做了15年数据,对实时数据仓库的一些总结
去年开始,实时数仓的概念突然火了。也许是传统的离线数仓搞了很多年,技术相对成熟了,因此大家都把注意力放到了挑战性更高的实时上来;也许是随着存量市场竞争的到来,对于速度的要求越来越快,T+1已经不能满足数据的获取要求了,实时的构建需求也就应运而生了。
总之,时效性开始大于分析性。
文本简单介绍实时数仓的一些基础理论,更系统性的理论,仍然行业需要更大范围的应用和总结。总之,这是一块有前景的新领域,值得探索。
实时数仓的技术要求
1.高并发性:未来的实时数据一定不是仅仅给几个运营或管理层人员使用,会更多的面向商户、用户,那么用户增加的情况下一定会带来并发量的提升,因此实时数仓一定要具备提供高并发数据服务的能力。
2.查询速度:目前很多实时指标的应用场景在移动端,移动端对于数据的响应要求远高于PC端,对于大多数数据使用场景希望能够毫秒级返回,未来实时标签如果应用到用户推荐上,对于响应的速度要求更高。
3.处理速度:要保证大促期间,在流量峰值的情况下有极强的处理能力,并且具备消费低延迟性甚至0延迟。
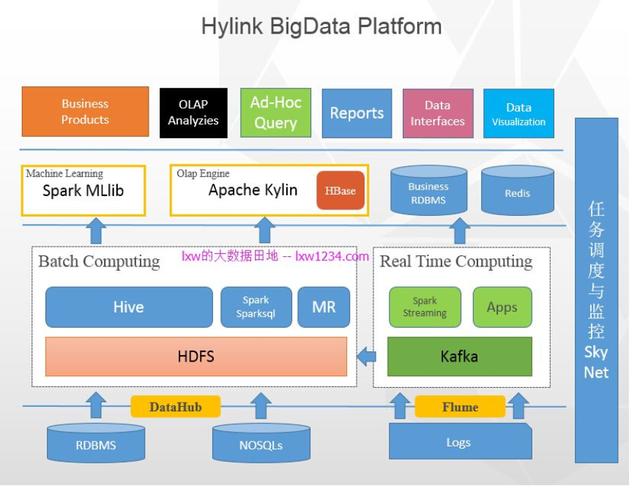
实时数仓的技术基础:流式技术架构
目前流式计算框架相对成熟,以Storm、Spark Streaming、Flink为代表的开源组件也被广泛应用。流式数据处理,简单来讲,就是系统每产生一条数据,都会被立刻采集并发送到流式任务中心进行处理,不需要额外的定时调度来执行任务。
目前在业界比较广泛采用的框架有Twitter的Storm、Apache的Spark Streaming,以及最近几年流行的Flink。它们整体架构大同小异,但在实现细节上有诸多的不同,需要根据业务场景的特征来灵活选择框架。
流式框架具备以下优点:
1.时效性高:延迟力度通常在秒级;
2.任务常驻:流式任务一旦启动,就会一直运行,直到人为终止,且数据源是无界的;
3.处理性能高:流式计算通常会采用较好的服务器来运行任务,因为一旦处理吞吐量赶不上采集吞吐量,就会出现数据计算延迟;
4.逻辑简单:由于流式计算通常是针对单条数据做处理,缺乏数据之间的关联运算能力,所以在支持的业务逻辑上相对简单,并且处理结果会与离线存在一定的差异。
实时数仓的两个常见架构
Lambda架构:Lambda架构的核心理念是“流批一体化”,因为随着机器性能和数据框架的不断完善,用户其实不关心底层是如何运行的,批处理也好,流式处理也罢,能按照统一的模型返回结果就可以了,这就是Lambda架构诞生的原因。现在很多应用,例如Spark和Flink,都支持这种结构,也就是数据进入平台后,可以选择批处理运行,也可以选择流式处理运行,但不管怎样,一致性都是相同的。
Kappa架构:Lambda架构虽然理念很好,但用多了会有一个问题:数据复杂性大大增加。为了解决复杂性的问题,有人提出了用一套架构解决所有问题的设想,而流行的做法就是基于流计算来做。通过加大流计算的“时间窗口”,来实现逻辑意义上的批处理操作。
实时数仓的查询引擎
实时数仓的查询依赖于交互式查询引擎,常见于OLAP场景,根据存储数据方式的不同可以分为ROLAP、MOLAP和HOLAP:
ROLAP:在大数据生态圈中,主流的应用于ROLAP场景的交互式计算引擎包括Impala和Presto。基于关系数据库OLAP实现(Relational OLAP),它以关系数据库为核心,以关系型结构进行多维数据的表示和存储。
它将多维结构划分成两类表:一类是事实表,迎来存储数据和维度关键字;另一类是维度表,即对每个维度至少使用一个表来存放维度层次、成员类别等维度描述信息。ROLAP的最大好处是可以实时地从源数据中获得最新数据更新,以保持数据实时性,缺点在于运算效率比较低,用户等待时间比较长。
MOLAP:MOLAP是一种通过预计算Cube方式加速查询的OLAP引擎,它的核心思想是“空间换时间”,典型的代表包括Druid和Kylin。基于多维数据组织的OLAP实现(Multidimensional OLAP),它以多维数据组织方式为核心,使用多维数组存储数据。
多维数据在存储系统中形成“数据立方体(Cube)”结构,此结构是高度优化的,可以最大程度提高查询性能。MOLAP的优势在于借助数据多位预处理显著提高运算效率,主要缺陷在于占用存储空间大和数据更新有一定延迟。
HOLAP:基于混合数据组织的OLAP实现(Hybrid OLAP),用户可以根据自己的业务需求,选择哪些模型采用ROLAP、哪些采用MOLAP。一般来说,将不常用或需要灵活定义的分析使用ROLAP,而常用、常规模型采用MOLAP实现。
实时数仓的分层模型
实时数仓的分层思路沿用了离线的思想。
CDM层(明细数据层): CDM层根据业务场景的不同,分为各个主题域。
DWS层(汇总数据层):DWS层对各个域进行了适度汇总。
ADS层 (应用数据层):ADS层并不完全根据需求一对一建设,而是结合不同的需求对这一层进行统一设计,以快速支撑更多的需求场景。
实时技术中的幂等机制
幂等是一个数学概念,特点是任意多次执行所产生的影响均与一次执行的影响相同,例如setTrue()函数就是一个幂等函数,无论多次执行,其结果都是一样的。在很多复杂情况下,例如网络波动、Storm重启等,会出现重复数据,因此并不是所有操作都是幂等的。在幂等的概念下,我们需要了解消息传输保障的三种机制:At most once、At least once和Exactly once。
At most once:消息传输机制是每条消息传输零次或者一次,即消息可能会丢失;
At least once:意味着每条消息会进行多次传输尝试,至少一次成功,即消息传输可能重复但不会丢失;
Exactly once:消息传输机制是每条消息有且只有一次,即消息传输既不会丢失也不会重复。
实时数仓中的多表关联
在流式数据处理中,数据的计算是以计算增量为基础的,所以各个环节到达的时间和顺序,既是不确定的,也是无序的。在这种情况下,如果两表要关联,势必需要将数据在内存中进行存储,当一条数据到达后,需要去另一个表中查找数据,如果能够查到,则关联成功,写入下游;
如果无法查到,可以被分到未分配的数据集合中进行等待。在实际处理中,考虑到数据查找的性能,会把数据按照关联主键进行分桶处理,以降低查找的数据量,提高性能。
实时技术中的洪峰挑战
主要解决思路有如下几种:
1.独占资源与共享资源合理分配:在一台机器中,共享资源池可以被多个实时任务抢占,如果一个任务80%的时间都需要抢资源,可以考虑分配更多的独占资源;
2.合理设置缓存机制:虽然内存的读写性能是最好的,但很多数据依然需要读库更新,可以考虑将热门数据尽量多的留在内存中,通过异步的方式来更新缓存;
3.计算合并单元:在流式计算框架中,拓扑结构的层级越深,性能越差,考虑合并计算单元,可以有效降低数据的传输、序列化等时间;
4.内存共享:在海量数据的处理中,大部分的对象都是以字符串形式存在的,在不同线程间合理共享对象,可以大幅度降低字符拷贝带来的性能消耗;
5.在高吞吐与低延迟间寻求平衡:高吞吐与低延迟天生就是一对矛盾体,将多个读写库的操作或者ACK操作合并时,可以有效降低数据吞吐,但也会增加延迟,可以进行业务上的取舍。
总结
在整个实时数仓的建设中,业界已经有了常用的方案选型。整体架构设计通过分层设计为OLAP查询分担压力,让出计算空间,复杂的计算统一在实时计算层处理掉,避免给OLAP查询带来过大的压力。汇总计算交给OLAP数据库进行。
因此,在整个架构中实时计算一般是Spark+Flink配合,消息队列Kafka一家独大,在整个大数据领域消息队列的应用中仍然处于垄断地位,Hbase、Redis和MySQL都在特定场景下有一席之地。
目前还没有一个OLAP系统能够满足各种场景的查询需求。其本质原因是,没有一个系统能同时在数据量、性能、和灵活性三个方面做到完美,每个系统在设计时都需要在这三者间做出取舍。
从长远看,Spark和Flink更有可能成为下一代的Hadoop,值得投入大量时间学习。
很显然在目前的信息时代,借助类似于FineDataLink的这些工具,可以让企业加速融入企业数据集成和分析的趋势。备受市场认可的软件其实有很多,选择时必须要结合实际的情况。一般的情况下,都建议选择市面上较主流的产品,比较容易达到好的效果,就是帆软的数据集成平台——FineDataLink。




 立即沟通
立即沟通