做数据库、大数据的来看看,ETL是SQL人辉煌的必经之路,有疑问吗
很多朋友会觉得写 CRUD 很无聊,翻来覆去就那么点花样。接触不到新鲜的技术,感觉自己要被这个时代淘汰了。于是怨天尤人,连基本的 SQL 都写不好了。
这可能是眼界与见识的问题。SQL 在行业内还是相当重要的,当然你说 CRUD 那点东西玩几个月就会了,没有新奇感。从技术角度来看,是这样,我承认。但换成业务角度来说,这又不是一回事了。这要细讲,我可以讲上三天三夜,所以留到以后的文章再说。
在 OLTP 系统中,CRUD 能做的事情,越来越少了。大部分都由前端框架封装好了。搞c#的同学有 Entity Framework, Java 系的同学有 Spring 全家桶。这些框架可以说,基本把 CRUD 同学的职位被抢掉了 2/3, 剩下纯搞 CRUD 的同学就偷着乐吧,也没几天了,想吃啥想喝啥,别委屈了自己。
真正能让 SQL 任凭手艺,还在 CRUD 行当里吃香的,喝辣的,技术上取决于你掌握了多少种数据库,SQL写得多快,要不然就是要享受福报了。
好在上帝关闭一扇窗的同时,他又打开了一道门。这道门便是数据仓库。
数据和银行的存款是一样的,越积越多,多得我们得千方百计思考该怎么用它。我们刚开始入行的时候,接触的数据库应用,十有八九都是业务系统,比如订单系统,生产系统和人事系统。
这是早就很多 CRUD boy/girl 的历史原因。随着年代的沉淀,数据越积越多,当报表越查越慢,分析师跑个查询要花费10多分钟,有可能还要使业务系统崩溃的时候,数据仓库就该出场了。
当我们尝试把分析用的数据,批量导出到另外一个数据库时, CRUD boy/girl 就大有可为了。
往小了说,数据仓库是在实现另类的读写分离,以空间换取业务系统的时间。当所有高IO吞吐量的只读查询,都跑到数据仓库上时,业务库承载的IO压力就会大大减少,从而提高业务库并发量。
往大了说,数据仓库串联了原先一个个信息孤岛,使得全面化分析变得可行。原本一个个业务系统,订单系统,库存系统,HR 系统,CRM, ERP等等,都是孤立地存在,每个系统产出的报表也只是自圆其说,各扫门前雪。
要想综合地看上下游数据的衔接,难以上青天。很多还在用 excel 作为导出数据的载体,用邮件分发这些整理好的 excel,让上下游衔接,痛苦吧。
所以需要专业的报表和BI工具,比如FineReport和FineBI,会极大地改善数据处理的流程,而且也会让企业的数据变得更清晰。
数据仓库的出现也是一种办法,通过 ETL 把各个系统之间的数据整合到一起,集中起来做分析,视角瞬间扩大。
而能将这些系统连接起来的,便是各位看文的读者了。总不至于让各位前端的“绣娘们”来完成导数的操作吧,毕竟这活儿他们是不屑的。
说完了 ETL 的目的,我们说说 ETL 怎么实现。这应该是大家急切想看的内容。接下来将从这些知识点切入:
ETL 架构怎么搭,
ETL 编程工具有哪些,
ETL 最新进展
ETL 的架构及编程工具
简单架构
先从简单的架构说起,比如单位里的信息软件管理系统(MIS)不多,我们搭建起来比较简单,可以抽象出来这样的架构图:
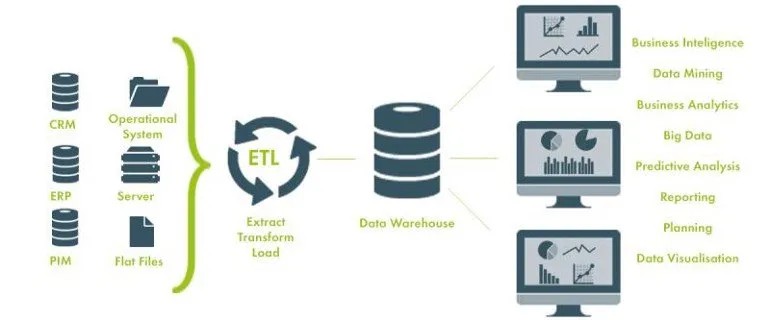
90年代起,国内建立了很多的信息管理系统,比如中小制造业工厂的进销存,大厂的MES,ERP等。这些初期的信息系统对关系型数据库的需求猛增,随之做数据库开发的朋友也越来越多。
初期建立的这些系统,都服务于特定的部门,比如销售部门的订单系统,生产部门的仓库管理,还有生产线上的 MES。虽然很快解决了特定部门的用数需求,提高了管理效率,但针对这么多小系统,在全公司范围内,能有一个统一视角来走查数据,是不够高效的。
甚至绝大多数公司,各个部门的数据接口是断层的。也就是,统计口径不唯一,给整个公司的运营层面带来的效率提升并不高。
因此,公司层面为了能够满足数据一致性,满足业务多维度的考察分析,开始了数据仓库的铺设。
早期的架构基本上都按照上面这张图设计。从公司早期建立的信息系统抽取数据,经过一系列数据格式的转变或合并,汇聚到一个数据库里面。各个部分需要数据时,从这个大集中的数据仓库中来取数。
熟悉数据仓库的朋友,都知道上图是 Kimball 理论的实现。Kimball 理论之所以这么流行,我想和他这种概念清晰好懂是分不开的。整个数据仓库项目,被清楚地划分为了四部分,源系统,ETL, 数据仓库,可视化分析。
注:这里涉及数据建模,通常会有 Kimball 与 Inmon 的对比。两者的优劣与选择,同样留到以后讲。
复杂架构
2000年左右,电商崛起。新经济形态带来巨量的数据,企业数据从原来的GB时代跨入了TB,PB时代。在巨量数据面前,原本的 ETL 架构满足不了高吞吐量的需求。因此,大数据技术应运而生。
而我们经历的数据时代,可以用这两张图来对比:
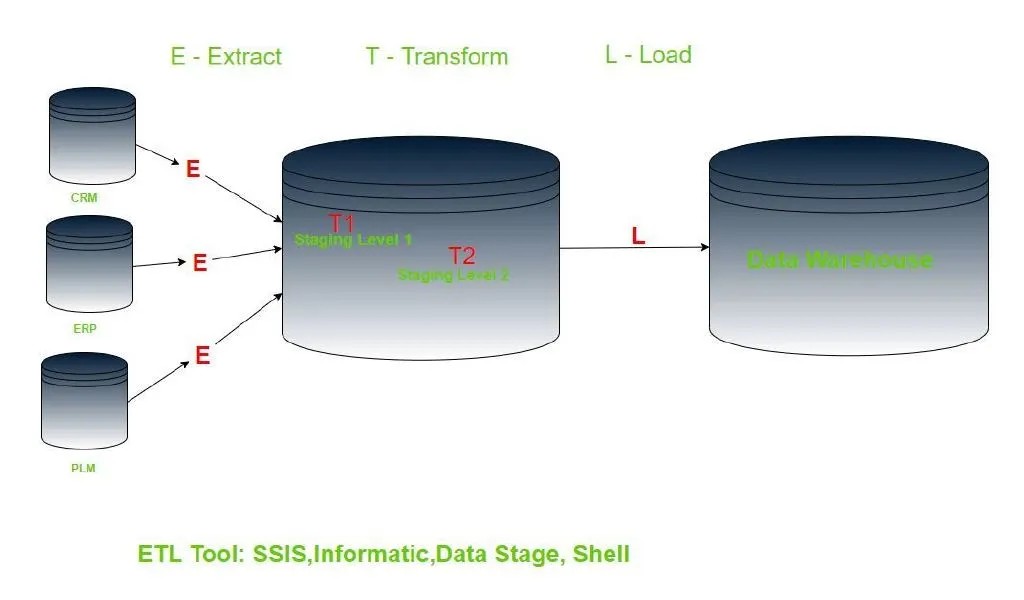
这是张经典的传统 ETL 架构图。将数据从各源业务系统区抽到缓冲数据存储库,经过存储过程做数据转换和聚合,再加载到数据仓库。每个项目都会有些细微的设计,但归总起来,就是这个流程。
当业务系统翻了十倍,甚至百倍的数据量之后,上面的 ETL 工具变得非常无力。因此引入了大数据技术。以 Hadoop 为基础的分布式存储和计算,使得分析和存储大量数据,变得高效。
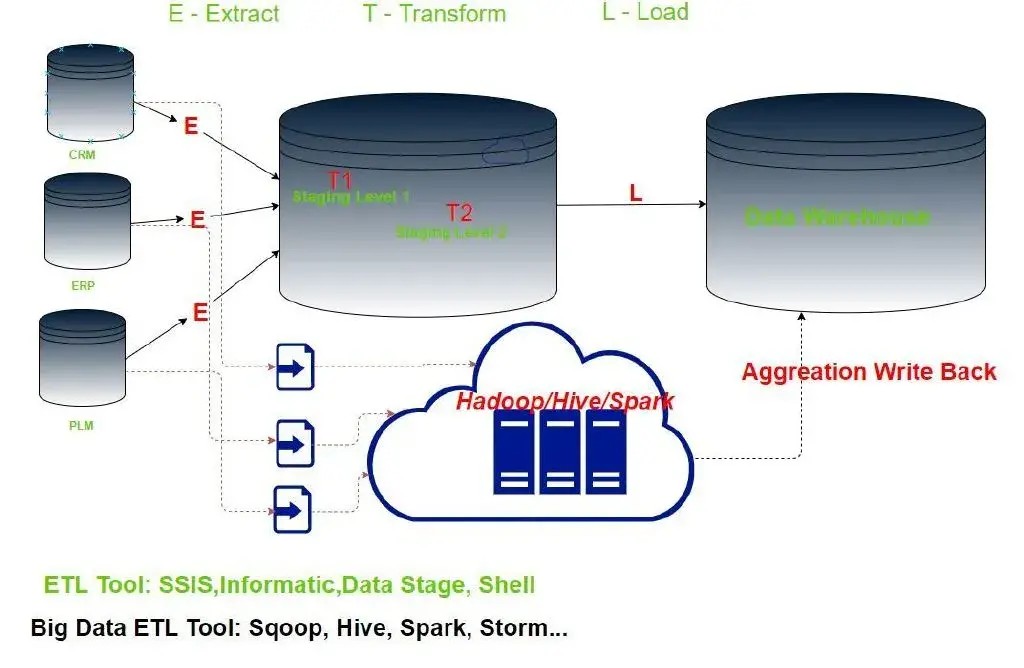
此时的ETL工具,围绕着 MapReduce 做了很多改造,比如 Sqoop, Hive, Spark 等等。借助这些工具,最终完成聚合计算,并同步到数据仓库中。
ETL 的最新进展
当数据应用有了实时要求时,一切开始变得好玩了。
在双12 看到自己心仪的衣服一件件卖完,而自己还没有排上号的时候,多么希望系统能自动推荐一些类似的宝贝。
作为影迷来说,碰到一部符合自己口味的电影,是多么难寻。刻意去寻找,总有些茫然,实时推送,便成了欣喜若狂。
而这一切,只有当我们还停留在心仪宝贝的页面时,才有效。所以加入了实时推荐,购物,看电影,听音乐等等,一切就都变成了乐趣。
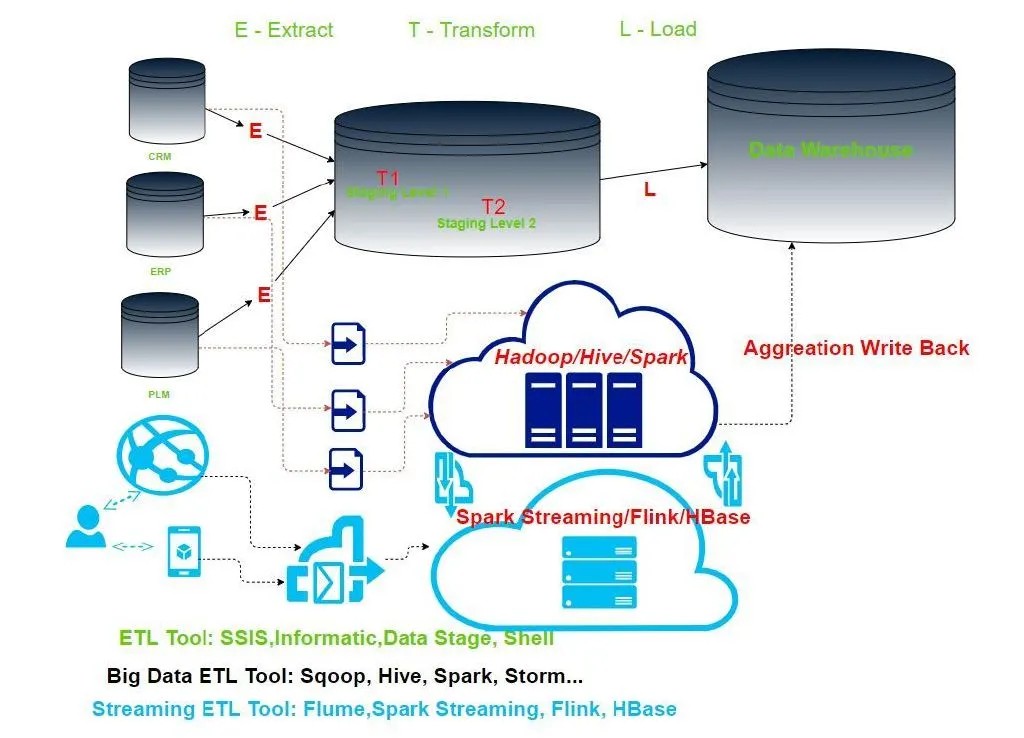
此时的实时数据处理,不再沿用传统的批次策略,而是每一次点击,滑动,切换都要实时地被计算框架给捕获,并给出反馈,或者推荐,或者聚合计算。类似 Flume, Kafka,Spark Streaming, Flink, HBase 的实时处理引擎,既要承接成百上千万的用户行为数据,还要与行为模型做交互,实时给出计算结果。
所以 ETL 是 SQL 人重启辉煌之光的必经之路。




 立即沟通
立即沟通