Overall Equipment Effectiveness is one of the most useful manufacturing metrics when plant leaders need a clear answer to a simple question: how much of planned production time actually became good output. For operations directors, plant managers, maintenance leaders, and continuous improvement teams, that answer matters because hidden losses rarely show up in ERP reports, shift summaries, or top-line throughput alone.
If your line appears busy but output is still disappointing, if one shift always “looks fine” on paper but misses schedule, or if downtime discussions go nowhere because every team defines losses differently, Overall Equipment Effectiveness gives you a structured way to isolate what is really happening. Used correctly, it exposes where capacity disappears: stoppages, speed loss, and defects. Used poorly, it creates false confidence.
What Is Overall Equipment Effectiveness and why plant leaders use it
Overall Equipment Effectiveness, or OEE, is a manufacturing metric that measures the percentage of planned production time that is truly productive. In plain language, it tells you how much scheduled time was converted into good parts, at the right speed, with the equipment actually running.
This is why plant leaders rely on it. OEE does not just show whether a machine was on. It shows whether the asset was:
- available when it was supposed to run,
- performing near its ideal speed,
- and producing acceptable output the first time.
The three core factors behind OEE
OEE is built from three factors:
- Availability: Was the equipment running during planned production time?
- Performance: When it was running, did it run at the expected rate?
- Quality: Of everything produced, how much met requirements the first time?
These three factors matter because they separate different failure modes that often get mixed together in operations reviews. A line can have high uptime but poor OEE because of slow cycles. Another can run fast but waste too much output in scrap or rework. A third may have strong quality but lose hours to changeovers and breakdowns.
What Overall Equipment Effectiveness can reveal
When definitions are consistent and data is reliable, Overall Equipment Effectiveness helps uncover:
- Hidden losses that do not appear in finished-goods totals alone
- Chronic bottlenecks that reduce plant capacity
- Process discipline issues such as inconsistent startup procedures or poor stop coding
- Maintenance impact on run time and asset reliability
- Speed losses that are often ignored because the line is technically “running”
- Quality leakage from rework, startup scrap, or unstable process windows
For plant leadership, this makes OEE valuable not just as a metric, but as an operational language. Maintenance, production, engineering, and quality can all use the same framework to discuss loss.
What OEE can and cannot tell you on its own
This is where many organizations get into trouble. OEE is powerful, but it is not a complete operating system.
OEE can tell you:
- how much planned production time became fully productive time,
- whether the primary loss is Availability, Performance, or Quality,
- where to start improvement work.
OEE cannot tell you by itself:
- whether you are making the most profitable product mix,
- whether labor is optimized,
- whether schedule adherence is realistic,
- whether customer service levels are improving,
- whether inventory, changeover strategy, or planning decisions are causing downstream waste.
A strong OEE score with weak schedule attainment can still be a business problem. Likewise, a lower OEE in a high-mix environment may be operationally acceptable. The metric needs context.
How OEE is calculated correctly
The standard formula is straightforward:
OEE = Availability × Performance × Quality
That simplicity is useful, but it also creates risk. Many misleading OEE results come from incorrect inputs, inconsistent time rules, or mixing units carelessly.
Key Metrics (KPIs)
To calculate Overall Equipment Effectiveness correctly, you need a tight definition for each input:
- Planned Production Time: The time the asset is scheduled and expected to produce. Excludes periods where there is no intention to run, such as planned breaks or shutdown windows.
- Run Time: Planned Production Time minus stop time. This is the actual time the equipment was running.
- Stop Time: Any time during planned production when the asset should have been running but was not. This may include breakdowns, changeovers, material shortages, or waiting events, depending on your standard.
- Ideal Cycle Time: The fastest sustainable time to produce one unit under defined optimal conditions. It must be realistic, stable, and consistently applied.
- Total Count: All units produced during run time, including both good units and rejected units.
- Good Count: Units that meet specification the first time, without rework.
- Availability: Run Time ÷ Planned Production Time.
- Performance: (Ideal Cycle Time × Total Count) ÷ Run Time.
- Quality: Good Count ÷ Total Count.
- Overall Equipment Effectiveness: Availability × Performance × Quality.
Percentages and units: where errors start
The math only works if units are aligned.
For example:
- If Run Time is in minutes, then Ideal Cycle Time × Total Count must also be converted to minutes.
- If Availability, Performance, and Quality are expressed as percentages, convert them properly before multiplying.
Correct approach:
- Availability = 90% = 0.90
- Performance = 95% = 0.95
- Quality = 98% = 0.98
- OEE = 0.90 × 0.95 × 0.98 = 0.8379 = 83.79%
Common bad approach:
- 90 × 95 × 98 = nonsense unless converted back properly
- minutes mixed with hours
- parts counted in one system while rejects come from another with a different timestamp basis
A mathematically correct formula can still produce an operationally useless answer if definitions are weak.
Definitions behind Availability, Performance, and Quality
Availability: the share of planned production time when the equipment is actually running
Availability answers the question: during the time we planned to produce, how much time did the machine actually run?
Formula:
Availability = Run Time ÷ Planned Production Time
If a line is scheduled for 420 minutes and loses 60 minutes to downtime, then:
- Run Time = 420 − 60 = 360 minutes
- Availability = 360 ÷ 420 = 85.71%
Availability is where breakdowns, changeovers, waiting for material, and other stop events typically show up. The key risk is inconsistency. If one line includes changeovers and another excludes them, comparison becomes meaningless.
Performance: how fast the equipment runs compared with its ideal rate while it is running
Performance answers: when the line was running, how close was it to the ideal speed?
Formula:
Performance = (Ideal Cycle Time × Total Count) ÷ Run Time
This captures both slow running and minor stops that do not get coded as downtime. If your line “never stops” but still under-delivers output, Performance usually explains the gap.
The biggest trap here is a bad ideal cycle time. If it is set too generously, Performance looks better than reality. If Performance exceeds 100%, your standard is likely wrong.
Quality: the share of output that meets requirements the first time
Quality answers: of everything produced, how much was good without rework?
Formula:
Quality = Good Count ÷ Total Count
If the line made 10,000 units and 300 were rejected or required rework:
- Good Count = 9,700
- Quality = 9,700 ÷ 10,000 = 97.0%
The phrase “first time” matters. If you count reworked parts as good without tracking the original defect, Quality becomes artificially inflated.
A simple step-by-step example
Let’s walk through a single shift.
Assume:
- Shift length: 8 hours = 480 minutes
- Breaks excluded from planned production: 60 minutes
- Planned Production Time: 420 minutes
- Downtime during planned production: 50 minutes
- Run Time: 370 minutes
- Ideal Cycle Time: 1.5 seconds per part
- Total Count: 13,200 parts
- Rejects: 400 parts
- Good Count: 12,800 parts
Step 1: Calculate Availability
Availability = Run Time ÷ Planned Production Time
= 370 ÷ 420
= 0.8810
= 88.10%
Step 2: Calculate Performance
First convert run time into seconds so the units match the ideal cycle time.
- Run Time = 370 minutes = 22,200 seconds
- Ideal Cycle Time × Total Count = 1.5 × 13,200 = 19,800 seconds
Performance = 19,800 ÷ 22,200
= 0.8919
= 89.19%
Step 3: Calculate Quality
Quality = Good Count ÷ Total Count
= 12,800 ÷ 13,200
= 0.9697
= 96.97%
Step 4: Calculate OEE
OEE = Availability × Performance × Quality
= 0.8810 × 0.8919 × 0.9697
= 0.7620
= 76.20%
This result is mathematically correct. But the operational insight is more valuable than the number alone:
- Availability is weak but not catastrophic.
- Performance is also a major loss area.
- Quality is comparatively stronger.
That tells leadership where to focus first. In this case, improving uptime alone will not solve the full problem if speed loss remains chronic.
Common arithmetic mistakes to avoid
The most frequent OEE calculation errors are basic but damaging:
- Mixing minutes and seconds in the Performance formula
- Using hours for Run Time and seconds for Ideal Cycle Time without conversion
- Using Total Count in one place and Good Count in another incorrectly
- Multiplying percentages as whole numbers instead of decimals
- Including breaks in Planned Production Time for one line but not another
- Counting rework as good output without a first-pass quality rule
These mistakes can make a dashboard look polished while hiding deeply flawed logic.
The most common reasons OEE results become misleading
Most OEE failures are not formula failures. They are governance failures. The formula is easy. The discipline behind it is hard.
Inconsistent definitions of downtime
If Line A logs changeovers as downtime but Line B excludes them, Availability becomes non-comparable. The same problem occurs across shifts and plants when local teams create their own stop codes or thresholds.
This is especially common in multi-site operations where legacy practices remain in place. Leadership sees one normalized OEE figure, but the underlying rules are different.
Inflated ideal cycle times
Performance depends on one critical standard: ideal cycle time. If that standard is too slow, Performance improves on paper without any real operational gain.
This creates one of the most dangerous situations in reporting: a metric that rewards low expectations. When Performance looks healthy despite operator complaints, missed schedules, and chronic minor stops, the ideal rate is often the problem.
Incorrect treatment of rework, startup scrap, or inspection holds
Quality is another area where definitions get bent. Teams may:
- exclude startup scrap,
- count reworked parts as good without tracking the original defect,
- delay rejects into another period,
- hold suspect inventory outside the metric.
The result is a Quality score that appears stable while first-pass yield is deteriorating.
Incomplete data from manual logs and disconnected systems
Manual production logs are vulnerable to:
- delayed entries,
- missing stop reasons,
- rounded time estimates,
- end-of-shift memory errors,
- incomplete reject coding.
Disconnected systems make this worse. The machine count may say one thing, the MES another, and the quality log a third. If timestamps do not reconcile, your Overall Equipment Effectiveness result becomes a rough approximation, not a trusted metric.
Why dashboards can tell a comforting but false story
A dashboard can be visually impressive and still misleading.
Averaged data hides chronic short stops and minor stops
A daily average may show decent Performance, while the line actually suffers from frequent five-to-fifteen-second interruptions that operators clear without escalation. Those losses accumulate fast, but aggregated views can hide them.
Excluded losses can make a line look world class when it is not
If planned maintenance, extended changeovers, startup losses, or waiting events are excluded without a clear rule, OEE improves artificially. Leaders may believe an asset is performing at an elite level when real capacity is still leaking away.
A single number masks the source of lost capacity
An OEE score of 78% can come from many different patterns:
- low Availability, strong Quality
- strong Availability, weak Performance
- high speed, poor Quality
- moderate losses in all three
Managing by the headline number alone creates bad decisions. Improvement requires loss visibility, not score obsession.
How to measure OEE without distorting the truth
If you want trustworthy Overall Equipment Effectiveness, you need standardization before automation. This is where many plants reverse the sequence. They deploy dashboards first, then argue over definitions later.
That approach almost guarantees false comparability.
Standardize loss definitions before comparing teams, assets, or sites
Before benchmarking, define:
- what counts as planned production time,
- what qualifies as downtime,
- which events are Availability losses versus Performance losses,
- how to classify startup, warm-up, and test production,
- what constitutes a good part,
- how rework is handled.
Document these rules and make them mandatory across sites. Without this, cross-line or cross-plant OEE comparisons are not credible.
Use the same time basis and data rules for every calculation period
Daily, weekly, and monthly OEE should be built from the same calculation rules. If one report uses shift-level data and another uses summarized ERP output, discrepancies will appear. The same applies to timezone issues, shift boundaries, and delayed quality confirmation.
A metric becomes trusted only when the logic remains stable period after period.
Separate loss categories consistently
Keep these categories distinct:
- planned stops
- unplanned downtime
- speed losses
- quality losses
Blending them may simplify reporting, but it weakens diagnosis. Improvement teams need to know whether to focus on maintenance, setup reduction, operator standard work, process stability, or defect prevention.
Audit data sources regularly
A reliable OEE program includes periodic validation of:
- machine timestamps,
- count accuracy,
- reject coding,
- shift calendars,
- stop reason completeness,
- event thresholds.
This audit discipline matters more than most teams expect. A dashboard can automate bad logic just as efficiently as good logic.
Practical rules for cleaner and more trustworthy data
Define ownership for every data field
Assign a clear owner for each key field:
- production schedule owner,
- stop code owner,
- quality disposition owner,
- ideal cycle time owner,
- report governance owner.
If no one owns a field, it will drift.
Review exceptions in advance
Decide how you will treat:
- changeovers,
- warm-up periods,
- first-piece approval,
- test runs,
- engineering trials,
- cleaning cycles,
- operator training periods.
Do not leave these decisions to end-of-shift interpretation.
Compare automated records with operator reality
Automation improves speed and consistency, but it can still miss context. Sensors may show that a machine is technically running while operators know the line is starved, blocked, or cycling abnormally. Use regular reconciliation between system records and shop-floor experience.
Document every assumption
Every OEE model contains assumptions. Capture them explicitly:
- threshold for stop events,
- standard cycle basis,
- reject timing logic,
- rework treatment,
- calendar exclusions.
This makes future comparisons defensible and prevents “metric drift.”
How to use OEE to drive better decisions
The best plants do not use OEE as a vanity KPI. They use it as a decision tool.
Use OEE trends alongside other operating metrics
Overall Equipment Effectiveness becomes more useful when paired with:
- throughput
- schedule attainment
- maintenance compliance
- mean time between failure
- scrap and rework rates
- changeover time
- labor efficiency
- on-time delivery
This combination helps leadership distinguish between apparent efficiency and actual business performance.
Prioritize improvement based on the biggest constraint
When OEE is broken down properly, it reveals where to attack first:
- If Availability is weakest, focus on breakdowns, setup loss, waiting events, and planning discipline.
- If Performance is weakest, investigate minor stops, reduced speed, line balancing, and operating standards.
- If Quality is weakest, prioritize process capability, defect root cause analysis, startup stability, and first-pass control.
This sounds obvious, but many plants still launch broad improvement programs without first identifying the dominant loss mechanism.
Avoid turning OEE into a target that encourages gaming
The moment OEE becomes a score people are punished for, behavior changes:
- downtime gets recoded,
- ideal cycle times get relaxed,
- rejects get deferred,
- bad product gets reworked quietly,
- changeovers get reclassified.
That is why mature organizations use OEE to learn, not just to judge. The purpose is to expose loss honestly enough to remove it.
Build a review rhythm that links losses to action
A strong operating cadence usually includes:
- Real-time or intrashift visibility for immediate response
- Daily loss review for supervisors and support teams
- Weekly trend analysis for recurring causes and countermeasures
- Monthly leadership review tied to capacity, service, and investment decisions
This review rhythm is where Overall Equipment Effectiveness stops being a dashboard number and becomes a management process.
Actionable best practices for implementing OEE the right way
Here are four practical steps I recommend in almost every plant deployment:
1. Build the measurement standard before you build the dashboard
Create a written OEE rulebook first. Lock definitions for planned production time, downtime, ideal cycle time, good count, and exception handling before any visualization goes live.
2. Start with one line, one product family, and one governance team
Pilot in a stable area where standards are easier to maintain. Validate data quality there before scaling to a site-wide or enterprise rollout.
3. Reconcile automated and manual records for at least several weeks
During implementation, compare sensor events, production records, and operator logs daily. The gaps you uncover early will prevent long-term reporting credibility issues.
4. Review loss patterns, not just the final OEE number
Every improvement meeting should look at Availability, Performance, Quality, and the top recurring loss reasons. If the review only discusses the headline score, the process will stall.
When OEE is useful and when another metric is better
Overall Equipment Effectiveness works best in environments with:
- repetitive production,
- stable routing,
- well-defined cycle standards,
- clear quality criteria,
- consistent scheduling.
That makes it especially effective for many discrete and repetitive manufacturing operations.
It is less straightforward in:
- high-mix, low-volume production,
- job shops,
- engineering-to-order environments,
- processes with frequent recipe changes,
- operations where cycle standards vary significantly by product.
In those environments, other measures may be more useful for decision-making, such as:
- schedule attainment,
- lead time,
- first-pass yield,
- asset utilization by product family,
- constraint throughput,
- on-time completion.
The key leadership principle is simple: do not manage by one number alone. Use OEE where it fits, and always keep operational context attached.
Building trustworthy OEE at scale with FineReport
Building this manually is complex; use FineReport to utilize ready-made templates and automate this entire workflow.
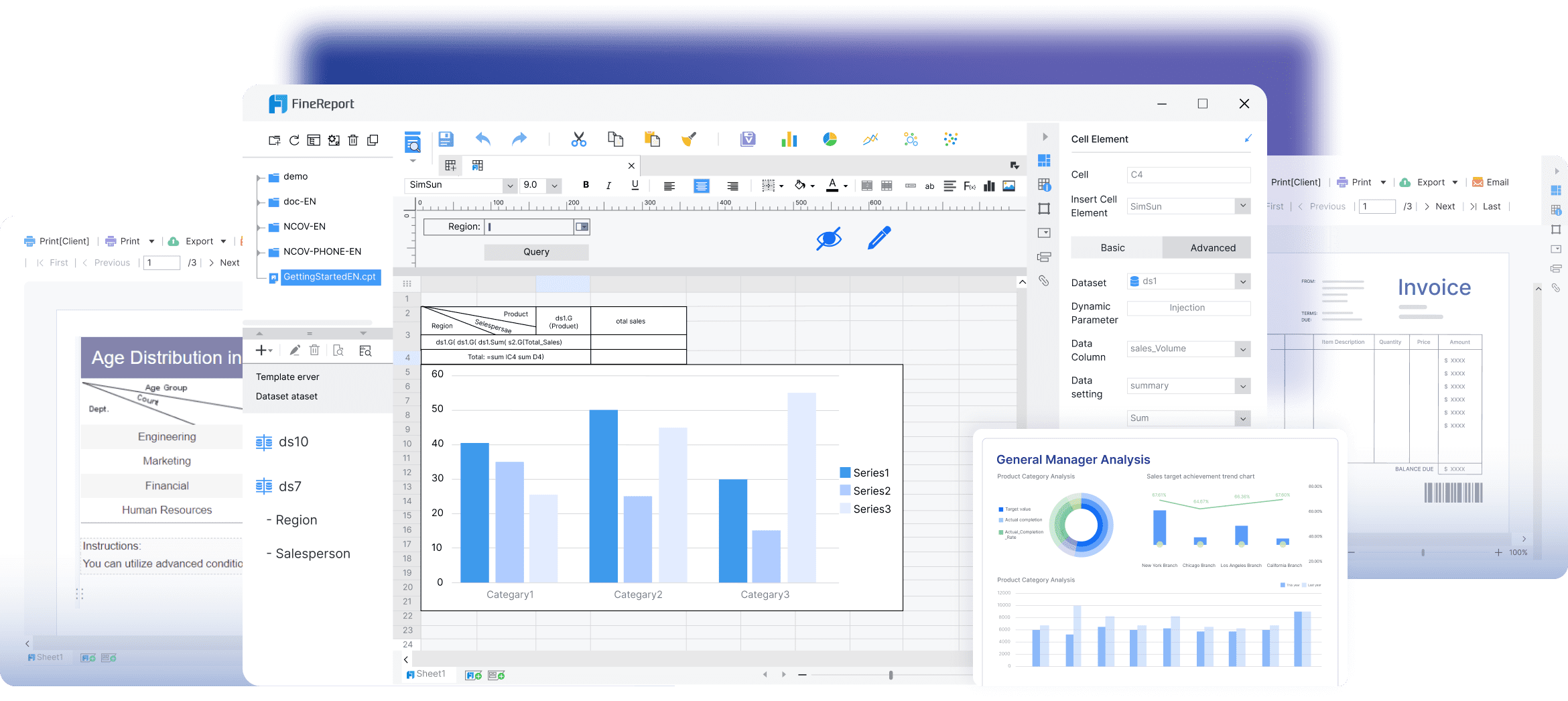
Most plants do not struggle with the OEE formula. They struggle with the enterprise reality around it:
- data scattered across PLCs, MES, ERP, and quality systems,
- inconsistent loss coding,
- manual Excel consolidation,
- delayed reporting,
- weak mobile visibility for frontline leaders,
- dashboards that show numbers but not usable insight.
FineReport helps solve that operational gap by turning OEE from a fragile spreadsheet exercise into a governed, enterprise-grade reporting workflow.
Why FineReport is a strong fit for OEE use cases
With FineReport, manufacturers can:
- Integrate multiple data sources into one trusted reporting layer
- Standardize KPI definitions across lines, shifts, and sites
- Automate dashboard refresh and report distribution
- Support drill-down analysis from plant summary to line, shift, stop reason, and reject category
- Deliver reports on PC and mobile so supervisors and executives can act faster
- Create templates for daily, weekly, and monthly OEE reviews
- Enable exception alerts and operational follow-up when quality or yield drops below thresholds
This matters because OEE only improves when the metric becomes actionable. A plant leader should not have to wait days for analysts to merge logs, reconcile counts, and rebuild charts in Excel before a review meeting.
A practical enterprise workflow with FineReport
A strong deployment pattern looks like this:
1. Integrate and govern the data
Connect production, maintenance, quality, and schedule data into a unified reporting model. Standardize time logic, loss definitions, and count rules centrally.
2. Build role-based OEE views
Give each stakeholder the right lens:
- executives see plant and site trends,
- operations managers see line and shift comparisons,
- maintenance sees breakdown patterns,
- quality teams see reject and rework impact.
3. Automate reporting and distribution
Use scheduled reports and dashboards so shift leaders, plant managers, and operations directors receive the latest OEE status without manual compilation.
4. Add drill-down and exception management
When OEE drops, teams should be able to move immediately from the headline KPI to the exact stop reason, time window, product, or defect category behind the loss.
5. Turn metrics into a repeatable management rhythm
Use FineReport templates to standardize daily loss review meetings, weekly trend analysis, and monthly performance summaries across plants.
The business case
For enterprise decision-makers, the value is not just prettier reporting. It is:
- less manual reporting effort,
- fewer data definition disputes,
- faster root-cause visibility,
- more credible benchmarking,
- better capacity decisions,
- stronger improvement accountability.
That is the difference between “having an OEE dashboard” and actually managing Overall Equipment Effectiveness as a trusted operational system.
If your current OEE process depends on disconnected logs, spreadsheet math, and inconsistent rules, the next step is not another cosmetic dashboard. The next step is a governed reporting architecture. FineReport gives you the templates, automation, and cross-system visibility to build that foundation faster and scale it with confidence.
FAQs
OEE, or Overall Equipment Effectiveness, measures how much planned production time becomes good output at the right speed while equipment is actually running. It combines Availability, Performance, and Quality into one metric.
OEE is calculated as Availability × Performance × Quality. To do it correctly, you need consistent definitions for planned production time, stop time, ideal cycle time, total count, and good count.
Misleading OEE usually comes from inconsistent time rules, incorrect ideal cycle times, missing stop reasons, or mixing units such as seconds and minutes. Scores above 100% are a strong sign that the inputs are wrong.
A good OEE score depends on your process, product mix, and operating model, so there is no universal target that fits every plant. OEE should be used with context rather than treated as a standalone benchmark.
OEE can show where productivity is being lost through downtime, speed loss, and defects. It cannot by itself tell you whether your product mix, labor plan, schedule, or profitability is optimized.





The Author
Yida Yin
FanRuan Industry Solutions Expert
Related Articles

How to Build a Manufacturing Production Report Dashboard Plant Managers Actually Use
A manufacturing $1 dashboard should help plant managers run the floor, not just explain results after the fact. If supervisors still rely on whiteboards, spreadsheets, and verbal updates after your dashboard launch, the
Yida Yin
May 31, 2026
Digital Production Tracking Dashboard Solutions: A Scenario-Based Guide to Real-Time Manufacturing Visibility
Digital production tracking dashboard solutions exist to solve a costly operational problem: manufacturing teams cannot improve what they cannot see in time. For plant managers, line supervisors, operations directors, an
Yida Yin
May 21, 2026
Building an SPC Dashboard: 7 Must-Track Metrics for Statistical Process Control
Learn the 7 essential SPC dashboard metrics for manufacturing quality control, including process stability, capability, and defect rate.
Yida Yin
May 11, 2026