从入门到进阶实时架构,数据仓库的那些事,不知道的快来看看
每个人对于数仓的理解,都源自于大数据,而大数据又源自于那个神奇的故事:从前有一家超市,它有一个怪现象,尿布和啤酒赫然摆在一起出售。外行人不明所以,但内行人却看到了尿布和啤酒的销量双双增加。
为什么呢?正是因为大数据发挥了它最原始的作用:组合分析。
妇女们经常会嘱咐她们的丈夫下班以后要为孩子买尿布,而丈夫在买完尿布之后又要顺手买回自己爱喝的啤酒,因此啤酒和尿布在一起购买的机会还是很多的。这就是大数据最初的魔力。
数据仓库已经是一个非常成熟稳定的模型了:
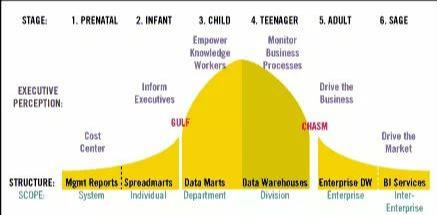
这个模型有六个阶段:孕育期、婴儿期、儿童期、少年期、成人期、长者期。
孕育期:打印基本的报表,交给各个部门的员工来手工填写;
婴儿期:用Excel完成基本的数据组织与统计;
儿童期:能够部署独立的应用程序,来满足单个部门的需求;
少年期:形成了基本的数仓概念,并引入了数据的定义、规则、维度标准化等概念;
成人期:搭建企业级数据仓库,并通过整合的数据来支持一些关键业务的驱动;
长者期:BI的概念形成,数仓建设非常规范。
(此处已添加小程序,请到今日头条客户端查看)
当然,由于中国过早的进入了互联网和移动互联网时代,并没有经历过软件时代的相关历程,因此数仓的概念从一开始就与大数据紧紧的绑定在了一起,成为了每个互联网公司的标配部门。
如果你是一名数据开发的同学,出去面试,基本都会被问到一个问题:“如果是你来负责数据仓库建设,你会考虑如何来建设好数据仓库?”这个问题通常是考察候选人的架构设计水平的,看你对于业务有多深入的了解。
大部分人的回答都是偏技术层面的,通常会说出一个比较完整的数据分层模型,但仅仅分层清晰就足够了吗?不一定。
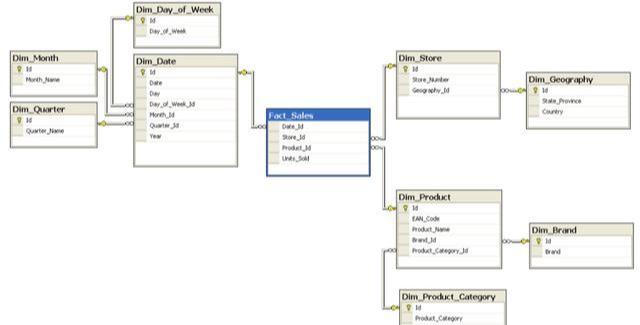
我们先看一下通常的数据仓库分层模型:
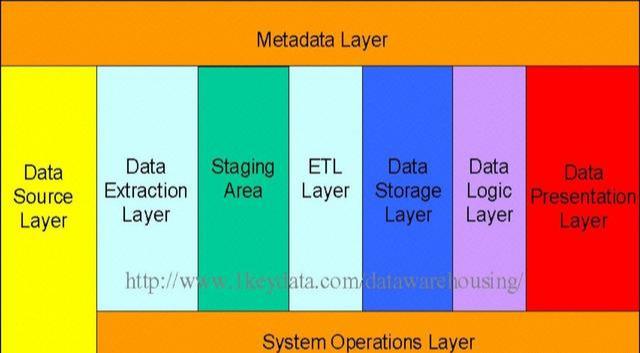
数据逻辑通常按照下图进行分层:
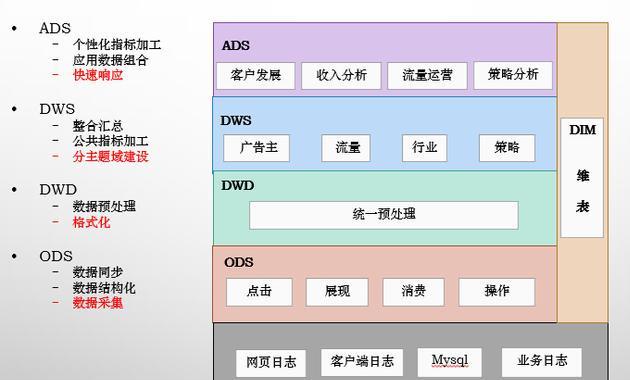
到这里为止,如何建设好一个数据仓库的概念,就基本解释清楚了,这也是一名从业3年的数据人应该有的基本能力。但是,这也仅仅是技术层面的总结,解决了工程上的“能不能实现”,但“能不能有用”,就是另外一个话题了。
数据仓库是不是有用,要看它能做什么。通常而言,数据仓库要解决业务的问题,为业务的发展提供决策依据和运营参考,换句话说,数据仓库要与业务有强绑定的关系。
如果一个数据仓库只能把数据接入进来,做好分层,但不知道给谁用,那么这个数据仓库通常就是没有价值的,在你做部门汇报的时候,会被大佬疯狂diss。那么业务会怎么用数据?通常而言,还是从数仓的概念出发,我们给出三个很具体的用途:
第一个用途是集成:对于互联网公司来说,数据通常十分的零散,例如数据库日志在运维手里、广告数据在广告团队那里、业务数据在后端那里,产品同学在全局角度上设计了一些好的产品或者功能,需要综合各方面的情况,来看这个产品或者功能是否有用,那么数据仓库就是他们唯一的选择。
从技术层面说,决策支持需求通常是全局的、关联的,必须将数据整合到一个地方才能方便统计分析和挖掘。从数据处理层面说,不同的数据格式不一样,有的是关系型的数据表,有的是本结构化的日志,有的数据还以多媒体的形式存在,也需要将数据转化成相对统一的格式。
在集成的层面上,我们就需要强调不同开源框架的作用与相互配合了。自底向上,与OSI类似,通用框架下的大数据体系有七层:数据源、数据收集层、数据存储层、资源管理与服务协调层、计算引擎层、数据分析层及数据可视化层。
第二个用途是面向主题:我们把四面八方的数据都拿到了,那怎样组织这些数据呢?换句话说,产品丢了一个又一个的需求过来,我们通过怎样的方式,能够尽快消灭掉这些需求嗯?通常而言,这里就要引入两个很重要的概念:建模、域。
在数据仓库领域,经常会听到两个名字,Bill Inmon与Ralph Kimball。Inmon最早提出数据仓库的概念,在构建数据仓库过程中,主张自顶向下的设计,先设计好数仓的整体架构,然后进行局部设计,而Kimball正好相反,主张自底向上设计,先根据各个业务主题进行设计,然后通过维度模型将数据仓库整合起来。
下图为Inmon构建过程示例:
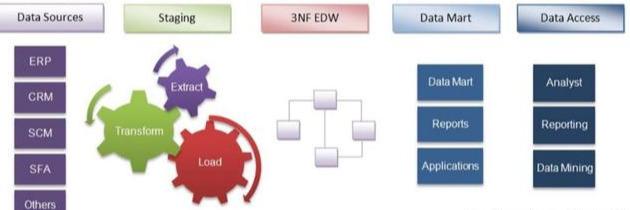
下图为Kimball维度建模示例:
域的概念,简单来说就是主题,是业务方向的统称。为什么要按主题来组织?因为数据仓库是分析型的数据集合,我们分析的出发点通常是业务实体,分析的目的就是要了解业务实体的各种行为状态、了解每个业务的效果。
通过将相对固定的业务领域,按照一定的抽象规则进行归纳,便可以形成相对独立的信息模型。
通常而言,我们会在公共层,也就是DWS层进行数据域的划分,在某些已成熟单一主体业务按照这样来做比较好,比如像金融,安全等领域,通过对主体业务内的数据进行抽象分类,进行精细化的管理。
但是,当业务领域过多时,会将数据管理复杂化,在当前业务快速响应的时代,基于业务+数据域的划分或许是更好的一种管理方式,它没有对原有的业务重新归纳,基于非直接业务数据也从横向整体通盘进行考虑。如下图所说:

第三个用途是反应历史变化:可能很多业务场景并不涉及到历史变化,但一旦涉及到了,就绝不是一件简单的事情,尤其是在电商领域。可以说,历史变化是一个将纵向比对横向的过程,只有对比历史才能发掘目前数据的价值。
所以,数据仓库有一个很重要的使命,就是保存历史数据的状态,免得产品同学挖出了一个坑后,你无从下手排查……
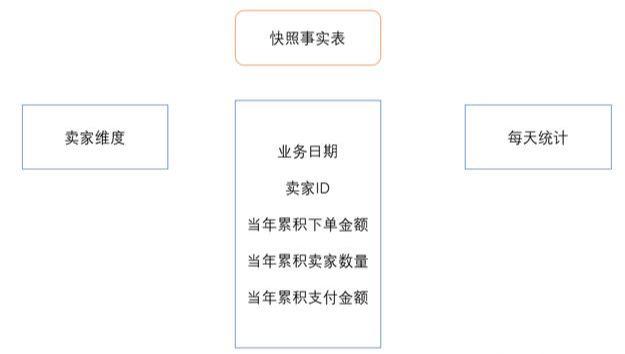
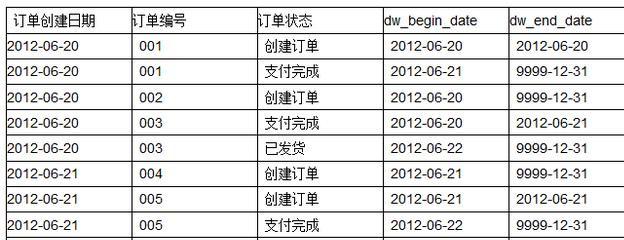
但是,历史数据的保存是有成本的,如果不加区分全量保存,会对存储系统产生非常大的压力,很快Hadoop集群就是各种90%、各种疯狂报警了。那么我们如何组织和整理历史变化数据呢?通常而言,这里就是拉链表、快照事实表等概念了。
下图是快照事实表的说明:

下图是拉链表的说明:
即便我们进阶了很多,既有技术支撑,也有方法论铺垫之后,还是会面对一个现实的问题:工作内容没有价值。大家其实能说出很多很多的原因,比如下面这些:
1.工作职责划分不明确,把数据分析当作报表开发,怎么体现价值?
2.需求一个接一个做不完,产品不把分析当合作伙伴,就是工具!
3.分析师没有主动权,只能被动接需求,需求是谁提的,谁的成果和价值才高!
对于不同的角色,能做的事情是很不同的:
1.对于一名执行者,小兵,没什么可说的,老老实实把自己的专业度提升到自己的巅峰,你的专业度才是你的立身之本,这都没有,那你有什么用?老大争取来了项目,你能完成吗?
2.对于一名团队的骨干,要学会去帮助老大发掘有价值的项目和好的切入点,去推动,去协调。你具备的不只是专业技能,更多的是一名职业人的职业性。
3.对于团队的老大,要学会共赢,一定要能够把大老板的路子打通,有一个至多个业务方的盟友。互联网很多Leader都是从技术转过来的,这时候要学会转变思维,不要总感觉自己是一名顶尖的工程师。
在整个实时数仓的建设中,业界已经有了常用的方案选型。整体架构设计通过分层设计为OLAP查询分担压力,让出计算空间,复杂的计算统一在实时计算层处理掉,避免给OLAP查询带来过大的压力。
汇总计算交给OLAP数据库进行。因此,在整个架构中实时计算一般是Spark+Flink配合,消息队列Kafka一家独大,在整个大数据领域消息队列的应用中仍然处于垄断地位,Hbase、Redis和MySQL都在特定场景下有一席之地。
目前还没有一个OLAP系统能够满足各种场景的查询需求。其本质原因是,没有一个系统能同时在数据量、性能、和灵活性三个方面做到完美,每个系统在设计时都需要在这三者间做出取舍。
从长远看,Spark和Flink更有可能成为下一代的Hadoop,值得投入大量时间学习。




 立即沟通
立即沟通