多源异构数据源融合怎么做呢,今天跟大家分享分享:
多源异构数据来自多个数据源,包括不同数据库系统和不同设备在工作中采集的数据集等。不同的数据源所在的操作系统、管理系统不同,数据的存储模式和逻辑结构不同,数据的产生时间、使用场所、代码协议等也不同,这造成了数据“多源”的特征。
但总的来说,多源异构数据分为3种:结构化数据、半结构化数据和非结构化数据。
- 结构化数据指关系模型数据,即以关系数据库表形式管理的数据;
- 半结构化数据指非关系模型的、有基本固定结构模式的数据,例如日志文件、XML文档、JSON文档、E-mail等;
- 非结构化数据指没有固定模式的数据,比如说WORD、PDF、PPT、EXCEL及各种格式的图片、视频等。
- 不同类型的数据在形成过程中没有统一的标准,因此造成了数据“异构”的特征。
针对多元化的结构化数据融合,主要关注在数据的ETL处理 以及时效性上:
1、表结构不同,需要做到不同类型的字段映射
2、假如要新增表字段的时候,需要新增列
3、若有表字段需要进行二次处理规范,需要支持字段转换,比如公式或其他
4、新增表设计时,需要保证三大范式,这里就不展开讲了:(5条消息) 数据库三大范式_凉_ting的博客-CSDN博客_数据库三范式
5、数据同步的时效性,例如半小时一次、或者一天一次、或者说是需要实时同步融合,这个要根据具体业务场景来确认。
然而针对半结构、非结构化的数据的利用则没有那么好,因为数据分散,甚至没有统一的进行管理。
目前有两种方式来处理半结构、非结构化数据:
1、提取半结构、非结构化数据种的关键信息到结构化数据中进行二次利用,比较好处理的是半结构化(json、xml)、excel、csv,因为这种数据的结构比较统一。
2、向word、PDF这种文件的关键信息提取,假如是单个文本的话,市面上可能有些工具可能实现,但假如是大批量的话,可能就需要通过程序,去自定义一些正则表达式,去进行关键信息的提取。这种一般来说,因为 格式不一致,以及用途不一致,所以程序自定义的比较多。
针对这种的话,会综合考虑数据价值和投入产出比,因为这部分的数据处理较为复杂。
另外,如若这部分历史文件的需要做到备份的话,会通过FTP或者SFTP将文件进行备份存储到文件服务器,进行文件业务分类、文件名、路径的统一管理,提供统一入口,通过权限管理的方式给到大家下载使用。
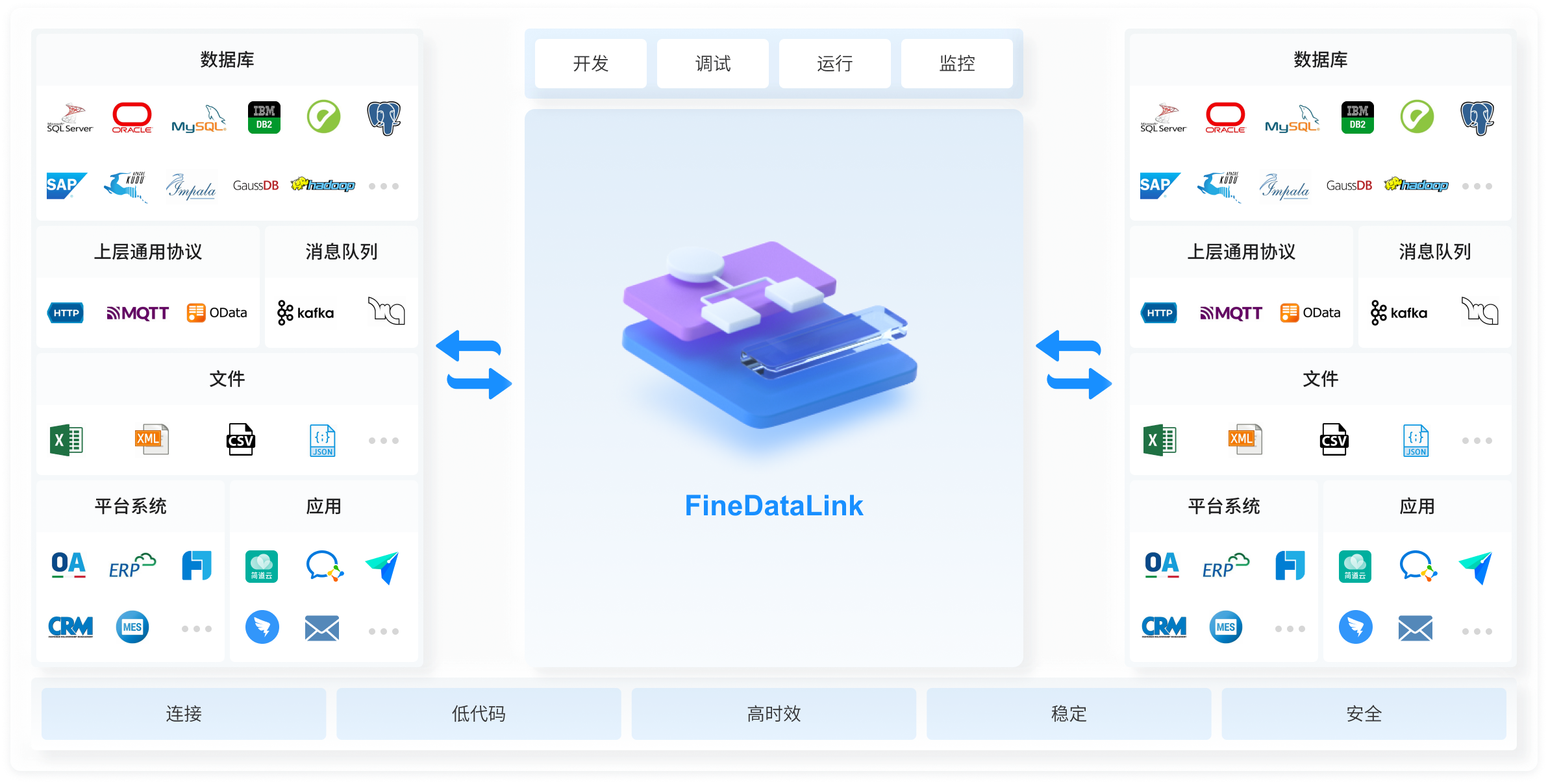
FineDataLink可以支持结构化和半结构化数据的融合集成,面向ETL数据处理场景,让数据编排更加简单,提高数据的使用价值。
总而言之,在数字化时代下,大数据治理对企业数据建设的重要性不言而喻,然而实现的困难有时也让人望而却步,因此选择合适的技术和工具会达到事半功倍的效果。帆软FineDataLink——中国领先的低代码/高时效数据集成产品,能过为企业提供一站式的数据服务,通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。




 立即沟通
立即沟通