数据湖与湖仓一体是如何演变而来的?详谈大数据存储架构的变迁!
在大数据存储架构的发展历程中,可以划分为三个显著的演进阶段。首先,随着Hadoop和Hive等初期项目的出现,数据仓库(Data Warehouse)的概念得以确立;随着数据仓库的不断演化,同时有了云与对象存储的诞生;大数据与 AI 的时代到来之后,数据湖(Data Lake)这个概念就被凸显了出来。
近几年,出现了一个新的存储概念,或者是说到了一个新的阶段,叫做湖仓一体(Lakehouse)。传统数仓大家都比较了解,今天这篇文章,我们会着重看一下后面这两个阶段,也就是数据湖和湖仓一体。
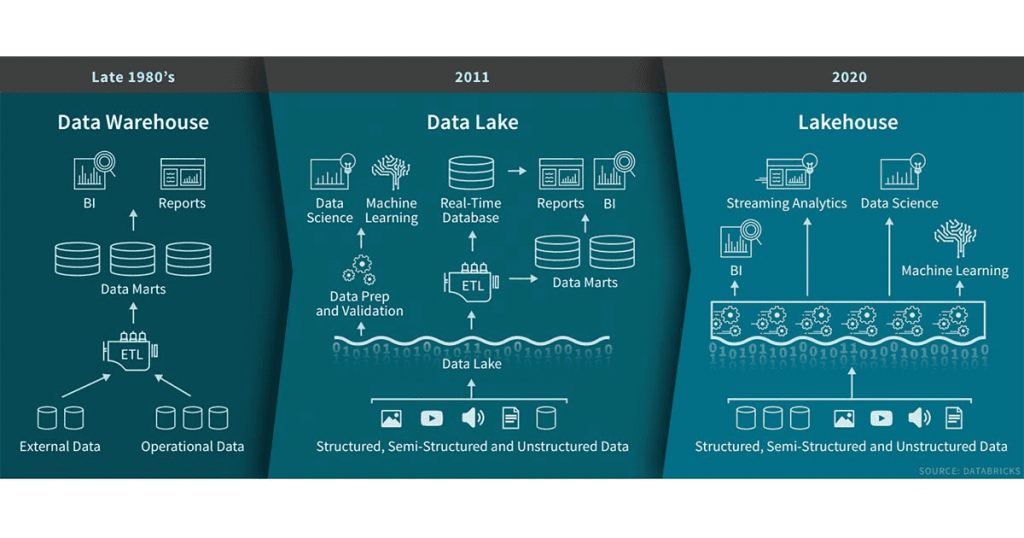
一、为什么要有「数据湖」?
数据湖的出现主要是为了解决数据烟囱(Data Silos)的问题。数据烟囱的形成主要源于不同的业务或团队由于历史原因导致数据隔离,无法进行有效连接。随着企业内部业务的增加,数据格式日益多样化,除了传统的结构化数据,还涉及大量的半结构化和非结构化数据。这些数据也需要被纳入企业的数据管理和运维体系中。传统的数据仓库架构难以满足这种多样化的数据存储需求。
其次,分散的数据管理也是数据烟囱问题的一个关联因素。由于数据分布在不同的位置,数据管理和权限控制变得分散,对于不同业务和团队进行管理需要大量的工作量。
再者,存储与计算的耦合(存算耦合)是另一个问题。这主要与传统的Hadoop架构,如HDFS和YARN,的设计理念有关。然而,对于基于公有云的现代大数据架构来说,这种存算耦合的设计显得缺乏弹性,无论是在运维弹性还是成本控制方面。
最后,随着人工智能(AI)行业的迅速发展,特别是在机器学习和深度学习领域,数据湖需要为基于这些技术的业务提供更好的支持。除了数据存储外,还需要与深度学习框架进行对接,提供如POSIX等更适合算法工程师的接口,而不仅仅是传统的SQL或其他方式。
二、什么是「数据湖」?
这里引用维基百科上的一句简介:
A data lake is a system or repository of data stored in its natural/raw format, usually objectblobs or files.
翻译一下:
数据湖是一个存储系统或数据仓库,其中的数据以其自然的或原始的格式存储,通常以对象、块或文件的形式存在。
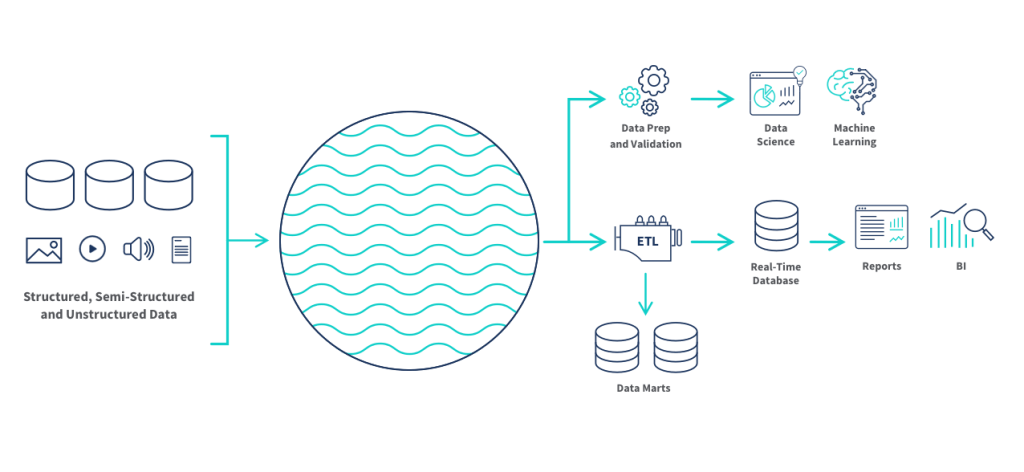
数据湖与传统数据仓库最大的区别在于数据存储的方式。数据湖更倾向于将数据以其原始格式存储,而不进行预处理或转换。要构建一个有效的数据湖,关键在于选择一种既经济实惠又能支持海量数据的底层存储解决方案。目前,云上的对象存储技术似乎是一个理想的选择,它不仅成本低廉和可靠,还能够处理大规模的数据存储需求。然而,对象存储也并非完美无缺,接下来将对其进行详细比较和分析。
简洁地说,数据湖的核心理念是「 Everything in one place」,即所有数据都首先存储在数据湖中。无论是进行数据仓库构建还是进行后续的ETL处理,都可以在后续阶段进行。这里的“后置ETL”指的是ETL过程仍然存在,但它被转变为一个后续处理步骤。由于采用了对象存储和存算分离的架构,数据湖的整体设计也更符合云原生的理念。
三、为什么要有「湖仓一体」?
在数据湖架构中,尽管数据仓库仍然存在,但由于其在数据处理流程中的后置位置,可能导致数据处理的滞后。特别是对于如 Hive 这类传统组件,要实现近实时或基于 Hive 的增量数据更新相对复杂,尤其是在缩短分区(partition)时间窗口的情况下。
此外,尽管数据湖已经存在,但与机器学习和深度学习的集成仍然面临挑战。在湖仓一体的阶段,需要解决如何更好地支持深度学习等先进技术的问题。
数据重复拷贝和重复ETL也是一个关键问题。由于ETL和数据仓库都被放置在数据处理流程的后端,可能导致数据从数据湖同步或复制到数据仓库,进而产生数据的重复拷贝或重复ETL,这可能会造成数据质量问题和不必要的资源浪费。
最后,基于对象存储这样的存储解决方案,需要提供更多的高级特性支持,例如ACID事务、多版本数据索引和零拷贝克隆等。这些特性对于确保数据一致性、提高数据查询效率和减少数据存储成本都是非常重要的。
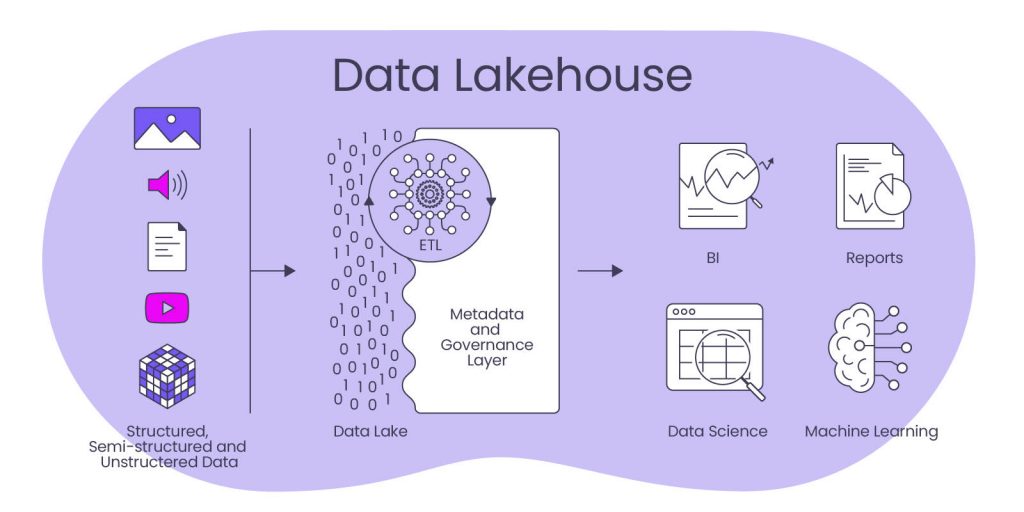
四、什么是「湖仓一体」?
湖仓一体的设计理念包括几个关键因素。首先,它需要采用一个统一开放的底层文件格式,例如Parquet、ORC等,这些都是业界广泛认可的高效存储格式。这种统一的文件格式有助于确保数据的高效存储和查询。
其次,湖仓一体还需要一个开放的存储层,这包括如Delta Lake、Iceberg、Hudi等开源组件。这些组件提供了额外的数据管理功能,如事务支持、版本控制等,使数据湖更加健壮和可靠。
第三,湖仓一体需要与多种计算引擎进行集成。无论是Spark、Presto还是其他商业计算引擎,都应该能够无缝地与湖仓一体的存储层结合,为用户提供多样化的计算和查询选项。
最后,湖仓一体还需要与深度学习框架进行紧密集成。以Uber开源的Petastorm项目为例,Petastorm为TensorFlow、PyTorch等深度学习框架提供了Parquet格式的读写支持。这种集成能力使得深度学习任务可以直接从数据湖中读取数据,极大地提高了数据处理的效率和灵活性。
总体而言,湖仓一体的目标是构建一个集统一文件格式、开放存储层、多样化计算引擎和深度学习框架于一体的,用于数据处理和分析的大数据平台,以满足现代大数据应用的多样化需求。
五、结语
在大数据领域的持续发展中,数据存储和处理架构也经历了从数据仓库到数据湖,再到湖仓一体的演进。湖仓一体旨在通过统一的开放文件格式、灵活的存储层、多样的计算引擎集成以及与深度学习框架的紧密结合,构建一个更加高效、灵活和功能丰富的数据处理和分析平台。对于上层的数据应用与分析工具FineBI而言,湖仓一体架构提供了一个更加完善和集成的数据管理解决方案,使FineBI能够更加高效地连接、查询和分析数据,为企业用户提供更加强大和灵活的数据分析能力。
湖仓一体的出现不仅弥补了数据湖架构中的不足,还为企业提供了一个更加完整和集成的数据管理解决方案。未来,随着大数据和机器学习技术的进一步发展,湖仓一体架构有望成为企业数据管理的主流模式,同时为FineBI这样的数据应用与分析工具提供了更广阔的应用场景和发展空间,为企业在数据驱动决策和创新应用方面提供强大的支持。






 立即沟通
立即沟通

