Data pipelines are the backbone of modern data management, propelling information seamlessly from its source to its destination. These pipelines play a crucial role in ensuring that data is efficiently processed, transformed, and stored for analysis. As businesses strive for enhanced decision-making and strategic insights, the significance of data pipelines continues to grow. In this blog, we will delve into the intricacies of data pipelines, exploring their definition, functions, components, and the myriad benefits they offer in today's data-driven landscape.
What is a Data Pipeline?
A data pipeline is the backbone of any data-driven organization, ensuring that data flows smoothly from its source to where it’s needed for analysis and decision-making. As businesses increasingly prioritize informed decision-making and strategic insights, the relevance and utilization of data pipelines continue to expand.
Definition of a Data Pipeline
A data pipeline is a system that automates the extraction, transformation, and loading (ETL) of data from various sources to a destination for analysis and use. It ensures the smooth and efficient flow of data, making it ready for querying and insights.
Basic Concept of a Data Pipeline
A data pipeline involves the systematic flow of data through three main stages: ingestion, processing, and storage/analysis.
Ingestion: Raw data is collected from various sources such as databases, logs, APIs, or streaming platforms. The data can be structured, semi-structured, or unstructured.
Processing: The ingested data is cleaned, transformed, and enriched to make it usable for analysis. This step includes tasks like data validation, normalization, aggregation, and filtering.
Storage/Analysis: The processed data is stored in a suitable repository like a data warehouse, data lake, or database. It can then be analyzed, queried, and visualized to derive insights and support decision-making.
Data pipelines can operate in batch mode or real-time, depending on the use case requirements. They are essential for organizations to efficiently manage and leverage their data for reporting, analytics, machine learning, and more.
Historical Context of a Data Pipeline
Data pipelines have undergone significant evolution alongside advancements in technology, transforming from basic data movement solutions into indispensable components driving business transformation. Here's a brief overview of their historical context:
Early Data Management
In the early days of computing, data was primarily managed using simple file systems and databases. Data movement and transformation were largely manual processes, often involving custom scripts and ad-hoc solutions. This approach was labor-intensive and prone to errors, limiting the ability to scale and handle growing volumes of data.
Emergence of ETL Processes
As businesses began to recognize the value of data for decision-making, the need for more structured and automated data management processes emerged. This led to the development of ETL (Extract, Transform, Load) tools in the 1970s and 1980s. ETL processes allow organizations to systematically extract data from various sources, transform it into a consistent format, and load it into a central data repository, such as a data warehouse. This was a significant step forward in data management, enabling more reliable and scalable data processing.
Growth of Data Warehousing
In the 1990s and early 2000s, data warehousing became a critical component of enterprise data strategy. Companies like Teradata, IBM, and Oracle developed sophisticated data warehouse solutions to support large-scale data storage and analysis. The rise of data warehousing further underscored the importance of efficient data pipelines to feed these repositories with clean, structured data.
Big Data Revolution
The mid-2000s saw the advent of big data technologies, driven by the explosion of data generated from web applications, social media, and IoT devices. Frameworks like Hadoop and later Spark revolutionized data processing by enabling distributed computing and the handling of massive datasets. Data pipelines had to evolve to accommodate these new technologies, supporting real-time data processing and more complex transformations.
Modern Data Pipelines
Today, data pipelines are an integral part of the modern data ecosystem. They support a wide range of data sources, including cloud services, real-time streaming data, and various APIs. Modern data pipelines are designed to be highly scalable, automated, and flexible, leveraging cloud-based platforms like AWS, Google Cloud, and Azure. Tools such as Apache Kafka, Apache NiFi, and cloud-native ETL services have made it easier to build and manage robust data pipelines.
In summary, the evolution of data pipelines reflects the broader trends in data management and technology, moving from manual processes to sophisticated, automated systems capable of supporting the complex data needs of modern organizations.
Key Functions of a Data Pipeline
A data pipeline is designed to ensure the smooth and efficient movement of data from various sources to its destination, preparing it for analysis and use. Here are its key functions:
Data Ingestion:
Collection: Gathering raw data from multiple sources such as databases, APIs, logs, and streaming platforms.
Integration: Combining data from disparate sources into a single, cohesive system for further processing.
Data Processing and Transformation:
Cleaning: Removing errors, duplicates, and inconsistencies to ensure data quality.
Validation: Ensuring that data meets predefined standards and criteria.
Transformation: Converting data into a desired format or structure, which may include normalizing, aggregating, or enriching the data.
Filtering: Excluding irrelevant or unnecessary data to focus on useful information.
Data Storage:
Loading: Moving processed data into storage systems such as data warehouses, data lakes, or databases.
Optimization: Storing data in a way that optimizes query performance and accessibility.
Data Orchestration and Workflow Management:
Scheduling: Automating the timing and sequence of data pipeline tasks.
Monitoring: Continuously tracking the pipeline’s performance to detect issues and ensure smooth operation.
Error Handling: Identifying and addressing errors or failures in the data flow to maintain data integrity and pipeline reliability.
Data Security and Compliance:
Encryption: Protecting data during transmission and storage to ensure confidentiality.
Access Control: Managing permissions and ensuring that only authorized users can access or modify the data.
Compliance: Adhering to regulatory requirements and data governance policies.
Real-time Processing:
Streaming Data Processing: Handling data as it arrives in real-time, enabling timely analysis and decision-making.
Event Handling: Responding to specific events or triggers in the data stream promptly.
Data Delivery and Visualization:
Exporting Data: Making processed data available to downstream systems, applications, or users.
Visualization: Creating dashboards, reports, and visual representations to make insights easily accessible and actionable.
In summary, the key functions of a data pipeline encompass the complete lifecycle of data from its initial collection to its final use, ensuring data quality, efficiency, and reliability throughout the process.
Components of a Data Pipeline
Data Sources of a Data Pipeline
In the realm of data pipelines, the types of data sources that serve as origins for information are diverse and varied, each contributing unique insights to the overall dataset. Understanding these sources is crucial for organizations seeking comprehensive analytics capabilities.
Internal Sources: Information generated within an organization, such as sales records, customer databases, or operational metrics.
External Sources: Data obtained from outside entities, like market research reports, social media feeds, or public datasets.
Streaming Sources: Real-time data streams that provide instant updates on various metrics, enabling prompt decision-making.
Legacy Systems: Historical databases or archives that store past information critical for trend analysis and forecasting.
When exploring examples of these data sources in action:
Customer Relationship Management (CRM) Systems: These platforms house valuable customer data, including contact details, purchase history, and preferences.
Social Media Platforms: Rich sources of user-generated content and engagement metrics that offer insights into consumer behavior and trends.
IoT Devices: Connected devices generate vast amounts of real-time data on performance, usage patterns, and environmental conditions.
Market Research Reports: External studies provide industry-specific data on market trends, consumer preferences, and competitive landscapes.
Data Processing of a Data Pipeline
Within the intricate framework of a data pipeline, the process of ETL (Extract, Transform, Load) plays a pivotal role in shaping raw data into actionable intelligence. This multifaceted approach involves extracting relevant information from diverse sources, transforming it into a standardized format, and loading it into storage for further analysis.
Extract: The initial phase involves retrieving raw data from various sources like databases, APIs, or files.
Transform: Subsequently, the extracted data undergoes transformation processes to ensure consistency and compatibility across different datasets.
Load: Finally, the refined data is loaded into designated repositories for storage and future retrieval.
When dealing with the ETL process, companies often face the challenge of manual, time-consuming processes. Significant time and effort are spent on manual data extraction, transformation, and loading (ETL), making these processes prone to errors and inefficiencies.
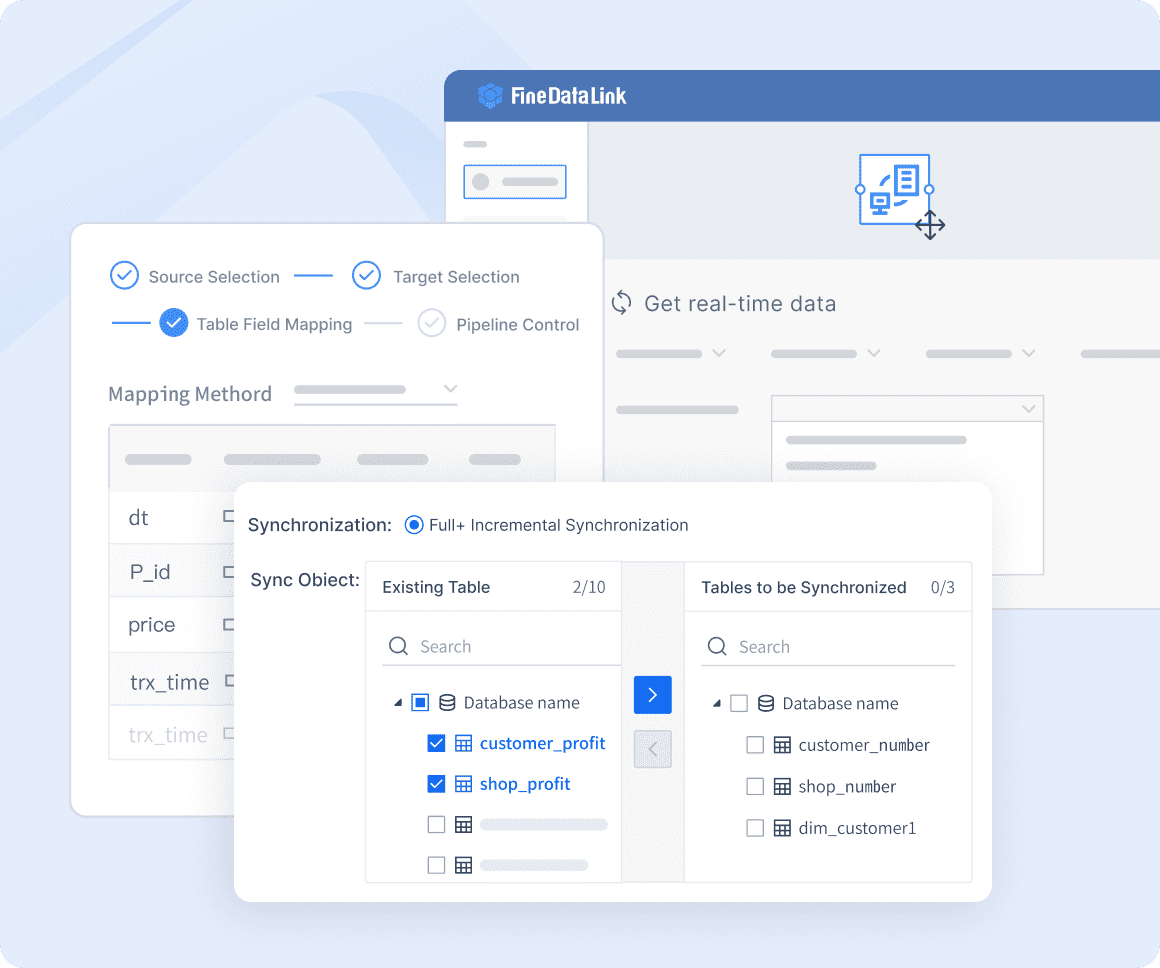
Using a professional data integration platform like FineDataLink can help companies overcome these ETL challenges. FineDataLink synchronizes data across multiple tables in real-time with minimal latency, typically measured in milliseconds. This makes it ideal for database migration and backup, as well as for building real-time data warehouses.
One of its core functions is timely data calculation and synchronization, which can be used for data preprocessing and as an ETL tool for data warehouse construction. Additionally, an API interface can be developed and launched in just five minutes without writing any code. This capability is especially useful for sharing data between different systems, particularly SaaS applications.
FineDataLink supports advanced ETL & ELT data development
Transform your data integration experience! Click the banner below to try FineDataLink for free and see how seamless data management can be!
Moreover, data validation serves as a critical checkpoint within the pipeline to verify the accuracy and integrity of processed information before storage or analysis. By implementing validation protocols and checks at key stages of processing, organizations can maintain high-quality datasets essential for informed decision-making.
Data Storage of a Data Pipeline
In the context of data pipelines, efficient storage mechanisms are paramount to safeguarding processed information while ensuring accessibility for analytical purposes. Two primary storage solutions commonly employed are data lakes and data warehouses, each offering distinct advantages based on organizational needs.
Data Lakes
Data lakes serve as vast reservoirs capable of storing structured and unstructured data in its native format without prior processing. This flexibility enables organizations to retain large volumes of raw information for future analysis without predefined schemas or structures.
Data Warehouses
On the other hand, data warehouses are optimized for efficiently querying and analyzing structured data sets. They organize information into tables with defined relationships and schemas, making complex queries more effective. By strategically leveraging these storage options within their pipelines, organizations can effectively manage their data assets and ensure seamless access to valuable insights when needed most.
Benefits of Data Pipelines
Efficiency of a Data Pipeline
In the realm of data management, data pipelines stand out as essential tools that significantly improve data efficiency and accuracy. By streamlining data management efforts, these pipelines automate repetitive tasks, reducing human errors and ensuring consistent data quality. Organizations can make quicker and more informed decisions by leveraging the capabilities of data pipelines to handle high volumes of structured and unstructured information efficiently. As modern technologies evolve, data pipelines integrate seamlessly with real-time processing frameworks, cloud-native solutions, machine learning integrations, and automation tools.
Automation
Data pipelines optimize resources effectively.
They reduce manual effort and streamline processes.
Performance is improved through efficient data processing.
Scalability
Efficiently handle high volumes of structured and unstructured information.
Support real-time processing for immediate insights.
Offer flexibility with various types of data for enhanced integration.
Ensure agility in operations by adapting to changes in sources and formats.
Data Quality of a Data Pipeline
Data pipeline solutions prioritize critical aspects such as governance, security, integrity, compliance, and orchestration throughout the entire data lifecycle. By automating workflows and streamlining development processes, these solutions enhance operational efficiency while reducing manual efforts. The focus on enhancing efficiency ensures that organizations can maintain consistent levels of performance while optimizing resource allocation effectively.
Consistency
Ensure consistency in handling diverse datasets.
Maintain high standards of quality across all processed information.
Reliability
Enhance reliability through robust security measures.
Comply with industry standards for secure data handling practices.
Real-Time Processing of a Data Pipeline
Data pipelines offer a high level of functionality by supporting real-time processing capabilities. This feature enables organizations to gain immediate insights from incoming data streams for prompt decision-making. The flexibility provided by these pipelines allows seamless scalability to meet evolving business needs efficiently.
Immediate Insights
By leveraging real-time processing features within data pipelines, organizations can promptly extract valuable insights from incoming datasets, enabling agile responses to changing market dynamics and consumer behaviors.
Business Applications
The applications of real-time processing extend beyond mere analytics, empowering businesses to implement dynamic strategies based on up-to-the-minute information. By harnessing the speed and adaptability of modern data pipeline solutions, organizations can stay ahead in competitive landscapes, anticipate trends proactively, and swiftly capitalize on emerging opportunities.
Implementing a Data Pipeline
Planning of a Data Pipeline
Identifying Requirements
To embark on the journey of implementing a data pipeline, organizations must first meticulously identify their requirements. This involves assessing the volume and variety of data to be processed, understanding the specific business objectives driving the need for a data pipeline, and defining key performance indicators (KPIs) to measure its success. By conducting a comprehensive analysis of these factors, companies can tailor their data pipeline to align seamlessly with their operational and analytical needs.
Choosing Tools
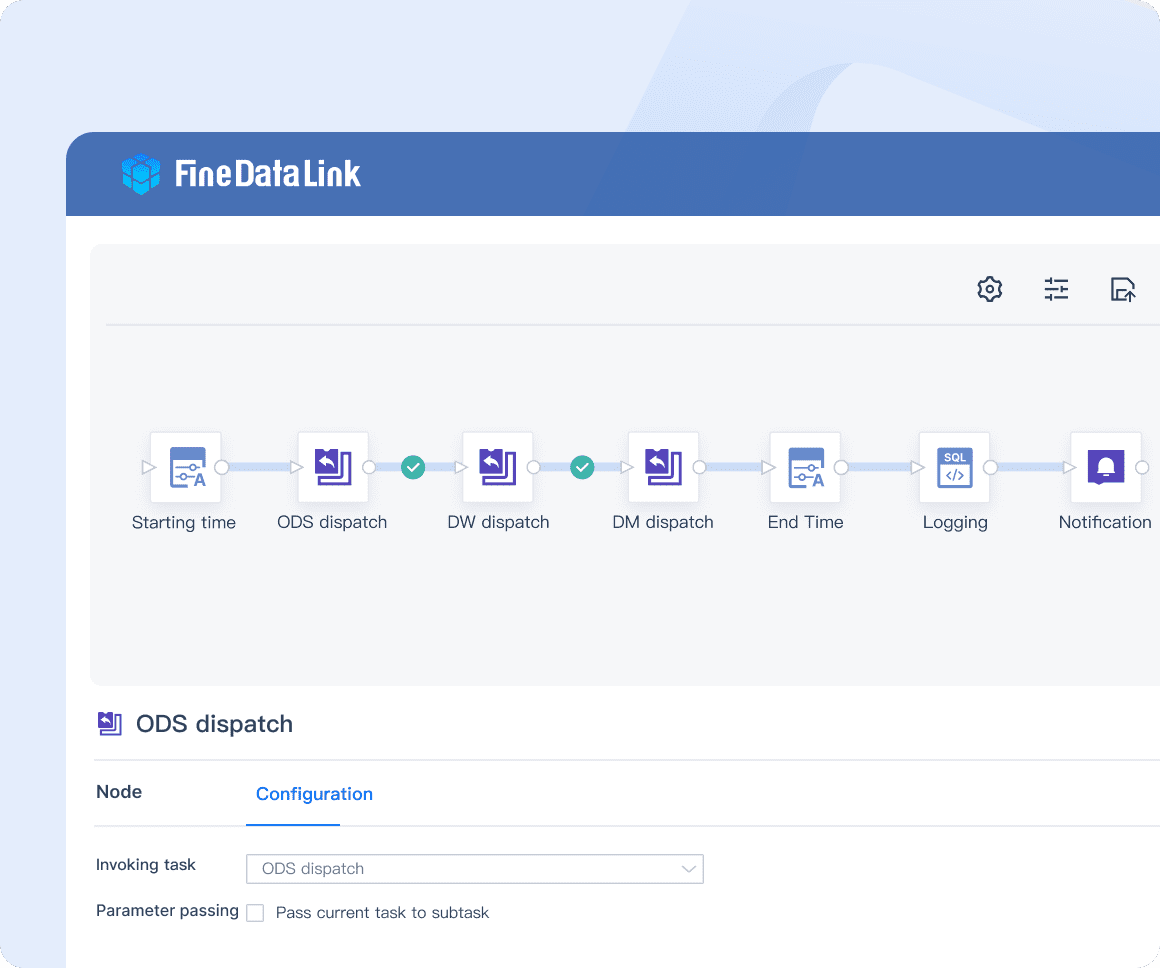
Selecting the right tools is crucial for the successful implementation of a data pipeline. FineDataLink stands out as a versatile solution, allowing users to define and schedule workflows efficiently. Its support for dynamic pipeline generation and task parallelization makes it an ideal choice for organizations seeking scalability and flexibility in their data processing operations. Additionally, FineDataLink serves as a reliable data integration platform, creating robust data pipelines and facilitating seamless data flow from source to destination.
Efficient data warehouse construction
The low-code platform streamlines the migration of enterprise data to the data warehouse, alleviating computational burdens.
Real-time Data Integration
Utilize data pipelines and log monitoring technology to effectively address challenges related to large data volumes and latency.
Application and API Integration
Leverage API data accounting capabilities to reduce interface development time from 2 days to just 5 minutes.
Enhanced Data Connectivity
Enable seamless data transmission between SaaS applications and across cloud environments.
As a modern and scalable data pipeline solution, FineDataLink tackles the challenges of data integration, data quality, and data analytics through three core functions: real-time data synchronization, ETL/ELT, and APIs.
Development of a Data Pipeline
Building the Pipeline
The development phase marks the practical realization of the planned data pipeline architecture. Leveraging tools like FineDataLink enables organizations to construct sophisticated pipelines tailored to their unique requirements. By democratizing data analytics through user-friendly interfaces and customizable workflows, businesses can streamline their data processing operations effectively. The ability to define operators and executors within these pipelines empowers users to orchestrate complex tasks with ease.
Testing
Thorough testing is essential to validate the functionality and reliability of a newly developed data pipeline. Tools such as Shipyard provide comprehensive testing capabilities that automate the validation process, ensuring that data extraction, transformation, and loading (ETL) processes function seamlessly. By simulating real-world scenarios and edge cases during testing, organizations can identify potential bottlenecks or issues early on, mitigating risks before deploying the pipeline into production environments.
Maintenance of a Data Pipeline
Monitoring
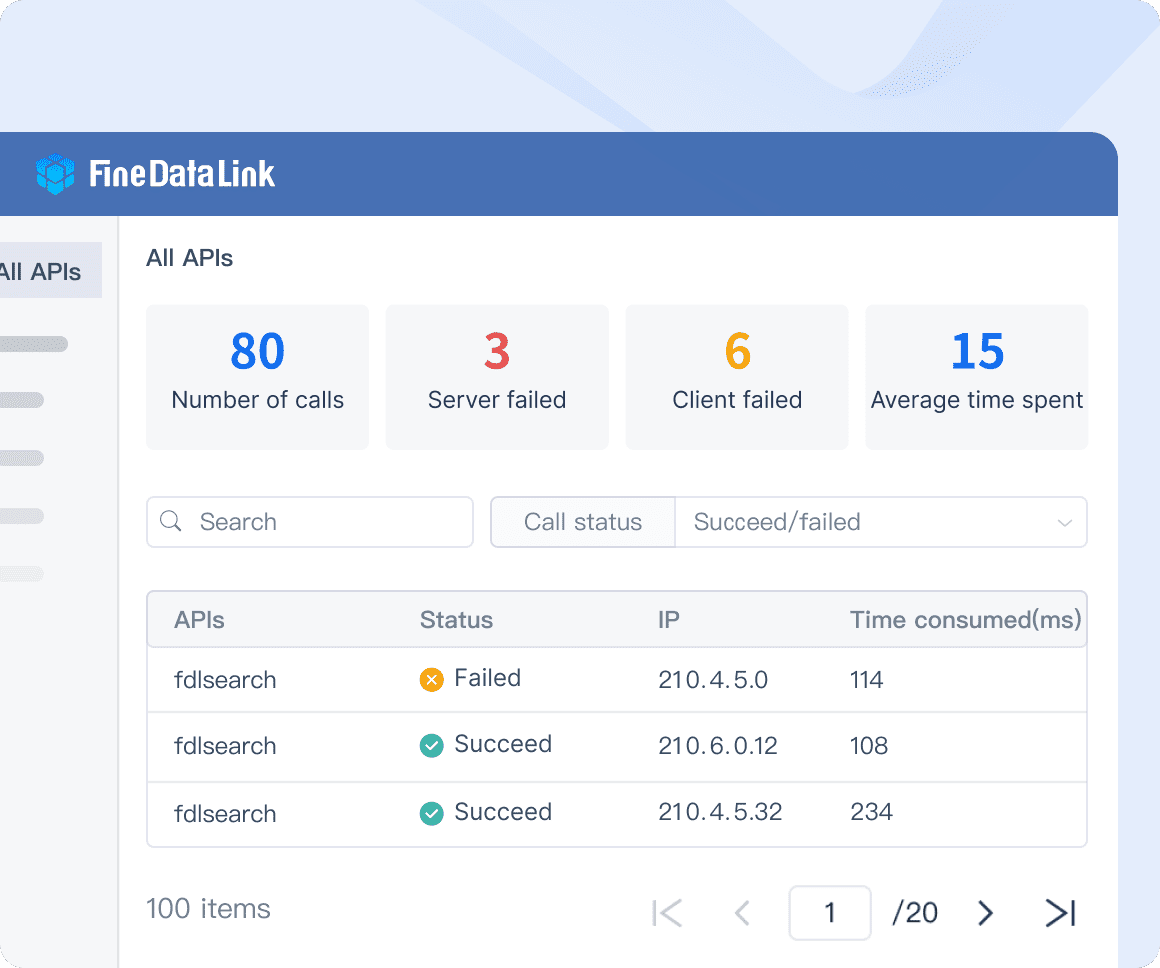
Continuous monitoring is critical in maintaining the optimal performance of a data pipeline post-implementation. Platforms like FineDataLink offer robust monitoring tools that track KPIs, detect anomalies, and provide real-time insights into pipeline efficiency. By proactively monitoring resource utilization, data throughput rates, and error logs, organizations can swiftly address any issues that may arise, ensuring uninterrupted data flow throughout the pipeline.
Troubleshooting
Inevitably, challenges may surface during the operation of a data pipeline that necessitates troubleshooting measures. Solutions like FineDataLink streamline troubleshooting processes by offering intuitive interfaces for identifying and resolving issues promptly. These tools enhance operational efficiency by minimizing downtime associated with debugging tasks while maintaining consistent data quality standards across all stages of processing.
By adhering to best practices in planning, development, maintenance, monitoring, and troubleshooting, organizations can optimize their use of cloud-native data pipeline tools to automate critical tasks associated with efficient data collection, consolidation, transformation, and loading into target systems such as data warehouses or lakes.
These tools not only expedite processing speeds but also simplify workflow setup, making them accessible even to non-technical users seeking rapid-deployment solutions for their analytics needs. Real-time data pipelines further elevate organizational capabilities by enabling swift capture, analysis, and action on incoming datasets, empowering businesses with timely insights for personalized services, recommendations, fraud detection, and anomaly identification.
Technologies like FineDataLink, Apache Flink, and Google Cloud Dataflow play pivotal roles in supporting real-time processing frameworks that drive continuous innovation in modern analytics landscapes.
Data pipelines are the cornerstone of modern data management, driving business success by converting raw datasets into valuable insights. Organizations leverage data pipelines to automate and scale repetitive tasks in the data flow, which is essential for timely and informed decision-making in today's dynamic business landscape. By effectively harnessing their data through these pipelines, businesses can gain a competitive edge, differentiate themselves from competitors, and stay ahead in the era of big data. The continuous evolution of data pipelines is crucial for organizations seeking real-time analytics capabilities to extract actionable insights promptly and efficiently.
In summary, by following best practices for selecting and implementing data pipeline solutions, businesses can effectively harness the power of these transformative tools to meet their evolving data needs. Considering these factors, FineDataLink may be your best choice.
Click the banner below to try FineDataLink for free and empower your enterprise to transform data into productivity!