一篇读懂数据仓库的演进与发展
是不是所有企业都必须要建设数据仓库?
是不是建设了数仓,数据底层的建设就一步到位、数据就高枕无忧了?
答案是不一定。企业在不同的发展阶段,对数据底层建设的需求不一样。数据建设没有万能的公式,只有最适合企业自身的解决方案。本文基于此,介绍了数据仓库的演进与发展历程。
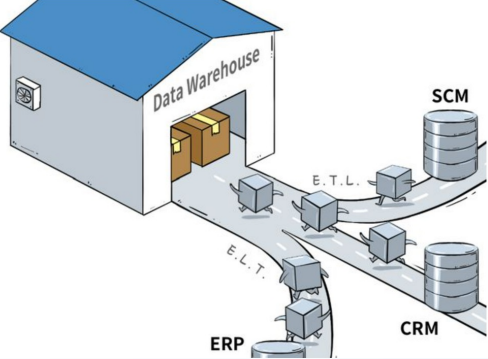
数据仓库的演进历程
1. 直读阶段:企业在信息化建设初期数据量小,结构简单,就可以通过植入数据库的方式快速应用数据。但是随着系统的数据量变大,业务扩展变多,读写频率变高,业务库的压力就会变得越来越大,会影响到业务系统本身的使用和效率。

2. 中间库阶段:为了解决以上问题,企业会建立中间数据库来进行读写分离,将数据进行预处理或常规的离线处理,这个就是我们常说的数据库ETL开发。在中间库阶段,改造成本低,数据库ETL开发简单,数据应用效率提升却非常明显。
但是随着业务交叉越来越多,需求也越来越多,数据库ETL开发逐渐力不从心。由于中间库没有进行统一的整合管理,成果就没有办法进行复用。而且中间库的扩展性较差,进行改造也比较困难。

3. 数据仓库阶段:
通常中小企业会以满足业务发展为目的,建设独立数据集市架构或者集中式架构。独立数据集市架构可以进行小型数仓的搭建,但随着业务系统越建越多,产生了多系统、多主题数据不一致的问题。
为了解决信息孤岛,企业开始在各个独立的数据集市架构间建立一些对照表进行数据交换,于是产生了联邦式数据仓库架构。联邦架构的缺点也很明显,除非建立之初就采用类似总线架构的方法实现数据一致,否则很容易出现数据不一致,导致整合不彻底。
此时需要通过集中式架构把所有业务库的数据集中在一个数仓里,然后对数据进行分层应用。集中式数仓的优点如下:
· 数据融合:消灭系统孤岛,快速构建数据中心。
· 数据治理:统一数据口径、规范、标准。
· 减少工作量:提供统一服务,避免重复工作,降低前后端互通成本。

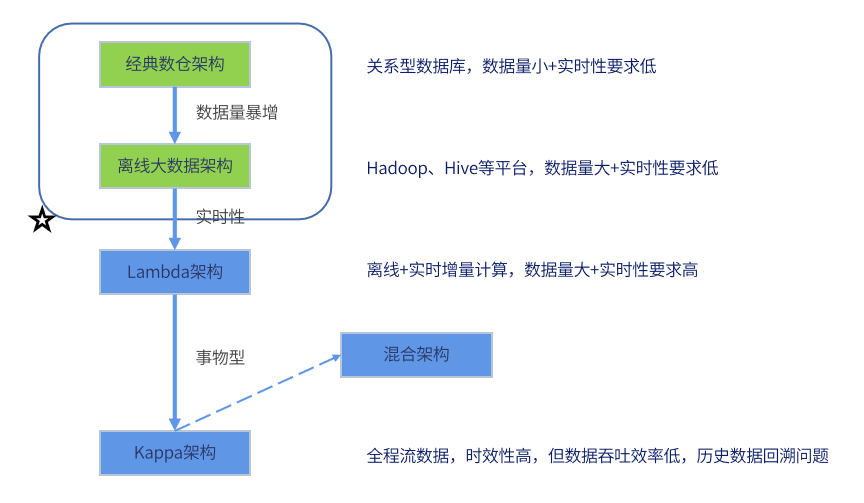
数据仓库的发展历程
1. 经典数仓架构:在这个阶段数据库的量级不大,对于实时性的要求也不高。
2. 离线大数据架构:当数据量逐渐膨胀,关系型数据库满足不了大数据量的计算时,信息部门往往会将存储数据库从关系型数据库过渡到大数据平台。
3. Lambda架构。当企业有实时性要求时,就要在原来离线数仓的基础上增加实时计算的链路。在Lambda架构中,我们会通过任务批处理来提供全面且准确的数据,从而达到平衡延迟吞吐量和容错率的目的。
4. Kappa架构:Kappa架构满足了实时的流计算要求,统一了数据口径,时效性非常高。但是由于它需要计算全量数据,所以数据吞吐效率较低,有必要时才会对所有的历史数据进行重复计算。
帆软软件推出的FineDataLink是一款中国领先的低代码/高时效数据仓库ETL工具,在构建数据仓库时具有以下优势:
1. 支持多种数据源:帆软FDL支持关系型数据库、非关系型数据库、接口类型数据和文本数据等多种数据源,可以将多种异构数据源一键接入到数据平台中。
2. 灵活的数据仓库ETL开发和任务引擎:帆软FDL提供灵活的数据仓库ETL开发和任务引擎,可以为上层应用预先处理数据,帮助企业处理出质量更高、更利于展示与分析的数据。
3. 自助化的数据调度与治理平台:帆软FDL提供开放的、一站式、标准化、可视化、高性能和可持续交付的自助化数据调度与治理平台,帮助企业打破数据孤岛,大幅激活企业业务潜能,使数据成为生产力。







 立即沟通
立即沟通

