实时数仓和离线数仓的区别是什么,企业该如何选择合适的数仓架构?
实时数仓和离线数仓都是数据仓库的不同类型,用于存储和管理企业的数据,但它们在数据处理和使用的时间、速度以及用途方面有明显的区别。
在介绍实时数仓之前,我们理应先来了解一下传统的离线数仓。毕竟在企业早期的数据建设规划中,在数据实时性要求不高的前提下,基本一开始都会选择建设离线数仓。
一、离线数仓
1. 离线数仓是什么?
离线数仓(Offline Data Warehouse)是一个用于存储和处理批处理数据的系统。它的特点是数据的处理和分析是基于批处理作业进行的,通常以较长的时间周期为单位。传统离线数仓的数据时效性是 T+1,调度频率以天为单位,无法支撑实时场景的数据需求。即使能将调度频率设置成小时,也只能解决部分时效性要求不高的场景,对于实效性要求很高的场景还是无法优雅的支撑。
2. 离线数仓的特点
- 批处理:离线数仓通过批处理作业处理数据,这意味着数据在一定时间周期内收集、存储,然后一次性处理。
- 高容量:离线数仓通常设计用于存储大量历史数据。
- 延迟较高:由于数据处理是批处理的,因此离线数仓不适合需要实时或近实时数据的应用。
3. 离线数仓的适用场景
- 需要进行历史数据分析、报告生成的应用,如销售报告、月度财务报表等。
- 数据量较大且处理时间不是关键问题的应用。
但是随着企业的发展,数据量日益增大,传统数据的方案在时效性上和数据维护上变得越来越困难。这时,实时数仓应运而生。
二、实时数仓
1. 实时数仓是什么?
实时数仓(Real-time Data Warehouse)是一个用于存储和处理实时数据的系统。它的主要特点是数据的处理和分析是即时进行的,数据几乎立即进入数仓并可以立即用于分析和决策。
2. 实时数仓的特点
- 低延迟:实时数仓能够在数据产生后迅速将其捕捉和处理,通常以秒或亚秒级的速度。
- 数据流处理:实时数仓通常使用流式处理技术来处理数据,这允许数据在进入仓库时立即进行转换和计算。
- 实时分析:数据可以用于实时监控、仪表板、预测和决策支持。
- 高吞吐量:实时数仓需要处理大量的数据流,因此需要具备高吞吐量的性能。
- 复杂性:由于需要处理实时数据流,实时数仓的架构和技术通常比较复杂。
3. 实时数仓的适用场景
- 需要实时监控业务指标的应用,如金融交易看板、实时销售报表、在线广告投放分析等。
- 需要立即采取行动以应对实时事件的应用,如异常监测大屏、欺诈实时检测等。
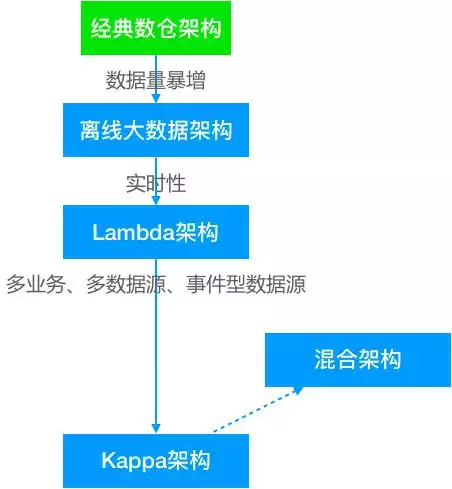
三、由数仓需求变化带来的数据仓库架构的演变
从1990年 Inmon 提出数据仓库概念到今天,数仓架构经历了最初的传统数仓架构、离线大数据架构、Lambda 架构、Kappa 架构以及由Flink 的火热带出的流批一体架构,数据架构技术不断演进,本质是在往流批一体的方向发展,让用户能以最自然、最小的成本完成实时计算。
1. 传统数仓架构

这是比较传统的一种方式,结构或半结构化数据通过离线ETL定期加载到离线数仓,之后通过计算引擎取得结果,供前端使用。这里的离线数仓+计算引擎,通常是使用大型商业数据库来承担,例如Oracle、DB2、Teradata等。
2. 离线大数据架构
随着数据规模的不断增大,传统数仓方式难以承载海量数据。随着大数据技术的普及,采用大数据技术来承载存储与计算任务。数据源通过离线的方式导入到离线数仓中。下游应用根据业务需求选择直接读取 DM 或加一层数据服务,比如 MySQL 或 Redis。
数据仓库从模型层面分为三层:
- ODS,操作数据层,保存原始数据;
- DWD,数据仓库明细层,根据主题定义好事实与维度表,保存最细粒度的事实数据;
- DM,数据集市/轻度汇总层,在 DWD 层的基础之上根据不同的业务需求做轻度汇总;
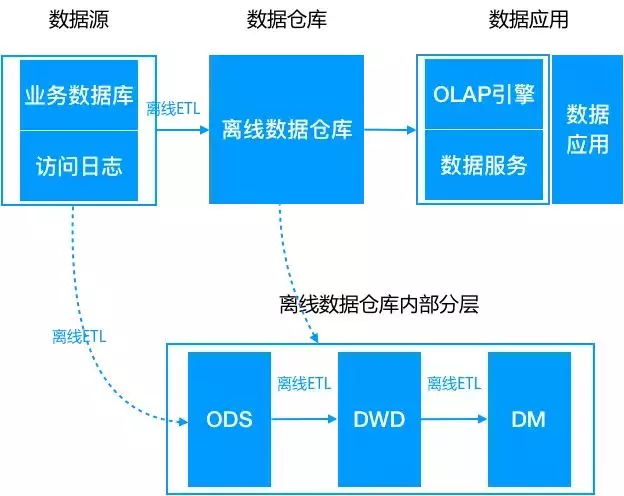
当然,也可以使用传传统数据库集群或MPP架构数据库来完成。例如Hadoop+Hive/Spark、Oracle RAC、GreenPlum等。
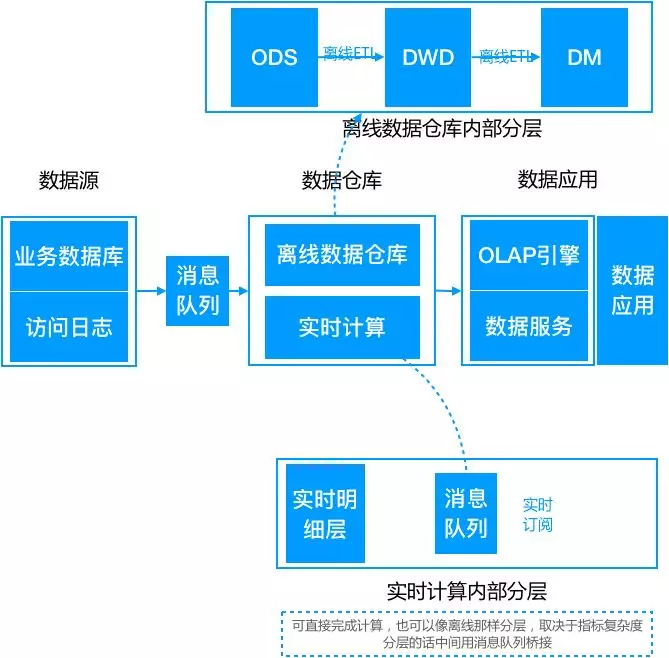
3. Lambda架构
随着业务的发展,随着业务的发展,人们对数据实时性提出了更高的要求。此时,出现了Lambda架构,其将对实时性要求高的部分拆分出来,增加条实时计算链路。从源头开始做流式改造,将数据发送到消息队列中,实时计算引擎消费队列数据,完成实时数据的增量计算。与此同时,批量处理部分依然存在,实时与批量并行运行。最终由统一的数据服务层合并结果给于前端。一般是以批量处理结果为准,实时结果主要为快速响应。
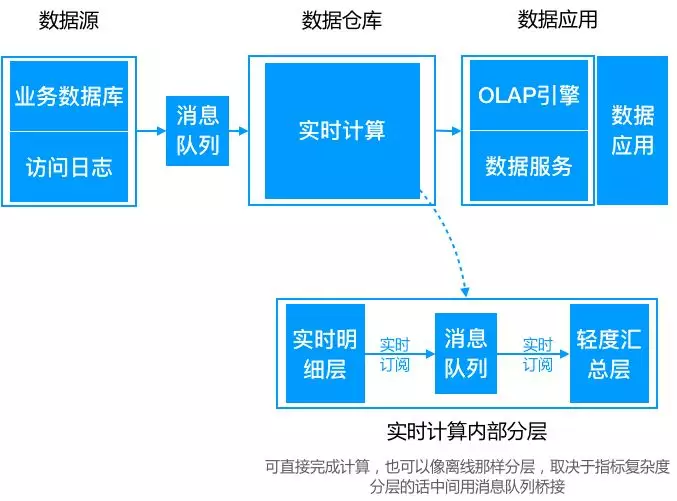
4. Kappa架构
而Lambda架构,一个比较严重的问题就是需要维护两套逻辑。一部分在批量引擎实现,一部分在流式引擎实现,维护成本很高。此外,对资源消耗也较大。随后诞生的Kappa架构,正是为了解决上述问题。其在数据需要重新处理或数据变更时,可通过历史数据重新处理来完成。方式是通过上游重放完成(从数据源拉取数据重新计算)。
可Kappa架构最大的问题是流式重新处理历史的吞吐能力会低于批处理,但这个可以通过增加计算资源来弥补。
5. 混合架构
上述架构各有其适应场景,有时需要综合使用上述架构组合满足实际需求。当然这也必将带来架构的复杂度。用户应根据自身需求,有所取舍。在一般大多数场景下,是可以使用单一架构解决问题。现在很多产品在流批一体、海量、实时性方面也有非常好的表现,可以考虑这种“全能手”解决问题。
四、实时数仓和离线数仓的思考与总结
通常,企业可能会同时使用实时数仓和离线数仓来满足不同的需求,以确保能够有效地处理各种类型的数据。这种情况下,这两者可能会集成,以充分利用它们的优势。
另外想说明的是实时数仓方案并不是“搬过来”,而是根据业务“演化来”的,具体设计的时候需要根据企业自身业务情况,找到最适合自己当下的数仓架构。
帆软为数仓建设提供生产力工具,若想了解更多数据仓库建设解决方案,请点击:《帆软数据仓库和商业智能解决方案》,另可获取各行业全业务场景数仓搭建案例及资料。



 立即沟通
立即沟通