A data pipeline is a tool that moves data from one place to another. You use a data pipeline to collect information, clean it, and send it where you need it, like an analytics dashboard or a database.
A data pipeline is like a city water system: it collects data from various sources, cleans and transforms it, and then pipes it to other systems such as analytics databases.
If you ever wondered what is a data pipeline, think of it as a way to make sure your data flows smoothly and reaches the right destination, ready for you to use.

When you ask, "what is a data pipeline," you start by looking at its main ideas. A data pipeline is a set of steps that moves data from one place to another. You use it to collect, clean, store, and deliver data so you can use it for analysis or reporting.
Here are the key concepts you need to know about a data pipeline:
Tip: A modular design makes your data pipeline easier to maintain. You can fix or upgrade one part without changing the whole system.
You should also think about scalability, fault tolerance, and security. A scalable data pipeline grows with your needs. Fault tolerance means your pipeline keeps working even if something fails. Security protects your data from threats.
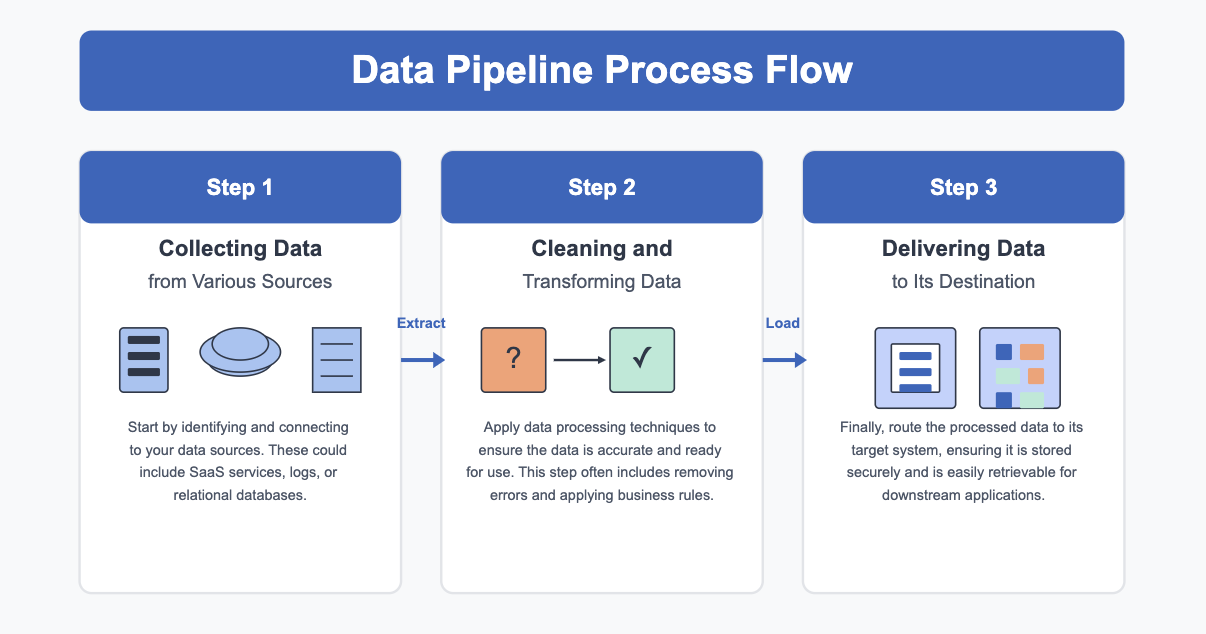
To understand what is a data pipeline, you need to see how it operates. A data pipeline works by moving data through several stages. Each stage has a clear purpose.
Here is a simple breakdown of how a data pipeline works:
A modern data pipeline includes extra features to make your work easier:
Note: Monitoring and alerts help you spot problems quickly. You can fix issues before they affect your business.
Modern data pipelines are different from traditional ones. Old pipelines often need a lot of manual coding and are hard to change. They can create data silos, making it tough to share data across teams. Modern pipelines use automation and modular design. You can scale them up or down as your needs change. They are easier to maintain and adapt to new data sources.
When you build a data pipeline, you make sure your data flows smoothly from start to finish. You avoid manual work, reduce errors, and get data where you need it, fast. You can use your data for analysis, reporting, or machine learning. This helps you make better decisions and grow your business.
A data pipeline brings real benefits to your organization. When you use a data pipeline, you make sure that everyone can access the right data at the right time. This helps you make trusted business decisions. You avoid delays because the data pipeline detects and fixes problems quickly. You also get a clear view of your data journey, so you can spot and solve quality issues before they affect your work.
Here are some reasons why businesses invest in a data pipeline:
| Benefit | How a Data Pipeline Helps |
|---|---|
| Better decisions | Automates data movement and ensures data quality |
| Cost savings | Subscription models and managed services lower expenses |
| Improved collaboration | Breaks down data silos and unifies data sources |
| Real-time analytics | Supports real-time data access for up-to-date insights |
A data pipeline also supports real-time analytics, so you can respond to changes as they happen. With real-time data access, your teams stay informed and agile.
Building and managing a data pipeline comes with challenges. You often deal with data in many formats and from different databases. This makes data integration complex. You need to design a flexible and scalable process to handle growing data volumes. If you do not validate and clean your data, you risk making decisions based on bad information.
Common challenges include:
To overcome these issues, you need strong validation and cleansing steps. Tools like FineDataLink help you solve these challenges. FineDataLink offers a modern data integration platform that automates data pipeline tasks, supports real-time data access, and connects over 100 data sources. With its low-code interface, you can build and manage your data pipeline easily, even as your needs grow.
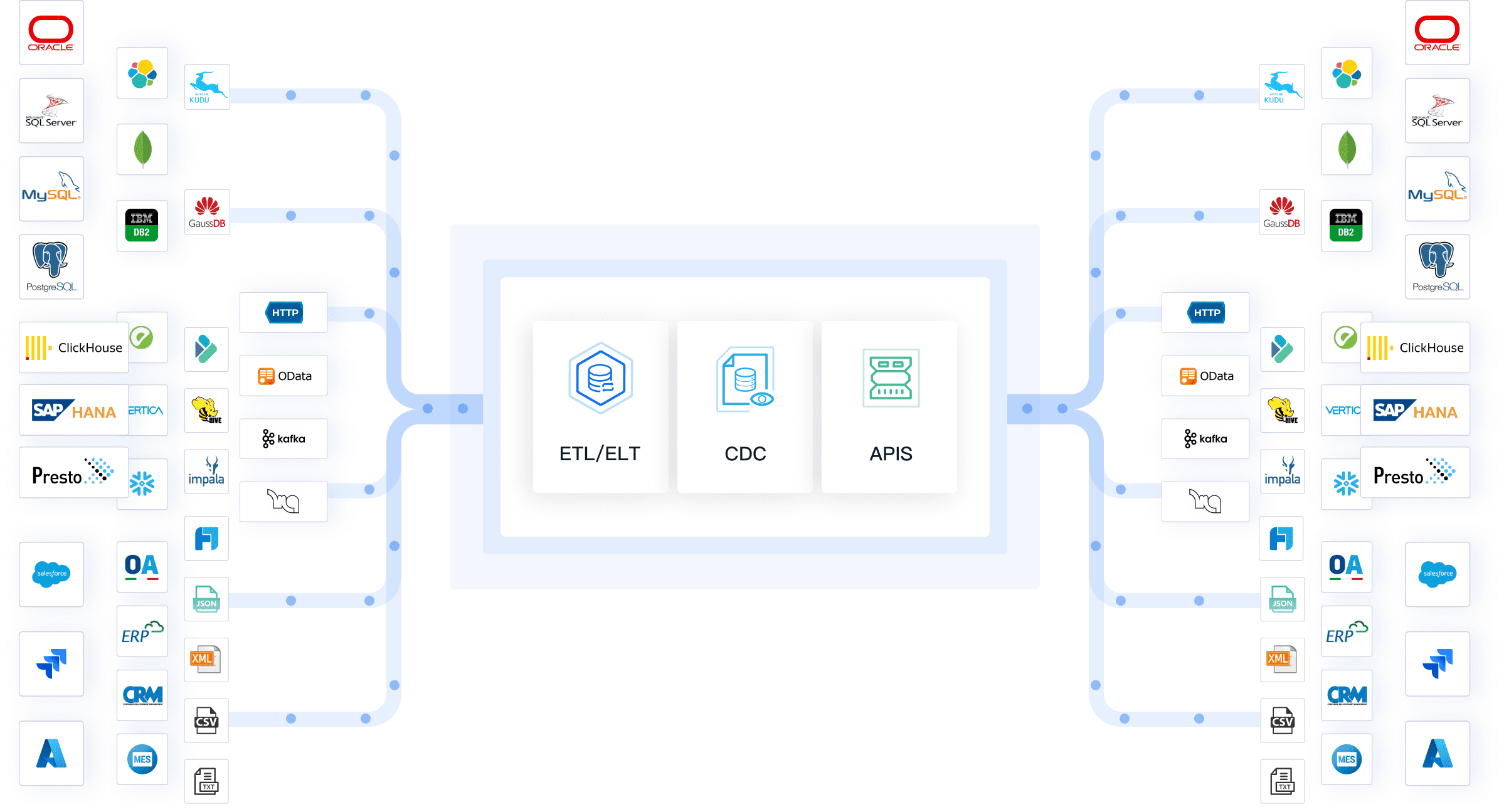

When you build a data pipeline, you work with several key components. Each part plays a specific role in moving and transforming your data. Understanding these components helps you design a system that meets your needs.
Here is a table that outlines the main components of a typical data pipeline:
| Component | Description |
|---|---|
| Data Source | The origin of the data, which can be internal or external, generating structured, semi-structured, or unstructured data. |
| Data Collection | The process of gathering data from various sources, involving cleaning, integration, and transformation. |
| Data Processing | Transforming data to make it valuable, including filtering, sorting, and aggregating. |
| Data Storage | Storing data in a centralized repository like a database or data warehouse, ensuring scalability and security. |
| Data Analysis | Using statistical and machine learning techniques to gain insights from the data. |
| Data Visualization | Presenting data visually through charts and dashboards to facilitate understanding and communication. |
Tip: Knowing each component helps you troubleshoot issues and optimize your data pipeline for better performance.
You can think of the data pipeline as a journey that your data takes from its source to its final destination. Data flows from sources such as SaaS applications, APIs, local files, or relational databases. You use a data ingestion pipeline to extract raw data, often through push notifications, webhooks, or API calls.
After collection, your data moves through several stages. You clean and transform it during data processing, making it ready for analysis. The pipeline architecture ensures that data moves efficiently from one stage to the next. Each stage connects to the next, so you always know where your data is and what happens to it.
A well-designed data pipeline collects data from multiple sources, processes it, and delivers it to target systems like dashboards or analytics tools. This structure supports efficient data movement and transformation, helping you meet your analytical goals. Understanding how data flows through each stage allows you to design a robust and reliable pipeline for your organization.
When you explore data pipelines, you find two main types: batch pipelines and streaming pipelines. Each type serves a different purpose and fits unique business needs.
A batch data pipeline collects and processes large amounts of data at scheduled times. You use this approach when you do not need instant results. For example, a retail company gathers all sales transactions at the end of each day. The system processes this data in one batch. You can analyze daily revenue, spot sales trends, and manage inventory efficiently. Batch pipelines work well for tasks that require complex data processing but do not need real-time updates.
A streaming data pipeline handles data as soon as it arrives. You use this type when you need immediate insights. Many industries rely on streaming pipelines for real-time decision-making. For instance, banks use streaming pipelines to detect fraud instantly. Ecommerce companies track customer behavior live to offer personalized recommendations. Logistics firms monitor shipments in real time to improve delivery speed.
| Industry | Example Use Case |
|---|---|
| Cybersecurity | Detect threats by analyzing security logs as they stream in. |
| Ecommerce | Track user actions and adjust recommendations instantly. |
| Banks and Finance | Spot fraud and support fast trading with live transaction analysis. |
| Logistics | Monitor shipments and inventory for better customer service. |
Streaming pipelines help you react quickly to changes and keep your business agile.
Note: FineDataLink supports both batch and real-time data pipelines. You can synchronize data in real time by monitoring database changes and using middleware like Kafka. This lets you build flexible solutions for both scheduled and live data needs.
| Type of Data Pipeline | Description |
|---|---|
| Batch Processing Pipelines | Move large amounts of data at set times, ideal for deep analysis and reporting. |
| Real-Time/Streaming Data Pipelines | Process data as it arrives, perfect for instant insights and live monitoring. |
You choose the right data pipeline based on your goals. FineDataLink gives you the tools to build both types, so you can meet any business challenge.
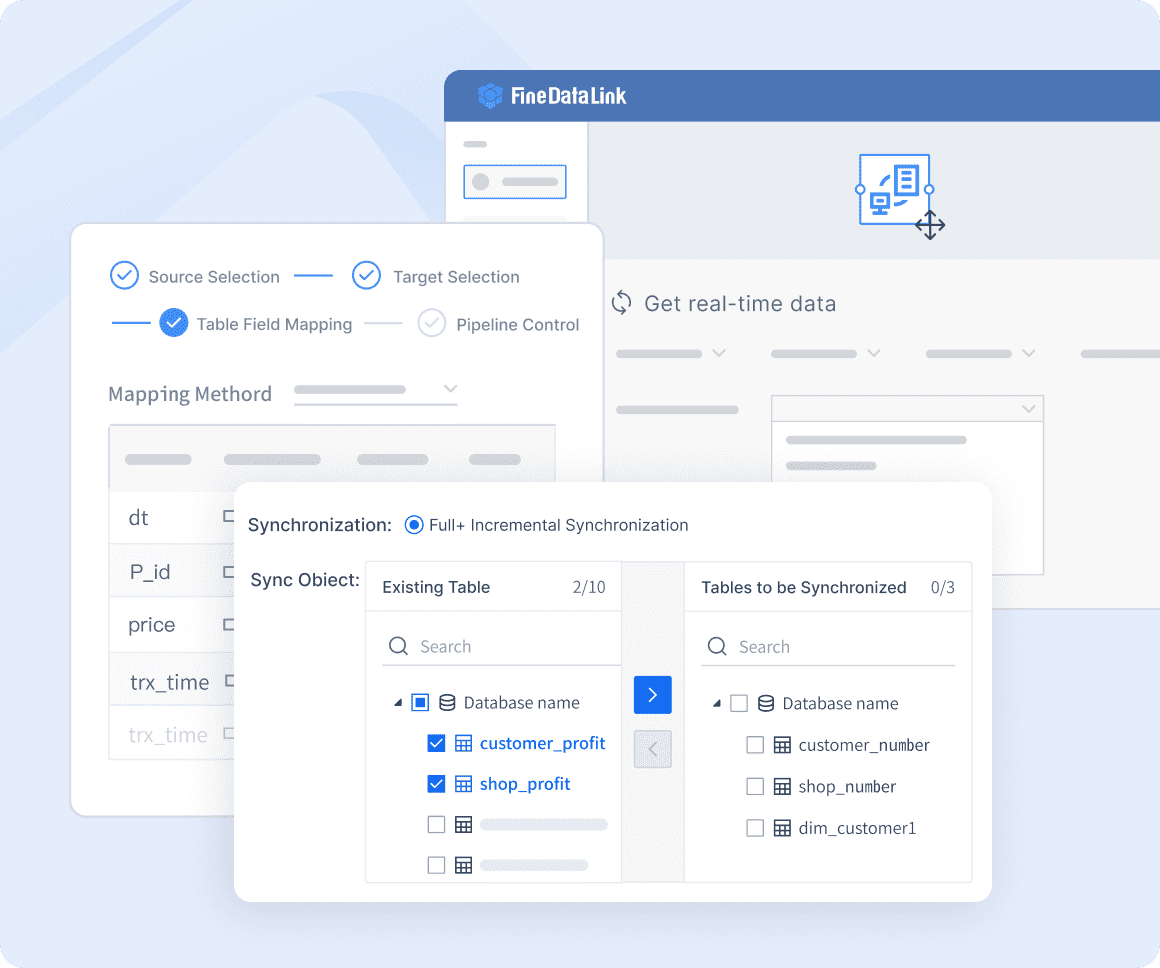
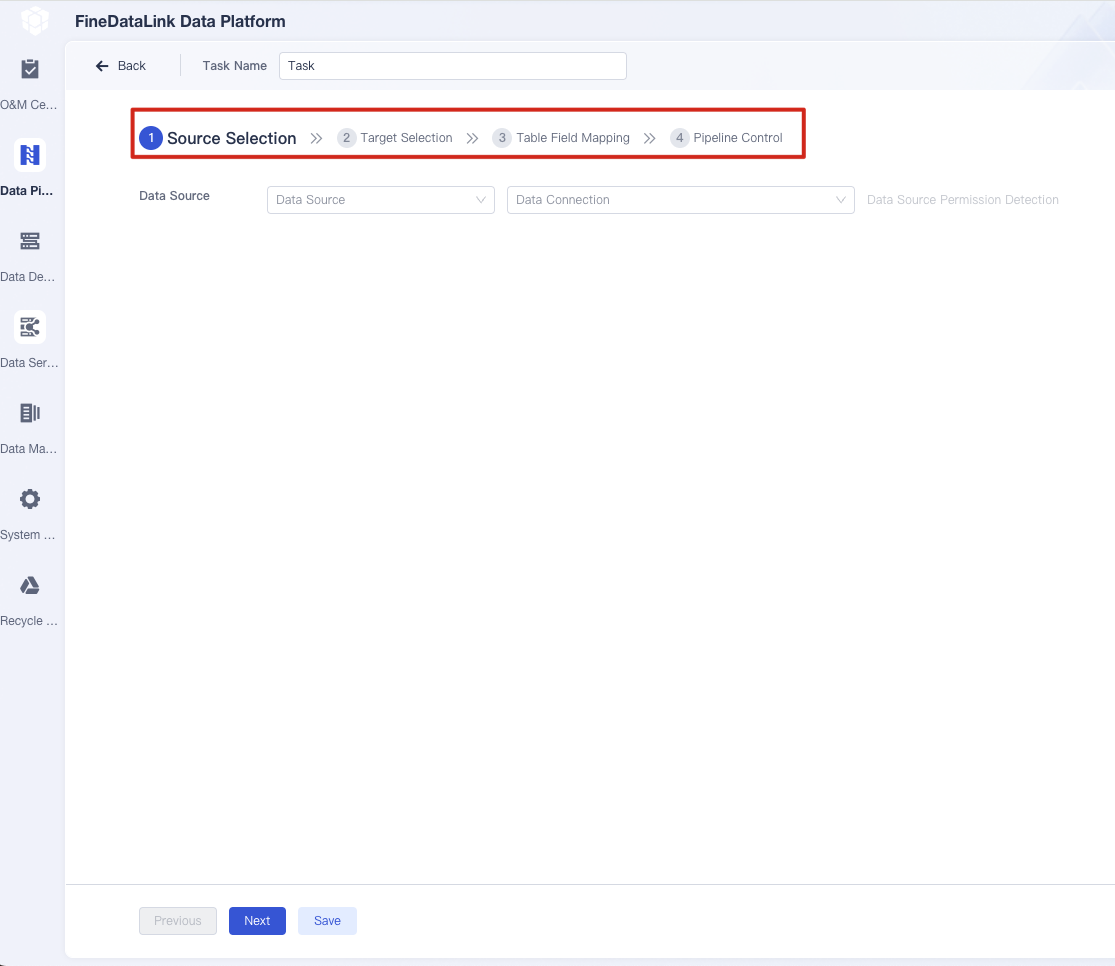
You can build a data pipeline with FineDataLink in a few straightforward steps. The platform uses a low-code, drag-and-drop interface, so you do not need advanced technical skills. You start by selecting your data sources. FineDataLink supports over 100 types, including databases, cloud services, and SaaS applications. You then drag and drop components to design your data processing pipeline. This visual approach helps you map out each stage, from data ingestion to transformation and storage.
After setting up your data flow, you configure real-time data access. FineDataLink enables you to synchronize data across systems with minimal delay. You can schedule batch jobs or set up streaming for real-time analytics. The platform also provides tools for monitoring and managing data quality and integrity. You can track each step, ensuring your data pipeline delivers reliable results.
Tip: FineDataLink’s visual workflow makes it easy to adjust your pipeline as your needs change, supporting scalability and flexibility for growing businesses.
FineDataLink offers several features that make data integration simple and effective:
FineDataLink supports both batch and streaming data pipelines, so you can handle large data volumes or real-time analytics. The platform includes built-in tools for data processing, transformation, and validation. You can monitor your pipeline’s performance and ensure data quality and integrity at every stage.
Many organizations have improved their operations with FineDataLink. For example:
| Company Name | Description |
|---|---|
| Noordzee | Gains real-time insights and accelerates data-driven decisions for future growth. |
| Mercedes Benz Türk | Streamlines travel and expense management, enhancing efficiency and employee experience. |
| TOP Medical | Brings innovations to market faster, improving patient care and demonstrating commitment to excellence. |
| DMK Deutsches Milchkontor | Drives data-driven decisions and boosts efficiency in the dairy industry. |
| SugarCreek | Optimizes its SAP environment with expert support and enhanced system performance. |
| KEB Automation KG | Delivers smart and efficient industrial solutions through engineering expertise and innovation. |
| Paul Vahle GmbH & Co KG | Specializes in power and data transmission systems, focusing on innovation and reliability. |
NTT DATA Taiwan also used FineDataLink to integrate backend systems and build a unified data platform. This helped them achieve better data processing and real-time analytics, supporting smarter business decisions.
FineDataLink gives you the tools to build a robust data pipeline that adapts to your needs. You can ensure data quality and integrity, achieve real-time data access, and scale your solution as your business grows.
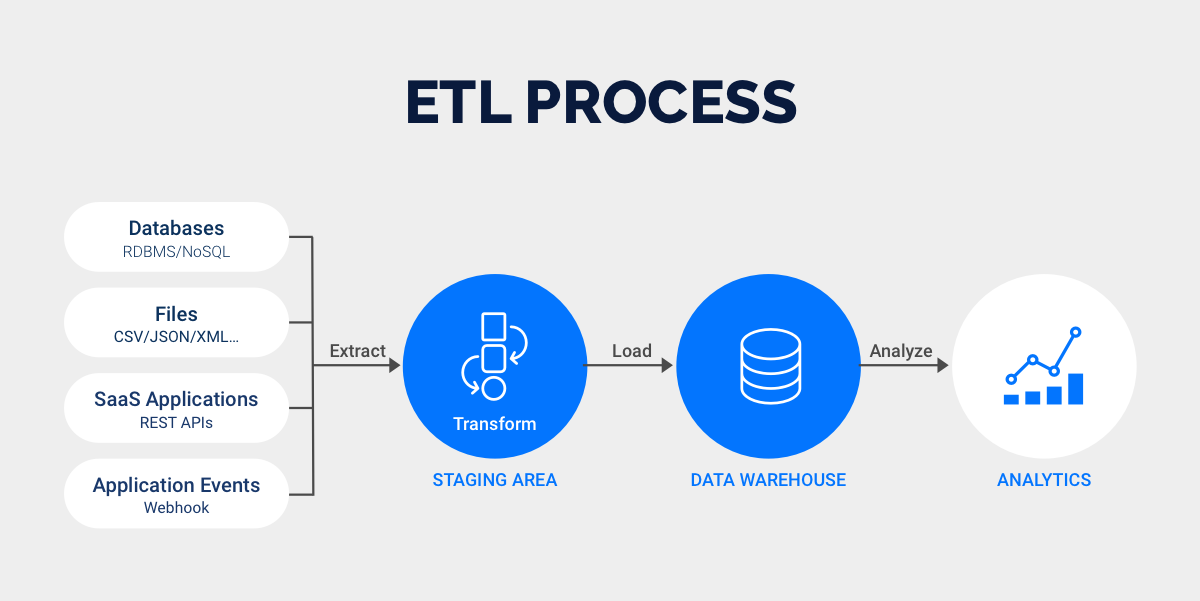
You might wonder how a data pipeline compares to ETL (Extract, Transform, Load). Both help you move and prepare data, but they work in different ways. A data pipeline is a broader concept. It covers any process that moves data from one place to another, including ETL steps, real-time streaming, and more. ETL focuses on extracting data from sources, transforming it, and loading it into a storage system, usually in batches.
Here is a table to help you see the main differences:
| Feature | ETL Pipeline | Data Pipeline |
|---|---|---|
| Data volume | Handles batch processing, less scalable | Scales easily with flexible processing |
| Data transformation | Batch-focused | Supports real-time and batch processing |
| Real-time vs. batch | Batch mode only | Real-time or near real-time possible |
| Latency | Higher latency | Lower latency with dynamic integration |
| Storage | Loads into data warehouse or lake | Loads into many destinations |
| Complexity | Less complex for standard tasks | Can be more complex with real-time needs |
| Integration | Works well with legacy systems | Fits modern data infrastructure |
| Monitoring | Monitors batch jobs | Monitors data flows continuously |
Tip: A data pipeline gives you more flexibility for modern data needs, while ETL works best for routine, scheduled tasks.
You should choose a data pipeline when you need to handle large or fast-growing data volumes. Data pipelines help you move data across systems quickly and accurately. They are ideal for real-time analytics, such as monitoring social media feeds or tracking financial transactions as they happen. If your business needs instant insights, a data pipeline is the right choice. You also benefit from data pipelines when you work with many data types, need automation, or want to build advanced solutions like machine learning workflows.
Use a data pipeline when:
On the other hand, ETL is a good fit for predictable, well-governed data processing. If your team relies on recurring dashboards or monthly reports, ETL ensures data accuracy and consistency. ETL also helps when you must follow strict privacy or governance rules, such as filtering or anonymizing sensitive data before storage.
Choose ETL when:
Note: Many organizations use both data pipelines and ETL, depending on their needs. You can combine them to get the best of both worlds.
You gain flexibility, improved data quality, and efficiency when you use a data pipeline in your organization. FineDataLink makes data integration simple with its low-code tools and real-time synchronization. You can connect different data sources and automate your workflows. As you master data pipelines, you prepare your business to respond quickly and make better decisions. Explore more resources to deepen your understanding and stay ahead in today’s data-driven world.

Mastering Data Pipeline: Your Comprehensive Guide
How to Build a Spark Data Pipeline from Scratch
Data Pipeline Automation: Strategies for Success
Understanding AWS Data Pipeline and Its Advantages

The Author
Howard
Data Management Engineer & Data Research Expert at FanRuan
Related Articles

Best Software for Creating ETL Pipelines This Year
Discover the top ETL pipelines tools for 2025, offering scalability, user-friendly interfaces, and seamless integration to streamline your data pipelines.
Howard
Apr 29, 2025

What is Data Pipeline Management and Why It Matters
Data pipeline management ensures efficient, reliable data flow from sources to destinations, enabling businesses to make timely, data-driven decisions.
Howard
Mar 07, 2025

2025 Data Pipeline Examples: Learn & Master with Ease!
Unlock 2025’s Data Pipeline Examples! Discover how they automate data flow, boost quality, and deliver real-time insights for smarter business decisions.
Howard
Feb 24, 2025



