数据处理方式怎么了解?一文速通数据处理!
什么是大数据:大数据(bigdata),指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
是
大数据的5V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
是
大数据处理流程:
1.是数据采集,搭建数据仓库,数据采集就是把数据通过前端埋点,接口日志调用流数据,数据库抓取,客户自己上传数据,把这些信息基础数据把各种维度保存起来,感觉有些数据没用(刚开始做只想着功能,有些数据没采集,后来被老大训了一顿)。
是
2.数据清洗/预处理:就是把收到数据简单处理,比如把ip转换成地址,过滤掉脏数据等。
是
3.有了数据之后就可以对数据进行加工处理,数据处理方式很多,总体分为离线处理,实时处理,离线处理就是每天定时处理,通过一些数据处理框架,可以吧数据计算成各种KPI,在这里需要注意一下,不要只想着功能,主要是把各种数据维度建起来,基本数据做全,还要可复用,后期就可以把各种kpi随意组合展示出来。
是
4.数据展现,数据做出来没用,要可视化,做到MVP,就是快速做出来一个效果,不合适及时调整。
是
数据采集:
1.批数据采集,就是每天定时去数据库抓取数据快照,可以根据需求,设置每天去数据库备份一次快照,如何备份,如何设置数据源,如何设置出错。
是
2.实时接口调用数据采集,可以用logHub,dataHub,流数据处理方式技术,DataHub具有高可用,低延迟,高可扩展,高吞吐的特点。
高吞吐:最高支持单主题(Topic)每日T级别的数据量写入,每个分片(Shard)支持最高每日8000万Record级别的写入量。
实时性:通过DataHub,您可以实时的收集各种方式生成的数据并进行实时的处理,
设计思路:首先写一个sdk把公司所有后台服务调用接口调用情况记录下来,开辟线程池,把记录下来的数据不停的往dataHub,logHub存储,前提是设置好接收数据的dataHub表结构
是
3.前台数据埋点,这些就要根据业务需求来设置了,也是通过流数据传输到数据仓库,如上述第二步。
是
数据处理:
数据采集完成就可以对数据进行加工处理,可分为离线批处理,实时处理。
1.离线批处理编写数据处理脚本,设置任务执行时间,任务执行条件,就可以按照你的要求,每天产生你需要数据
是
2.实时处理:采用storm/spark,目前接触的只有storm,strom基本概念网上一大把,在这里讲一下大概处理过程,首先设置要读取得数据源,只要启动storm就会不停息的读取数据源。Spout,用来读取数据。Tuple:一次消息传递的基本单元,理解为一组消息就是一个Tuple。stream,用来传输流,Tuple的集合。Bolt:接受数据然后执行处理的组件,用户可以在其中执行自己想要的操作。可以在里边写业务逻辑,storm不会保存结果,需要自己写代码保存,把这些合并起来就是一个拓扑,总体来说就是把拓扑提交到服务器启动后,他会不停读取数据源,然后通过stream把数据流动,通过自己写的Bolt代码进行数据处理,然后保存到任意地方,关于如何安装部署storm,如何设置数据源,网上都有教程,这里不多说。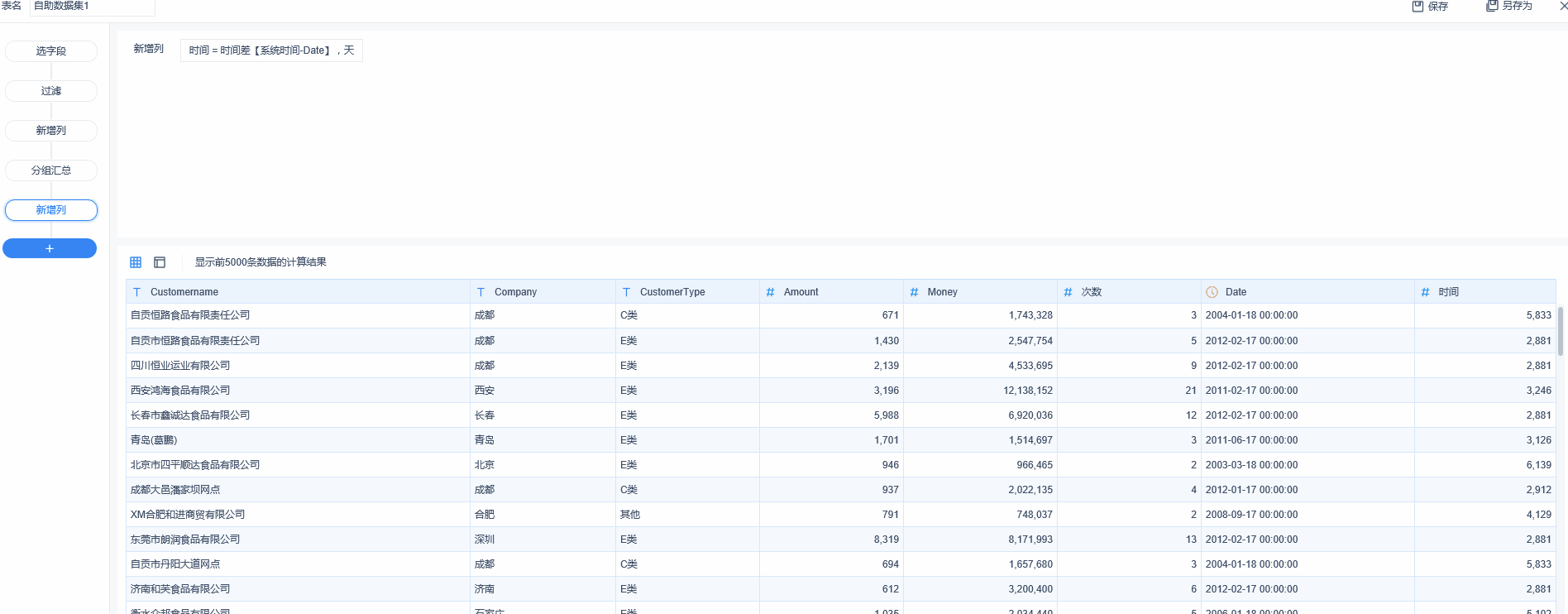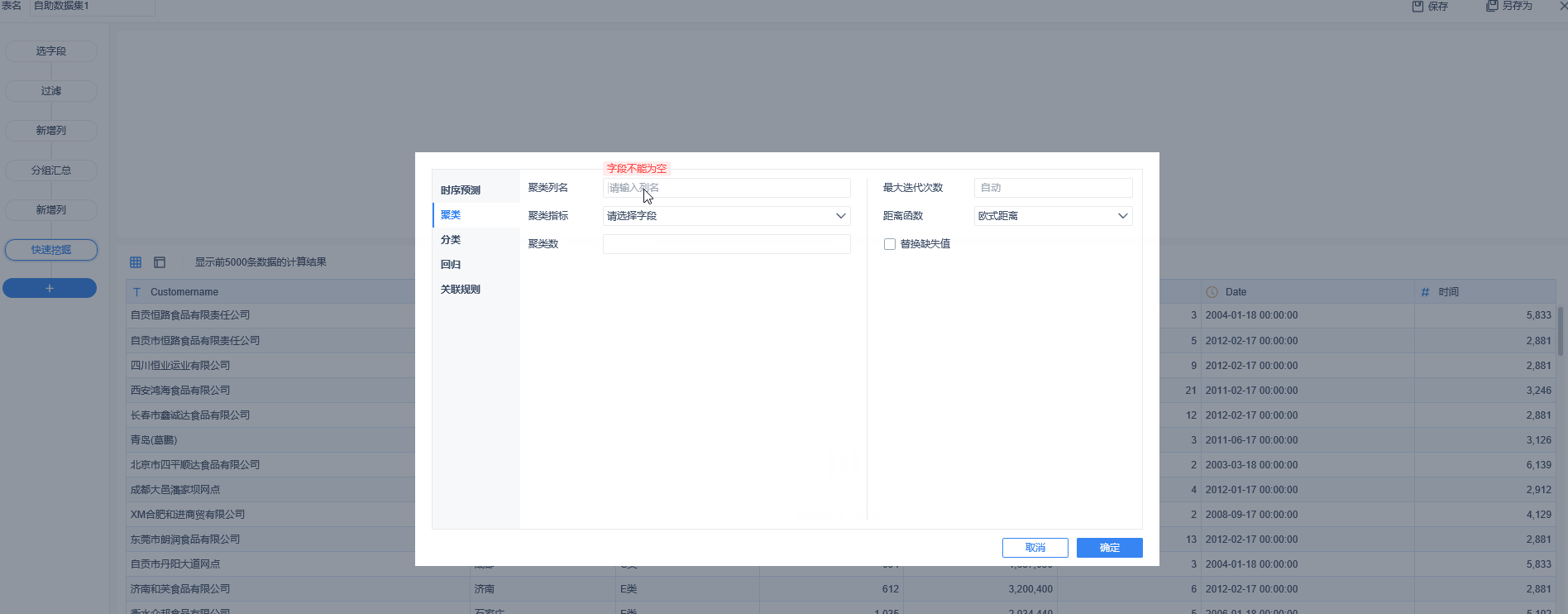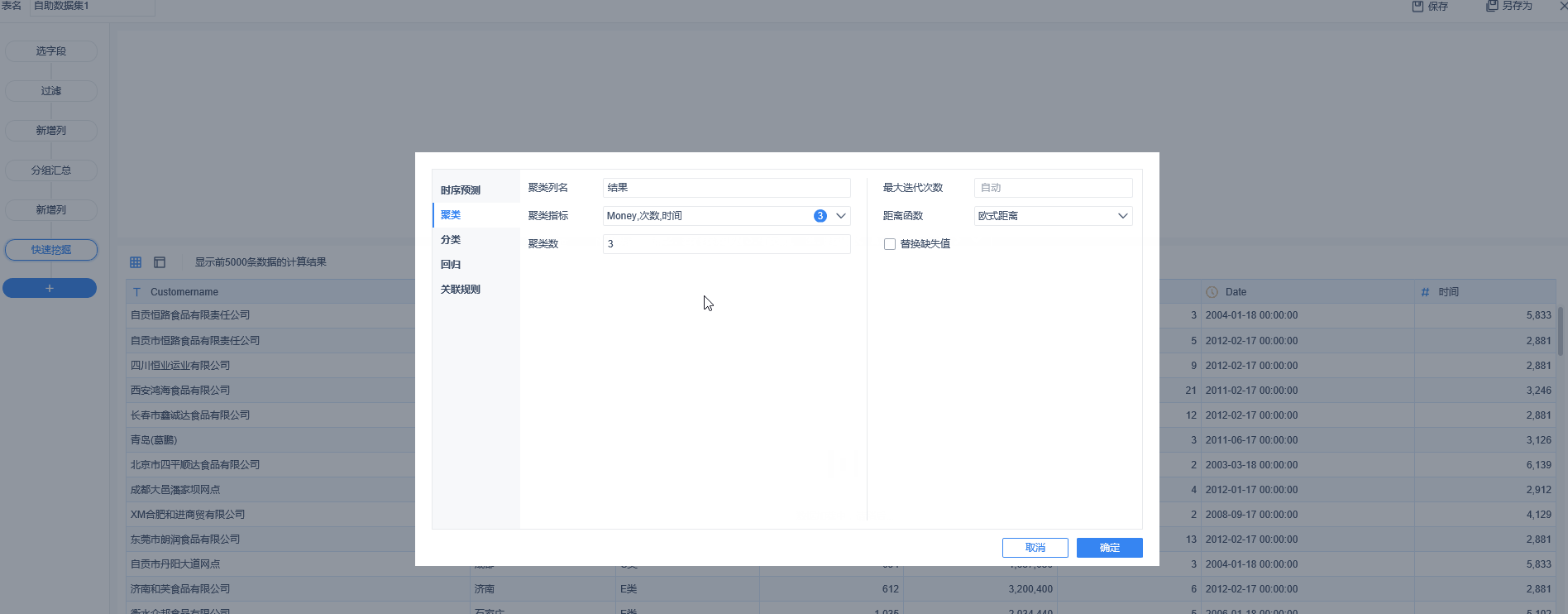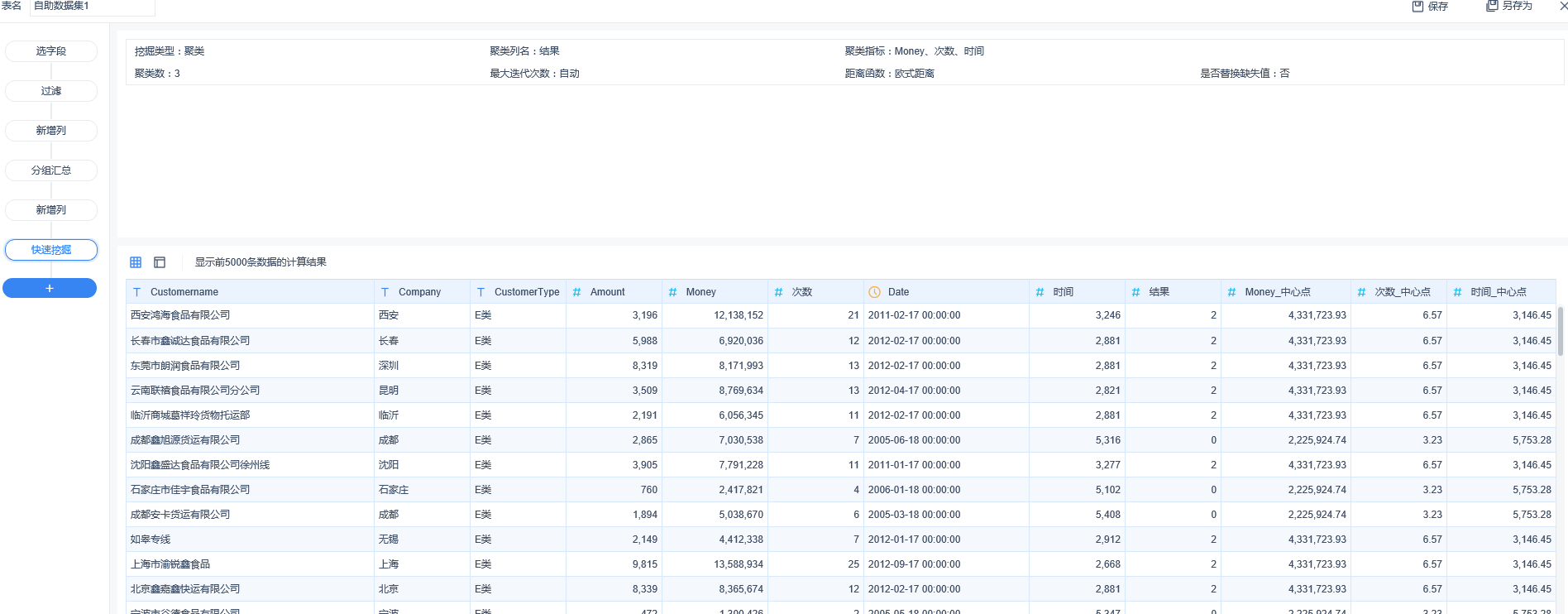
是







 立即沟通
立即沟通

