漫谈数据挖掘模型,看了大有启发!
可视化分析大数据分析的使用者有大数据分析专家,同时还有普通用户,但是他们二者对于大数据分析最基本的要求就是可视化分析,因为可视化分析能够直观的呈现大数据特点,同时能够非常容易被读者所接受,就如同看图说话一样简单明了。
数据挖掘模型算法大数据分析的理论核心就是数据挖掘模型算法,各种数据挖掘的算法基于不同的数据类型和格式才能更加科学的呈现出数据本身具备的特点,也正是因为这些被全世界统计 学家所公认的各种统计方法(可以称之为真理)才能深入数据内部,挖掘出公认的价值。另外一个方面也是因为有这些数据挖掘的算法才能更快速的处理大数据,如 果一个算法得花上好几年才能得出结论,那大数据的价值也就无从说起了。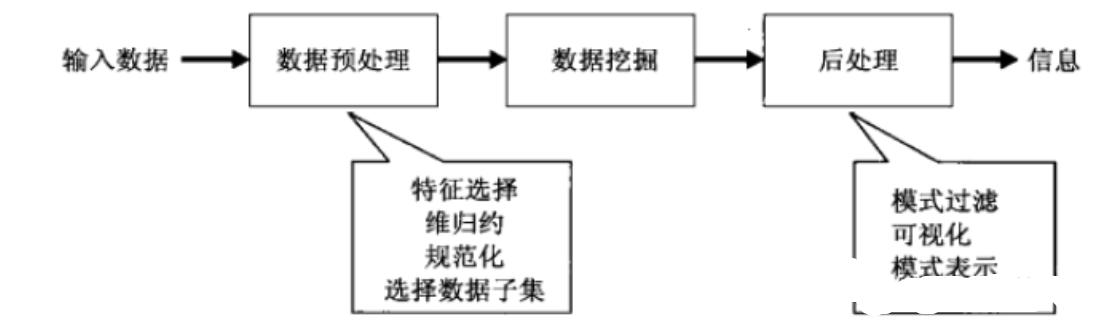
数据挖掘模型: 分类 (Classification)、估计(Estimation)、预测(Prediction)、相关性分组或关联规则(Affinity grouping or association rules)、聚类(Clustering)、描述和可视化、Description and Visualization)、复杂数据类型挖掘(Text, Web ,图形图像,视频,音频等)模型预测 :预测模型、机器学习、建模仿真。
结果呈现: 云计算、标签云、关系图等。
数据挖掘一般没有什么预先设定好的主题,主要是在现有数 据上面进行基于各种常用数据挖掘算法的计算,从而起到预测(Predict)的效果,从而实现一些高级别数据分析的需求。比较典型算法有用于聚类的Kmeans、用于 统计学习的SVM和用于分类的NaiveBayes,主要使用的工具有Hadoop的Mahout等。该过程的特点和挑战主要是用于常用数据挖掘算法很复杂,并 且计算涉及的数据量和计算量都很大,常用数据挖掘算法都以单线程为主。整个大数据处理的普遍流程至少应该满足这四个方面的大数据处理步骤,才能算得上是一个比较完整的大数据处理。






 立即沟通
立即沟通

