数据预处理的处理缺失值怎么做?看完你就知道了!
任何仪器分析之前都要样品预处理,数据也是如此。经过预处理的数据,能够使数据深度挖掘的分析结果更加高效且准确。同时,数据预处理的方法在数据深度挖掘之前使用,大大提高了数据深度挖掘模式的质量,降低实际挖掘所需要的时间。
数据预处理的常用流程为:去除唯一属性、处理缺失值、属性编码、数据标准化正则化、特征选择、主成分分析。
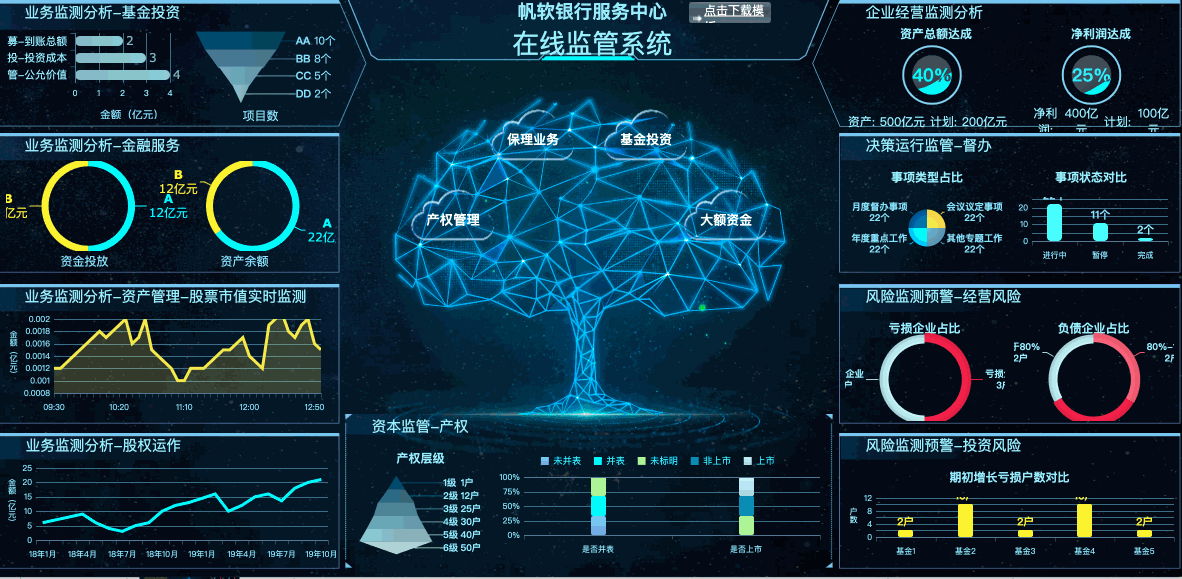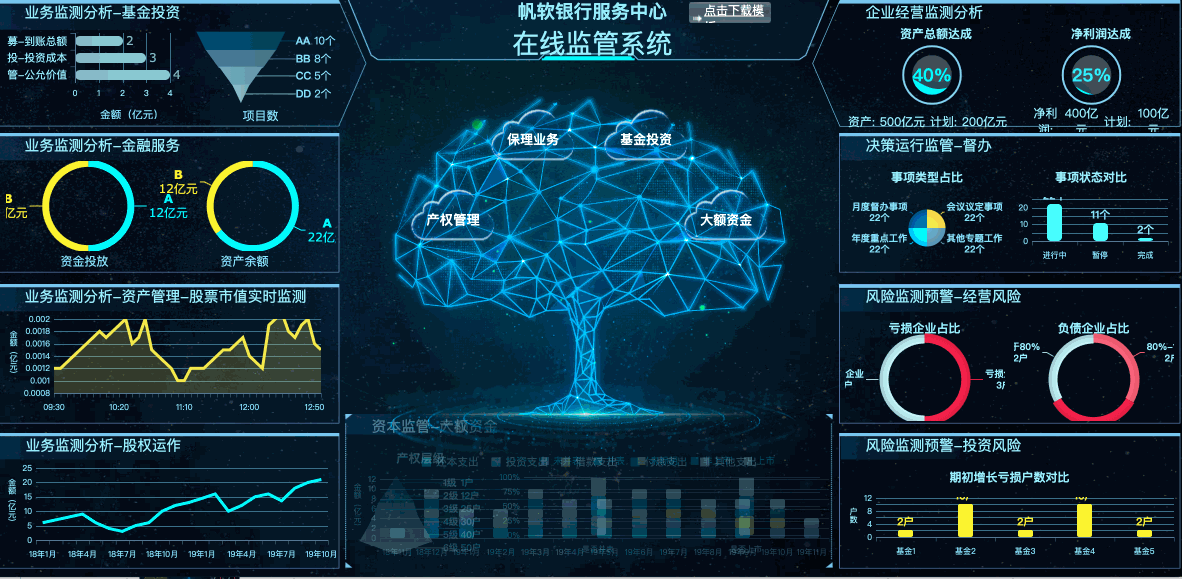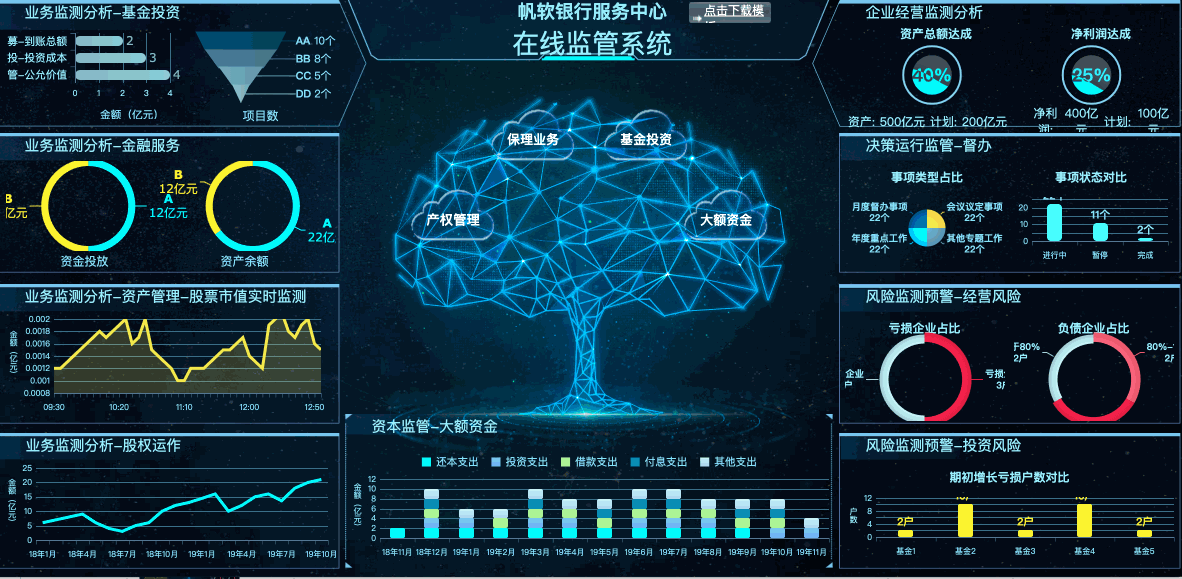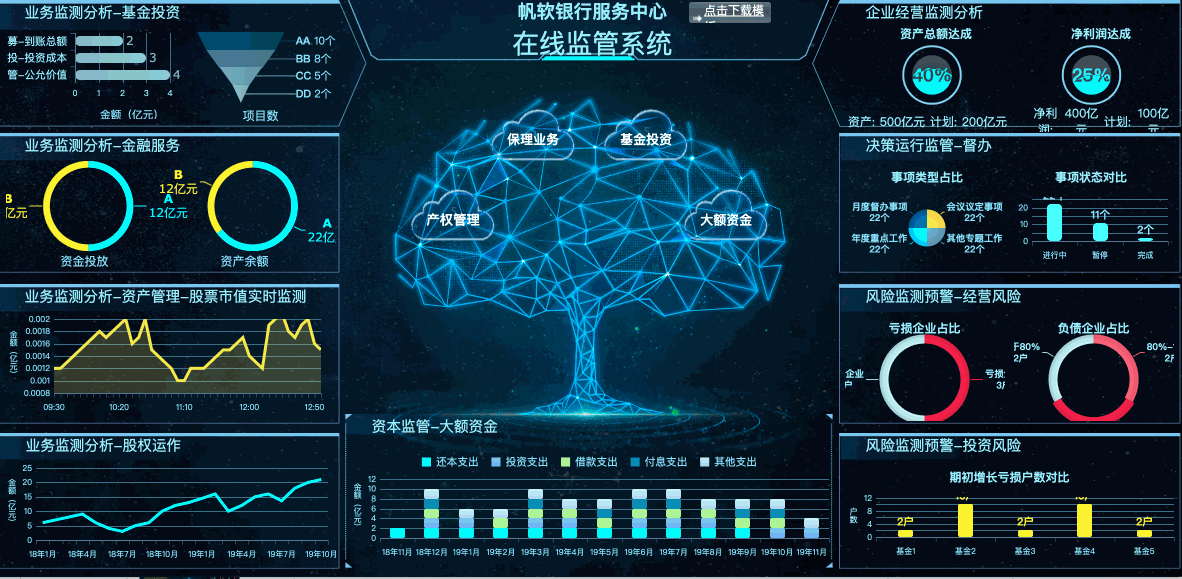
下面就简单讲述一下数据预处理的流程中较为重要的“处理缺失值”:
处理缺失值的三种方法:直接使用含有缺失值的特征;删除含有缺失值的特征(该方法在包含缺失值的属性含有大量缺失值而仅仅包含极少量有效值时是有效的);缺失值补全。
常见的缺失值补全方法:均值插补、同类均值插补、建模预测、高维映射、多重插补、极大似然估计、压缩感知和矩阵补全。
(1)均值插补
如果样本属性的距离是可度量的,则使用该属性有效值的平均值来插补缺失的值;
如果的距离是不可度量的,则使用该属性有效值的众数来插补缺失的值。如果使用众数插补,出现数据倾斜会造成什么影响?
(2)同类均值插补
首先将样本进行分类,然后以该类中样本的均值来插补缺失值。
(3)建模预测
将缺失的属性作为预测目标来预测,将数据集按照是否含有特定属性的缺失值分为两类,利用现有的机器学习算法对待预测数据集的缺失值进行预测。
该方法的根本的缺陷是如果其他属性和缺失属性无关,则预测的结果毫无意义;但是若预测结果相当准确,则说明这个缺失属性是没必要纳入数据集中的;一般的情况是介于两者之间。
(4)高维映射
将属性映射到高维空间,采用独热码编码(one-hot)技术。将包含K个离散取值范围的属性值扩展为K+1个属性值,若该属性值缺失,则扩展后的第K+1个属性值置为1。
这种做法是最精确的做法,保留了所有的信息,也未添加任何额外信息,若预处理时把所有的变量都这样处理,会大大增加数据的维度。这样做的好处是完整保留了原始数据的全部信息、不用考虑缺失值;缺点是计算量大大提升,且只有在样本量非常大的时候效果才好。
(5)多重插补(MultipleImputation,MI)
多重插补认为待插补的值是随机的,实践上通常是估计出待插补的值,再加上不同的噪声,形成多组可选插补值,根据某种选择依据,选取最合适的插补值。
(6)手动插补
插补处理只是将未知值补以我们的主观估计值,不一定完全符合客观事实。在许多情况下,根据对所在领域的理解,手动对缺失值进行插补的效果会更好。






 立即沟通
立即沟通

