采访了10家名企的20位ETL工程师,总结了这些数据架构的思考
三年前写过一篇ETL的文章,最近又被小伙伴问到了,这期间我也进行过调研,10多个名企,阿里腾讯和传统企业的都有,总计20多位工程师,因此今天来重新说一下,他们远不是sql男孩。
虽然已经过去两三年了,ETL 领域的一些组件也都有了一些更新,但是整体来看设计的理念变化不是特别大(比如实时处理以前流行的是Spark Streaming,现在流行 Flink,而对于组件,本文也不会讲解它的一些使用教程。本文更多地是分享做ETL和数据流的思考。)
1.先聊一下什么是 ETL。聊一下大致的概念和一般意义上的理解。
2.聊一聊数据流是什么样子。因为 ETL 的工作主要会体现在一条条的数据处理流上,因此这里做一个说明。
3.举个具体的例子来说明。
0x01 什么是 ETL
将数据从OLTP系统中转移到数据仓库中的一系列操作的集合
嗯,怎么理解 ETL 这个东西呢?直接上一个网上搜到的招聘信息看一下:
看上面的要求,有几个点可以关注一下:
数仓的理论
计算引擎:Hadoop、Spark、Hive
数据同步:Flume、Sqoop、Kettle
存储引擎:Mysql、Oracle、Hbase等存储平台
了解ETL之前,这些概念是你必须懂的:
ODS——操作性数据
DW——数据仓库
DM——数据集市
我们大致分析一下这些内容。首先说数仓的理论,这个在前面的博客也都有提到,很重要,从理论上指导了怎么来进行数据处理。存储引擎也就不提了。这两者不太算是 ETL 的范畴。
那就聊一下计算引擎和数据同步的工具。我们可以大致理解 ETL 的主要工作就是利用这些工具来对数据进行处理。下面举几个例子来说明 ETL 的场景:
1.Nginx 的日志可以通过 Flume 抽取到 HDFS 上。
2.Mysql 的数据可以通过 Sqoop 抽取到 Hive 中,同样 Hive 的数据也可以通过 Sqoop 抽取到 Mysql 中。
3.HDFS 上的一些数据不规整,有很多垃圾信息,可以用 Hadoop 或者 Spark 进行处理并重新存入 HDFS 中。
4.Hive 的表也可以通过 Hive 再做一些计算生成新的 Hive 表。
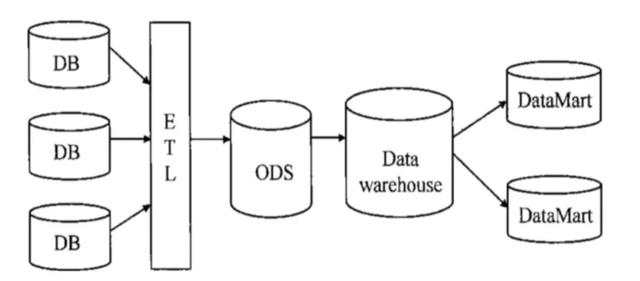
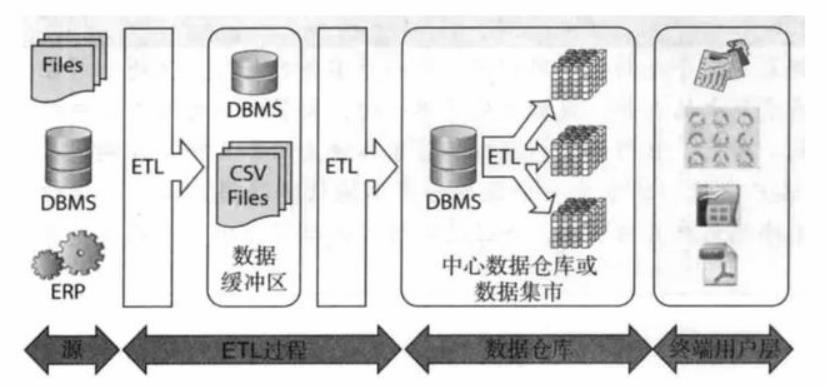
这些都算是 ETL,其中 1 和 2 都比较典型,它们把数据从一个存储引擎转移到另一个存储引擎,在转移的过程中做了一定的转换操作。3 和 4 也同样是 ETL 只是它们更侧重的是数据的加工。
到了这一步,我们不再纠结于具体的 ETL 概念是什么,仅从自己的直观理解上来定义 ETL,不管严谨不严谨,反正这些活 ETL 工程师基本都要干。
ETL 是对数据的加工过程,它包括了数据抽取、数据清洗、数据入库等一系列操作,大部分和数据处理清洗相关的操作都可以算是 ETL。
0x02 数据流长什么样子
举个简单的例子,下面是一个种数据流的设计,蓝色的框框代表的是数据来源,红色的框框主要是数据计算平台,绿色的 HDFS 是我们一种主要的数据存储,Hive、Hbase、ES这些就不再列出来了。
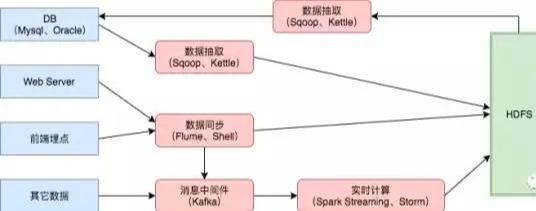
数据流的分类
我们常说的数据流主要分两种:
1.离线数据
2.实时数据
其中离线数据一般都是 T+1 的模式,即每天的凌晨开始处理前一天的数据,有时候可能也是小时级的,技术方案的话可以用 Sqoop、Flume、MR 这些。实时数据一般就是指实时接入的数据,一般是分钟级别以下的数据,常用的技术方案有 Spark Streaming 和 Flink。
现在的大部分数据流的设计都会有离线和实时相结合的方案,即 Lambda 架构,感兴趣的同学可以了解一下。
0x03 举个例子
前段时间和一个哥们再聊数据流的设计,正好这里大概描述一下场景和解决方案。
一、场景
1.数据源主要为 Mysql,希望实时同步 Mysql 数据到大数据集群中(肯定是越快越好)。
2目前每日 20 亿数据,可预见的一段时间后的规模是 100 亿每日以上。
3.能快速地查到最新的数据,这里包含两部分含义:从 Mysql 到大数据集群的速度快、从大数据集群中查询的速度要快。
二、方案选型
遇到这个场景的时候,根据经验我们主要考虑下面两个点:数据抽取引擎和存储引擎。
数据抽取引擎
这里我们主要考虑两种方案:
1.Sqoop 定时抽取 Mysql 数据到 HDFS 中,可以每天全量抽取一份,也可以隔段时间就抽取一份变更的数据。
2.Canal 监听 Mysql 的 binlog 日志,相当于是 Mysql 有一条数据久变动,我们就抽取一条数据过来。
优缺点的对比也很明显:
1.Sqoop 相对比较通用一些,不管是 Mysql 还是 PostgreSql都可以用,而且很成熟。但是实时性较差,每次相当于是启动一个 MR 的任务。
2.Canal 速度很快,但是只能监听 Mysql 的日志。
存储引擎
存储引擎主要考虑 HDFS、Hbase 和 ES。
一般情况下,HDFS 我们尽量都会保存一份。主要纠结的就是 Hbase 和 ES。本来最初是想用 Hbase 来作为实时查询的,但是由于考虑到会有实时检索的需求,就暂定为ES
三、方案设计
最终,我们使用了下面的方案。
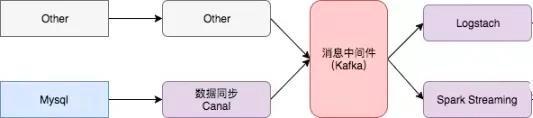
1.使用 Canal 来实时监听 Mysql 的数据变动
2.使用 Kafka 作为消息中间件,主要是为了屏蔽数据源的各种变动。比如以后即使用 Flume 了,我们架构也不用大变
3.数据落地,有一份都会落地 HDFS,这里使用 Spark Streaming,算是准实时落地,而且方便加入处理逻辑。在 落地 ES 的时候可以使用 Spark Streaming,也可以使用 Logstach,这个影响不大
四、一些问题
有两个小问题列一下。
1.小文件,分钟级别的文件落地,肯定会有小文件的问题,这里要考虑的是,小文件的处理尽量不要和数据接入流程耦合太重,可以考虑每天、每周、甚至每月合并一次小文件。
2.数据流的逻辑复杂度问题,比如从 Kafka 落地 HDFS 会有一个取舍的考虑,比如说,我可以在一个 SS 程序中就分别落地 HDFS 和 ES,但是这样的话两条流就会有大的耦合,如果 ES 集群卡住,HDFS 的落地也会受到影响。但是如果两个隔开的话,就会重复消费同一份数据两次,会有一定网络和计算资源的浪费。




 立即沟通
立即沟通