데이터 분석에서 표준편차는 데이터의 분포와 변동성을 정량적으로 보여주는 핵심 지표입니다. 평균만으로는 데이터의 다양성을 파악하기 어렵기 때문에, FanRuan의 FineBI와 같은 도구는 표준편차를 시각화하여 데이터 해석과 비즈니스 의사결정의 신뢰도를 높입니다.
표준편차는 데이터가 평균을 중심으로 얼마나 퍼져 있는지를 나타내는 대표적인 산포도 지표입니다. 데이터 분석에서 평균만으로는 데이터의 다양성과 분포를 충분히 설명할 수 없습니다. 표준편차는 각 데이터가 평균에서 얼마나 떨어져 있는지, 즉 데이터의 흩어짐 정도를 수치로 보여줍니다.
데이터의 편차 합은 항상 0이 되기 때문에 단순히 편차들의 합을 이용한 산포도는 의미가 없습니다. 이를 해결하기 위해 편차를 제곱하여 분산을 구하고, 분산은 평균으로부터 데이터가 얼마나 퍼져 있는지를 나타냅니다. 하지만 분산은 제곱 단위로 값이 커져 해석이 어렵기 때문에, 분산에 제곱근을 씌워 원래 단위로 되돌린 표준편차를 사용합니다.
표준편차는 분산을 해석하기 쉽게 만든 값으로, 분산은 계산을 위한 값이고 표준편차는 해석을 위한 값이라고 이해할 수 있습니다.
수학적으로 표준편차는 다음과 같이 정의됩니다.
표준편차 = √(Σ(xi - 평균)² / n)여기서 xi는 각 데이터 값, 평균은 데이터의 평균값, n은 데이터의 개수입니다. 표준편차가 작으면 데이터가 평균에 가까이 모여 있고, 표준편차가 크면 데이터가 평균에서 멀리 퍼져 있음을 의미합니다.
표준편차는 데이터의 분포와 변동성을 직관적으로 파악할 수 있게 해줍니다. 다양한 분야에서 표준편차를 활용하여 데이터의 신뢰도와 안정성을 평가합니다. 예를 들어, 시험 점수의 표준편차가 작으면 학생들의 성적이 고르게 분포되어 있음을 의미합니다. 반면, 표준편차가 크면 성적 차이가 크다는 뜻입니다.
아래 표는 여러 분야에서 표준편차가 어떻게 활용되는지 보여줍니다.
| 사례 분야 | 표준편차 활용 내용 설명 |
|---|---|
| 품질 관리 | 과자 무게의 표준편차를 통해 무게의 일관성 확인 및 생산 과정 문제 탐지 |
| 투자 위험 평가 | 주식 수익률의 표준편차를 통해 투자 위험도 평가 및 수익 변동성 파악 |
| 기상 예측 | 연간 기온의 표준편차를 통해 지역 기후 특성 이해 및 기후 변동성 분석 |
| 시험 점수 분포 | 시험 점수의 분포를 분석하여 학생들의 성취도 및 변동성 파악 |
| 직원 업무 성과 평가 | 직원들의 업무 성과 분포를 분석하여 평가 및 관리에 활용 |
| 환자 건강 지표 분석 | 혈압, 콜레스테롤 등 건강 지표의 분포를 분석하여 환자 상태 평가 |
표준편차는 데이터의 신뢰성과 예측 가능성을 높이는 데 중요한 역할을 합니다. FanRuan의 FineBI와 같은 데이터 분석 도구는 표준편차를 시각화하여 사용자가 데이터의 변동성을 쉽게 파악할 수 있도록 지원합니다. 이를 통해 기업은 품질 관리, 투자 위험 평가, 성과 분석 등 다양한 분야에서 데이터 기반 의사결정을 내릴 수 있습니다.
표준편차를 계산하는 과정은 다음과 같습니다. 각 단계는 데이터의 변동성을 정확하게 파악하기 위해 중요합니다.
표준편차를 보고할 때는 평균과 함께 "평균 = 13.5 (SD = 1.3)"과 같이 표기하는 것이 바람직합니다. 여러 평균을 보고할 경우, 각 평균에 대응하는 표준편차 값을 반드시 포함해야 합니다.
아래 표는 편차 제곱의 의미와 표준편차 공식에서의 역할을 정리한 것입니다.
| 개념 | 설명 및 역할 |
|---|---|
| 편차 제곱의 의미 | 편차가 음수가 될 수 있어 절댓값 대신 제곱을 사용하여 음수 문제를 해결하고, 편차 크기를 명확히 표현함. |
| 분산 | 편차 제곱의 평균으로, 데이터가 평균에서 얼마나 흩어져 있는지를 수치화함. 분산은 표준편차를 구하기 위한 중간 단계임. |
| 표준편차 | 분산의 제곱근으로 정의되며, 분산에서 발생한 제곱 단위 왜곡을 보정하여 원래 데이터 단위로 흩어짐 정도를 나타냄. |
표본 표준편차와 모집단 표준편차 공식의 차이점도 중요합니다.
실제 데이터셋을 활용하여 표준편차를 계산하는 예시를 살펴보겠습니다.
이 예시에서 표준편차는 학생들의 점수가 평균에서 얼마나 퍼져 있는지를 보여줍니다. 표준편차가 크면 점수 차이가 크다는 의미입니다. 표준편차는 데이터의 변동성을 직관적으로 이해할 수 있게 해주며, 통계 모델링과 데이터 분석에 필수적인 역할을 합니다.
FanRuan의 FineBI와 같은 데이터 분석 도구를 활용하면, 복잡한 계산 과정을 자동화하고 다양한 데이터셋에 대해 표준편차를 빠르게 산출할 수 있습니다. FineBI는 데이터 시각화와 실시간 분석 기능을 제공하여, 사용자가 표준편차를 기반으로 데이터의 분포와 변동성을 쉽게 파악할 수 있도록 지원합니다.
FineBI의 Def 함수와 OLAP 분석 기능을 활용하면, 표본과 모집단 표준편차를 구분하여 정확한 통계 분석을 수행할 수 있습니다. 또한, 여러 데이터 소스를 통합하여 표준편차를 포함한 다양한 통계 지표를 한눈에 확인할 수 있습니다.
표준편차는 데이터가 평균에서 얼마나 퍼져 있는지, 즉 변동성의 크기를 나타내는 핵심 지표입니다. 데이터 분석과 비즈니스 인사이트 도출에 있어 표준편차의 정확한 계산과 해석은 매우 중요합니다.

학교에서는 학생들의 시험 점수를 분석할 때 표준편차를 자주 사용합니다. 표준편차가 작으면 학생들의 점수가 평균에 가까이 모여 있다는 뜻입니다. 상위권 학생이 많을수록 표준편차가 작아집니다. 반대로 표준편차가 크면 점수 분포가 넓고, 상위권 학생이 적다는 의미입니다.
이러한 분석을 통해 교사는 시험 난이도와 학생들의 성취도 분포를 평가할 수 있습니다. 예를 들어, 수학 시험에서 표준편차가 크고 상위권 학생 비율이 낮으면 시험이 어려웠고 학생들의 실력 차이가 크다는 해석이 가능합니다. 학교는 이 정보를 바탕으로 교육 방침을 조정합니다.
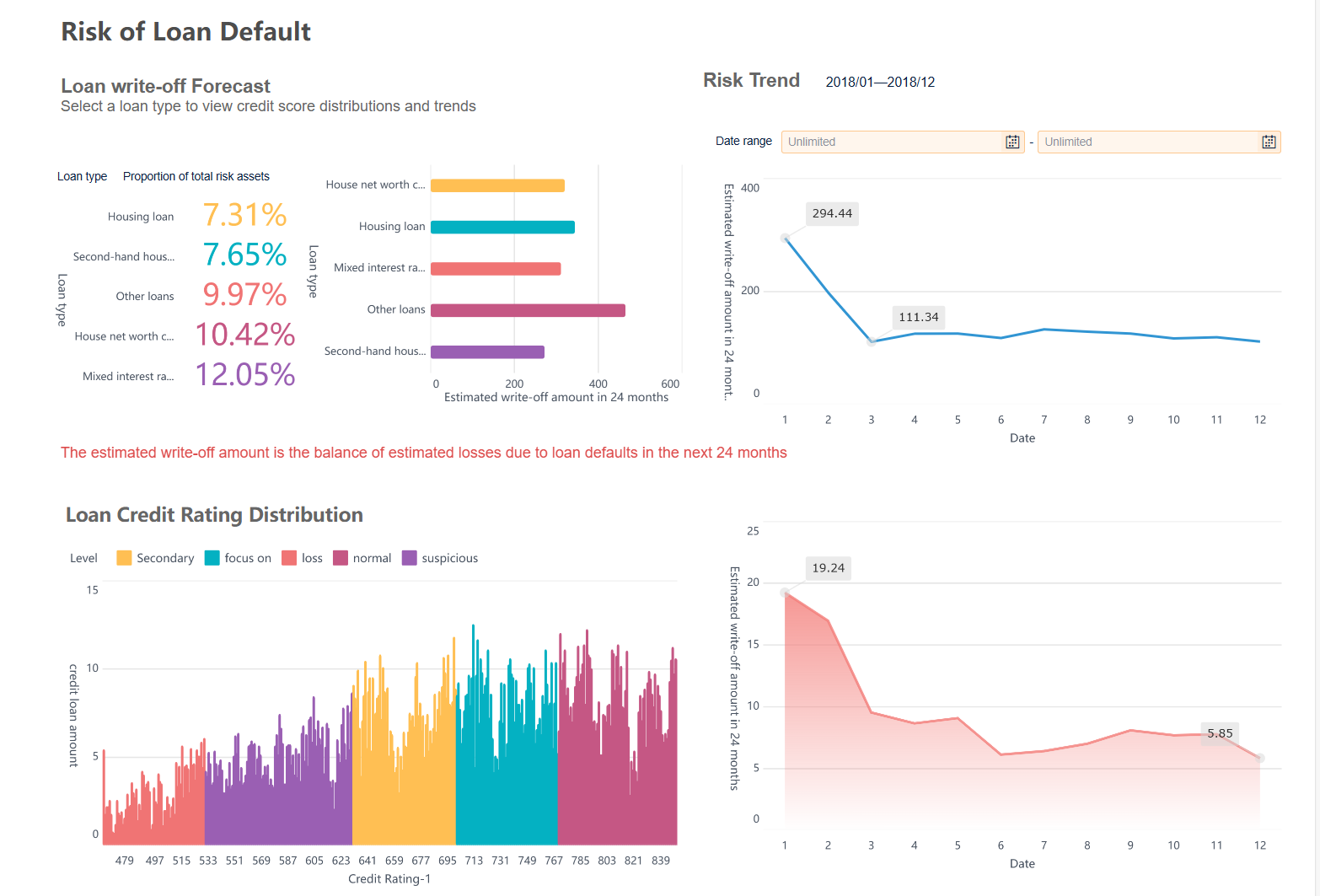
금융 분야에서 표준편차가 수익률 변동성을 나타내고 예상 손실액의 변동 폭을 통해 대출 리스크가 어느 정도 불안정한지 파악할 수 있게 해줍니다. 즉, 표준편차가 클수록 수익률의 위험이 크듯, 그래프에서 변동이 심할수록 대출 부실 위험도 크다는 의미입니다.
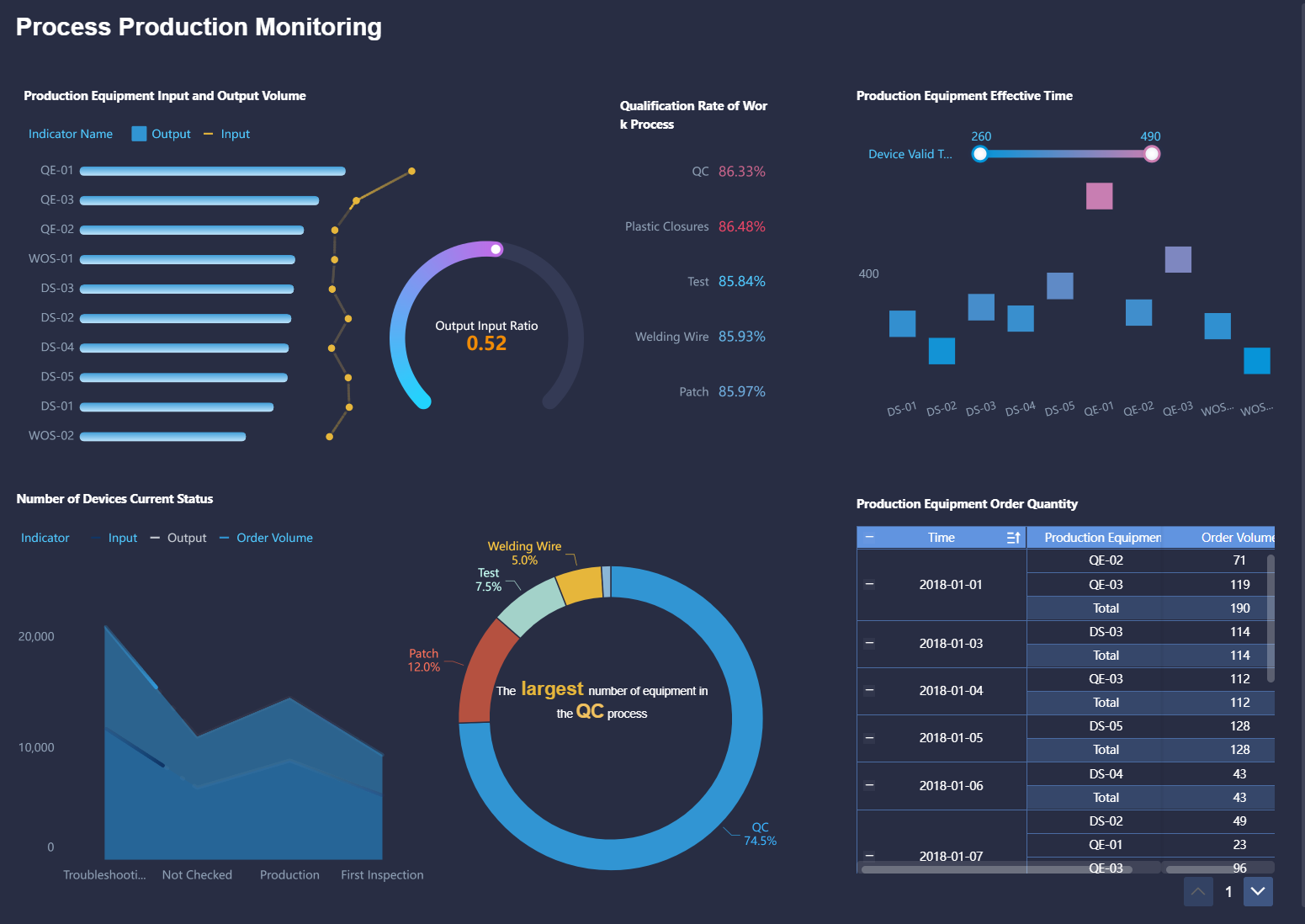
제조업에서는 품질관리에 표준편차가 중요합니다. 예를 들어, 생산된 제품의 무게나 크기를 측정해 표준편차를 계산하면 제품의 일관성을 평가할 수 있습니다. 표준편차가 작을수록 품질이 일정하게 유지된다는 의미합니다.
FanRuan-kr의 FineBI는 다양한 산업에서 표준편차를 활용해 데이터 기반 의사결정을 지원한다.
FineBI는 여러 데이터 소스를 통합하여 실시간으로 표준편차와 같은 통계 지표를 시각화한다.
예를 들어, 제조업체는 FineBI를 통해 생산 라인의 불량률 표준편차를 모니터링한다. 이를 통해 품질 이상 징후를 빠르게 파악하고, 즉각적인 개선 조치를 취할 수 있다.
금융 기업은 FineBI의 OLAP 분석 기능을 활용해 투자 포트폴리오의 수익률 표준편차를 분석한다. 이 과정에서 위험 분산 전략을 수립하고, 비즈니스 성과를 높인다.
데이터 분석에서는 표본과 모집단의 구분이 매우 중요합니다. 분석자가 모집단 전체의 데이터를 알고 있다면 모집단 표준편차 공식을 사용해야 합니다. 반면, 모집단 전체를 알지 못하고 일부 표본만 가지고 있다면 표본 표준편차 공식을 적용해야 합니다. 표본 크기가 30개 이상이면 두 표준편차 값이 거의 비슷해지지만, 모집단 정보를 모르는 경우에는 반드시 표본 표준편차를 사용해야 합니다.
또한, 표준편차 계산 시 데이터에 이상치가 포함되어 있으면 결과가 크게 달라질 수 있습니다. 이상치는 평균과 크게 벗어난 값으로, 표준편차를 과장하거나 왜곡할 수 있습니다. 분석자는 이상치를 무작정 제거하지 않고 데이터의 특성과 분석 목적에 따라 신중하게 처리해야 합니다.
표준편차 해석 오류는 실제 상황과 다른 판단을 초래할 수 있습니다. 예를 들어, 평균만 보고 복지 예산을 결정하면 용돈 격차를 무시하게 되고, 강의 평균 수심만 참고하면 깊은 곳의 위험을 간과할 수 있습니다.
| 사례 | 문제점 및 해석 오류 | 결과 및 위험 |
|---|---|---|
| 노인 용돈 조사 | 표준편차가 크다는 사실을 평균 신뢰성 문제로 오해 | 복지 예산 배분 오류 |
| 강의 평균 수심 | 분포의 흩어진 정도 무시 | 안전 위험 발생 |
| 통계적 추론 | 통계 기법 원리 미숙지 | 잘못된 판단 초래 |
표준편차와 표준오차는 서로 다른 개념입니다. 표준편차는 개별 데이터가 평균에서 얼마나 떨어져 있는지를 나타내며, 데이터의 산포 정도를 측정합니다. 반면, 표준오차는 표본평균이 모집단 평균을 얼마나 잘 추정하는지, 즉 표본평균의 변동성을 나타냅니다. 표준오차는 표준편차를 표본 크기의 제곱근으로 나누어 계산하며, 표본 크기가 커질수록 표준오차는 작아집니다.
분석자는 표준편차를 데이터 자체의 분포를 이해하는 데 사용하고, 표준오차는 통계적 추정의 정확도와 신뢰도를 평가하는 데 활용해야 합니다. 표준오차가 작을수록 추정치의 신뢰도가 높아집니다.
표준편차와 표준오차를 혼동하면 데이터 해석에 오류가 발생할 수 있으므로, 목적에 따라 올바른 지표를 선택하는 것이 중요합니다.
표준편차는 데이터가 평균을 기준으로 얼마나 퍼져 있는지 직관적으로 보여주는 지표입니다.
FineBI는 평균, 분산, 표준편차 등 핵심 통계 개념을 빠르게 시각화하여 기업의 데이터 기반 의사결정을 지원합니다.
실제로 당근마켓, 대형 쇼핑몰, 소셜 미디어 기업들은 표준편차를 활용해 이상치 제거, 고객 분석, 광고 타겟팅 등 다양한 비즈니스 성공 사례를 만들어내고 있습니다.

작성자
Seongbin
FanRuan에서 재직하는 고급 데이터 분석가
관련 기사

AI 툴 모음 비교: FineChatBI와 주요 경쟁사 분석으로 최적 선택 가이드
디지털 시대, 데이터는 새로운 석유입니다. 하지만 원유를 정제하지 않으면 가치가 없듯이, 데이터도 분석과 통찰로 전환되어야 비즈니스의 힘이 됩니다. 이를 위해 수많은 $1 도구가 쏟아져 나오고 있으며, 올바른 $1 속에서 자신의 필요에 딱 맞는 솔루션을 찾는 것은 쉽지 않은 과제입니다. 이 글은 대화형 $1의 선구자인 FineChatBI를 중심으로 주요 경쟁사들과의 객관적인 비교를 제공함으로
Seongbin
2026년 6월 04일

직장인 필수 AI 툴 고르기: 검색형 AI, 문서형 AI, BI형 AI의 차이와 추천 상황
AI가 업무에 깊숙이 들어오면서 많은 직장인이 비슷한 고민을 합니다. “어떤 $1 을 써야 정말 일이 빨라질까?” 문제는 AI 서비스가 많아질수록 선택이 더 어려워진다는 점입니다. 검색을 잘하는 도구, 글을 잘 써주는 도구, 데이터를 읽고 설명해주는 도구는 겉보기엔 비슷해 보여도 실제 업무에서의 역할은 전혀 다릅니다. 특히 직장인의 실무는 단순히 답을 얻는 데서 끝나지 않습니다. 자료를 찾고
Seongbin
2026년 5월 28일

생산성 향상이 안 되는 진짜 이유 7가지: 시간관리보다 먼저 점검할 핵심
$1 향상이라고 하면 많은 사람이 먼저 일정 관리, 할 일 목록, 캘린더 최적화 같은 방법을 떠올립니다. 물론 이런 도구들은 분명 도움이 됩니다. 하지만 현실에서는 시간관리 기술을 배워도 성과가 크게 달라지지 않는 경우가 많습니다. 바쁘게 일했는데 남는 결과는 적고, 하루를 꽉 채웠는데도 중요한 일은 제자리인 경험이 반복되기 때문입니다. 문제는 시간이 아니라 무엇에 시간을 쓰고 있는지 , 그
Seongbin
2026년 5월 17일



