什么是数据集成工具?8款数据集成工具超全介绍!
在数字化时代,数据已成为企业和社会发展的核心驱动力。然而,随着数据的快速增长和多样化,如何有效地管理和利用这些数据成为了一个巨大的挑战。为了解决这个问题,数据集成工具应运而生。
一、数据集成工具是什么
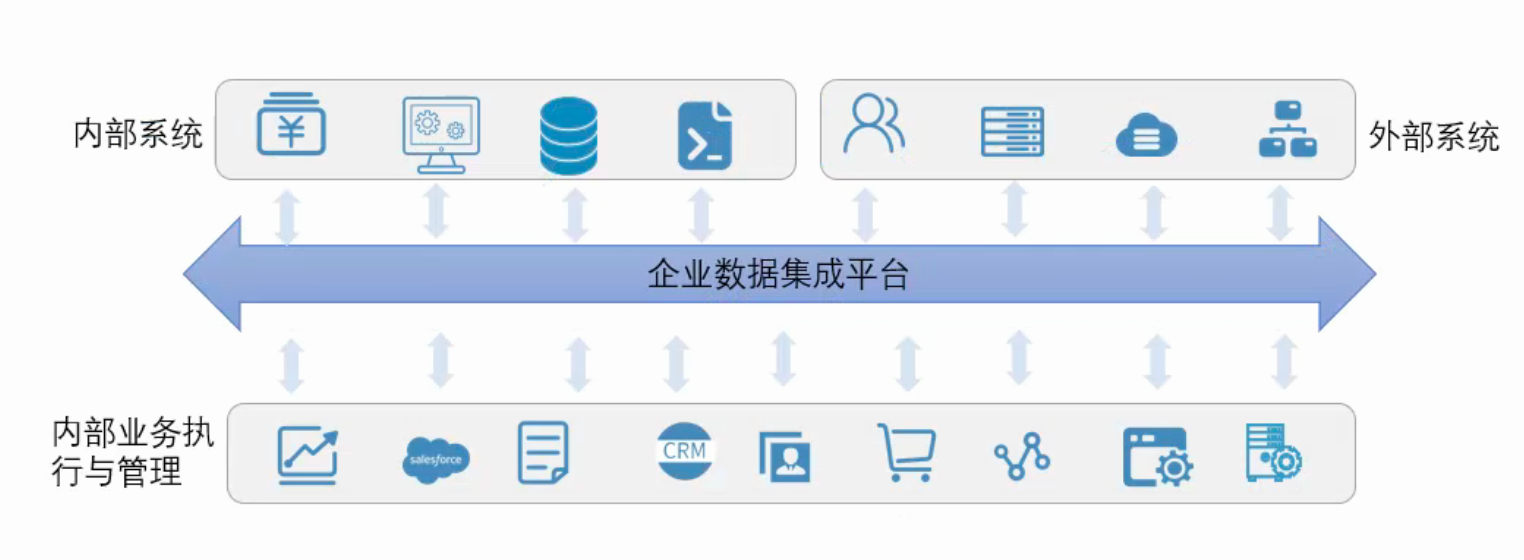
数据集成工具是一种在数据管理和分析领域中广泛使用的软件工具,主要用于帮助组织从各种不同来源的数据中提取、转换和加载数据。旨在将来自不同来源的信息(例如不同的数据库类型和文件)整合到一个统一的平台中,从而为最终用户提供有价值的见解。
数据集成工具不仅能够帮助我们实现数据的整合和共享,还能够提高数据的质量和可用性。它们通过强大的数据抽取、转换和加载功能,将不同来源、格式和质量的数据进行统一处理,确保数据的一致性和准确性。同时,这些工具还提供了灵活的企业数据管理和监控功能,帮助我们更好地理解和利用数据,发现企业数据管理的价值。
二、8款数据集成工具推荐
以下是8款数据集成工具每个工具的详细特性介绍:
1.Apache Nifi:
a.可视化控制:
Nifi提供了一个直观的可视化界面,允许用户以图形方式展现和编辑数据流,从而更轻松地处理数据流。
b.实时修改:
在数据流上进行的修改可以立即生效,这意味着用户可以在不停止整个流处理过程的情况下进行局部修改。
c.数据背压:
Nifi提供队列缓存功能,当生产速度大于消费速度时,能够提供数据背压能力。
d.高扩展性:
Nifi的设计使其具有高扩展性,可以适应不同的数据处理需求。
e.优先级队列:
Nifi允许用户设置一个或多个优先级方案,以满足不同的数据处理需求,如先进先出、后进先出等。
2.Talend:
a.多种数据源支持:
Talend支持各种常用数据库(如MySQL、Oracle、Hive)和文件等数据源。
b.速度优化:
对特定数据源有优化处理,以提高数据处理速度。
c.部署灵活:
可以通过创建Java或Perl文件,并使用操作系统调度工具来运行。
d.易用性:
提供GUI图形界面,但通常以Eclipse插件的形式提供。
3.Apache Kafka:
a.消息文件存储:
Kafka具有消息堆积能力,可以处理大量的消息数据。
b.消息Topic分区:
消息可以根据Topic进行分区处理,提高数据处理效率。
c.消息顺序保证:
Kafka保证消息的顺序性,确保数据处理的准确性。
d.拉模型:
采用消费者水平扩展的方式,支持大量的消费者同时处理消息。
e.高吞吐量:
Kafka的设计目标之一是高吞吐量,即使在普通硬件上也可以支持每秒数十万的消息。
f.数据持久化:
通过O(1)的磁盘数据结构提供消息的持久化,保证数据的稳定性。
4.Flink:
a.高吞吐和低延迟:
Flink可以每秒处理数百万个事件,并具有毫秒级的延迟。
b.结果准确性:
提供了事件时间(event-time)和处理时间(processing-time)语义,即使在乱序事件流中也能提供一致且准确的结果。
c.状态一致性:
Flink保证了精确一次(exactly-once)的状态一致性。
d.连接性:
可以轻松连接到常用的存储系统,如Apache Kafka、Elasticsearch、JDBC和HDFS。
e.高可用性和动态扩展:
Flink具有高可用性设置,可以与K8s和YARN紧密集成,具有从故障中快速恢复和动态扩展任务的能力。
f.分层API:
提供了从底层到有状态的流处理函数,到核心API(如DataStream API和DataSet API),再到声明式的Table API的多个抽象层级。
5.AWS Glue:
a.无服务器数据集成:
AWS Glue是一项无服务器数据集成服务,允许用户轻松发现、准备、移动和集成来自多个来源的数据。
b.全面功能:
提供了数据发现、现代ETL、数据清理、转换和集中式编目等功能。
c.灵活性:
可以灵活支持ETL、ELT和流式传输等多种工作负载。
d.生产力工具:
包括用于编写、运行任务和实施业务工作流程的额外生产力和数据操作工具。
6.Google Cloud Dataflow:
a.结构化文档处理:
旨在以相同的编程模型在批处理和流模式下处理数据。
b.错误处理:
提供了一个特殊的错误处理界面,可以管理可能导致永久性损害的错误。
c.自动化:
通过自动扩展和将任务分成小块,让虚拟机同时工作,从而快速完成数据处理。
d.无服务器方法:
减轻了管理计算机资源的负担,实现了数据流的自动化。
e.服务支持:
提供了从Shuffle到SQL到模板的各种服务,以加强和优化数据处理流程。
7.Azure Data Factory:
a.云端数据集成:
是一个部署于云端的数据集成服务系统,允许在本地和云端之间转移数据。
b.创建和编排数据流:
可以创建和编排复杂的数据流,并制定全面托管的作业。
c.自动化:
实现了自动的、按期执行的、无需人为干预的数据流。
8.FineDataLink
a.实时数据同步:
基于CDC、binlog、LogMiner等技术实现实时增量同步数据,避免了对源数据的影响,从而响应大数据量数据实时同步的需求。
b.数据处理:
支持ELT和ETL两种数据处理模式,提供可视化开发模式,构建复杂的调度依赖,打造符合企业级数仓的功能模块,为数字化转型提供支持。
c.数据服务:
低成本构建数据集成服务,依托于API构建企业级数据资产,实现企业数据管理互通共享。
d.系统管理:
提供协同任务开发平台,实时监控等功能,方便用户对系统进行管理和维护。
e.部署灵活:
可以在Windows或Linux环境上进行单机或集群部署,全程基于B/S浏览器端进行任务开发和任务运维。
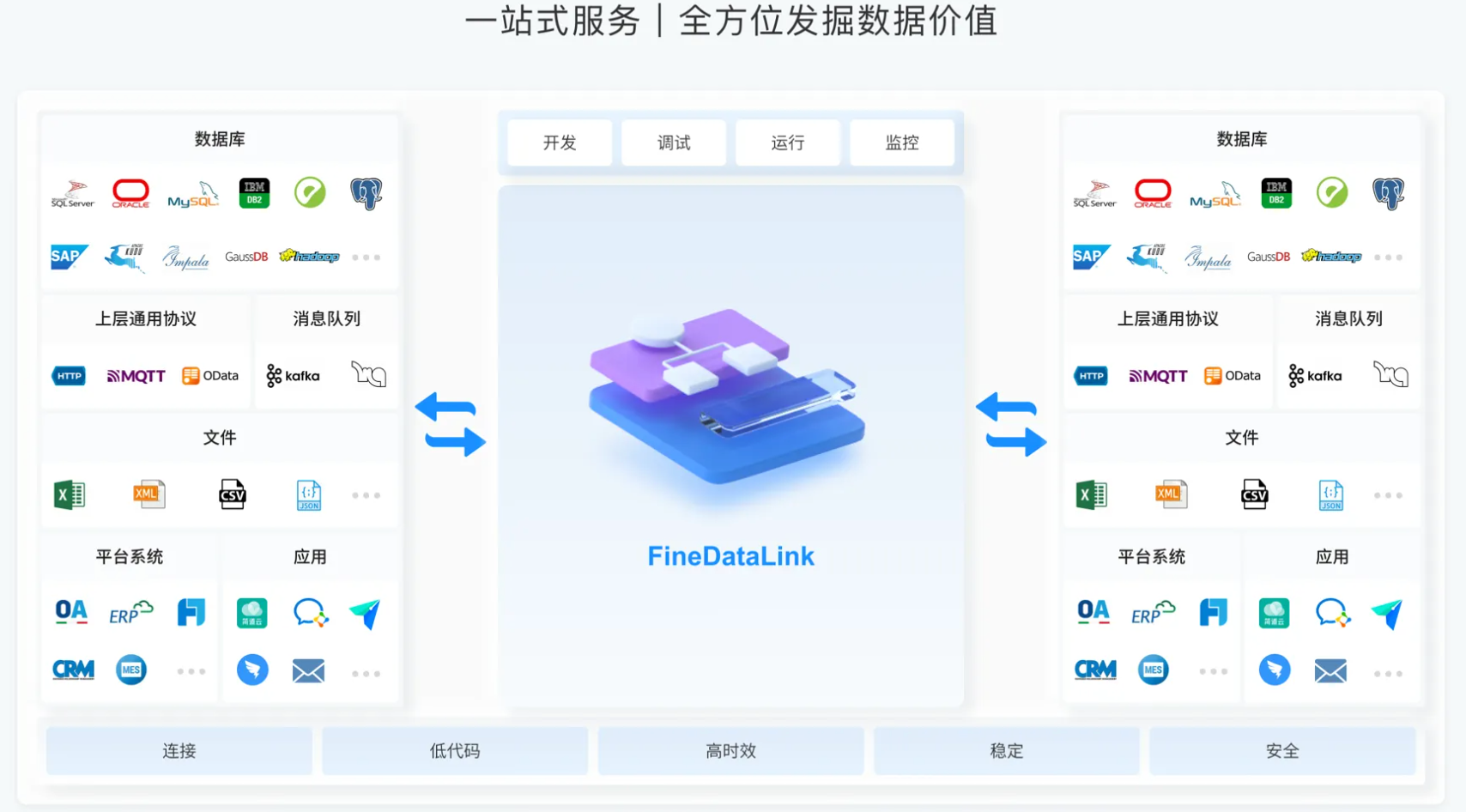
很显然在目前的信息时代,借助类似于FineDataLink的这些工具,可以让企业加速融入企业数据集成和分析的趋势。备受市场认可的软件其实有很多,选择时必须要结合实际的情况。一般的情况下,都建议选择市面上较主流的产品,比较容易达到好的效果,就是帆软的数据集成平台——FineDataLink。它是一款低代码/高效率的ETL工具,可以帮助企业快速构建数据仓库,对数据进行管理、分析和使用,提高数据治理效率和质量。同时,帆软FDL也支持开放API和服务接口,可以与其他数据工具和系统进行整合和拓展。






 立即沟通
立即沟通

