数据分析前必做什么?答案是数据清洗
在数据处理过程中,原始数据常常存在缺失值、重复值和异常值等问题。这些问题会在数据分析中对结果产生干扰,降低分析结果的准确性和可靠性。因此在进行数据分析前,需要进行数据清洗。
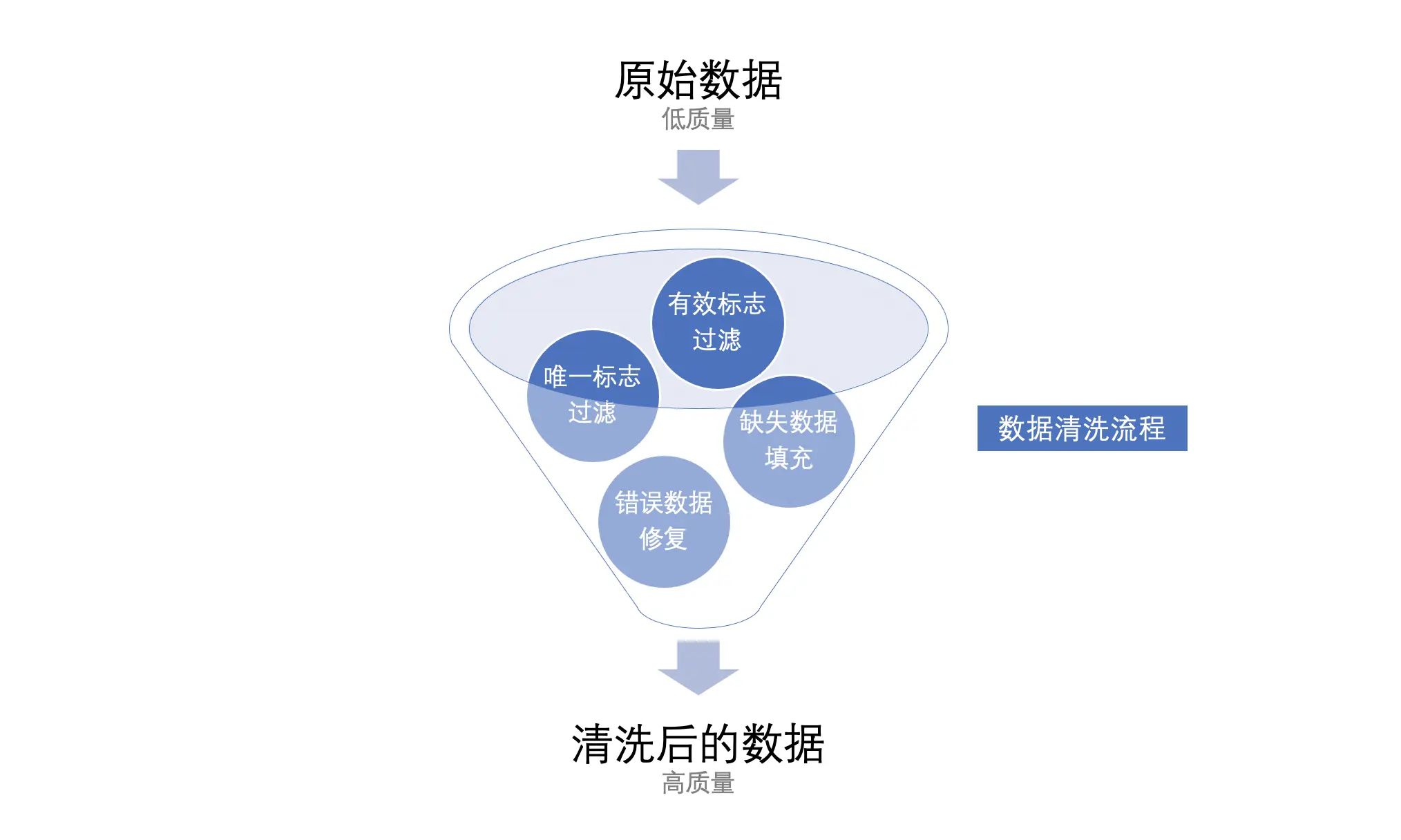
什么是数据清洗
数据清洗是指对数据进行检查、纠正、删除或者替换等操作,以确保数据的一致性、准确性、完整性和可信度。数据清洗的目的是让数据更好地满足分析要求,提高分析效率和准确度。
数据清洗包括对缺失值、重复值和异常值等数据进行清理。缺失值指数据集中某些数据因各种原因无法收集或者丢失,需要进行填充或者删除处理。重复值指数据集中出现重复数据记录,需要进行去重处理。异常值则是指数据值与整体数据分布出现显著偏差,需要进行剔除或者替换处理。
总之,在进行数据分析前,数据清洗是必不可少的一步。通过正确处理数据集中存在的问题,可以得到更准确的数据结果,提高分析结果的可靠性和可行性。

为什么需要数据清洗
ETL是企业数据管理中的一个重要环节,主要负责将不同来源、异构的数据源进行抽取、转换和加载,从而将数据整合成规范化、一致化的格式,以满足数据分析和其他业务需要。
在ETL过程中,数据清洗是非常重要的一个步骤,因为保证数据质量是ETL过程的基础。通过对数据进行清洗、格式化、转换和验证等操作,可以确保数据的完整性、一致性和准确性,从而提高ETL流程的质量和效率。
在数据分析过程中,ETL过程的干净数据对于提高数据分析的效率和准确度非常重要。在ETL中,数据清洗会清除数据中存在的噪声、错误、重复和无效数据等问题,从而提高数据质量,以确保在数据分析过程中准确性和可靠性。
总之,ETL中的数据清洗是非常重要的环节,通过对数据进行清洗、格式化和转换等操作,以确保数据质量和准确性。只有保证了干净的数据,才能更好地进行数据分析和决策支持。
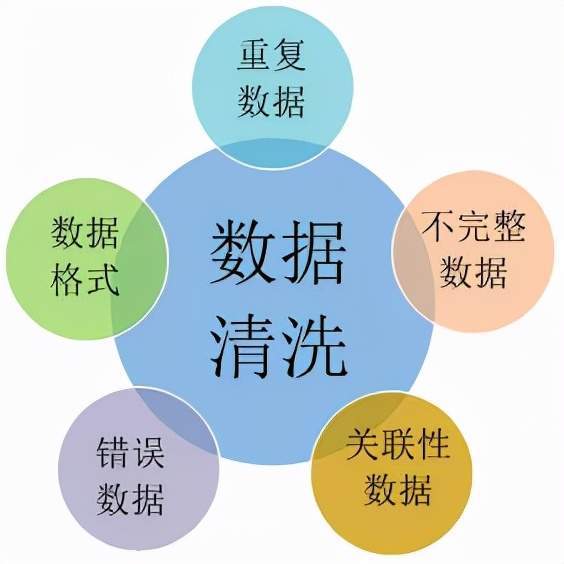
数据清洗的对象是什么
数据清洗的主要对象包括缺失值、重复值和异常值等。
1. 缺失值:指数据集中某些数据因各种原因无法收集或者丢失,导致数据不完整,对后续数据分析和决策造成影响。常见的处理方法包括删除或者填充缺失值。
2. 异常值:指数据值与整体数据分布出现显著偏差,可能是由于测量误差、录入错误或者其他原因造成的。异常值会对数据分析造成干扰和误导,处理方法包括剔除、替换或者标记等。
3. 重复值:重复值的存在会对数据分析产生混淆和误导,常见的处理方法包括基于列或字段去重和基于记录去重。处理重复值可以减少数据冗余,提高数据分析效率。
需要根据具体情况选择合适的数据清理方法和工具,从而确保数据的一致性、准确性和可信度,保证数据分析过程和结果的正确性和可靠性。
FineDataLink是一款低代码/高时效的数据集成平台,它不仅提供了数据清理和数据分析的功能,还能够将清理后的数据快速应用到其他应用程序中。FineDataLink的功能非常强大,可以轻松地连接多种异构数据源,包括数据库、文件、云存储等。此外,FineDataLink还支持高级数据处理功能,例如数据转换、数据过滤、数据重构、数据集合等。使用FineDataLink可以显著提高团队协作效率,减少数据连接和输出的繁琐步骤,使整个数据处理流程更加高效和便捷。







 立即沟通
立即沟通

