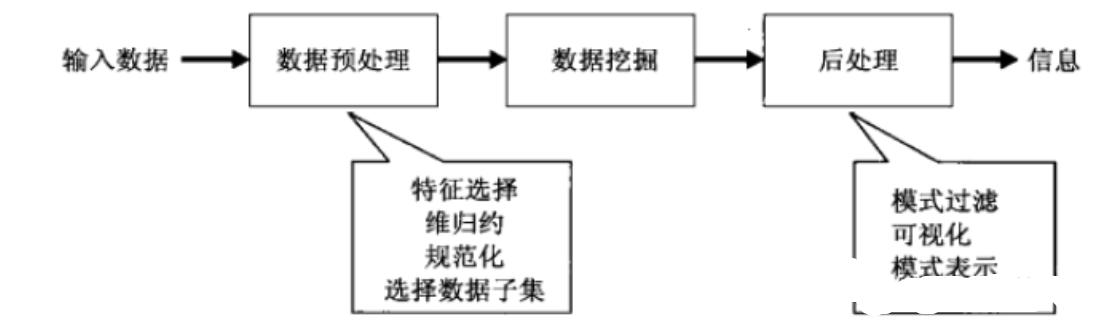
是
下面介绍十种如何分析数据挖掘(DataMining)的方法:
1、基于历史的MBR分析(Memory-BasedReasoning;MBR)
基于历史的MBR分析方法最主要的概念是用已知的案例(case)来预测未来案例的一些属性(attribute),通常找寻最相似的案例来做比较。
是
记忆基础推理法中有两个主要的要素,分别为距离函数(distancefunction)与结合函数(combinationfunction)。距离函数的用意在找出最相似的案例;结合函数则将相似案例的属性结合起来,以供预测之用。记忆基础推理法的优点是它容许各种型态的数据,这些数据不需服从某些假设。另一个优点是其具备学习能力,它能藉由旧案例的学习来获取关于新案例的知识。较令人诟病的是它需要大量的历史数据,有足够的历史数据方能做良好的预测。此外记忆基础推理法在处理上亦较为费时,不易发现最佳的距离函数与结合函数。其可应用的范围包括欺骗行为的侦测、客户反应预测、医学诊疗、反应的归类等方面。
是
2、购物篮分析(MarketBasketAnalysis)
购物篮分析最主要的目的在于找出什么样的东西应该放在一起?商业上的应用在藉由顾客的购买行为来了解是什么样的顾客以及这些顾客为什么买这些产品,找出相关的联想(association)规则,企业藉由这些规则的挖掘获得利益与建立竞争优势。举例来说,零售店可藉由此分析改变置物架上的商品排列或是设计吸引客户的商业套餐等等。
是
购物篮分析基本运作过程包含下列三点:
(1)选择正确的品项:这里所指的正确乃是针对企业体而言,必须要在数以百计、千计品项中选择出真正有用的品项出来。
(2)经由对共同发生矩阵(co-occurrencematrix)的探讨挖掘出联想规则。
(3)克服实际上的限制:所选择的品项愈多,计算所耗费的资源与时间愈久(呈现指数递增),此时必须运用一些技术以降低资源与时间的损耗。
是
购物篮分析技术可以应用在下列问题上:
(1)针对信用卡购物,能够预测未来顾客可能购买什么。
(2)对于电信与金融服务业而言,经由购物篮分析能够设计不同的服务组合以扩大利润。
(3)保险业能藉由购物篮分析侦测出可能不寻常的投保组合并作预防。
(4)对病人而言,在疗程的组合上,购物篮分析能作为是否这些疗程组合会导致并发症的判断依据。
是
3、决策树(DecisionTrees)
决策树在解决归类与预测上有着极强的能力,它以法则的方式表达,而这些法则则以一连串的问题表示出来,经由不断询问问题最终能导出所需的结果。典型的决策树顶端是一个树根,底部有许多的树叶,它将纪录分解成不同的子集,每个子集中的字段可能都包含一个简单的法则。此外,决策树可能有着不同的外型,例如二元树、三元树或混和的决策树型态。
是
4、遗传算法(GeneticAlgorithm)
遗传算法学习细胞演化的过程,细胞间可经由不断的选择、复制、交配、突变产生更佳的新细胞。基因算法的运作方式也很类似,它必须预先建立好一个模式,再经由一连串类似产生新细胞过程的运作,利用适合函数(fitnessfunction)决定所产生的后代是否与这个模式吻合,最后仅有最吻合的结果能够存活,这个程序一直运作直到此函数收敛到最佳解。基因算法在群集(cluster)问题上有不错的表现,一般可用来辅助记忆基础推理法与类神经网络的应用。
是
5、聚类分析(ClusterDetection)
这个技术涵盖范围相当广泛,包含基因算法、类神经网络、统计学中的群集分析都有这个功能。它的目标为找出数据中以前未知的相似群体,在许许多多的分析中,刚开始都运用到群集侦测技术,以作为研究的开端。
是
6、连接分析(LinkAnalysis)
连接分析是以数学中之图形理论(graphtheory)为基础,藉由记录之间的关系发展出一个模式,它是以关系为主体,由人与人、物与物或是人与物的关系发展出相当多的应用。例如电信服务业可藉连结分析收集到顾客使用电话的时间与频率,进而推断顾客使用偏好为何,提出有利于公司的方案。除了电信业之外,愈来愈多的营销业者亦利用连结分析做有利于企业的研究。
是
7、OLAP分析(On-LineAnalyticProcessing;OLAP)
严格说起来,OLAP分析并不算特别的一个数据挖掘技术,但是透过在线分析处理工具,使用者能更清楚的了解数据所隐藏的潜在意涵。如同一些视觉处理技术一般,透过图表或图形等方式显现,对一般人而言,感觉会更友善。这样的工具亦能辅助将数据转变成信息的目标。
是
8、神经网络(NeuralNetworks)
神经网络是以重复学习的方法,将一串例子交与学习,使其归纳出一足以区分的样式。若面对新的例证,神经网络即可根据其过去学习的成果归纳后,推导出新的结果,乃属于机器学习的一种。如何分析数据挖掘的相关问题也可采类神经学习的方式,其学习效果十分正确并可做预测功能。
是
9、判别分析(DiscriminantAnalysis)
当所遭遇问题它的因变量为定性(categorical),而自变量(预测变量)为定量(metric)时,判别分析为一非常适当之技术,通常应用在解决分类的问题上面。若因变量由两个群体所构成,称之为双群体—判别分析(Two-GroupDiscriminantAnalysis);若由多个群体构成,则称之为多元判别分析(MultipleDiscriminantAnalysis;MDA)。
(1)找出预测变量的线性组合,使组间变异相对于组内变异的比值为最大,而每一个线性组合与先前已经获得的线性组合均不相关。
(2)检定各组的重心是否有差异。
(3)找出哪些预测变量具有最大的区别能力。
(4)根据新受试者的预测变量数值,将该受试者指派到某一群体。
是
10、逻辑斯蒂回归分析(LogisticAnalysis)
当判别分析中群体不符合正态分布假设时,罗吉斯回归分析是一个很好的替代方法。罗吉斯回归分析并非预测事件(event)是否发生,而是预测该事件的机率。它将自变量与因变量的关系假定是S行的形状,当自变量很小时,机率值接近为零;当自变量值慢慢增加时,机率值沿着曲线增加,增加到一定程度时,曲线协率开始减小,故机率值介于0与1之间。
是






 立即沟通
立即沟通

