Manual cleaning remains a major obstacle for you in 2025. Data professionals spend up to 80% of their time on data cleaning and manual data wrangling. You face constant pressure from data errors and inconsistencies during data cleanup and data cleansing. The process of manual data wrangling introduces mistakes and slows down your workflow.
Here are some of the most common pain points you encounter:
Pain Point
Description
High potential for human error
Manual data cleaning is prone to mistakes, which can lead to costly consequences in data integrity.
Time-consuming processes
Identifying duplicates and standardizing formats require significant time, diverting focus from analysis.
Difficulties in maintaining consistency
Inconsistent data formats create major obstacles, complicating the integration of datasets.
You often wonder what makes manually cleaning data challenging? Modern solutions like FineDataLink help you overcome these issues with smarter data wrangling and efficient integration. You will discover practical strategies to reduce time and errors in data cleanup and improve data management.
What Makes Manually Cleaning Data Challenging?
You face new obstacles every year, but the core question remains: what makes manually cleaning data challenging? The answer lies in three main areas. You must deal with massive volumes and complex structures, constant risks of human error, and a lack of standardization across teams and systems. These factors combine to make data cleaning a time-consuming and error-prone process.
Volume and Complexity
You see the amount of enterprise data growing at an incredible rate. By 2028, global enterprise data will surpass 394 zettabytes. This explosion in data volume makes manual data cleaning much harder. You must sift through huge datasets, which increases the time needed for data cleanup and data wrangling. You encounter more data quality issues as the complexity rises. You struggle to maintain data integrity and ensure compliance. Real-time access becomes difficult when you rely on manual data cleansing.
Here are some types of data complexity that make manual cleaning difficult:
Data Complexity Type
Description
Data Inconsistencies
Errors scattered throughout datasets that require identification and correction.
Incomplete and Missing Values
Missing data that can occur randomly or follow patterns, complicating the cleaning process.
Duplicate Records
Instances where the same individual or event is recorded multiple times, requiring manual detection.
Variety of Data Formats and Structures
Challenges in integrating data from different sources with varied formats and schemas.
In manufacturing and enterprise environments, you often spend hours compiling reports in spreadsheets. You deal with multiple versions of the same report, which leads to confusion and data discrepancies. Manual data collection slows down your workflow and causes unexpected errors. You waste valuable resources on repetitive tasks instead of focusing on analysis.
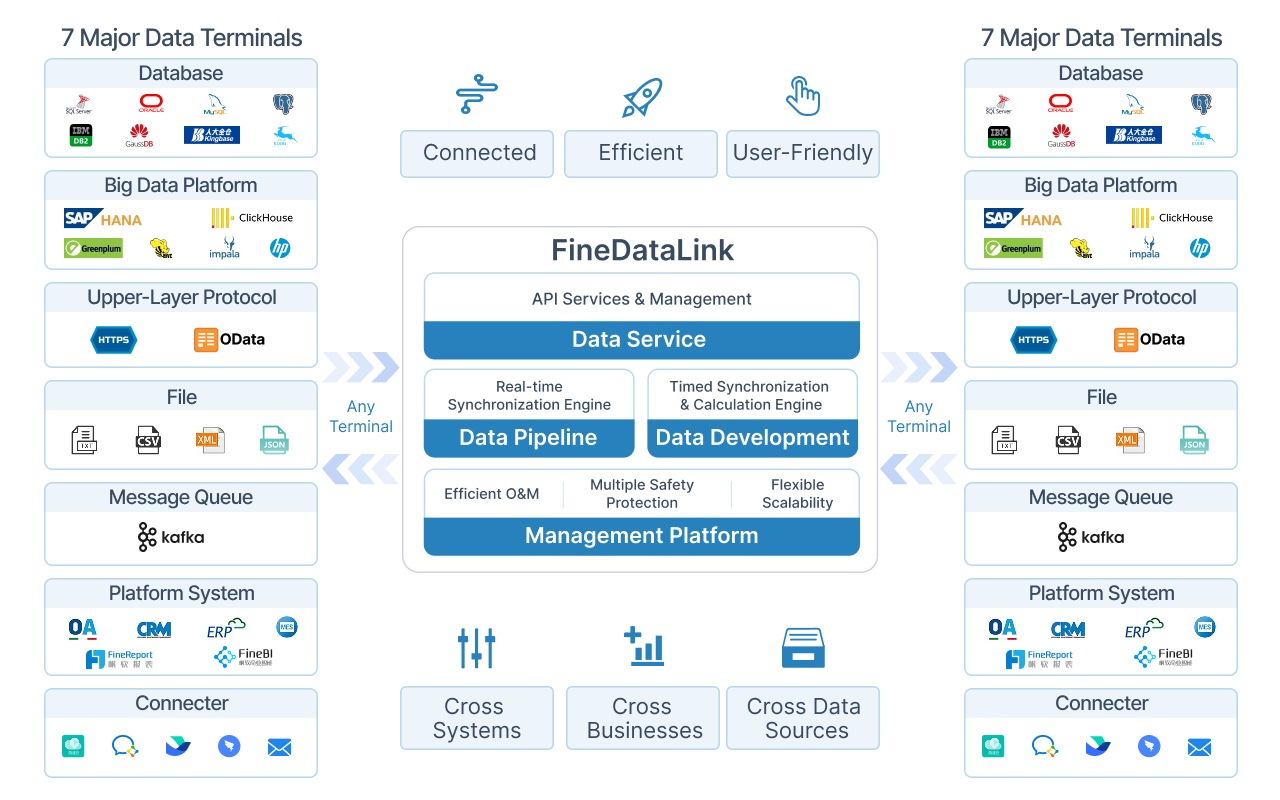
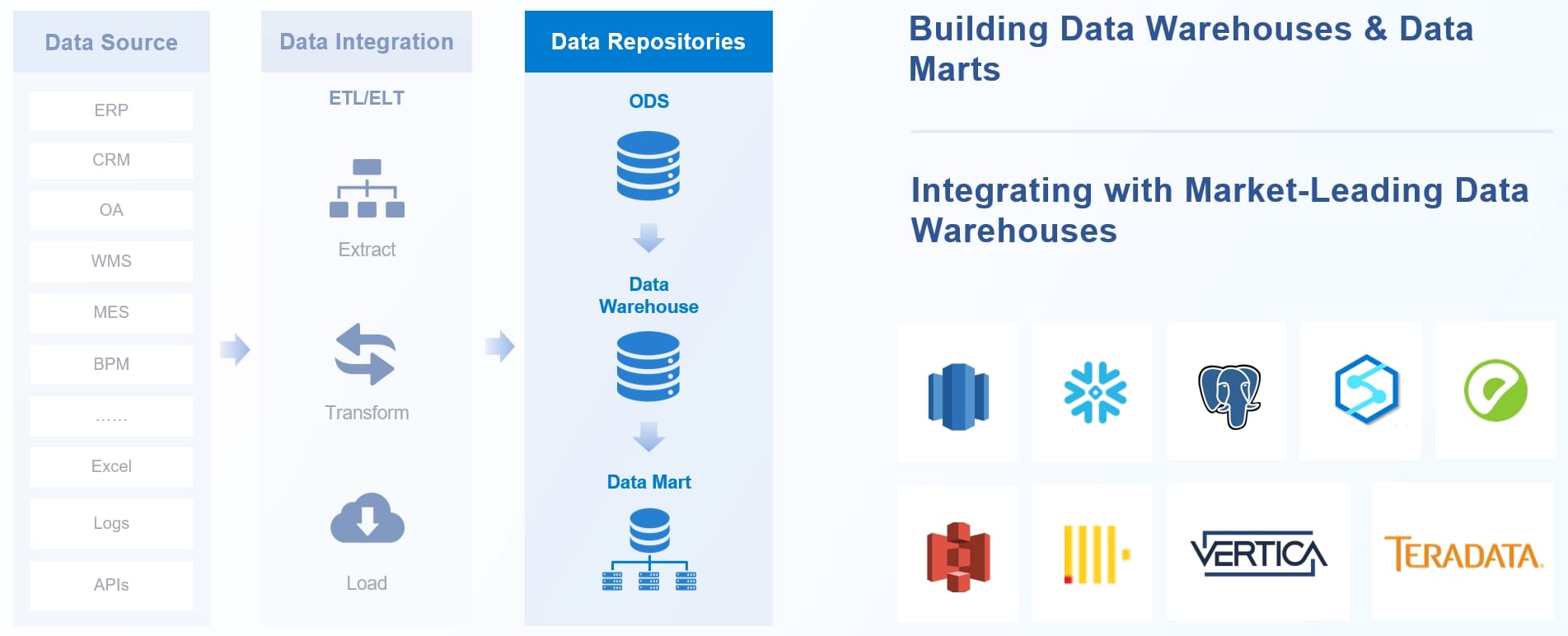
FineDataLink from FanRuan helps you overcome these challenges. The platform integrates data from over 100 sources and supports real-time synchronization. You can automate data wrangling and reduce the time spent on manual data cleanup. This solution builds a high-quality data layer for business intelligence, making your data cleaning process more efficient.
You know that human error is a major risk in manual data cleaning. The estimated error rate from manual intervention is around 1%. If you perform 10,000 calibrations each year, you could have 4,000 records with errors. Every calibration might contain at least one faulty entry. These errors threaten data quality and data integrity.
Common causes of human error in data cleaning include:
Cause of Error
Description
Data Input Errors
Errors occurring during case recording, common in systems relying on manual input.
Similar or Duplicate Records
Arising from operational errors or when cases with different completeness are stored together.
Missing Values
Can result from technical recording errors, patient concealment, or data storage failures.
You also encounter typos, omissions, inconsistencies, and inadequate validation procedures. Lack of standardization in data entry makes these problems worse. In manufacturing, manual reporting leads to inconsistent data and undermines confidence in your decisions. The complexity of data increases the likelihood of errors, making data wrangling even more challenging.
FineDataLink reduces human error risks by automating data integration and providing a visual interface. You can use drag-and-drop tools to build efficient data pipelines and minimize manual intervention. This approach improves data quality and helps you avoid costly mistakes during data cleanup.
You struggle with a lack of standardization in data cleaning processes. Different analysts use different methods on the same dataset. One person might remove rows with missing values, while another fills them in. This inconsistency leads to unreliable outcomes and makes it hard to replicate results. The absence of standardization causes data quality issues and complicates data cleansing.
You often see employees using workarounds like batch recording, which reduces data accuracy. Multiple versions of reports exist, causing confusion and data discrepancies. Manual data wrangling becomes inefficient and error-prone.
FineDataLink addresses these challenges by providing a unified platform for data integration and data cleaning. You can standardize your data cleansing workflows and ensure consistent results. The platform supports real-time data synchronization and advanced ETL/ELT functions, making your data cleanup process faster and more reliable.
Tip: You can improve your data cleaning results by adopting standardized workflows and leveraging automation tools like FineDataLink. This approach helps you reduce errors, save time, and maintain high data quality.
You now understand what makes manually cleaning data challenging. You face large volumes, complex structures, human error risks, and a lack of standardization. By using modern solutions like FineDataLink, you can overcome these obstacles and achieve better data quality in your organization.
Key Data Cleaning Challenges for Enterprises
You face several obstacles when you try to improve data cleaning in your organization. These challenges slow down your workflow and threaten the accuracy of your analytics. Let’s look at three major issues you encounter and how you can address them.
Inconsistent Formats
You often deal with inconsistent data formats. This problem appears when you collect data from different sources or migrate information between systems. For example, you might see dates written as MM/DD/YYYY in one database and DD/MM/YYYY in another. These inconsistencies lead to conversion errors and make data wrangling more difficult. You risk losing valuable information and creating mistakes during data cleanup.
Issue
Impact on Data Quality
Data integration issues
Leads to conversion errors and discrepancies in data.
Data-capturing inconsistencies
Introduces errors and reduces reliability of data.
Poor data migration
Causes inconsistencies that build up over time.
You can solve these problems by using advanced data cleaning methods and clear data entry guidelines. FineDataLink helps you standardize formats and automate data cleansing. You gain a unified view of your data and reduce the risk of errors.
You encounter missing values and duplicate entries in almost every dataset. These issues waste your time and lower the quality of your reports. Duplicate entries confuse your analytics and lead to poor business decisions. Missing values make it hard to trust your results and can cause compliance problems.
Organizations in the US lose billions each year due to poor data quality. Sales teams waste time chasing duplicate records. You see decreased efficiency and struggle to generate accurate reports.
You can improve data cleaning by auditing your data regularly and using tools that detect duplicates. FineDataLink automates data wrangling and helps you find and fix missing values. You spend less time on manual data cleanup and more time on analysis.
You face data errors when you integrate information from multiple systems. Human error rates can reach 5% in complex scenarios. Repetitive tasks increase the risk of mistakes. You see mismatched schemas, incomplete fields, and flawed transformation rules. These errors cause operational inefficiencies and threaten data integrity.
Data-Related Issues
Impact on Integration Performance
Incomplete or erroneous data
Leads to operational inefficiencies
Higher than anticipated data volume
Causes system overload and performance degradation
Duplicated data
Results in reconciliation issues and data integrity loss
Mismatched schemas
Causes data to be dropped or ignored
You can reduce data errors by using automated integration platforms. FineDataLink helps you overcome data silos and manual ETL inefficiencies. You gain real-time synchronization and a reliable data layer for business intelligence.
DAS Corporation improved its data cleaning process by adopting FineDataLink. The company automated data wrangling and data cleanup across 12 global branches. You can achieve similar results by using modern solutions to manage inconsistencies and errors.
Why Automation Alone Can't Solve Data Cleaning
Limits of Current Tools
You rely on automation to speed up data cleaning, but you still face many challenges. Most automated tools in 2025 have limits that affect your workflow. You notice mild feedback about interface usability and very few user reviews. These tools often need domain expertise, which makes scaling manual processes difficult. You must balance automation with accuracy, but this is not always easy.
Limitation Type
Description
User Feedback
Very few user reviews and limited public feedback
Interface Usability
Mild interface and usability feedback
You see that poor data hygiene, such as duplicate entries and inconsistent formatting, slows down your operations. Manual data cleaning becomes impracticable as your data grows. These limits lead to inefficiencies in decision-making and higher operational costs. You miss business opportunities when your data is outdated or inaccurate.
Need for Human Judgment
You know that automation cannot replace human judgment in data cleaning. AI can find patterns, but it cannot understand context. You must decide whether to drop or impute missing values. Your insight is crucial for interpreting data nuances. You transition from manual data wrangling to becoming a strategic data steward.
AI enhances efficiency but does not replace your role.
You ensure that data is contextually accurate and valuable.
The combination of automation and human judgment improves data quality.
You make decisions that automation cannot handle. You understand the meaning behind the data and catch errors that machines miss. Your expertise ensures that data cleansing leads to reliable results.
FineDataLink Solutions
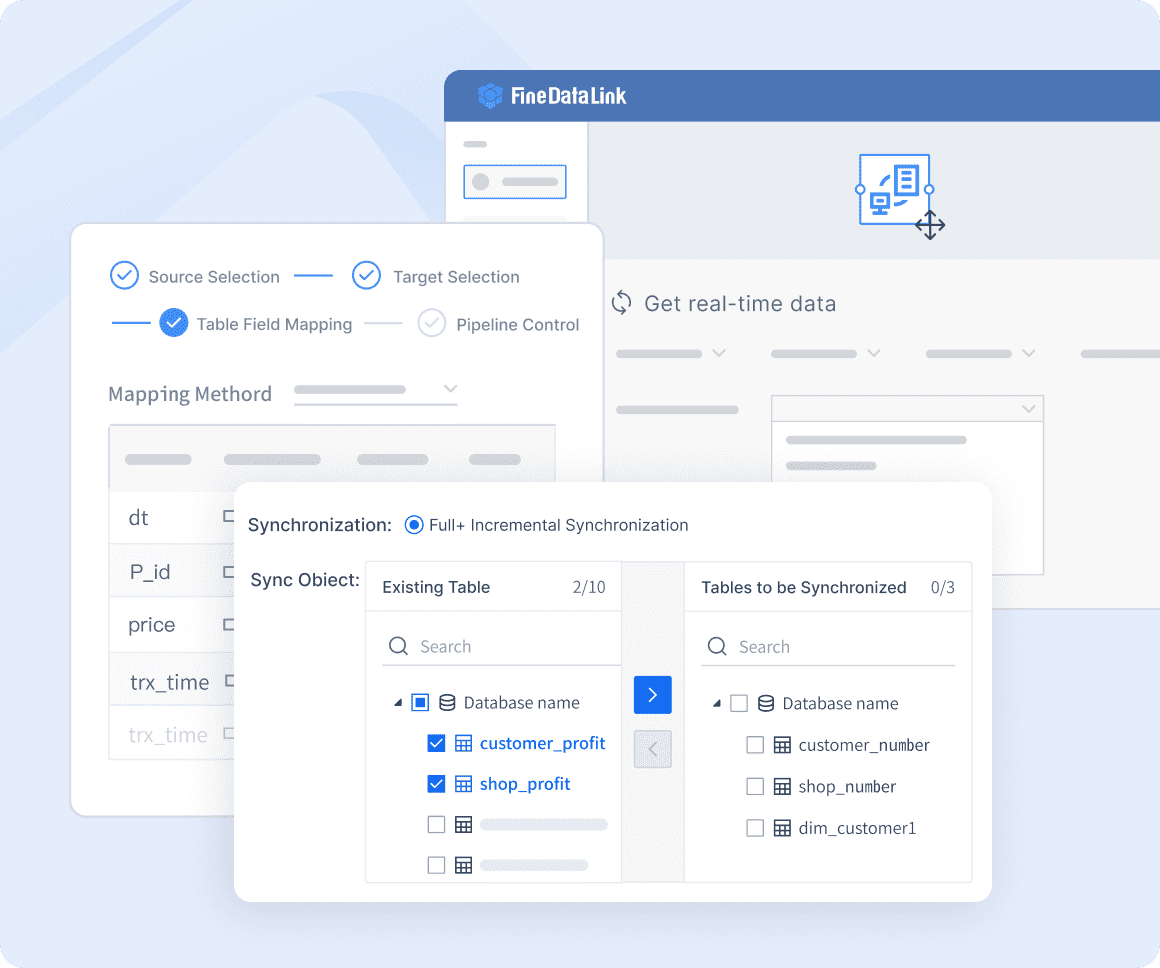
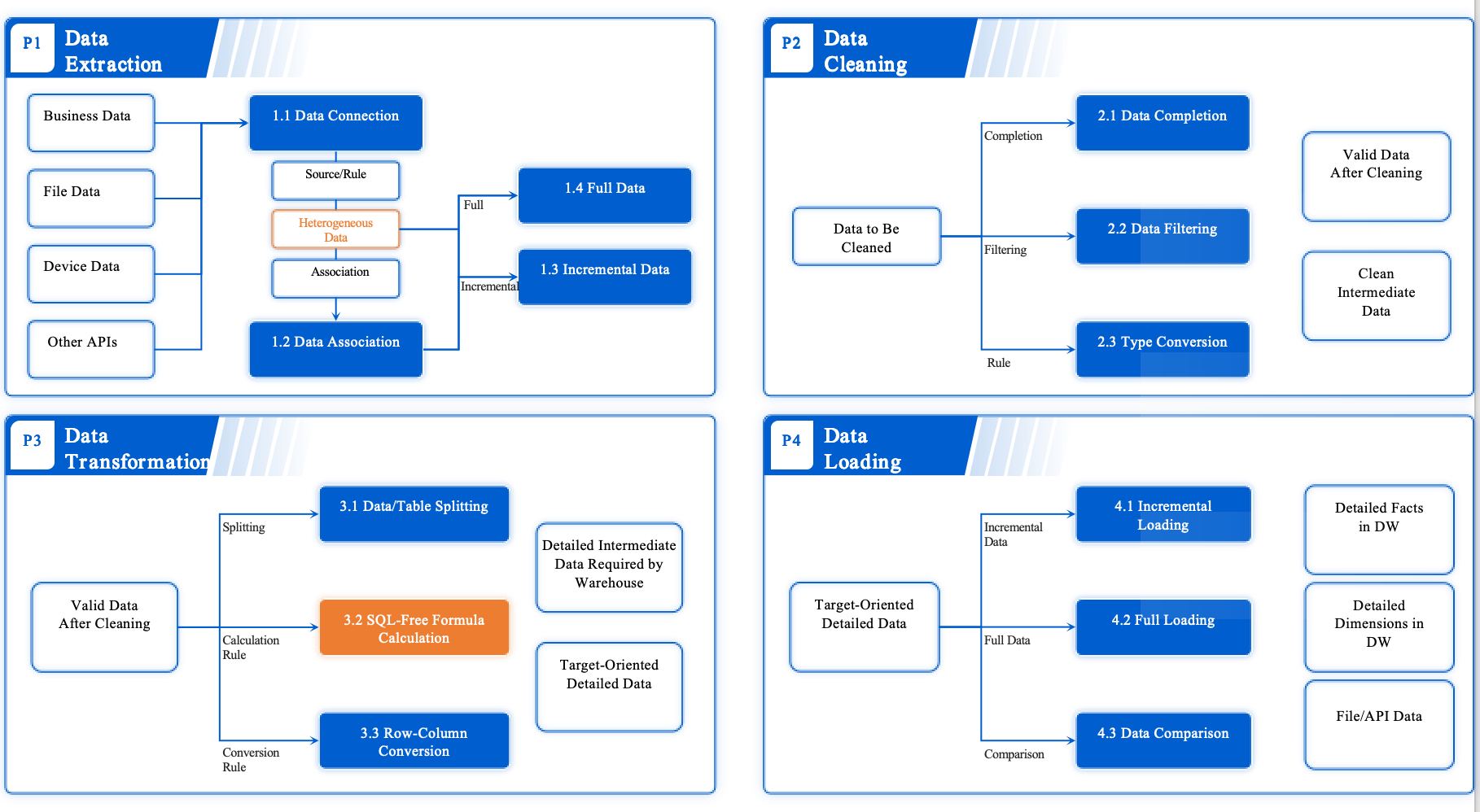
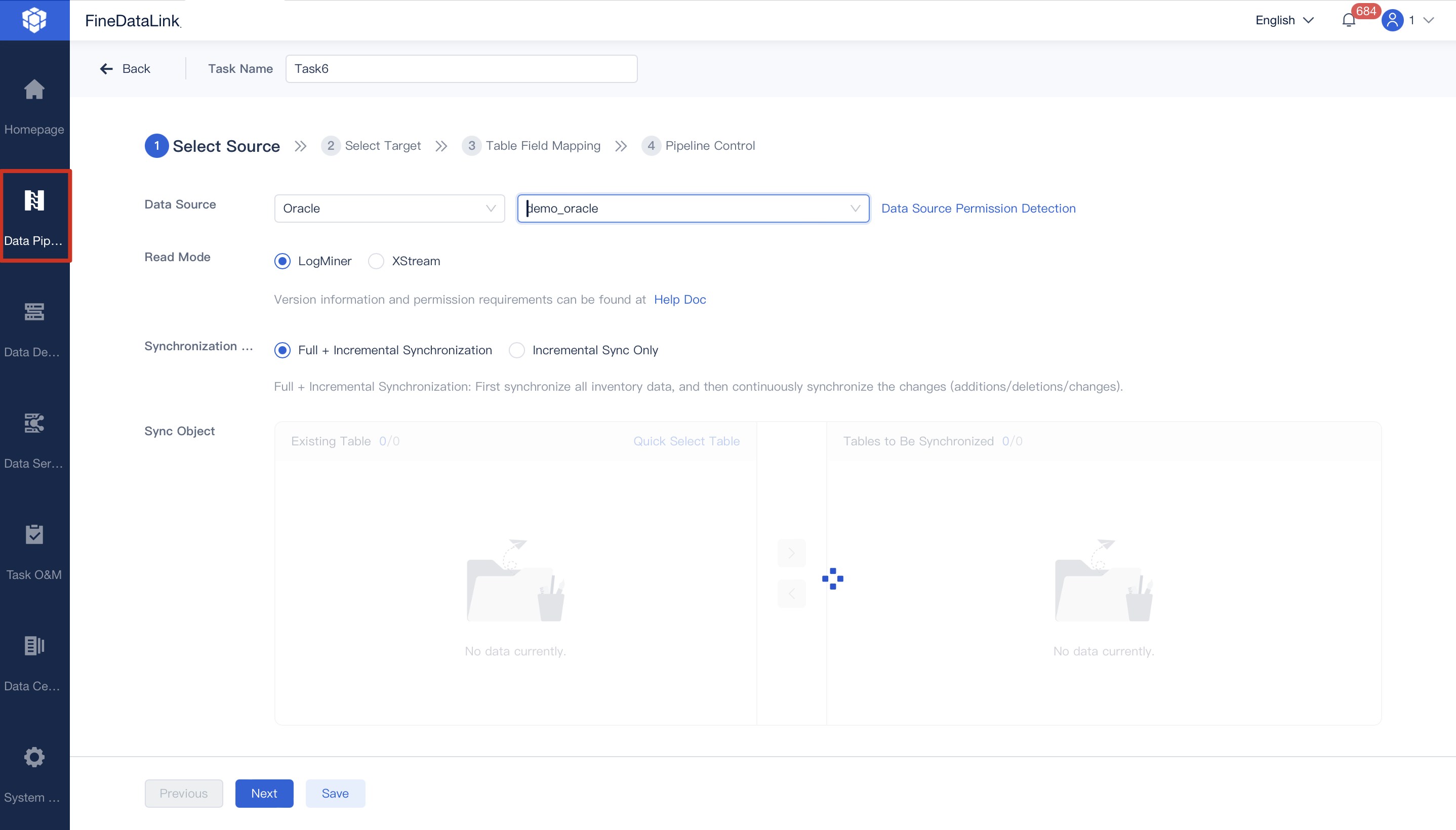
You can overcome many data cleaning challenges with FanRuan's FineDataLink. The platform uses a low-code approach to simplify complex data integration tasks. You minimize manual efforts and reduce errors during data cleanup. FineDataLink automates data extraction, transformation, and loading. You benefit from real-time data synchronization, which keeps your datasets clean and current.
FineDataLink manages various data formats and supports advanced ETL/ELT functions. You build efficient data pipelines and improve data quality. The platform combines automation with manual oversight, so you maintain control over data wrangling and data cleansing. You save time and achieve better outcomes in your data cleaning process.
Tip: Use FineDataLink to automate repetitive tasks and focus your time on strategic decisions. This approach helps you maintain high data quality and reduces errors in data cleanup.
Strategies to Reduce Data Errors and Manual Effort
Best Practices for Data Cleaning
You can improve data cleaning by following proven best practices. Start by standardizing formats for text, dates, and categories. This step helps you avoid errors during data cleanup and data wrangling. Investigate outliers using business rules and statistical methods. Ongoing quality monitoring is important. Automated checks for missing values and duplicates help maintain data quality. Build systematic workflows with four phases: profiling, rule creation, testing, and monitoring. These steps make your data cleansing process more reliable.
Best Practice
Description
Standardizing formats
Use consistent text, date, and category formats to prevent errors.
Dealing with outliers
Identify and review outliers to protect data integrity.
Set up automated checks for missing values and duplicates.
Systematic workflows
Follow profiling, rule creation, testing, and monitoring for data cleanup.
Leveraging FineDataLink
You can reduce manual effort in data cleaning by using FineDataLink. This platform streamlines data cleanup and analysis. FineDataLinkautomates extraction, transformation, and loading, which lowers the risk of errors. You handle diverse data formats and synchronize data in real time. The low-code approach simplifies complex data wrangling tasks. You gain efficient ETL/ELT functions for data preprocessing. FineDataLink helps you maintain high data quality and keeps your datasets up-to-date.
FineDataLink streamlines data cleaning and analysis.
You enhance data quality for better insights.
The platform simplifies integration with low-code tools.
Automation reduces manual data cleanup and errors.
Real-time synchronization keeps your data current.
You can build efficient data pipelines to automate data cleaning and data wrangling. Automated validation checks and transformations ensure only clean data enters your system. These pipelines minimize human error and maintain consistent standards. You save time and reduce manual data cleanup workload. Efficient pipelines lead to faster time-to-insight and a 60-80% reduction in manual processing time. You also see a 30-40% drop in data-related errors and a 20-25% boost in regulatory reporting efficiency.
Tip: Back up your original data before cleaning. Maintain detailed records of errors and profiling. Use real-time validation to prevent mistakes from entering your dataset.
You face ongoing challenges with manual data cleaning. The volume and complexity of data, along with quality and integration issues, make the process difficult. Automation helps, but you still need human judgment. The table below shows why manual data cleaning remains tough:
Challenge Type
Description
Volume of data
Businesses generate vast amounts of data from many sources.
Complexity of data sources
Data comes in different formats and structures.
Data quality issues
Datasets often have inaccuracies and missing values.
Data integration issues
Combining data from diverse sources is hard.
Time-consuming efforts
Manual cleansing takes a lot of time.
Automation limitations
Tools may miss errors needing human review.
Continuous maintenance
Data quality needs ongoing updates.
You can improve your workflow by adopting smarter strategies and using platforms like FineDataLink. Explore FanRuan's solutions for efficient, error-free data management.
Product Trial
FineReport
Pixel-perfect reports · Interactive dashboards · Easy data entry · Digital twins
Access a wealth of case studies, industry insights, and solution guides to accelerate digital transformation.
FAQ
What is the biggest challenge in manual data cleaning?
You face large volumes of data with many errors. Manual cleaning takes a lot of time. You often find mistakes and inconsistencies that slow down your work.
How does FineDataLink help you clean data faster?
You use FineDataLink to automate data integration and cleaning. The platform supports real-time synchronization and low-code tools. You save time and reduce errors in your workflow.
Can you use FineDataLink with different data sources?
You connect FineDataLink to over 100 data sources. You integrate databases, cloud apps, and legacy systems. The platform helps you manage all your data in one place.
Why do you still need human judgment in data cleaning?
You make decisions that automation cannot handle. You understand the context and meaning behind the data. Your expertise ensures that data cleaning leads to reliable results.