


Hadoop adalah kerangka kerja open-source yang dirancang untuk menyimpan dan memproses data besar secara terdistribusi. Anda mungkin bertanya-tanya, mengapa Hadoop begitu penting dalam pengolahan data besar? Hadoop memungkinkan perusahaan seperti Facebook dan Yahoo untuk mengelola dan menganalisis data dalam jumlah besar dengan efisiensi tinggi. Dengan Hadoop, Anda dapat mengatasi tantangan Big Data melalui distribusi, toleransi kesalahan, dan efisiensi pemrosesan. Ini menjadikannya alat yang sangat berharga dalam transformasi digital dan analitik data, membantu berbagai industri meningkatkan efisiensi dan menciptakan inovasi.
Poin Penting Tentang Hadoop
- Hadoop adalah kerangka kerja open-source yang memungkinkan penyimpanan dan pemrosesan data besar secara efisien dan terdistribusi.
- Komponen utama Hadoop meliputi HDFS untuk penyimpanan data, YARN untuk pengelolaan sumber daya, dan MapReduce untuk pemrosesan data.
- Hadoop menawarkan skalabilitas yang tinggi, memungkinkan penambahan node sesuai kebutuhan tanpa mengganti infrastruktur yang ada.
- Dengan kemampuan toleransi kesalahan, Hadoop memastikan data tetap aman meskipun terjadi kegagalan perangkat keras.
- Menggunakan FineBI dengan Hadoop memudahkan analisis data, memungkinkan visualisasi yang menarik dan analisis real-time.
- Memulai dengan Hadoop memerlukan pemahaman konsep dasar, persiapan infrastruktur, dan pelatihan dalam pemrograman MapReduce.
- Hadoop membantu perusahaan dalam transformasi digital dengan memberikan wawasan yang lebih dalam dan meningkatkan efisiensi operasional.

Apa Itu Hadoop?
Definisi dan Sejarah Hadoop
Hadoop adalah kerangka kerja open-source yang dirancang untuk menyimpan dan mengelola data besar secara terdistribusi. Doug Cutting dan Mike Cafarella mengembangkan Hadoop pada tahun 2005 saat bekerja di Yahoo. Inspirasi awalnya berasal dari makalah Google File System (GFS) yang diterbitkan pada Oktober 2003. Yahoo kemudian menggunakan Hadoop untuk memproses data berukuran petabyte, dan pada akhirnya, Apache Software Foundation menjadikannya sumber terbuka. Sejak saat itu, Hadoop telah menjadi salah satu framework yang paling banyak digunakan untuk memproses dan menganalisis big data di berbagai aplikasi.
Pentingnya Hadoop dalam Ekosistem Big Data
Hadoop memainkan peran penting dalam ekosistem Big Data. Dengan kemampuannya untuk menyimpan dan memproses data dalam jumlah besar secara efisien, Hadoop menjadi solusi andal dan terjangkau untuk menangani tantangan Big Data. Banyak perusahaan besar, termasuk Facebook dan Yahoo, memanfaatkan Hadoop untuk mengelola data mereka. Hadoop memungkinkan pemrosesan data secara cepat dan dapat diskalakan dengan menambahkan node komputasi. Ini menjadikannya alat yang sangat berharga dalam analisis data, mulai dari analisis web hingga analisis keuangan. Dengan Hadoop, Anda dapat mengatasi berbagai jenis permasalahan dalam pengolahan big data yang sebelumnya masih dilakukan secara konvensional.
Komponen Utama Hadoop

Dalam ekosistem Hadoop, terdapat beberapa komponen utama yang bekerja sama untuk menyimpan dan memproses data besar secara efisien. Memahami fungsi dari setiap komponen ini akan membantu Anda dalam mengoptimalkan penggunaan Hadoop untuk kebutuhan analisis data Anda.
HDFS (Hadoop Distributed File System)
HDFS adalah sistem file terdistribusi yang dirancang untuk menyimpan data dalam jumlah besar di berbagai mesin. Anda dapat membayangkan HDFS sebagai tulang punggung dari Hadoop, yang memungkinkan penyimpanan data secara terdistribusi. HDFS membagi data menjadi blok-blok kecil dan menyimpannya di berbagai node dalam kluster. Dengan cara ini, Anda dapat mengakses dan memproses data dengan cepat dan efisien. HDFS juga dirancang untuk menangani kegagalan perangkat keras dengan replikasi data, sehingga Anda tidak perlu khawatir kehilangan data jika terjadi kerusakan pada salah satu node.
YARN (Yet Another Resource Negotiator)
YARN berfungsi sebagai pengelola sumber daya dalam ekosistem Hadoop. Anda dapat menganggap YARN sebagai otak dari Hadoop yang mengatur dan mengalokasikan sumber daya komputasi untuk berbagai aplikasi. Dengan YARN, Anda dapat menjalankan berbagai aplikasi secara bersamaan dalam satu kluster, sehingga meningkatkan efisiensi pemrosesan data. YARN memastikan bahwa setiap aplikasi mendapatkan sumber daya yang dibutuhkan tanpa mengganggu aplikasi lain, sehingga Anda dapat memaksimalkan penggunaan kluster Anda.
MapReduce
MapReduce adalah model pemrograman yang digunakan untuk memproses data dalam Hadoop. Anda dapat menggunakan MapReduce untuk membagi tugas pemrosesan data menjadi bagian-bagian kecil yang dapat dijalankan secara paralel di berbagai node. Proses ini terdiri dari dua tahap utama: Map dan Reduce. Pada tahap Map, data dipecah menjadi pasangan kunci-nilai, sementara pada tahap Reduce, pasangan kunci-nilai tersebut digabungkan untuk menghasilkan output akhir. Dengan MapReduce, Anda dapat memproses data dalam jumlah besar dengan cepat dan efisien, memanfaatkan kekuatan komputasi dari seluruh kluster.
Common
Dalam ekosistem Hadoop, komponen Common memainkan peran penting sebagai fondasi yang mendukung fungsi dari komponen lainnya seperti HDFS, YARN, dan MapReduce. Anda dapat menganggap Common sebagai kumpulan utilitas dan pustaka yang menyediakan layanan dasar untuk komponen-komponen tersebut. Berikut adalah beberapa fungsi utama dari Common:
- Konfigurasi dan Pengaturan: Common menyediakan mekanisme untuk mengkonfigurasi dan mengatur berbagai komponen dalam ekosistem Hadoop. Anda dapat menggunakan file konfigurasi untuk menyesuaikan pengaturan sesuai dengan kebutuhan spesifik Anda.
- Utilitas I/O: Common menawarkan berbagai utilitas untuk operasi input dan output, yang memudahkan Anda dalam mengelola data yang masuk dan keluar dari sistem Hadoop. Ini termasuk dukungan untuk berbagai format file dan protokol jaringan.
- Keamanan: Dalam lingkungan yang terdistribusi, keamanan menjadi aspek penting. Common menyediakan fitur keamanan seperti autentikasi dan otorisasi untuk melindungi data Anda dari akses yang tidak sah.
- Pemantauan dan Logging: Untuk memastikan sistem berjalan dengan lancar, Common menyediakan alat pemantauan dan logging. Anda dapat memantau kinerja sistem dan mengidentifikasi masalah dengan cepat melalui log yang dihasilkan.
Dengan memahami peran Common, Anda dapat lebih efektif dalam mengelola dan mengoptimalkan penggunaan Hadoop. Komponen ini memastikan bahwa semua bagian dari ekosistem Hadoop dapat berfungsi dengan baik dan saling berinteraksi secara harmonis.
Cara Kerja Hadoop
Proses Penyimpanan Data Hadoop
Dalam ekosistem Hadoop, proses penyimpanan data dimulai dengan Hadoop Distributed File System (HDFS). Anda menyimpan data dalam blok-blok kecil yang tersebar di berbagai node dalam kluster. Ini memungkinkan Anda untuk mengakses data dengan cepat dan efisien. HDFS dirancang untuk menangani kegagalan perangkat keras. Anda tidak perlu khawatir kehilangan data karena sistem ini mereplikasi data di beberapa node. Dengan demikian, jika satu node gagal, data tetap aman dan dapat diakses dari node lain.
Proses Pemrosesan Data Hadoop
Pemrosesan data dalam Hadoop menggunakan model pemrograman MapReduce. Anda dapat membagi tugas pemrosesan menjadi bagian-bagian kecil yang dapat dijalankan secara paralel di berbagai node. Proses ini terdiri dari dua tahap utama: Map dan Reduce. Pada tahap Map, Anda memecah data menjadi pasangan kunci-nilai. Kemudian, pada tahap Reduce, Anda menggabungkan pasangan kunci-nilai tersebut untuk menghasilkan output akhir. Dengan MapReduce, Anda dapat memanfaatkan kekuatan komputasi dari seluruh kluster untuk memproses data dalam jumlah besar dengan cepat dan efisien.
Keunggulan Hadoop
Hadoop menawarkan berbagai keunggulan yang membuatnya menjadi pilihan utama dalam pengolahan data besar. Anda dapat memanfaatkan keunggulan ini untuk meningkatkan efisiensi dan efektivitas dalam pengelolaan data.
Skalabilitas dan Efisiensi Biaya Hadoop
- Skalabilitas: Anda dapat dengan mudah menambah atau mengurangi jumlah node dalam kluster Hadoop sesuai kebutuhan. Ini memungkinkan Anda untuk menangani volume data yang terus bertambah tanpa harus mengganti infrastruktur yang ada. Dengan menambahkan lebih banyak node, Anda dapat meningkatkan kapasitas penyimpanan dan pemrosesan data secara signifikan.
- Efisiensi Biaya: Hadoop dirancang untuk bekerja dengan perangkat keras komoditas. Anda tidak perlu mengeluarkan biaya besar untuk perangkat keras khusus. Ini membuat Hadoop menjadi solusi yang terjangkau untuk perusahaan yang ingin mengelola data dalam jumlah besar. Dengan memanfaatkan semua kapasitas penyimpanan dan pemrosesan di server klaster, Anda dapat mengoptimalkan penggunaan sumber daya yang ada.
Toleransi Kesalahan Hadoop
- Toleransi Kesalahan: Hadoop memiliki kemampuan untuk menangani kegagalan perangkat keras tanpa kehilangan data. Anda tidak perlu khawatir jika salah satu node dalam kluster mengalami kerusakan. HDFS, sebagai sistem file terdistribusi, mereplikasi data di beberapa node. Ini memastikan bahwa data tetap aman dan dapat diakses meskipun terjadi kegagalan pada salah satu node.
- Keandalan: Dengan sistem replikasi data, Hadoop memastikan bahwa data Anda selalu tersedia. Anda dapat mengandalkan Hadoop untuk menjaga integritas data meskipun terjadi gangguan pada infrastruktur. Ini memberikan ketenangan pikiran bagi Anda yang mengelola data penting dan sensitif.
Dengan memahami keunggulan Hadoop, Anda dapat memanfaatkannya untuk mengatasi tantangan dalam pengolahan data besar. Skalabilitas, efisiensi biaya, dan toleransi kesalahan menjadikan Hadoop sebagai solusi yang andal dan efektif untuk berbagai kebutuhan analisis data.
Tantangan dalam Menggunakan Hadoop
Kompleksitas Pengelolaan
Mengelola Hadoop bisa menjadi tantangan tersendiri. Anda harus memahami berbagai komponen dan cara kerjanya. Hadoop terdiri dari beberapa elemen seperti HDFS, YARN, dan MapReduce. Setiap elemen memiliki fungsi dan konfigurasi yang berbeda. Anda perlu menguasai pengaturan dan pemeliharaan sistem ini agar dapat berfungsi optimal. Selain itu, Anda juga harus memastikan bahwa sistem tetap aman dan efisien. Ini memerlukan pemantauan dan penyesuaian yang terus-menerus. Anda mungkin perlu melibatkan tim IT yang terampil untuk mengelola dan memecahkan masalah yang muncul.
Kebutuhan Infrastruktur
Hadoop memerlukan infrastruktur yang memadai. Anda harus menyiapkan perangkat keras yang cukup untuk mendukung operasi Hadoop. Meskipun Hadoop dirancang untuk bekerja dengan perangkat keras komoditas, Anda tetap memerlukan sejumlah besar server untuk menangani data dalam jumlah besar. Anda juga harus mempertimbangkan kebutuhan penyimpanan dan jaringan. Infrastruktur yang tidak memadai dapat menghambat kinerja Hadoop. Anda perlu memastikan bahwa semua komponen terhubung dengan baik dan dapat berkomunikasi secara efektif. Ini memerlukan investasi awal yang signifikan dalam perangkat keras dan sumber daya manusia. Namun, dengan infrastruktur yang tepat, Anda dapat memanfaatkan Hadoop untuk mengolah data besar dengan efisiensi tinggi.
Implementasi Hadoop

Contoh Kasus Penggunaan Hadoop
Hadoop telah digunakan dalam berbagai industri untuk mengatasi tantangan Big Data. Anda dapat melihat bagaimana perusahaan besar seperti Facebook dan Yahoo memanfaatkan Hadoop untuk mengelola data dalam jumlah besar. Berikut beberapa contoh kasus penggunaan Hadoop yang dapat menginspirasi Anda:
- Analisis Media Sosial: Perusahaan media sosial menggunakan Hadoop untuk menganalisis data pengguna dalam jumlah besar. Anda dapat memanfaatkan Hadoop untuk melacak tren, memahami perilaku pengguna, dan meningkatkan pengalaman pengguna.
- Pengolahan Data Keuangan: Lembaga keuangan menggunakan Hadoop untuk menganalisis transaksi dalam jumlah besar. Anda dapat menggunakan Hadoop untuk mendeteksi penipuan, mengelola risiko, dan memprediksi tren pasar.
- Penelitian Genomik: Dalam bidang kesehatan, Hadoop digunakan untuk menganalisis data genomik yang kompleks. Anda dapat memanfaatkan Hadoop untuk mempercepat penelitian dan pengembangan obat baru.
- Pengelolaan Log Web: Perusahaan teknologi menggunakan Hadoop untuk menganalisis log web dan meningkatkan kinerja situs. Anda dapat menggunakan Hadoop untuk mengidentifikasi masalah, meningkatkan keamanan, dan mengoptimalkan pengalaman pengguna.
Langkah-langkah Memulai dengan Hadoop
Memulai dengan Hadoop mungkin tampak menantang, tetapi Anda dapat mengikuti langkah-langkah berikut untuk memudahkan prosesnya:
- Pahami Konsep Dasar: Sebelum Anda mulai, penting untuk memahami konsep dasar Hadoop. Pelajari tentang komponen utama seperti HDFS, YARN, dan MapReduce. Anda dapat menemukan banyak sumber daya online yang dapat membantu Anda memahami dasar-dasar ini.
- Siapkan Infrastruktur: Anda perlu menyiapkan infrastruktur yang memadai untuk menjalankan Hadoop. Pastikan Anda memiliki perangkat keras yang cukup untuk mendukung operasi Hadoop. Anda dapat memulai dengan beberapa server dan menambahkannya seiring dengan pertumbuhan kebutuhan Anda.
- Instalasi Hadoop: Setelah infrastruktur siap, Anda dapat menginstal Hadoop. Ikuti panduan instalasi yang tersedia di situs resmi Apache Hadoop. Pastikan Anda mengkonfigurasi setiap komponen dengan benar untuk memastikan sistem berjalan dengan lancar.
- Pelajari Pemrograman MapReduce: Untuk memanfaatkan Hadoop sepenuhnya, Anda perlu mempelajari pemrograman MapReduce. Anda dapat memulai dengan contoh-contoh sederhana dan secara bertahap meningkatkan kompleksitasnya. Banyak tutorial dan buku yang dapat membantu Anda mempelajari pemrograman MapReduce.
- Mulai dengan Proyek Kecil: Setelah Anda merasa nyaman dengan dasar-dasar Hadoop, mulailah dengan proyek kecil. Anda dapat mencoba menganalisis dataset publik atau mengembangkan aplikasi sederhana. Ini akan membantu Anda memahami cara kerja Hadoop dalam praktik.
- Optimalkan dan Skalakan: Seiring dengan pertumbuhan kebutuhan Anda, optimalkan dan skalakan sistem Hadoop Anda. Tambahkan lebih banyak node ke kluster Anda dan sesuaikan konfigurasi untuk meningkatkan kinerja. Anda dapat memanfaatkan komunitas Hadoop untuk mendapatkan saran dan dukungan.
Dengan mengikuti langkah-langkah ini, Anda dapat memulai perjalanan Anda dengan Hadoop dan memanfaatkan potensinya untuk mengatasi tantangan Big Data.
FanRuan dan Hadoop
Integrasi FineBI dengan Hadoop
Integrasi FineBI dengan Hadoop memberikan solusi yang kuat untuk analisis data besar. Dengan FineBI, Anda dapat menghubungkan berbagai sumber data, termasuk Hadoop, untuk mendapatkan wawasan yang lebih dalam. FineBI memanfaatkan kemampuan Hadoop dalam menyimpan dan memproses data besar secara efisien. Anda dapat mengakses data dari Hadoop dan mengolahnya dengan mudah menggunakan antarmuka FineBI yang intuitif.
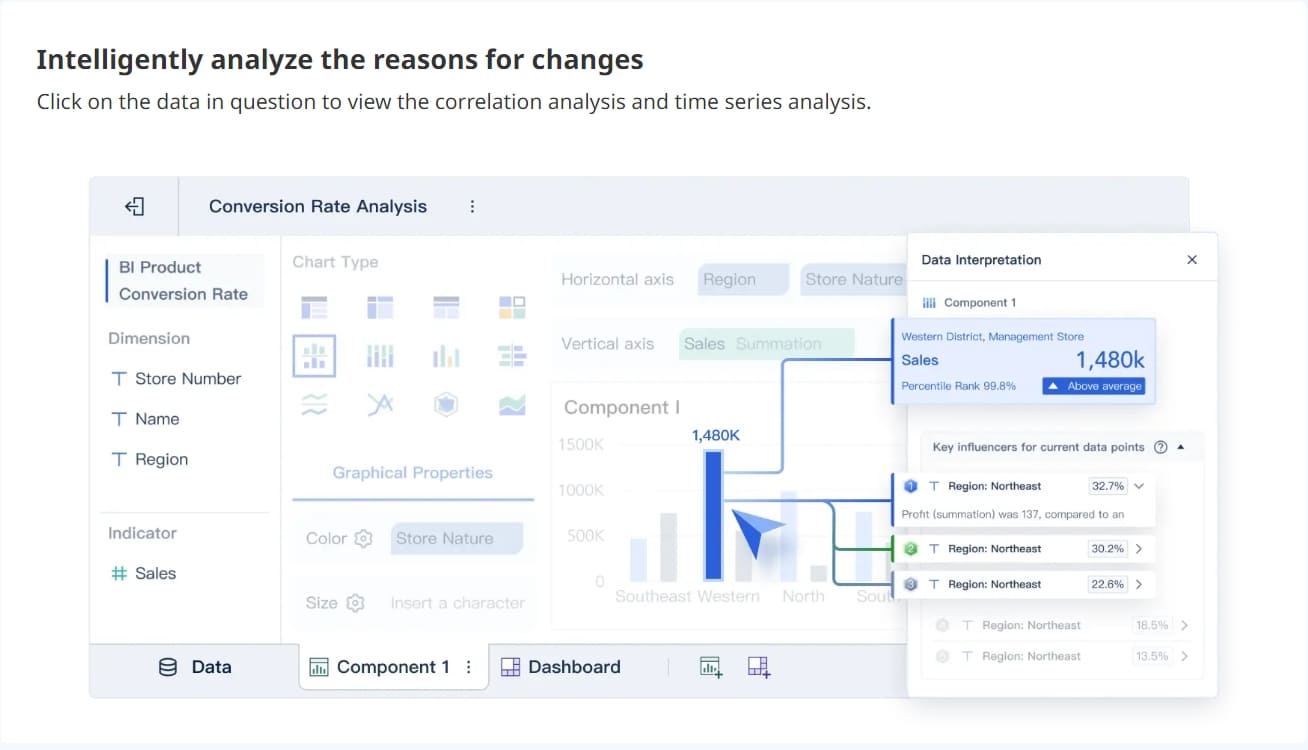
FineBI memungkinkan Anda untuk melakukan analisis data secara mandiri. Anda tidak perlu bergantung pada tim IT untuk mengakses dan menganalisis data dari Hadoop. Dengan fitur drag-and-drop, Anda dapat membuat visualisasi data yang menarik dan informatif. FineBI juga mendukung analisis real-time, sehingga Anda dapat memantau data terkini dan mengambil keputusan yang tepat waktu.
Manfaat Menggunakan FineBI untuk Analisis Data Hadoop
Menggunakan FineBI untuk analisis data Hadoop menawarkan berbagai manfaat yang signifikan:
- Kemudahan Penggunaan: FineBI dirancang untuk memudahkan pengguna dalam melakukan analisis data. Anda dapat dengan cepat menguasai proses analisis data tanpa perlu keahlian teknis yang mendalam. Ini memungkinkan Anda untuk fokus pada pengambilan keputusan berdasarkan data.
- Integrasi Data yang Kuat: FineBI menawarkan kemampuan integrasi data yang tangguh. Anda dapat menghubungkan berbagai sumber data, termasuk Hadoop, untuk analisis yang komprehensif. Ini memungkinkan Anda untuk mendapatkan gambaran yang lebih lengkap tentang bisnis Anda.
- Analisis Real-time: Dengan FineBI, Anda dapat melakukan analisis data secara real-time. Anda tidak perlu menunggu data diperbarui setelah diubah. Ini memungkinkan Anda untuk merespons perubahan kondisi bisnis dengan cepat dan membuat keputusan yang tepat waktu.
- Visualisasi Data yang Menarik: FineBI menyediakan berbagai jenis visualisasi data yang dapat membantu Anda memahami data dengan lebih baik. Anda dapat membuat dashboard yang menarik dan informatif untuk memantau kinerja bisnis Anda.
- Kolaborasi Tim: FineBI memfasilitasi kolaborasi tim dengan memungkinkan berbagi dan memodifikasi data di antara anggota tim. Ini mempromosikan kerja tim dan validasi data yang efisien.
Dengan memanfaatkan FineBI untuk analisis data Hadoop, Anda dapat meningkatkan efisiensi dan efektivitas dalam pengelolaan data. FineBI membantu Anda mengubah data mentah menjadi wawasan yang berharga, sehingga Anda dapat membuat keputusan yang lebih tepat dan cepat.
Hadoop telah membuktikan dirinya sebagai solusi yang andal dan efisien dalam mengolah data besar. Dengan kemampuannya untuk menyimpan dan memproses data dalam skala besar, Hadoop menjadi pilihan utama bagi banyak perusahaan global. Anda dapat memanfaatkan Hadoop untuk meningkatkan efisiensi dan efektivitas analisis data Anda. Kami mengajak Anda untuk mencoba implementasi Hadoop dan memanfaatkan FineBI untuk analisis data yang lebih mendalam. Dengan integrasi ini, Anda dapat mengubah data mentah menjadi wawasan berharga yang mendukung pengambilan keputusan yang lebih baik.
Lihat juga Tentang Hadoop
Pengertian Data Lake Dan Pentingnya Dalam Analisis Data
FAQ
Hadoop adalah kerangka kerja open-source yang dirancang untuk menyimpan dan memproses data besar secara terdistribusi. Anda mungkin bertanya-tanya mengapa Hadoop begitu penting. Hadoop memungkinkan Anda untuk mengatasi tantangan Big Data seperti volume, kecepatan, dan keragaman data. Dengan Hadoop, Anda dapat menyimpan dan memproses data dalam jumlah besar dengan cepat dan efisien.
Hadoop bekerja dengan membagi data menjadi blok-blok kecil yang disimpan di berbagai node dalam kluster. Anda dapat memproses data ini secara paralel menggunakan model pemrograman MapReduce. Proses ini memungkinkan Anda untuk memanfaatkan kekuatan komputasi dari seluruh kluster, sehingga meningkatkan efisiensi pemrosesan data.
Hadoop terdiri dari beberapa komponen utama, yaitu:
Hadoop dianggap efisien karena dapat bekerja dengan perangkat keras komoditas, sehingga mengurangi biaya. Anda dapat menambah atau mengurangi jumlah node dalam kluster sesuai kebutuhan, menjadikannya sangat skalabel. Selain itu, Hadoop memiliki kemampuan toleransi kesalahan, yang berarti data Anda tetap aman meskipun terjadi kegagalan perangkat keras.
Menggunakan FineBI dengan Hadoop memberikan berbagai manfaat, seperti:
Untuk memulai dengan Hadoop, Anda dapat mengikuti langkah-langkah berikut:
- Pahami konsep dasar Hadoop.
- Siapkan infrastruktur yang memadai.
- Instal Hadoop dan konfigurasikan komponen-komponennya.
- Pelajari pemrograman MapReduce.
- Mulai dengan proyek kecil dan tingkatkan kompleksitasnya seiring waktu.
Menggunakan Hadoop dapat menimbulkan beberapa tantangan, seperti:
Hadoop sangat cocok untuk data yang besar dan tidak terstruktur. Anda dapat menyimpan dan memproses berbagai jenis data, termasuk teks, gambar, dan video. Namun, untuk data yang sangat terstruktur, mungkin ada solusi lain yang lebih efisien.
Hadoop membantu dalam transformasi digital dengan memungkinkan perusahaan untuk mengelola dan menganalisis data dalam jumlah besar. Anda dapat menggunakan Hadoop untuk mendapatkan wawasan yang lebih dalam tentang bisnis Anda, meningkatkan efisiensi operasional, dan menciptakan inovasi baru.

Lanjutkan Membaca Tentang Hadoop
10 Tools Terbaik Untuk Analisis Data
Kita akan mempelajari apa alat analisis data, cara memilih software ang tepat, dan 10 alat dan software analisis data terbaik yang tersedia di pasar.
Lewis
2024 Agustus 07
15 Rekomendasi Tools Visualisasi Data Terbaik
Kita akan mengeksplorasi pentingnya alat visualisasi data, memandu Anda tentang cara memilih, dan memberi Anda daftar lengkap alat visualisasi data.
Lewis
2024 Agustus 12
Apa Itu Boxplot ? Pengertian, Fungsi, dan Cara Kerjanya
Boxplot adalah alat visualisasi statistik yang menampilkan distribusi data melalui median, kuartil, dan outlier untuk analisis data yang lebih dalam dan jelas.
Lewis
2024 November 19
Apa itu Analisis Data : Arti, Metode, Jenis, dan Manfaatnya
Apa itu analisis data? Analisis data adalah proses mengolah informasi untuk menemukan pola, tren, dan wawasan yang berguna dalam pengambilan keputusan.
Lewis
2025 Februari 24
Apa Itu Data Analis dan Perannya di Era Digital
Data analis adalah profesional yang mengolah data menjadi wawasan strategis. Perannya penting di era digital untuk mendukung keputusan berbasis data.
Lewis
2025 Maret 06
Alternatif Power BI : 10 Rekomendasi Terbaik
Dalam artikel ini, kita akan membahas 10 alternatif Power BI terbaik termasuk fitur-fitur mereka. Power BI adalah alat intelijen bisnis yang kuat dan populer.
Lewis
2024 Juli 26

