Downtime yang tinggi bukan hanya masalah teknis. Bagi Operations Director, downtime adalah masalah margin, kapasitas, service level, dan kepercayaan pelanggan. Ketika data produksi tersebar di mesin, MES, ERP, spreadsheet, dan sistem maintenance, keputusan menjadi lambat, akar masalah kabur, dan tim hanya bereaksi setelah line berhenti.
Manufacturing analytics membantu mengubah kondisi itu. Dengan analitik yang tepat, tim operasi dapat melihat sumber gangguan lebih cepat, memprioritaskan masalah berdasarkan dampak bisnis, dan mengeksekusi tindakan korektif sebelum kehilangan output membesar. Nilai bisnisnya jelas: downtime turun, OEE membaik, biaya maintenance lebih terkendali, dan utilisasi aset meningkat.
Panduan ini dirancang untuk Operations Director yang ingin membangun pendekatan praktis, bukan sekadar laporan. Fokusnya adalah KPI yang benar-benar penting, dashboard yang benar-benar dipakai, dan langkah operasional yang benar-benar menurunkan downtime.
Manufacturing analytics adalah proses mengumpulkan, mengintegrasikan, menganalisis, dan memvisualisasikan data dari operasi manufaktur untuk mendukung keputusan yang lebih cepat dan akurat. Dalam konteks downtime, tujuannya bukan hanya mengetahui bahwa mesin berhenti, tetapi mengapa berhenti, pola apa yang berulang, area mana yang paling mahal dampaknya, dan tindakan apa yang harus diprioritaskan.
Bagi operasi manufaktur modern, analitik berperan sebagai lapisan visibilitas di atas sistem produksi. Data dari sensor mesin, histori alarm, output line, work order maintenance, scrap, changeover, dan jadwal produksi digabungkan agar tim dapat melihat performa aktual secara menyeluruh.
Hubungannya dengan penurunan downtime sangat langsung:
Tantangan paling umum yang dihadapi Operations Director adalah data berada di banyak tempat dan tidak berbicara dalam definisi yang sama. Tim maintenance melihat MTTR, produksi melihat output, quality melihat reject rate, dan finance melihat biaya. Tanpa kerangka manufacturing analytics yang konsisten, organisasi sulit menyepakati masalah utama, apalagi menyelesaikannya secara sistematis.
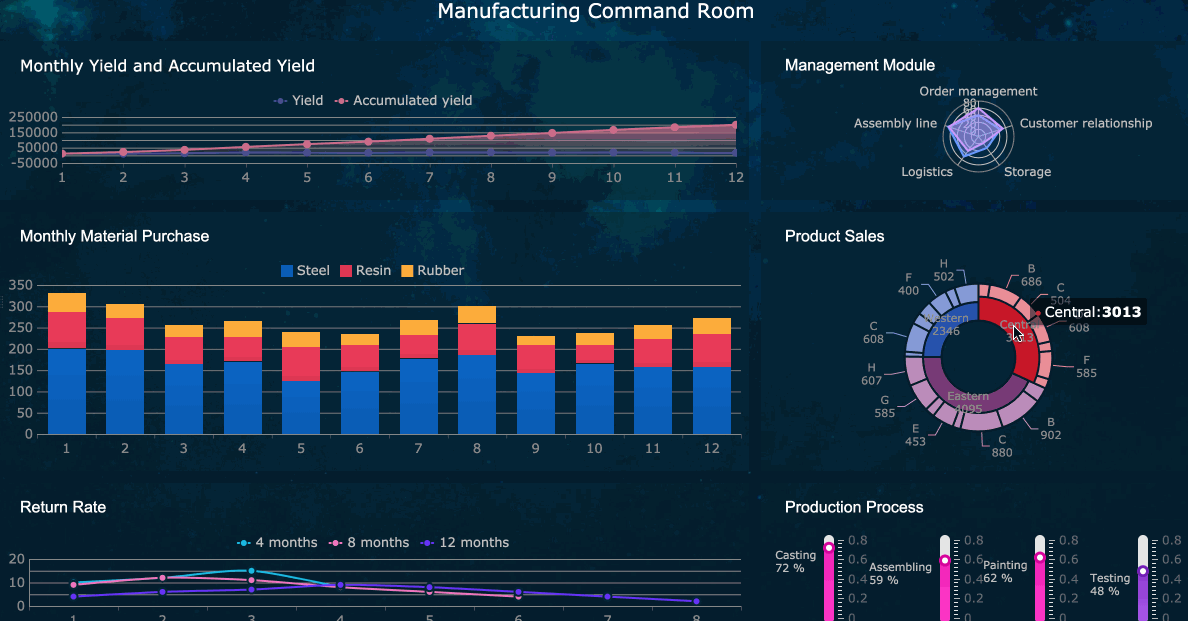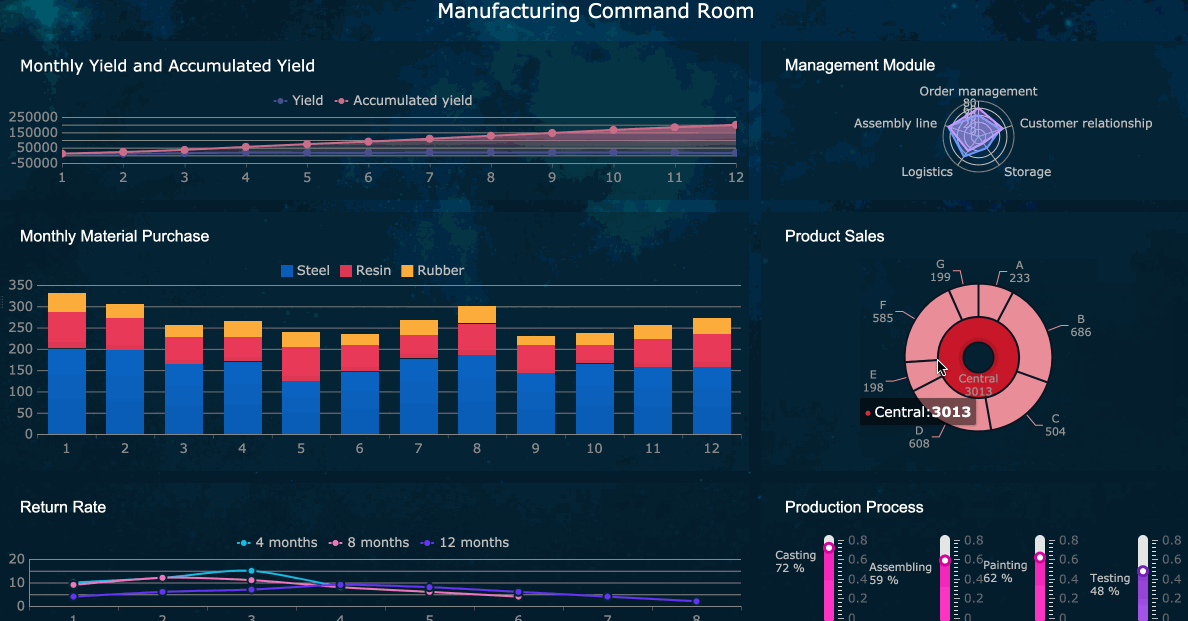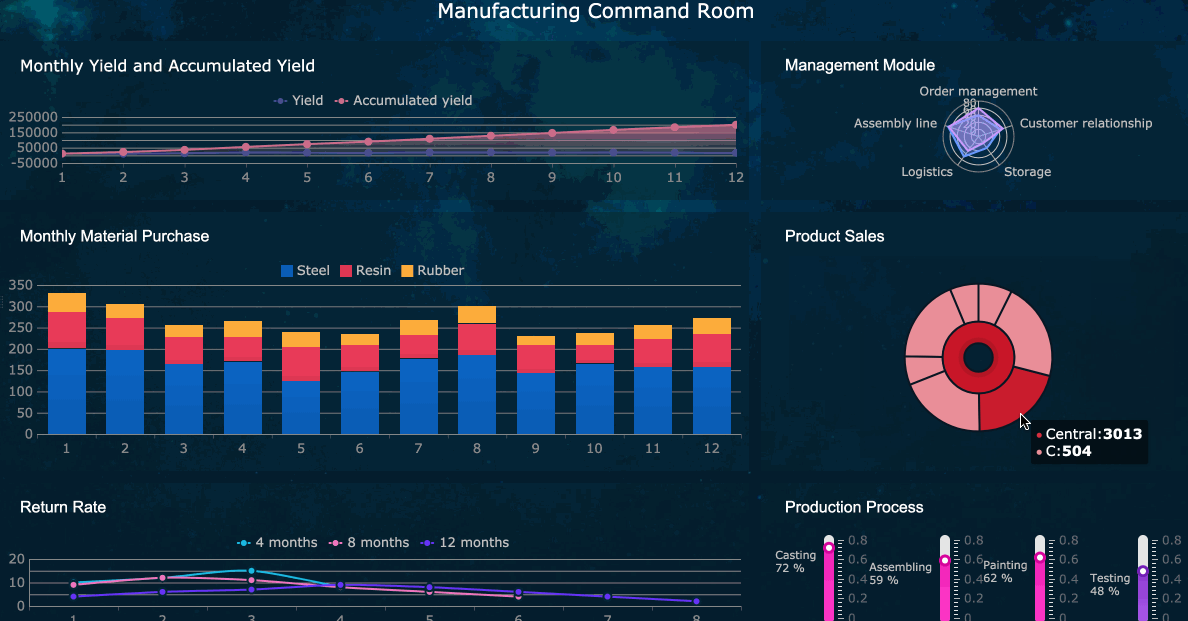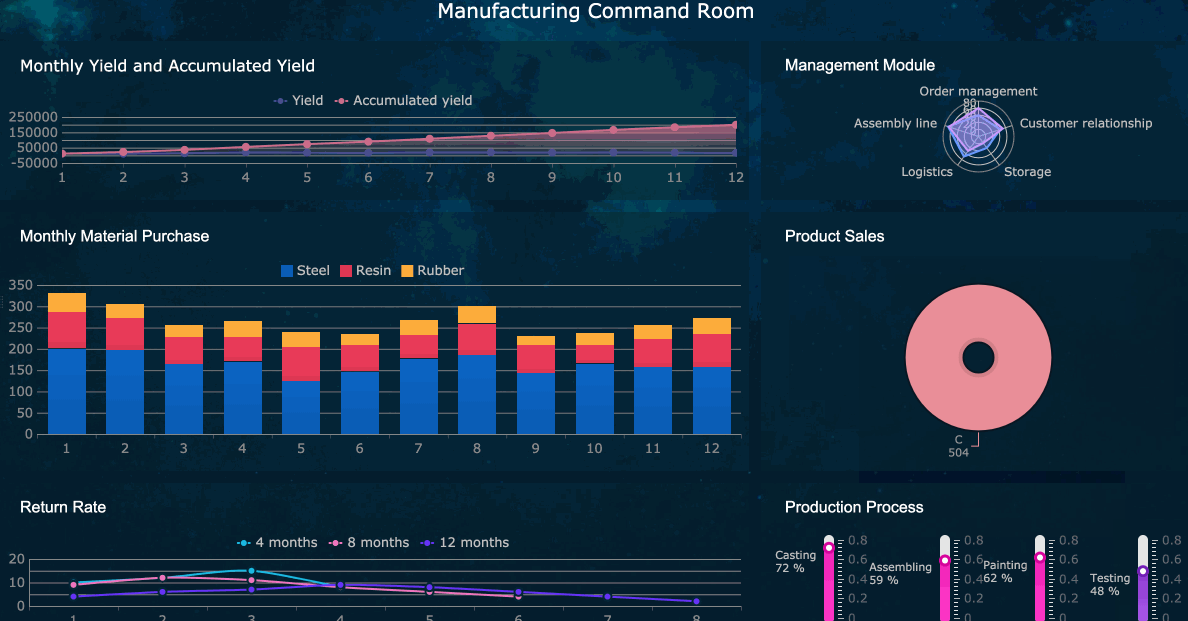
Agar manufacturing analytics berdampak nyata, KPI harus dipilih berdasarkan kemampuan untuk mendeteksi, menjelaskan, dan mengurangi downtime. Jangan mulai dengan puluhan metrik. Mulailah dengan KPI inti yang menghubungkan performa mesin ke hasil bisnis.
OEE adalah metrik paling umum untuk melihat efektivitas produksi secara keseluruhan. Namun, nilainya hanya berguna jika tim memahami komponen penyusunnya.
Cara membacanya:
Untuk penurunan downtime, availability biasanya menjadi pintu masuk paling jelas. Namun, Operations Director perlu melihat hubungan antar komponen. Mesin yang jarang berhenti tetapi sering berjalan lambat tetap merusak throughput.
Ketika fokus bergeser dari output harian ke keandalan aset, metrik reliability menjadi lebih berguna.
Kapan metrik ini lebih berguna dibanding sekadar output harian?
Contohnya, dua mesin bisa kehilangan output yang sama. Tetapi satu mesin sering berhenti singkat, sedangkan yang lain jarang berhenti namun sekali rusak butuh 4 jam perbaikan. Strategi perbaikannya jelas berbeda.
Banyak tim operasi terlalu fokus pada lagging indicator seperti total downtime bulanan. Itu penting, tetapi sifatnya reaktif. Untuk benar-benar mencegah gangguan, Anda perlu lead indicator.
Contoh indikator dini yang efektif:
Lead indicator memberi waktu bagi tim untuk bertindak sebelum downtime mahal terjadi.
Dashboard yang efektif bukan dashboard yang paling lengkap. Dashboard yang efektif adalah dashboard yang membuat orang tahu apa yang salah, seberapa besar dampaknya, dan siapa yang harus bertindak dalam beberapa detik.
Setiap peran membutuhkan level informasi berbeda. Salah satu kesalahan paling umum adalah menampilkan data yang sama untuk semua orang.
Butuh ringkasan strategis dan lintas plant atau lintas line:
Butuh visibilitas operasional tingkat pabrik:
Butuh data cepat untuk eksekusi harian:
Butuh data diagnosis dan reliabilitas:
Prinsip utamanya: setiap dashboard harus selaras dengan keputusan yang dibuat oleh penggunanya.
Visual yang salah memperlambat tindakan. Visual yang tepat mempercepat pemahaman.
Gunakan jenis visual berikut secara selektif:
Prinsip desain dashboard yang baik:
Nilai manufacturing analytics hanya sekuat integrasi datanya. Jika definisi stop time berbeda antara MES dan CMMS, dashboard akan diperdebatkan, bukan dipakai.
Hal penting saat menghubungkan sumber data:
Untuk enterprise manufacturing, integrasi yang konsisten lebih penting daripada mencoba menghubungkan semua sumber data sekaligus. Mulai dari data minimum yang dibutuhkan untuk satu use case downtime, lalu perluas secara bertahap.
Manufacturing analytics baru bernilai saat insight berubah menjadi tindakan. Berikut pendekatan yang paling efektif di lapangan.
Jangan mulai dari aset yang paling sering dikeluhkan. Mulailah dari aset yang paling besar dampak bisnisnya.
Gunakan tiga dimensi prioritas:
Praktiknya:
Pendekatan ini memberi hasil lebih cepat dibanding menyebar sumber daya ke terlalu banyak inisiatif.
Downtime berulang jarang diselesaikan hanya dengan mengganti komponen. Anda perlu membedakan gejala, penyebab langsung, dan akar masalah.
Pendekatan yang disarankan:
Tanda bahwa organisasi belum menemukan akar masalah adalah ketika kode penyebab yang sama terus muncul tetapi tindakan korektif selalu bersifat sementara.
Dashboard tanpa ritme review hanya menjadi layar pasif. Untuk menurunkan downtime, Anda perlu mekanisme tindak lanjut yang disiplin.
Struktur yang efektif:
Rapat harian 10–15 menit
Review mingguan lintas fungsi
Review bulanan manajemen
Agar ritme ini berjalan, setiap aksi korektif harus punya:
Sebagai panduan praktis, berikut 5 langkah implementasi yang paling sering berhasil:
Definisikan satu use case downtime yang spesifik
Sepakati definisi KPI lintas fungsi
Bangun dashboard per peran, bukan dashboard generik
Hubungkan insight dengan workflow tindakan
Review hasil tiap 2–4 minggu dan sesuaikan
Untuk banyak organisasi, kesalahan terbesar adalah mencoba membangun program manufacturing analytics skala besar sejak hari pertama. Pendekatan yang lebih aman adalah mulai kecil, fokus, dan cepat membuktikan nilai.
Pilih target 30–90 hari yang dapat menunjukkan hasil nyata.
Contoh target awal:
Karakteristik use case yang baik:
Manufacturing analytics bukan proyek IT semata. Ini adalah program lintas fungsi.
Peran yang perlu terlibat:
Elemen tata kelola yang wajib ada:
ROI harus diterjemahkan dalam bahasa operasional dan bahasa manajemen puncak.
Indikator keberhasilan yang umum digunakan:
Rumus praktis untuk mengukur ROI:
Agar perbaikan berkelanjutan:
Banyak inisiatif manufacturing analytics gagal bukan karena teknologinya lemah, tetapi karena implementasinya tidak fokus.
Jika dashboard menampilkan 30 KPI tetapi tidak jelas mana yang harus direspons hari ini, tim akan berhenti memperhatikan semuanya. Pilih KPI yang langsung terkait dengan downtime, keandalan, dan dampak bisnis.
Visual yang menarik tidak otomatis berguna. Jika supervisor masih harus bertanya ke beberapa orang untuk tahu apa yang harus dilakukan, berarti dashboard belum efektif.
Laporan hanya menunjukkan masalah. Penurunan downtime terjadi saat organisasi memperbaiki SOP, mempercepat eskalasi, meningkatkan PM, dan menutup akar masalah.
Bahkan dashboard terbaik akan gagal jika operator, supervisor, dan maintenance tidak percaya pada datanya. Bangun kepercayaan melalui definisi yang konsisten, validasi rutin, dan pelibatan pengguna sejak awal.
Secara teori, Anda bisa membangun sistem manufacturing analytics sendiri dengan kombinasi spreadsheet, BI tool umum, integrasi custom, dan proses manual. Dalam praktiknya, pendekatan ini sering memakan waktu, sulit diskalakan, dan rentan terhadap masalah definisi data, maintenance dashboard, serta adopsi pengguna.
Untuk Operations Director yang membutuhkan hasil lebih cepat, FineReport menjadi enabler yang jauh lebih praktis. Pendekatannya sederhana: membangun ini secara manual itu kompleks; gunakan FineReport untuk memanfaatkan template siap pakai dan mengotomatisasi seluruh workflow ini.
Dengan FineReport, tim dapat:
Bagi organisasi manufaktur, nilai utamanya bukan sekadar visualisasi. Nilainya ada pada kemampuan untuk mengubah data operasional menjadi sistem keputusan yang konsisten, cepat, dan bisa dijalankan tim setiap hari.
Jika target Anda adalah menurunkan downtime secara terukur, mulailah dengan satu use case prioritas, satu set KPI yang jelas, dan satu dashboard yang benar-benar digunakan. Setelah itu, standarkan ritme tindak lanjut dan perluas cakupan secara bertahap. Dengan dukungan platform seperti FineReport, proses ini menjadi jauh lebih cepat, lebih terstruktur, dan lebih mudah dibuktikan ROI-nya.
Manufacturing analytics membantu tim melihat penyebab gangguan lebih cepat, menyatukan data dari berbagai sistem, dan memprioritaskan tindakan berdasarkan dampak bisnis. Hasilnya biasanya terlihat pada turunnya downtime, naiknya OEE, dan membaiknya utilisasi aset.
OEE perlu dilihat bersama komponen availability, performance, dan quality agar akar masalah lebih jelas. Jika availability rendah, fokus awal biasanya ada pada breakdown, setup lama, waiting material, atau changeover yang tidak efisien.

Penulis
Yida Yin
Pakar Solusi Industri di FanRuan
Artikel Terkait
IoT Adalah dan Cara Kerjanya dalam Predictive Maintenance Manufaktur: Implementasi + Dashboard
Sebagai seorang IT Manager atau Operations Director di sektor manufaktur, Anda pasti sering bergulat dengan $1 mesin yang tak terduga, biaya pemeliharaan yang melonjak, dan tekanan untuk meningkatkan Overall Equipment Ef
Yida Yin
2026 Juni 11

8 Contoh Aplikasi SCM untuk Manufaktur, Distribusi, Retail, dan Logistik: Mana yang Paling Cocok?
$1 adalah platform reporting dan $1 enterprise yang membantu bisnis memantau $1 $1 secara real time agar keputusan operasional lebih cepat dan akurat. Ringkasan 8 contoh aplikasi SCM dan cara memilih yang paling cocok Be
Yida Yin
2026 Mei 18

Apa Itu MES? Panduan Praktis Direktur Operasi untuk Memahami Peran MES di Lantai Produksi
Jika Anda memimpin operasi manufaktur dan masih mengandalkan spreadsheet, $1 akhir shift, atau data mesin yang tersebar di banyak sistem, maka pertanyaan apa itu MES bukan lagi sekadar istilah teknis. Ini adalah pertanya
Yida Yin
2026 Mei 13



