

Feature Engineering
Sean, Editor Industri
2024 Desember 25

Feature Engineering adalah proses penting dalam data science yang mengubah data mentah menjadi informasi yang lebih bermakna. Proses ini membantu model machine learning memahami pola dalam data dengan lebih baik. Dengan fitur yang relevan, model dapat membuat prediksi yang lebih akurat. Selain itu, Feature Engineering juga memungkinkan pengurangan kompleksitas data, sehingga analisis menjadi lebih efisien. Dalam dunia machine learning, kualitas fitur sering kali menentukan keberhasilan model.
Poin Penting Feature Engineering
- Feature Engineering adalah proses penting yang mengubah data mentah menjadi fitur yang lebih bermakna untuk meningkatkan akurasi model machine learning.
- Proses ini membantu mengurangi kompleksitas data, sehingga analisis menjadi lebih efisien dan cepat.
- Membuat fitur baru dari data mentah dapat memberikan wawasan tambahan yang tidak terlihat sebelumnya, seperti 'total penjualan per bulan' dari data harian.
- Teknik seperti normalisasi, standardisasi, dan encoding data kategorikal adalah dasar yang penting untuk mempersiapkan data sebelum analisis.
- Menggunakan alat seperti FineBI dapat mempercepat eksplorasi dan visualisasi data, membantu pengguna memahami pola dengan lebih baik.
- Pemula disarankan untuk mulai dengan dataset sederhana dan fokus pada teknik dasar sebelum beralih ke teknik yang lebih kompleks.
- Seleksi fitur yang tepat dapat menghindari overfitting dan meningkatkan performa model dengan memilih fitur yang paling relevan.

Apa Itu Feature Engineering?
Definisi dan Konsep Dasar Feature Engineering
Feature Engineering adalah proses mengubah data mentah menjadi fitur yang lebih bermakna. Fitur ini digunakan oleh model machine learning untuk memahami pola dalam data. Proses ini melibatkan manipulasi, transformasi, dan pembuatan fitur baru yang relevan. Data mentah sering kali tidak langsung dapat digunakan oleh model. Oleh karena itu, Feature Engineering membantu menjadikan data lebih informatif dan siap untuk dianalisis.
Dalam konsep dasarnya, Feature Engineering bertujuan untuk meningkatkan kualitas data. Data yang berkualitas tinggi memungkinkan model machine learning bekerja lebih optimal. Proses ini juga membantu mengurangi noise dalam data, sehingga model dapat fokus pada informasi yang benar-benar penting.

Tujuan dan Manfaat Feature Engineering
Feature Engineering memiliki beberapa tujuan utama. Pertama, proses ini bertujuan untuk meningkatkan akurasi model. Fitur yang relevan dan informatif membantu model membuat prediksi yang lebih baik. Kedua, Feature Engineering membantu mengurangi kompleksitas data. Dengan data yang lebih sederhana, analisis menjadi lebih cepat dan efisien. Ketiga, proses ini memungkinkan identifikasi pola yang sebelumnya tidak terlihat dalam data mentah.
Manfaat dari Feature Engineering sangat signifikan. Model machine learning yang menggunakan fitur berkualitas tinggi cenderung lebih andal. Selain itu, proses ini juga membantu menghemat waktu dan sumber daya. Data yang telah melalui Feature Engineering lebih mudah diproses oleh algoritma machine learning.
Contoh Sederhana Feature Engineering dalam Kehidupan Sehari-Hari
Feature Engineering sering kali terjadi dalam kehidupan sehari-hari tanpa disadari. Sebagai contoh, dalam analisis data penjualan, seseorang dapat membuat fitur baru seperti "total penjualan per bulan" dari data mentah harian. Fitur ini memberikan gambaran yang lebih jelas tentang tren penjualan.
Contoh lainnya adalah dalam aplikasi kesehatan. Data mentah seperti detak jantung per detik dapat diubah menjadi fitur seperti "rata-rata detak jantung per menit". Fitur ini lebih mudah dipahami dan lebih relevan untuk analisis kesehatan.
Proses ini juga terlihat dalam aplikasi transportasi. Data lokasi mentah dapat diubah menjadi fitur seperti "jarak tempuh" atau "waktu perjalanan". Fitur-fitur ini membantu aplikasi memberikan estimasi waktu kedatangan yang lebih akurat.
Mengapa Feature Engineering Penting dalam Machine Learning?
Meningkatkan Kualitas Data untuk Analisis
Data mentah sering kali mengandung informasi yang tidak relevan atau sulit dipahami. Proses Feature Engineering membantu mengubah data tersebut menjadi lebih terstruktur dan bermakna. Dengan fitur yang berkualitas, analisis data menjadi lebih efektif. Model machine learning dapat memahami pola dengan lebih baik ketika data yang digunakan telah melalui proses ini. Sebagai contoh, data transaksi mentah dapat diubah menjadi fitur seperti "jumlah pembelian per pelanggan". Fitur ini memberikan wawasan yang lebih jelas untuk analisis perilaku konsumen.
Selain itu, Feature Engineering memungkinkan identifikasi anomali dalam data. Misalnya, outlier atau data yang tidak konsisten dapat diatasi melalui pembersihan dan transformasi fitur. Dengan data yang lebih bersih, hasil analisis menjadi lebih akurat dan dapat diandalkan.
Mengurangi Kompleksitas Data
Data yang terlalu kompleks sering kali menyulitkan proses analisis. Feature Engineering membantu menyederhanakan data tanpa mengurangi informasi penting. Proses ini melibatkan seleksi fitur yang relevan dan penghapusan fitur yang tidak diperlukan. Dengan demikian, jumlah dimensi data dapat dikurangi, sehingga analisis menjadi lebih cepat dan efisien.
Sebagai ilustrasi, dalam dataset yang memiliki ratusan kolom, hanya beberapa kolom yang mungkin relevan untuk analisis tertentu. Feature Engineering membantu memilih kolom-kolom tersebut berdasarkan relevansi dan kontribusinya terhadap model. Hal ini tidak hanya menghemat waktu, tetapi juga mengurangi risiko overfitting pada model machine learning.
Meningkatkan Akurasi dan Generalisasi Model
Fitur yang baik memungkinkan model machine learning membuat prediksi yang lebih akurat. Feature Engineering membantu menciptakan fitur yang lebih informatif, sehingga model dapat memahami hubungan antarvariabel dengan lebih baik. Sebagai contoh, dalam analisis data cuaca, fitur seperti "kelembapan rata-rata harian" dapat memberikan informasi yang lebih relevan dibandingkan data mentah seperti "kelembapan per jam".
Selain meningkatkan akurasi, proses ini juga membantu model untuk lebih generalisasi. Model yang dilatih dengan fitur berkualitas tinggi cenderung bekerja lebih baik pada data baru. Hal ini penting untuk memastikan bahwa model tidak hanya bekerja baik pada data pelatihan, tetapi juga pada data yang belum pernah dilihat sebelumnya.

Dasar-Dasar Feature Engineering
Langkah-Langkah Utama dalam Feature Engineering
Memahami Data dan Tujuan Analisis
Langkah pertama dalam Feature Engineering adalah memahami data yang tersedia. Data harus dievaluasi untuk mengetahui jenis, struktur, dan distribusinya. Pemahaman ini membantu menentukan fitur mana yang relevan untuk analisis. Selain itu, tujuan analisis harus jelas. Apakah analisis bertujuan untuk prediksi, klasifikasi, atau pengelompokan? Dengan memahami tujuan, proses Feature Engineering dapat lebih terarah.
Membersihkan dan Menyiapkan Data
Data mentah sering kali mengandung noise, missing values, atau inkonsistensi. Membersihkan data menjadi langkah penting untuk memastikan kualitasnya. Proses ini melibatkan penghapusan data duplikat, pengisian nilai yang hilang, dan penanganan outlier. Setelah data bersih, langkah berikutnya adalah menyiapkan data agar siap digunakan oleh model. Contohnya, mengubah format tanggal menjadi angka atau mengonversi data kategorikal menjadi numerik.
Membuat Fitur Baru yang Relevan
Fitur baru sering kali memberikan nilai tambah dalam analisis. Proses ini melibatkan transformasi data mentah menjadi informasi yang lebih bermakna. Sebagai contoh, dari data transaksi, seseorang dapat membuat fitur seperti "rata-rata pembelian per pelanggan". Fitur ini memberikan wawasan yang lebih mendalam dibandingkan data mentah. Membuat fitur baru memerlukan kreativitas dan pemahaman mendalam tentang data.
Seleksi Fitur untuk Mengurangi Dimensi Data
Dataset dengan banyak fitur sering kali mengandung informasi yang tidak relevan. Seleksi fitur membantu mengurangi dimensi data dengan memilih fitur yang paling penting. Proses ini dapat dilakukan dengan analisis korelasi atau menggunakan algoritma seperti Random Forest. Seleksi fitur tidak hanya meningkatkan efisiensi analisis tetapi juga mengurangi risiko overfitting pada model.
Alat dan Teknologi yang Mendukung Feature Engineering
FineBI untuk Eksplorasi dan Visualisasi Data
FineBI adalah alat yang sangat berguna untuk eksplorasi dan visualisasi data. Alat ini memungkinkan pengguna untuk memahami pola dan tren dalam data dengan cepat. Dengan visualisasi yang interaktif, pengguna dapat mengidentifikasi fitur yang relevan untuk analisis. FineBI juga mendukung integrasi dengan berbagai sumber data, sehingga mempermudah proses Feature Engineering.
Library Python seperti pandas dan scikit-learn
Python menyediakan berbagai library yang mendukung Feature Engineering. Library seperti pandas mempermudah manipulasi dan transformasi data. Dengan pandas, pengguna dapat membersihkan data, membuat fitur baru, dan melakukan analisis eksplorasi. Selain itu, scikit-learn menyediakan alat untuk seleksi fitur dan transformasi data. Kombinasi kedua library ini memberikan fleksibilitas tinggi dalam proses Feature Engineering.
Teknik-Teknik Umum dalam Feature Engineering

Transformasi Data
Normalisasi dan Standardisasi
Normalisasi dan standardisasi adalah dua teknik penting dalam Feature Engineering yang membantu menyelaraskan skala data. Normalisasi mengubah nilai data ke dalam rentang tertentu, biasanya antara 0 hingga 1. Teknik ini sangat berguna ketika data memiliki skala yang berbeda, seperti harga dalam jutaan dan jumlah unit dalam puluhan. Dengan normalisasi, model machine learning dapat memproses data tanpa bias terhadap fitur dengan nilai yang lebih besar.
Standardisasi, di sisi lain, mengubah data sehingga memiliki rata-rata nol dan standar deviasi satu. Teknik ini sering digunakan ketika data memiliki distribusi normal. Sebagai contoh, dalam analisis data kesehatan, tinggi badan dan berat badan dapat distandardisasi agar memiliki skala yang sama. Standardisasi membantu model memahami hubungan antar fitur dengan lebih baik.
Encoding Data Kategorikal
Data kategorikal sering kali tidak dapat langsung digunakan oleh model machine learning. Encoding adalah teknik untuk mengubah data kategorikal menjadi format numerik. Salah satu metode yang umum digunakan adalah One-Hot Encoding. Teknik ini mengubah setiap kategori menjadi kolom biner, di mana nilai 1 menunjukkan keberadaan kategori tersebut.
Label Encoding adalah metode lain yang mengubah kategori menjadi angka. Misalnya, kategori "Merah", "Hijau", dan "Biru" dapat diubah menjadi 1, 2, dan 3. Teknik ini cocok untuk data dengan urutan tertentu, seperti tingkat pendidikan atau peringkat. Dengan encoding, data kategorikal menjadi lebih informatif dan dapat digunakan oleh model.
Seleksi Fitur
Seleksi Berdasarkan Korelasi
Seleksi fitur berdasarkan korelasi membantu mengidentifikasi hubungan antara fitur dan target. Fitur dengan korelasi tinggi terhadap target sering kali lebih relevan untuk analisis. Teknik ini melibatkan perhitungan koefisien korelasi, seperti Pearson atau Spearman. Sebagai contoh, dalam analisis penjualan, fitur seperti "jumlah iklan" mungkin memiliki korelasi tinggi dengan "penjualan bulanan".
Fitur dengan korelasi rendah atau tidak signifikan dapat dihapus untuk mengurangi kompleksitas data. Namun, penting untuk memastikan bahwa fitur yang dipilih tidak memiliki korelasi tinggi satu sama lain. Korelasi antar fitur yang tinggi dapat menyebabkan redundansi dan memengaruhi performa model.
Seleksi Berdasarkan Model
Seleksi fitur berdasarkan model menggunakan algoritma machine learning untuk menentukan fitur yang paling penting. Algoritma seperti Random Forest atau Gradient Boosting sering digunakan untuk tujuan ini. Model ini memberikan skor penting untuk setiap fitur berdasarkan kontribusinya terhadap prediksi.
Sebagai contoh, dalam analisis risiko kredit, fitur seperti "riwayat pembayaran" mungkin memiliki skor penting yang tinggi. Fitur dengan skor rendah dapat dihapus untuk menyederhanakan data. Teknik ini tidak hanya meningkatkan efisiensi analisis tetapi juga membantu model fokus pada informasi yang benar-benar relevan.
Pembuatan Fitur Baru
Kombinasi Fitur
Kombinasi fitur adalah teknik untuk menciptakan fitur baru dengan menggabungkan dua atau lebih fitur yang ada. Sebagai contoh, dalam analisis e-commerce, fitur "harga per unit" dapat dibuat dengan membagi "total harga" dengan "jumlah unit". Fitur ini memberikan wawasan tambahan yang tidak tersedia dalam data mentah.
Teknik ini memerlukan pemahaman mendalam tentang data dan tujuan analisis. Kombinasi fitur sering kali menghasilkan informasi yang lebih bermakna dan membantu model memahami pola yang kompleks.
Ekstraksi Fitur dari Data Waktu
Data waktu sering kali mengandung informasi yang tersembunyi. Ekstraksi fitur dari data waktu membantu mengungkap pola tersebut. Sebagai contoh, dari data tanggal, seseorang dapat membuat fitur seperti "hari dalam seminggu" atau "bulan dalam setahun". Fitur ini berguna untuk analisis musiman atau tren.
Dalam analisis transportasi, fitur seperti "jam sibuk" dapat diekstraksi dari data waktu perjalanan. Teknik ini membantu model memahami pola waktu yang memengaruhi hasil analisis. Dengan fitur yang relevan, model dapat membuat prediksi yang lebih akurat.
Contoh Penerapan Feature Engineering

Studi Kasus Feature Engineering: Prediksi Harga Rumah
Membersihkan Data dan Mengatasi Missing Values
Dalam analisis prediksi harga rumah, data mentah sering kali mengandung nilai yang hilang atau tidak konsisten. Langkah pertama adalah membersihkan data untuk memastikan kualitasnya. Misalnya, jika terdapat kolom "luas tanah" dengan nilai kosong, pengisian dapat dilakukan menggunakan rata-rata atau median dari data yang tersedia. Selain itu, data duplikat harus dihapus untuk menghindari bias dalam analisis. Proses ini memastikan bahwa data yang digunakan oleh model machine learning lebih akurat dan dapat diandalkan.
Membuat Fitur Baru dari Data Lokasi
Lokasi merupakan salah satu faktor penting dalam menentukan harga rumah. Dari data lokasi mentah, fitur baru dapat dibuat untuk memberikan informasi tambahan. Sebagai contoh, jarak rumah ke pusat kota atau aksesibilitas ke fasilitas umum seperti sekolah dan rumah sakit dapat menjadi fitur baru. Fitur ini memberikan wawasan yang lebih mendalam tentang nilai properti. Dengan fitur yang relevan, model dapat memahami hubungan antara lokasi dan harga rumah dengan lebih baik.
Menggunakan FineBI untuk Analisis dan Visualisasi
FineBI membantu dalam eksplorasi dan visualisasi data untuk analisis harga rumah. Dengan alat ini, pola dan tren dalam data dapat diidentifikasi dengan cepat. Sebagai contoh, pengguna dapat membuat grafik yang menunjukkan hubungan antara luas tanah dan harga rumah. Visualisasi ini mempermudah identifikasi fitur yang paling relevan untuk analisis. FineBI juga memungkinkan integrasi dengan berbagai sumber data, sehingga proses Feature Engineering menjadi lebih efisien.
Studi Kasus Feature Engineering: Analisis Data Penjualan
Mengelompokkan Data Berdasarkan Kategori
Dalam analisis data penjualan, pengelompokan data berdasarkan kategori membantu memahami pola pembelian. Sebagai contoh, data dapat dikelompokkan berdasarkan jenis produk atau wilayah penjualan. Pengelompokan ini memungkinkan identifikasi kategori yang paling menguntungkan. Selain itu, fitur baru seperti "total penjualan per kategori" dapat dibuat untuk memberikan wawasan tambahan. Proses ini membantu perusahaan dalam merancang strategi pemasaran yang lebih efektif.
Menggunakan Teknik Encoding untuk Data Kategorikal
Data kategorikal seperti nama produk atau wilayah sering kali tidak dapat langsung digunakan oleh model machine learning. Teknik encoding mengubah data ini menjadi format numerik yang dapat diproses oleh model. Sebagai contoh, One-Hot Encoding dapat digunakan untuk mengubah kategori produk menjadi kolom biner. Teknik ini memastikan bahwa data kategorikal menjadi lebih informatif dan relevan untuk analisis. Dengan encoding yang tepat, model dapat membuat prediksi yang lebih akurat.
Tantangan dan Solusi dalam Feature Engineering
Mengatasi Data yang Tidak Lengkap atau Tidak Konsisten
Data yang tidak lengkap atau tidak konsisten sering menjadi hambatan utama dalam Feature Engineering. Data mentah sering kali mengandung nilai yang hilang, duplikat, atau format yang tidak seragam. Hal ini dapat memengaruhi kualitas analisis dan performa model machine learning.
Untuk mengatasi tantangan ini, beberapa langkah dapat dilakukan:
- Mengisi Nilai yang Hilang
Menggunakan metode seperti imputasi rata-rata, median, atau modus untuk mengisi nilai yang hilang. Misalnya, jika kolom "usia" memiliki nilai kosong, rata-rata usia dari data yang tersedia dapat digunakan sebagai pengganti. - Menghapus Data Duplikat
Data duplikat dapat diidentifikasi dan dihapus untuk memastikan keakuratan analisis. Proses ini membantu mengurangi bias yang mungkin muncul akibat data yang berulang. - Standarisasi Format Data
Format data yang tidak seragam, seperti tanggal atau satuan ukuran, perlu diseragamkan. Sebagai contoh, semua tanggal dapat diubah ke format "YYYY-MM-DD" untuk mempermudah analisis. - Menggunakan Alat Otomasi
Alat seperti FineBI atau library Python seperti pandas dapat membantu mendeteksi dan menangani data yang tidak lengkap atau tidak konsisten dengan lebih efisien.
Menghindari Overfitting dengan Seleksi Fitur yang Tepat
Overfitting terjadi ketika model terlalu fokus pada data pelatihan sehingga kehilangan kemampuan untuk generalisasi pada data baru. Hal ini sering disebabkan oleh penggunaan terlalu banyak fitur yang tidak relevan atau redundan.
Beberapa solusi untuk menghindari overfitting meliputi:
- Seleksi Fitur Berdasarkan Korelasi
Menggunakan analisis korelasi untuk memilih fitur yang memiliki hubungan kuat dengan target. Fitur yang tidak relevan dapat dihapus untuk mengurangi kompleksitas data. - Menggunakan Algoritma Seleksi Fitur
Algoritma seperti Lasso Regression atau Random Forest dapat membantu menentukan fitur yang paling penting. Fitur dengan kontribusi rendah terhadap model dapat diabaikan. - Regularisasi Model
Teknik regularisasi seperti L1 atau L2 dapat digunakan untuk mengurangi dampak fitur yang kurang relevan. Regularisasi membantu model fokus pada fitur yang benar-benar penting. - Validasi Silang (Cross-Validation)
Validasi silang membantu mengevaluasi performa model pada data yang berbeda. Teknik ini memastikan bahwa model tidak hanya bekerja baik pada data pelatihan tetapi juga pada data baru.
Dengan seleksi fitur yang tepat, model dapat bekerja lebih efisien dan menghasilkan prediksi yang lebih akurat.
Mengelola Waktu dan Sumber Daya untuk Proses Feature Engineering
Feature Engineering sering kali memerlukan waktu dan sumber daya yang signifikan. Proses ini melibatkan eksplorasi data, pembersihan, transformasi, dan pembuatan fitur baru. Tanpa manajemen yang baik, proses ini dapat menjadi tidak efisien.
Berikut adalah beberapa strategi untuk mengelola waktu dan sumber daya:
- Prioritaskan Fitur yang Paling Relevan
Fokus pada fitur yang memiliki dampak terbesar terhadap analisis. Hal ini membantu menghemat waktu dengan menghindari eksplorasi fitur yang kurang penting. - Gunakan Alat Otomasi
Alat seperti FineBI atau library Python dapat mempercepat proses Feature Engineering. Alat ini memungkinkan eksplorasi data yang lebih cepat dan efisien. - Buat Pipeline Otomatis
Pipeline otomatis membantu mengintegrasikan langkah-langkah Feature Engineering, seperti pembersihan data, transformasi, dan seleksi fitur. Dengan pipeline, proses dapat diulang dengan mudah untuk dataset yang berbeda. - Kolaborasi Tim
Melibatkan tim dengan keahlian yang berbeda dapat mempercepat proses. Misalnya, seorang data engineer dapat fokus pada pembersihan data, sementara data scientist membuat fitur baru. - Evaluasi Secara Berkala
Evaluasi setiap langkah dalam Feature Engineering untuk memastikan efisiensi. Jika suatu langkah tidak memberikan nilai tambah, langkah tersebut dapat dihilangkan.
Manajemen waktu dan sumber daya yang baik memastikan bahwa proses Feature Engineering berjalan lancar dan memberikan hasil yang optimal.
Tips dan Strategi untuk Pemula dalam Feature Engineering
Mulai dengan Dataset yang Sederhana
Pemula sebaiknya memulai dengan dataset yang sederhana. Dataset kecil dengan jumlah fitur yang terbatas lebih mudah dipahami. Contohnya, dataset seperti "Iris" atau "Titanic" yang tersedia di berbagai platform pembelajaran data science. Dataset ini memberikan kesempatan untuk memahami dasar-dasar Feature Engineering tanpa merasa kewalahan.
Langkah pertama adalah mengeksplorasi dataset. Pemula dapat memeriksa struktur data, jenis fitur, dan distribusi nilai. Proses ini membantu mengenali pola awal dalam data. Setelah itu, fokus pada fitur yang relevan untuk tujuan analisis. Misalnya, dalam dataset Titanic, fitur seperti "usia" dan "jenis kelamin" relevan untuk memprediksi kelangsungan hidup penumpang.
Gunakan Alat seperti FineBI untuk Eksplorasi Data
Alat seperti FineBI sangat membantu dalam eksplorasi data. FineBI menyediakan visualisasi interaktif yang mempermudah pemahaman pola dalam data. Pemula dapat menggunakan grafik dan diagram untuk mengidentifikasi fitur yang relevan. Misalnya, grafik batang dapat menunjukkan distribusi kategori dalam data, sementara scatter plot membantu memahami hubungan antar fitur.
FineBI juga mendukung integrasi dengan berbagai sumber data. Pemula dapat mengimpor dataset dari file Excel, database, atau API. Proses ini mempercepat eksplorasi data tanpa memerlukan banyak pengetahuan teknis. Selain itu, FineBI memungkinkan pengguna untuk membersihkan data dengan mudah, seperti menghapus duplikat atau mengisi nilai yang hilang.
Pelajari Teknik Dasar Sebelum Mencoba Teknik Lanjutan
Pemula sebaiknya fokus pada teknik dasar sebelum mencoba teknik lanjutan. Teknik dasar seperti normalisasi, standardisasi, dan encoding data kategorikal adalah fondasi dari Feature Engineering. Teknik ini membantu menyelaraskan data sehingga lebih mudah diproses oleh model machine learning.
Sebagai contoh, normalisasi mengubah nilai data ke dalam rentang tertentu, seperti 0 hingga 1. Teknik ini penting ketika data memiliki skala yang berbeda. Encoding data kategorikal, seperti One-Hot Encoding, mengubah kategori menjadi format numerik yang dapat digunakan oleh model. Teknik-teknik ini memberikan pemahaman awal tentang bagaimana data dapat diubah menjadi lebih informatif.
Setelah menguasai teknik dasar, pemula dapat mulai mempelajari teknik lanjutan seperti seleksi fitur berdasarkan model atau pembuatan fitur baru. Namun, pemahaman yang kuat tentang dasar-dasar akan mempermudah proses belajar teknik lanjutan.
Bagaimana FineBI Mendukung Proses Feature Engineering?
Eksplorasi Data yang Cepat dan Mudah
FineBI mempermudah eksplorasi data dengan menyediakan antarmuka yang intuitif. Pengguna dapat dengan cepat mengimpor dataset dari berbagai sumber, seperti file Excel, database, atau API. Proses ini memungkinkan analisis data tanpa memerlukan keahlian teknis yang mendalam. FineBI juga mendukung pengelompokan data berdasarkan kategori tertentu, sehingga pengguna dapat memahami struktur data dengan lebih baik.
Fitur drag-and-drop pada FineBI mempercepat proses eksplorasi. Pengguna dapat memilih kolom data yang relevan dan langsung melihat hasilnya dalam bentuk tabel atau grafik. Dengan cara ini, pola awal dalam data dapat diidentifikasi tanpa memerlukan banyak langkah manual. FineBI juga memungkinkan pengguna untuk menyaring data berdasarkan kriteria tertentu, seperti rentang nilai atau kategori spesifik.
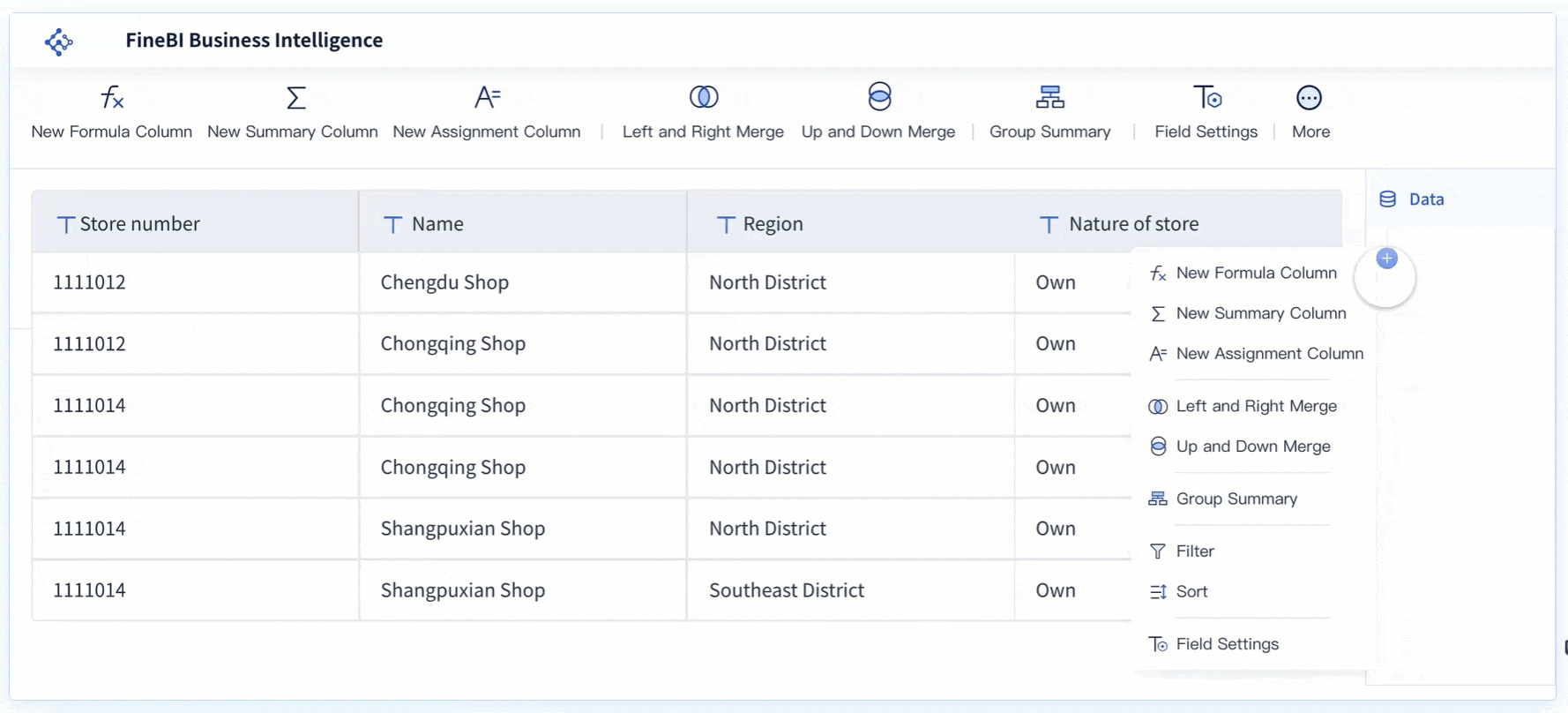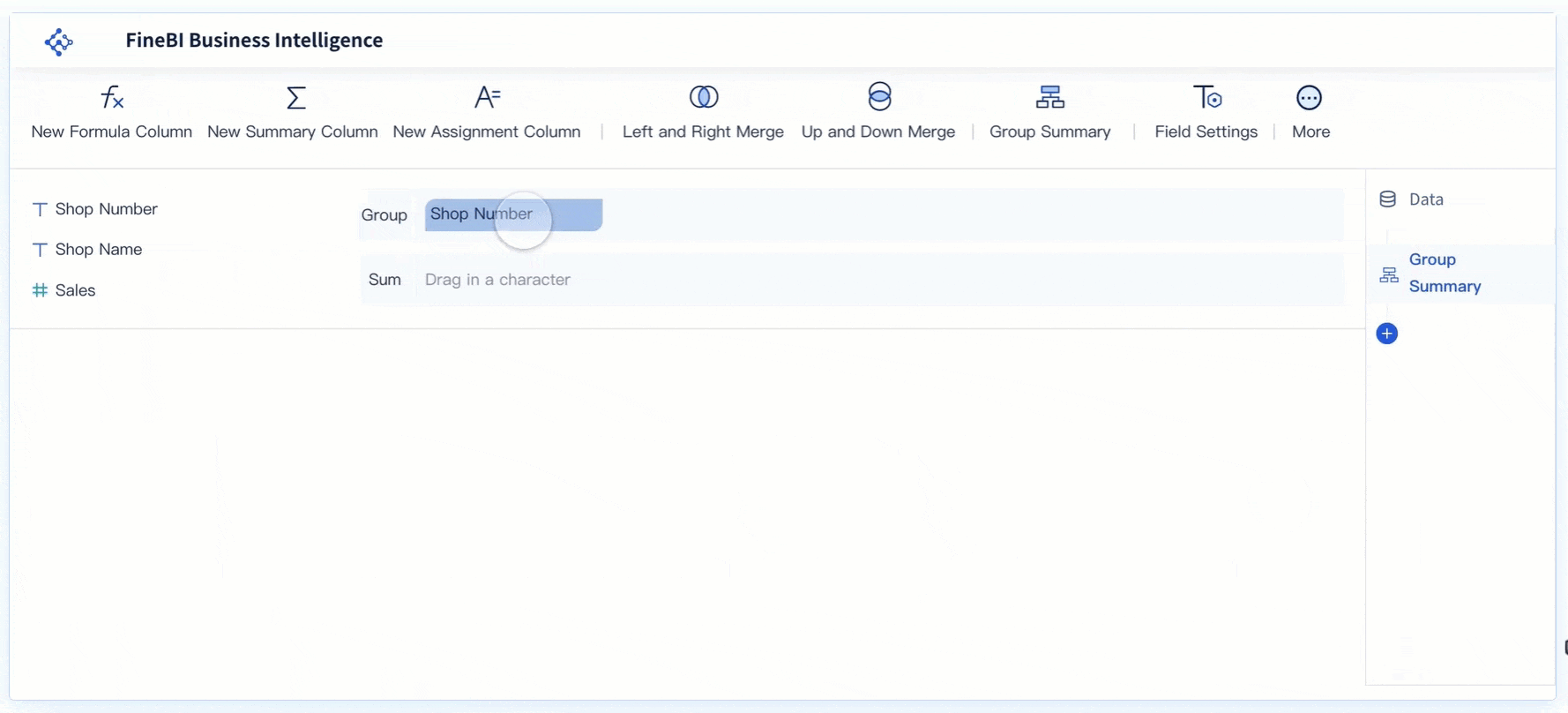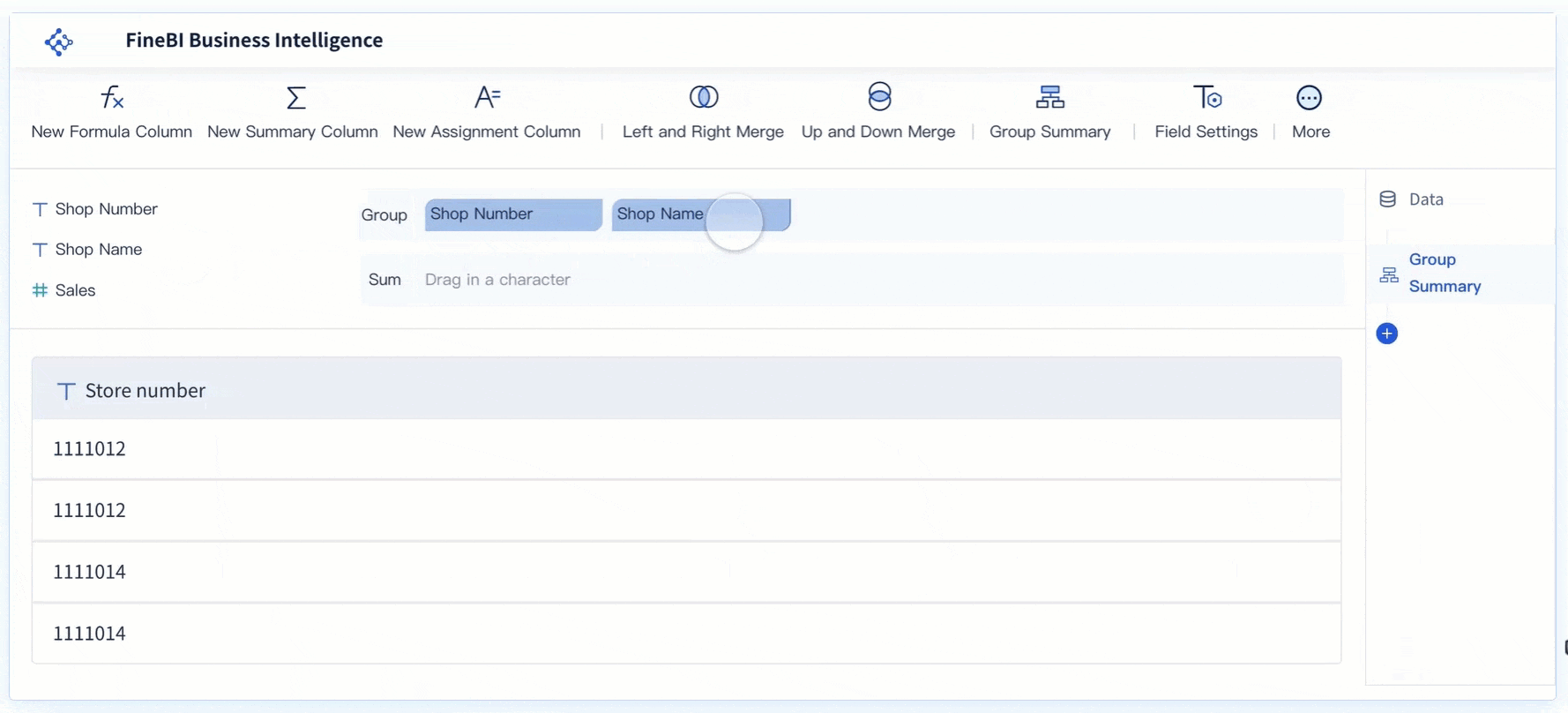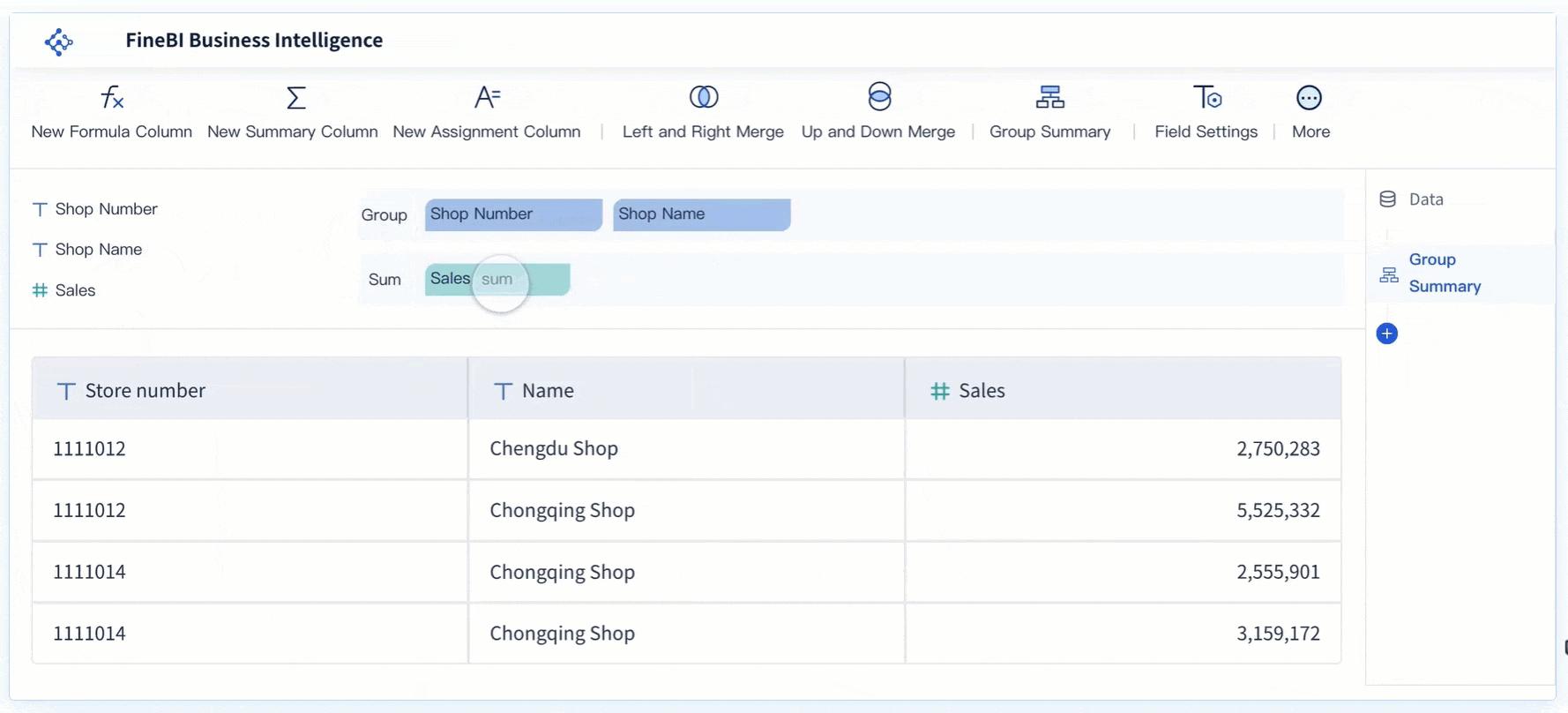
Visualisasi untuk Memahami Pola dan Tren Data
FineBI menyediakan berbagai opsi visualisasi yang membantu pengguna memahami pola dan tren dalam data. Grafik batang, garis, dan pie chart adalah beberapa contoh visualisasi yang dapat dibuat dengan mudah. Visualisasi ini memberikan gambaran yang lebih jelas tentang hubungan antar fitur dalam dataset.
Pengguna dapat memanfaatkan heatmap untuk melihat korelasi antar fitur. Misalnya, dalam analisis penjualan, heatmap dapat menunjukkan hubungan antara jumlah iklan dan total penjualan. Scatter plot juga berguna untuk mengidentifikasi pola distribusi data. Dengan visualisasi ini, pengguna dapat menentukan fitur mana yang paling relevan untuk analisis lebih lanjut.
FineBI juga mendukung visualisasi interaktif. Pengguna dapat menggali lebih dalam dengan mengklik elemen tertentu dalam grafik untuk melihat detailnya. Fitur ini membantu dalam proses pengambilan keputusan yang lebih informatif.
Integrasi dengan Alat Lain untuk Analisis Lanjutan
FineBI mendukung integrasi dengan berbagai alat analisis lainnya, seperti Python, R, dan database populer. Integrasi ini memungkinkan pengguna untuk menggabungkan kekuatan FineBI dengan alat lain untuk analisis yang lebih mendalam. Sebagai contoh, pengguna dapat membersihkan data di Python menggunakan pandas, lalu mengimpor data tersebut ke FineBI untuk visualisasi.
FineBI juga mendukung koneksi langsung ke database seperti MySQL, PostgreSQL, dan SQL Server. Dengan koneksi ini, pengguna dapat mengakses data secara real-time tanpa perlu mengunduh atau memindahkan file. Hal ini sangat berguna untuk analisis data yang terus diperbarui, seperti data penjualan harian atau data sensor IoT.

Selain itu, FineBI memungkinkan pengguna untuk mengekspor hasil analisis ke format yang kompatibel dengan alat lain. Misalnya, hasil visualisasi dapat diekspor ke Excel untuk laporan atau ke PDF untuk presentasi. Dengan fleksibilitas ini, FineBI menjadi alat yang ideal untuk mendukung seluruh proses Feature Engineering.
Feature Engineering menjadi langkah krusial dalam machine learning. Proses ini meningkatkan kualitas data dan membantu model menghasilkan performa yang lebih baik. Dasar-dasar Feature Engineering mencakup pemahaman data, pembersihan, pembuatan fitur baru, serta seleksi fitur yang relevan. FineBI memberikan kemudahan dalam eksplorasi dan analisis data, sehingga mendukung proses ini secara efisien. Pembaca disarankan untuk terus berlatih menggunakan dataset sederhana. Pendekatan ini akan memperkuat pemahaman dan keterampilan dalam menerapkan teknik Feature Engineering.
Lihat juga tentang Feature Engineering
Pengertian Data Lake Dan Pentingnya Dalam Analisis
Pengurangan Data: Teknik Dan Manfaatnya
Mengenal Konsep Data Lake Dalam Penyimpanan
FAQ
Feature Engineering adalah proses mengubah data mentah menjadi fitur yang lebih bermakna dan relevan untuk analisis. Proses ini melibatkan manipulasi, transformasi, dan pembuatan fitur baru agar data lebih informatif bagi model machine learning.
Feature Engineering penting karena menentukan kualitas data yang digunakan oleh model. Fitur yang relevan dan informatif membantu model membuat prediksi yang lebih akurat. Selain itu, proses ini juga mengurangi kompleksitas data, sehingga analisis menjadi lebih efisien.
Feature Engineering berfokus pada pembuatan dan transformasi fitur untuk meningkatkan kualitas data. Data Cleaning, di sisi lain, bertujuan untuk menghapus noise, menangani missing values, dan memastikan data konsisten. Keduanya saling melengkapi dalam mempersiapkan data untuk analisis.
Beberapa teknik umum dalam Feature Engineering meliputi:
Seleksi fitur adalah proses memilih fitur yang paling relevan untuk analisis. Proses ini penting untuk mengurangi dimensi data, meningkatkan efisiensi analisis, dan menghindari overfitting pada model machine learning.
Beberapa cara untuk menangani data yang tidak lengkap meliputi:
- Imputasi Nilai yang Hilang: Menggunakan rata-rata, median, atau modus untuk mengisi nilai kosong.
- Menghapus Data yang Tidak Lengkap: Jika data yang hilang terlalu banyak, penghapusan dapat menjadi solusi.
- Menggunakan Alat Otomasi: Alat seperti pandas atau FineBI dapat membantu menangani data yang tidak lengkap dengan lebih efisien.
FineBI mempermudah eksplorasi dan visualisasi data. Alat ini membantu pengguna memahami pola dan tren dalam data dengan cepat. Selain itu, FineBI mendukung integrasi dengan berbagai sumber data, sehingga mempercepat proses Feature Engineering.
Feature Engineering tidak hanya digunakan dalam machine learning. Proses ini juga bermanfaat dalam analisis data tradisional, seperti statistik atau business intelligence. Dengan fitur yang relevan, analisis data menjadi lebih efektif dan informatif.
Pemula dapat memulai dengan langkah berikut:
Tantangan terbesar dalam Feature Engineering meliputi:

Lanjutkan Membaca Tentang Feature Engineering
10 Tools Terbaik Untuk Analisis Data
Kita akan mempelajari apa alat analisis data, cara memilih software ang tepat, dan 10 alat dan software analisis data terbaik yang tersedia di pasar.
Lewis
2024 Agustus 07
Analisis Data Deskriptif: Kualitatif vs Kuantitatif
Analisis data deskriptif: Bandingkan metode kualitatif dan kuantitatif, pahami karakteristik, teknik, dan aplikasi dalam penelitian sosial dan bisnis.
Lewis
2024 September 06
Analisis Data Eksplorasi (EDA): Arti, Manfaat, dan Contohnya
Dalam artikel ini, kami akan menjelaskan apa itu Analisis Data Eksplorasi, memperkenalkan tiga jenis EDA dan cara melakukannya!
Lewis
2024 Agustus 05
Analisis Data Kuantitatif : Arti, Penerapan, dan Studi Kasus
Analisis data kuantitatif adalah evaluasi data numerik menggunakan statistik untuk menemukan pola, tren, dan wawasan guna mendukung pengambilan keputusan.
Lewis
2024 September 05
Analisis Data: Salah Satu Bentuk Analisis Data Dasar Adalah
Salah satu bentuk analisis data dasar adalah analisis statistik, penting untuk strategi bisnis efektif dan pengambilan keputusan yang tepat.
Lewis
2024 Desember 15
Analisis Data Kualitatif: Teknik Paling Efektif
Pelajari cara memilih teknik analisis data kualitatif yang tepat untuk penelitian Anda, termasuk teknik berbasis teks dan observasi serta alat analisis.
Lewis
2024 September 02

