在數位時代裡,企業每天都會產生大量資料:網站瀏覽紀錄、交易明細、客服對話、感測器訊號、社群互動、物流軌跡,甚至是影像與語音。這些資料若能被有效蒐集、整理與分析,就能成為決策依據;若無法處理,則只會堆積成看不見價值的資訊負擔。
因此,很多人都會問:什麼是大數據?它和一般資料有什麼不同?企業為什麼都在談大數據分析、AI 與資料治理?
這篇文章會從零開始,帶你完整理解大數據的定義、5V 特性、核心技術、分析方法、實際應用、常見挑戰,以及企業如何從打破資料孤島開始,真正走向數據驅動決策。
一、大數據的定義與傳統數據的差異
1. 什麼是大數據
大數據(Big Data),指的是規模龐大、產生速度快、資料類型多元,且難以用傳統資料庫與人工方式有效處理的資料集合。它不只是「資料很多」而已,更重要的是:企業必須借助新的架構、工具與分析方法,才能從中找出可行動的洞察。
當企業的資料同時出現資料量持續爆增、來源分散在不同系統、包含非結構化影音日誌、需要接近即時地被分析,且傳統 Excel 或單一資料庫已經難以負荷時,就很可能已經進入大數據範疇。例如電商平台分析數百萬筆商品的瀏覽紀錄、製造業監控產線設備的即時感測、金融機構偵測秒級異常交易,或是零售通路整合門市與會員資料等,都是典型的大數據場景。
所以,如果你正在思考什麼是大數據,最核心的答案是:大數據是一種資料規模與處理需求的變化,迫使企業用新的方式管理、分析與運用資料。
2. 大數據與傳統數據的關鍵對比

大數據與傳統數據最大的差異,不只在「量」,更在於整體資料處理模式的不同。為了讓您更直觀地理解兩者的轉變,我們可以透過以下維度進行對比:
| 評估維度 | 傳統數據 | 大數據(Big Data) |
|---|---|---|
| 資料規模 | 規模有限(通常在 GB 等級以下) | 大量暴增(達到 TB、PB 級以上規模) |
| 資料類型 | 多半是結構化表格與數字 | 同時包含結構化、半結構化與非結構化資料 |
| 儲存架構 | 主要儲存在單一關聯性資料庫(RDBMS) | 分散於 ERP、CRM、IoT、網站等多來源底座 |
| 處理速度 | 更新頻率較低,以定期批次結算為主 | 有即時(Real-time)或準即時的分析與回應需求 |
| 核心價值 | 以報表查詢與歷史分析來描述過去 | 不只描述過去,更旨在預測未來與驅動自動化行動 |
你可以把兩者想像成:傳統數據像是一本整理好的固定帳本,而大數據則像是持續湧入的多語言、多格式、多來源資訊流。這也是為什麼很多企業明明「有很多資料」,卻仍然無法形成決策力。問題不在資料不足,而在於缺乏整合、治理與分析能力。
二、大數據的 5V 特性解析

1. 數量 (Volume)
Volume 指的是資料規模巨大,這是大數據最直觀的特徵。過去企業也許一天只新增幾千筆交易資料,但現在透過網站點擊紀錄、行動裝置使用行為、產線機台感測器、社群媒體內容以及監控影像,可能是一秒鐘就產生數萬筆事件紀錄。當資料量大到傳統資料庫查詢變慢、儲存成本升高、人工整理完全無法負荷時,企業就必須導入分散式儲存與平行運算架構來應對。
2. 速度 (Velocity)
Velocity 指的是資料產生、傳輸與處理的速度。現在許多資料不是每月結算,而是必須即時發生、即時更新並即時回應。常見的情境包括金融交易的異常詐欺偵測、電商平台的即時推薦引擎、廣告競價系統,或是物流配送的即時追蹤。速度的重要性在於,如果資料分析結果太慢出來,即使數據再準確,也可能錯過最佳決策時機。
3. 種類 (Variety)
Variety 指的是資料型態多樣。傳統資料多半是結構化表格,鍵如客戶編號、訂單金額或交易日期;但大數據面對的資料,往往還包含電子郵件、客服對話紀錄、PDF 文件、社群貼文、圖片、影片、音訊以及機器日誌。這種非結構化與半結構化資料的多樣性,讓資料整合難度大幅提高,如果沒有統一的資料模型,很容易在內部形成互相矛盾的資訊。
4. 真實性 (Veracity)
Veracity 指的是資料的真實性與可信度。資料越多,不代表結果越準,若原始資料存在缺漏值、重複資料、異常值、標準不一致或來源不明等問題,分析結論就可能失真。因此,大數據的重點不只是收集很多資料,而是建立可信的資料基礎。企業若沒有良好的資料清洗與治理機制,再強的演算法也可能只是放大錯誤。
5. 價值 (Value)
Value 是大數據最終的核心,因為資料本身不是目的,能產生商業價值才是重點。真正成熟的大數據應用,會把冰冷的資料轉化為可解釋的洞察、可追蹤的指標與可執行的決策。無論是預測哪些客戶可能流失、找出哪些產品需要立即補貨,還是預判產線設備可能故障,企業能否把資料變成實際的營運競爭力,才是大數據的真諦。
三、大數據的核心技術與生態系
1. Hadoop 分散式架構原理
Hadoop 是早期大數據生態系的重要基礎架構,主要解決兩件事:大量資料儲存與分散式運算。它的核心概念是「化整為零」,不要把所有資料塞進單一高規格伺服器,而是把資料切分後,分散儲存在多台機器組成的叢集上,再透過分散式架構一起處理。
在架構組成上,Hadoop 主要由負責儲存大量資料的分散式檔案系統(HDFS)、將運算任務拆解成多個節點平行處理的運算框架(MapReduce),以及負責資源調度與叢集管理的 YARN 所組成。它的優勢在於具備極佳的水平擴充能力與容錯表現,非常適合處理超大規模的批次任務。不過,由於其運算過程需要頻繁寫入磁碟,因此延遲相對較高,不一定適合需要即時回應的分析場景。
2. Spark 記憶體內運算技術
為了補足 Hadoop 在即時運算上的弱點,Spark 成為了目前非常關鍵的大數據運算引擎,其核心特色為記憶體內運算(In-Memory Computing)。相較於 Hadoop MapReduce 需要頻繁把中間運算結果寫入磁碟,Spark 直接在記憶體中完成大量計算,因此處理速度快了十倍甚至百倍。
這項技術讓 Spark 非常適合應用在即時資料處理、機器學習模型訓練、互動式分析以及串流分析等情境。很多人常拿兩者進行比較,但更精確地說,它們不是完全取代的關係。在企業實務中,常見的黃金組合是由 Hadoop 負責底層的分散式儲存,而由 Spark 擔任高效率的運算與分析引擎,兩者相輔相成。
3. 資料倉儲與資料湖泊的差異
在大數據架構中,資料倉儲(Data Warehouse)與資料湖泊(Data Lake)是兩個最常被提及的儲存概念,兩者在資料成熟度與彈性上有著根本的落差:
| 比較維度 | 資料倉儲(Data Warehouse) | 資料湖泊(Data Lake) |
|---|---|---|
| 資料型態 | 以高度結構化的資料為主 | 支援結構化、半結構化與非結構化原始資料 |
| 進入門檻 | 資料進入前必須先經過清洗、整理與建置模型 | 採取先儲存再處理(Schema-on-Read)的彈性機制 |
| 主要用途 | 適合固定報表、KPI 分析與商業智慧(BI)應用 | 適合探索式分析、資料科學實驗與 AI 模型訓練 |
| 治理難度 | 結構分明,治理與權限控管較完整 | 彈性極高,若缺乏治理容易退化為「資料沼澤」 |
簡單理解,資料倉儲就像是一間分類清晰、整齊劃一的圖書館;而資料湖泊則像是一個先把各種物資集中存放的大型現代化倉庫。實務上,企業常依需求建立分層架構,讓原始資料先進湖,再將高價值的可用資料整理進倉,兼顧探索彈性與營運治理。
四、大數據的運作生命週期
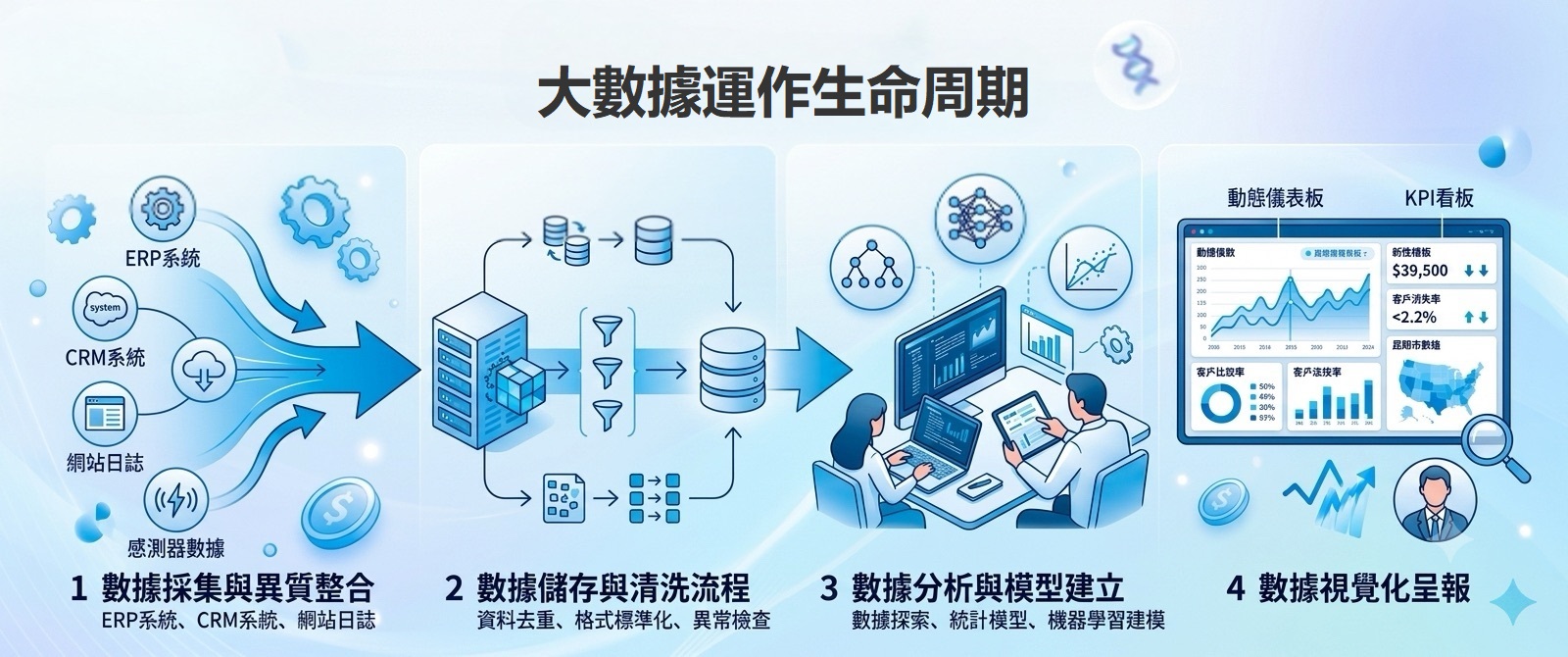
1. 數據採集與異質整合
大數據的第一步不是分析,而是蒐集與整合。企業的營運資料往往分散在 ERP、CRM、POS、製造執行系統(MES)、財務系統、Excel 表格、網站與 App 行為資料等異質來源中。
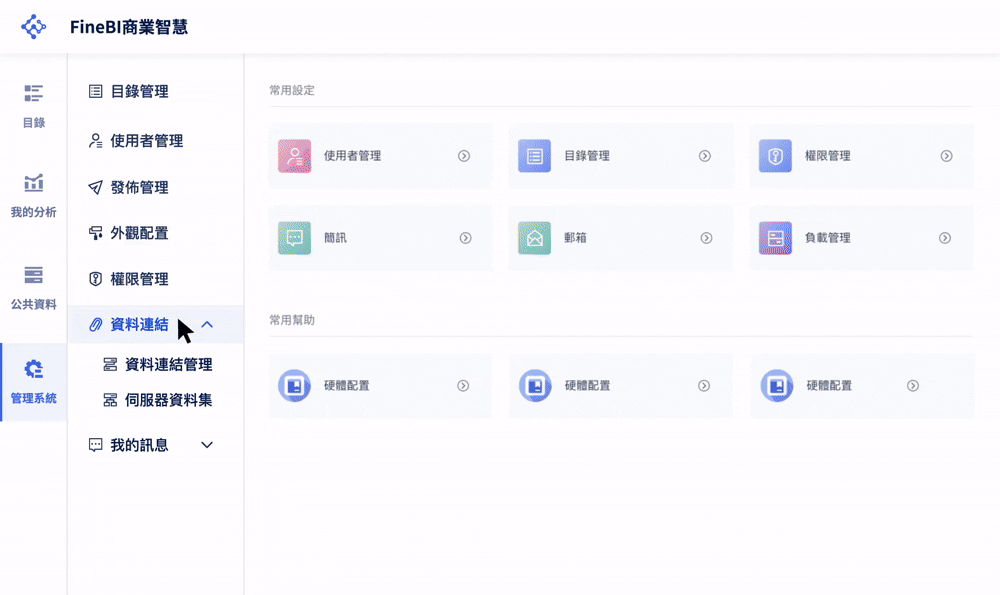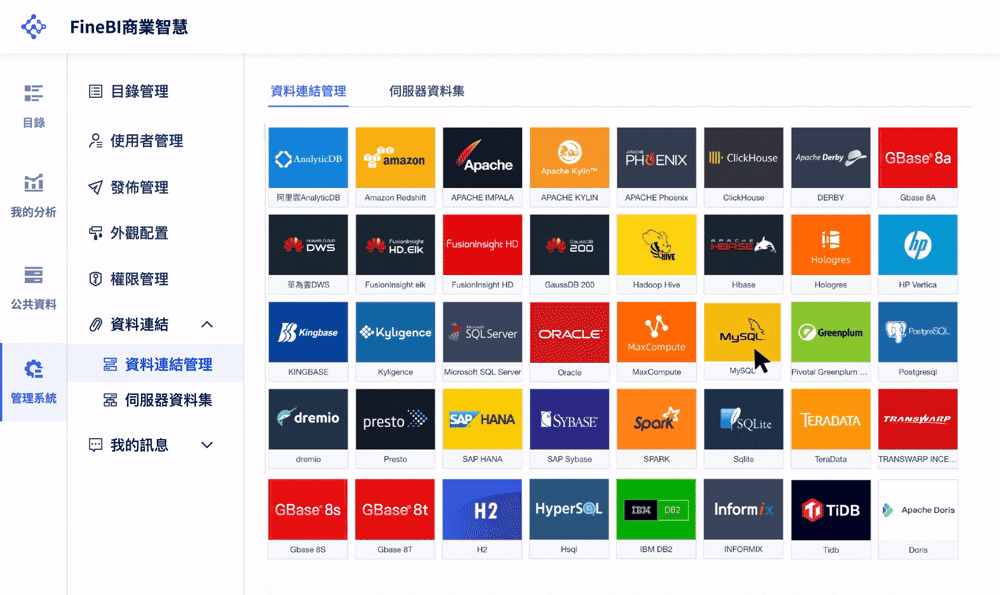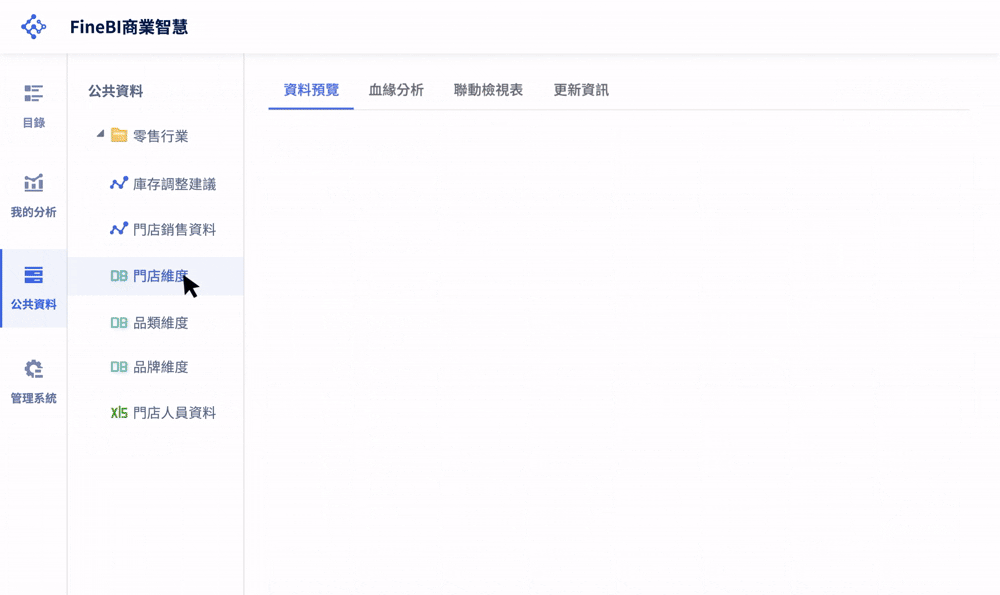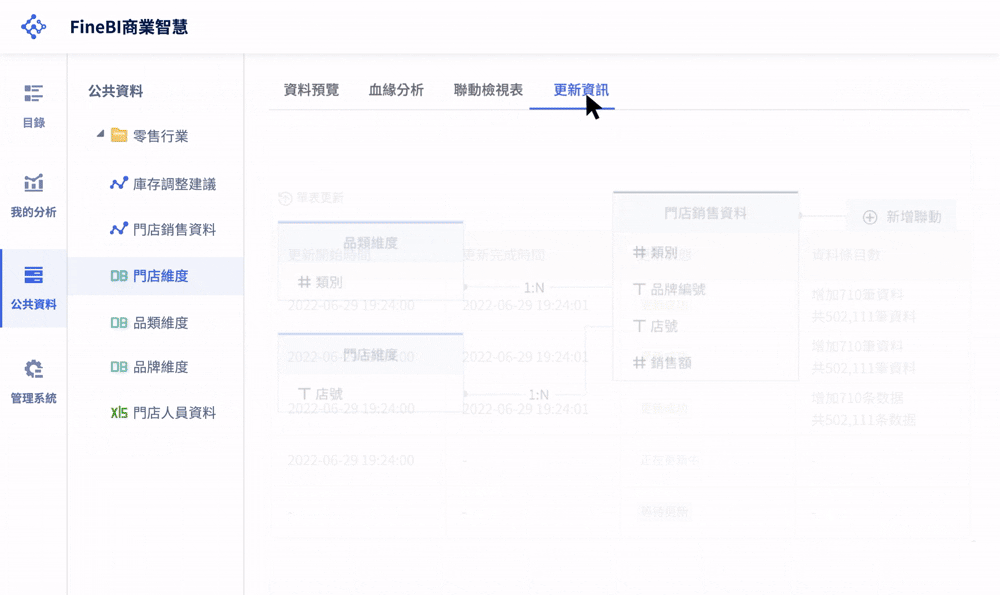
在過去,這些來源通常格式不同、命名規則各異且更新頻率不一,這就是所謂的「資料孤島」場景。當部門之間各持己見,同一個業績指標在財務部與業務部看到不同數字時,決策就會陷入癱瘓。因此,這個階段必須透過 ETL(編號步驟 2 有詳細說明)或 API 串接,建立統一的數據底座。
2. 數據儲存與清洗
資料採集進來之後,絕對不能直接拿來分析,因為原始資料通常充滿雜訊。為了確保資料可以被信任,企業必須建立標準的資料清洗流程,通常包含以下四個關鍵步驟:
- 資料去重與補值:剔除重複上傳的交易紀錄,並針對漏填的關鍵欄位進行合理的統計補值。
- 格式標準化:將來自不同系統的日期格式(如 YYYY/MM/DD 與 DD-MM-YYYY)和字串進行統一映射。
- 異常值檢查:透過演算法設定合理區間,自動偵測並標記超出常理的極端數字或人工輸入錯誤。
- 建立資料血緣:追蹤資料從源頭到最終報表的流轉路徑,確保欄位變更時具備版本管理機制。
3. 數據分析與模型建立
完成清洗與整合後,資料轉化為可信任的資產,這才進入真正的分析與建模階段。企業可以根據不同的商務目標,選擇導入不同的演算法。例如,透過交叉分析找出核心客戶群的特徵,利用統計關聯分析發現商品之間的搭配銷售機會,或是進一步結合機器學習演算法,建立自動化的流失預測模型。這個階段的目標,是從歷史資料的規律中摸索出未來的營運密碼。
4. 數據視覺化呈報
數據若只停留在複雜的資料表與程式碼,其價值就無法真正落地。大數據生命週期的最後一哩路,是把複雜的分析結果轉化為決策者一秒就能看懂的視覺化介面。無論是經營戰情室的動態儀表板、全公司統一的 KPI 看板,還是具備自動化告警通知的異常回報系統,好的視覺化能讓管理層、業務單位與 IT 單位用相同的數據語言溝通,真正驅動企業採取一致的行動。
五、大數據的四種分析方法
大數據分析依據深度與目標的不同,主要分為四個遞進的層次。企業通常會從最基礎的描述性分析開始,逐步邁向最高階的智慧化規範性分析。
- 描述性分析 (Descriptive) —「發生了什麼?」:主要用於整理歷史資料,找出現況與趨勢。例如本月營收總額、哪些商品賣最好、哪個地區的流量最高。這是報表與商業智慧(BI)最常見的基礎應用。
- 診斷性分析 (Diagnostic) —「為什麼會發生?」:進一步追查背後原因。例如營收下滑究竟是因為廣告流量減少,還是購物車轉換率下降?透過維度拆解與下鑽分析,幫助企業定位問題的核心。
- 預測性分析 (Predictive) —「未來可能會發生什麼?」:結合統計模型或機器學習,根據歷史規律預測未來結果。例如預估未來一週的物料需求量、客戶的流失風險,或是機台設備的故障機率,讓企業提前佈局。
- 規範性分析 (Prescriptive) —「接下來應該怎麼做?」:不只預測結果,還直接提出最佳行動建議。例如系統自動指出哪些高風險流失客戶應優先發放優惠券、哪條產線應立即安排停機維修,直接將數據轉化為營運策略。
六、企業引進大數據的優勢
1. 數據驅動決策的商業價值
企業導入大數據最大的好處,是讓決策從傳統的「憑經驗、拍腦袋」轉向「有依據、看數據」。當管理層能即時看到一致且可信的數據,就能更精準地判斷哪些產品值得加大投入、哪些市場正在成長,以及哪些流程出現瓶頸。根據市場研究,成功轉型為數據驅動的企業,其決策效率與市場反應速度平均能提升 30% 以上。
2. 提升客戶體驗與精準行銷
透過大數據,企業得以 360 度全方位理解客戶的輪廓與偏好。藉由追蹤用戶在網站上的瀏覽軌跡、在哪個流程離開購物車,以及對哪些促銷內容互動率最高,行銷團隊可以實施高度個人化的推薦與分眾行銷。當企業能在對的時間、透過對的管道、提供對的產品給對的人,客戶的體驗與最終轉換率通常都會得到顯著的提升。
3. 提高營運效率與降低成本
大數據不只能幫助企業賺更多,也能幫助企業花更少。透過精準的需求預測,零售業能大幅降低庫存堆積成本;製造業則能透過生產監控減少無預警停機的損失。更重要的是,導入現代化的商業智慧(BI)平台後,過往需要花費數天人工整理 Excel 報表的時間可以縮短至秒級,讓業務部門能夠自主進行分析,大幅減輕 IT 部門的製表壓力。
4. 改善風險管理與即時預警
在金融、物流與資安等高度重視安全性的場景中,大數據更能發揮即時預警的價值。透過設定自動化監控規則,系統能即時偵測異常的刷卡交易、發現供應鏈延誤的早期跡象,或是監控社群網路上客服負評的異常飆升。資料越即時、分析越自動化,企業就越能從過往的「被動事後反應」,轉向「主動事前防範」。
七、企業導入大數據的常見挑戰與資安風險
1. 數據隱私與資安合規 (GDPR)
大數據應用越廣泛,隱私與合規的風險就隨之攀升。尤其當企業處理的是個人識別資料(PII)、交易紀錄或定位資料時,必須嚴格遵守如歐盟 GDPR 或台灣個資法等法規。企業在建置大數據平台時,必須確保資料取得合法授權、具備完善的去識別化與去敏感機制,並落實嚴格的權限控管與存取紀錄審計,以免創造價值的同時,卻面臨高昂的法律罰鍰。
2. 數據治理與品質維護
許多企業在推動大數據時,最大的痛點不是「沒有資料」,而是「資料不能用」。常見的亂象包含各部門對同一個指標的定義不一致、系統主資料混亂、歷史報表版本過多,以及缺乏明確的權責歸屬。因此,大數據要成功,不能只靠工程師搭建平台,更必須在組織內部建立健全的數據治理制度,落實指標口徑統一與品質監督機制。
3. 舊系統整合與人才短缺
企業現場常見的另一個硬傷,是歷史遺留系統(Legacy System)過多且架構封閉。許多高價值資料長期封鎖在老舊的 ERP、缺乏 API 的封閉平台,甚至是各部門自行建立的 Excel 檔案中。要把這些分散的資料整合進現代化大數據架構,往往需要耗費極大的協調成本。此外,大數據同時跨越了資料工程、資料治理、商業智慧與機器學習等多個專業領域,人才供不應求,這也促使許多企業開始尋求更直觀、低程式碼的工具來降低導入難度。
八、大數據與 AI 人工智慧的共生關係
1. 大數據是生成式 AI 的數據訓練基礎
AI 技術雖然強大,但前提是有足夠、可信且高質量的資料作為燃料。不論是傳統的機器學習、深度學習,還是當前主流的生成式 AI(Generative AI),本質上都需要龐大的大數據來訓練與優化模型。正如「垃圾進,垃圾出(Garbage In, Garbage Out)」的黃金定律,沒有高規格的大數據與穩定的資料治理,AI 的輸出結果就容易出現偏誤或失真。意指生成式 AI 若要落地在企業內部的知識問答或營運分析,更需要緊密結合企業自有的結構化與非結構化數據。
2. AI 驅動數據自動化處理
反過來說,AI 技術也正在全面顛覆傳統大數據的處理與分析方式。在過去,資料清洗、標註與分類需要耗費大量人工與時間,而現在透過 AI模型,系統已經能夠自動完成非結構化文件的分類、文字摘要、影像辨識以及異常值偵測。更具革命性的是,AI 讓「自然語言查詢數據(Text-to-SQL)」成為現實,企業用戶未來只需要輸入中文,系統就能自動生成對應的分析圖表,兩者相輔相成,共同推動組織從資料管理邁向智慧決策。
九、真實大數據應用案例
1. 零售業真實案例:解決資料孤島與優化庫存
台灣某家連鎖零售業者,過往最頭痛的問題就是資料分散在 POS、ERP、會員系統與電商平台中。由於各系統彼此不通,導致門市與電商庫存無法同步、會員標籤支離破碎,補貨決策往往只能仰賴店長過去的個人經驗。
為了解決這個痛點,該企業導入了大數據架構,將分散的交易、會員與商品庫存資料進行集中整合,建立主題式分析模型。透過對各區域銷售趨勢與商品週轉率的深入分析,系統成功優化了補貨邏輯與安全庫存設定。導入後,該企業的熱銷商品缺貨率大幅下降了 15%,而整體滯銷庫存也減少了近兩成,真正實現了數據驅動營運。
2. 製造業真實案例:設備預測性維護
在現代化高精密製造業場景中,機台的非預期停機往往會帶來難以估計的產能損失。過去,某半導體封測廠主要採用「定期保養」或「壞了再修」的模式,前者容易造成過度維護浪費成本,後者則容易因突然斷線而導致整批產品報廢。
該廠隨後引進大數據與物聯網(IoT)技術,在核心設備上部署感測器,24小時不間斷地採集溫度、振動、壓力和轉速等即時數據。透過將這些串流資料與歷史故障日誌進行比對建模,系統得以在設備真正發生損壞前的數天發出預警通知。這項轉型不僅讓無預警停機時間縮短了 40%,也讓維修主管能更從容地調配派工節奏。
3. 金融業真實案例:即時欺詐檢測
金融業的風險控管是一場與時間賽跑的戰爭。傳統風控多採用靜態規則審查,然而在詐欺手法日新月異的今天,靜態規則容易產生漏洞,甚至因誤判率過高而嚴重影響用戶的刷卡體驗。
某家商業銀行建置了即時大數據風控引擎,當卡友進行刷卡消費時,系統會在毫秒之內同時運算該筆交易的金額、裝置資訊、地理位置、交易頻率,並與用戶過去的歷史行為模式進行高維度交叉比對。如果發現該筆交易在短時間內出現跨國登入或異常裝置切換,系統會即時凍結該筆高風險交易並觸發二次簡訊驗證,在不干擾正常用戶體驗的前提下,大幅降低了金融詐欺的衍生損失。
十、結語:打破數據孤島,從低程式碼 BI 跨出第一步
1. 業務與管理階層的數據痛點
在實務商業場景中,多數企業高層面臨的真實痛點,往往不是手頭上的資料不夠多,而是資料過於凌亂。資料散落在各個封閉系統無法整合、管理階層看得到的報表大量依賴人工使用 Excel 重複剪貼、跨部門開會時指標定義各自表述,導致 IT 部門每天疲於奔命應付各單位的拉表需求,卻無法提供具備洞察力的分析。
當企業還在用零散、傳統的工具去處理系統級的資訊問題時,數據就很難真正轉化為決策基礎。一場成功的數據轉型,通常必須遵循明確的推進路徑:第一步必須先打通底層異質資料以打破孤島,第二步建立全公司統一的指標體系,第三步將分析能力下放給第一線業務單位,最終才能建立起數據驅動的即時預警與決策機制。
2. FineBI 解決方案:免寫程式的自助式 [BI]
如果你正在規劃帶領組織從雜亂的大數據邁向實際的商業決策,FineBI 這類低程式碼的自助式 BI 工具,會是企業跨出數位轉型最理想的起點。它能直接串接 ERP、CRM、資料倉儲與 Excel 等異質來源,在前端提供直觀的拖拉式操作介面,讓完全沒有程式背景的業務、財務或營運人員,也能在符合企業安全治理的框架下,自主完成多維度下鑽分析並建立動態經營戰情室。
大數據的真正價值從不在於技術名詞多麼酷炫,而在於能否為企業創造可延續的競爭力。從自助式 BI 跨出第一步,打破孤島、激活暗數據,你的企業才能真正把資料變成資產,把分析變成行動,全面開啟數據驅動決策的新局。
FAQs
大數據的 5V 指的是資料量(Volume)、速度(Velocity)、多樣性(Variety)、真實性(Veracity)與價值(Value)。它用來說明大數據不只是資料很多,而是同時具備處理難度與商業應用價值。
傳統資料庫通常處理結構化、規模較小且更新頻率較低的資料。大數據則常來自多個來源,包含非結構化資料,且更強調即時處理與分散式運算能力。
企業通常應先盤點資料來源、釐清指標定義,並解決資料孤島問題。若沒有先做好整合與治理,後續分析結果容易不一致,也難以真正支援決策。
兩者沒有絕對誰比較好,而是取決於需求。Hadoop較適合大規模批次處理與分散式儲存,Spark則更適合需要高速運算、即時分析與機器學習的場景。
常見挑戰包括資料品質不穩、系統來源分散、權限與治理不足,以及隱私與合規風險。若缺少清洗、標準化與權責機制,資料越多反而越難產生可信洞察。







免費資源下載