

머신러닝과 딥러닝은 어떻게 다를까? 머신러닝 딥러닝의 가장 큰 차이는 딥러닝이 인공 신경망을 사용해 스스로 특징을 추출하는 반면, 머신러닝은 사람이 직접 주요 특징을 선정해야 한다는 점에 있다. FineChatBI 같은 최신 대화형 BI 솔루션은 이 두 기술을 결합해 더 정확하고 신뢰할 수 있는 분석 결과를 제공한다.

머신러닝은 인공지능의 한 분야다. 컴퓨터가 명시적으로 프로그래밍되지 않아도 데이터를 통해 스스로 학습하고 결정을 내릴 수 있도록 돕는 기술이다. 예를 들어, 아이가 고양이와 강아지를 구분하는 법을 배우듯, 컴퓨터도 수많은 사진을 보며 특징을 익힌다. 시간이 지날수록 컴퓨터는 더 정확하게 구분할 수 있다.
아래 표는 머신러닝의 정의와 주요 특징을 정리한 것이다.
딥러닝은 머신러닝의 한 종류다. 인간의 뇌 구조와 비슷한 인공 신경망을 여러 층으로 쌓아 복잡한 데이터를 학습한다. 딥러닝은 이미지, 음성, 자연어 등 다양한 비정형 데이터를 처리하는 데 강점을 가진다.
딥러닝은 사람이 직접 특징을 뽑지 않아도, 신경망이 스스로 중요한 특징을 찾아낸다. 이 덕분에 자율주행, 음성 인식, 얼굴 인식 등 다양한 분야에서 활발히 쓰이고 있다.
머신러닝 딥러닝은 인공지능이라는 큰 틀 안에서 서로 연결되어 있다.
인공지능 > 머신러닝 > 딥러닝
머신러닝이 인공지능의 하위 개념이라면, 딥러닝은 머신러닝의 한 갈래다.
아래 표는 두 기술의 구조와 특징을 비교한다.
머신러닝 딥러닝은 모두 데이터를 통해 학습하지만, 딥러닝은 더 많은 데이터와 복잡한 구조를 활용해 스스로 특징을 찾아낸다는 점에서 차별화된다.
머신러닝과 딥러닝은 신경망 구조에서 큰 차이를 보인다. 머신러닝의 대표적인 신경망은 단층 퍼셉트론이다. 이 구조는 입력층과 출력층 사이에 하나의 계층만 존재한다. 입력 특징 벡터와 가중치의 단순한 조합으로 결과를 예측한다.
딥러닝은 다층 퍼셉트론(MLP)과 합성곱 신경망(CNN) 등 여러 층을 쌓은 심층 신경망 구조를 사용한다. MLP는 은닉층을 포함해 여러 층으로 구성되어 복잡한 패턴을 학습한다. CNN은 합성곱 계층과 풀링 계층을 반복적으로 쌓아 이미지와 같은 비정형 데이터에서 뛰어난 성능을 보인다.
이처럼 머신러닝 딥러닝은 신경망의 깊이와 복잡성에서 뚜렷한 차이를 가진다.
참고: 다양한 인공신경망 구조는 Neural Network Zoo(Asimov Institute)에서 시각적으로 확인할 수 있다. 딥러닝의 기본 구조인 Deep Feedforward Network는 입력층, 2개 이상의 은닉층, 출력층으로 구성된다.
머신러닝 딥러닝의 또 다른 핵심 차이는 특징 추출 방식이다. 머신러닝은 사람이 직접 데이터의 특징을 설계하고 추출한다. 예를 들어, 고객 이탈 예측에서는 도메인 전문가가 나이, 구매 이력, 접속 빈도 등 중요한 특징을 선정한다.
딥러닝은 인공신경망의 다층 구조를 통해 데이터에서 중요한 특징을 자동으로 학습한다. CNN의 경우, 첫 번째 은닉층은 이미지의 가장자리나 선분 같은 저수준 특징을 학습한다. 중간 층은 모양이나 질감 같은 중간 수준 특징을, 마지막 층은 고양이 얼굴과 같은 고수준 개념을 인식한다.
아래 표는 두 기술의 특징 추출 방식을 비교한다.
딥러닝은 원시 데이터에서 자동으로 특징을 추출한다. 예를 들어, 고양이 인식에서는 귀, 눈, 수염 같은 특징을 일일이 지정하지 않아도 수천 장의 사진을 통해 스스로 고양이를 인식하는 방법을 학습한다.
FineChatBI는 이러한 딥러닝의 자동 특징 추출 능력과 머신러닝의 해석 가능성을 결합한다. FineChatBI는 Text2DSL 기술을 활용해 자연어를 데이터 표준 쿼리 구조로 변환한다. 또한, 규칙 기반 모델과 대규모 모델을 함께 사용해 신뢰성과 성능을 모두 높인다.
머신러닝 딥러닝은 데이터 요구량과 하드웨어 필요성에서도 차이를 보인다. 머신러닝은 비교적 적은 데이터로도 빠르게 학습할 수 있다. 일반 CPU 환경에서도 충분히 동작한다.
딥러닝은 복잡한 신경망 구조와 대량의 행렬 연산을 수행한다. 이 때문에 GPU와 같은 고성능 하드웨어가 필요하다. 많은 데이터를 사용해 모델을 학습하며, 연산량이 많아 학습 시간이 길다.
아래 표는 데이터와 하드웨어 요구사항을 정리한 것이다.
FineChatBI는 여러 모델을 결합해 복잡한 자연어 처리와 데이터 분석을 동시에 수행한다. Text2DSL 기술과 규칙 기반 모델, 대규모 모델의 조합은 다양한 데이터 환경과 하드웨어 조건에서도 높은 신뢰성과 성능을 보장한다.

머신러닝과 딥러닝은 다양한 분야에서 활발하게 활용되고 있다. 스마트폰의 얼굴 인식 기능은 이미지 분석 기술을 기반으로 한다. 의료 영상 분석에서는 암 진단과 같은 복잡한 문제를 해결한다. 음성 인식 분야에서는 Siri, Alexa와 같은 음성 비서가 대표적이다. 추천 시스템은 사용자의 행동 데이터를 분석해 맞춤형 콘텐츠를 제공한다. 자율주행 자동차는 도로의 차량, 보행자, 신호등을 인식하고 안전한 경로를 계획한다. 아래 표는 머신러닝과 딥러닝의 대표적 활용 사례를 정리한 것이다.
머신러닝 딥러닝은 이메일 분류, 예측 분석, 이미지 인식, 자연어 처리, 게임 등 다양한 분야에서 혁신을 이끌고 있다.
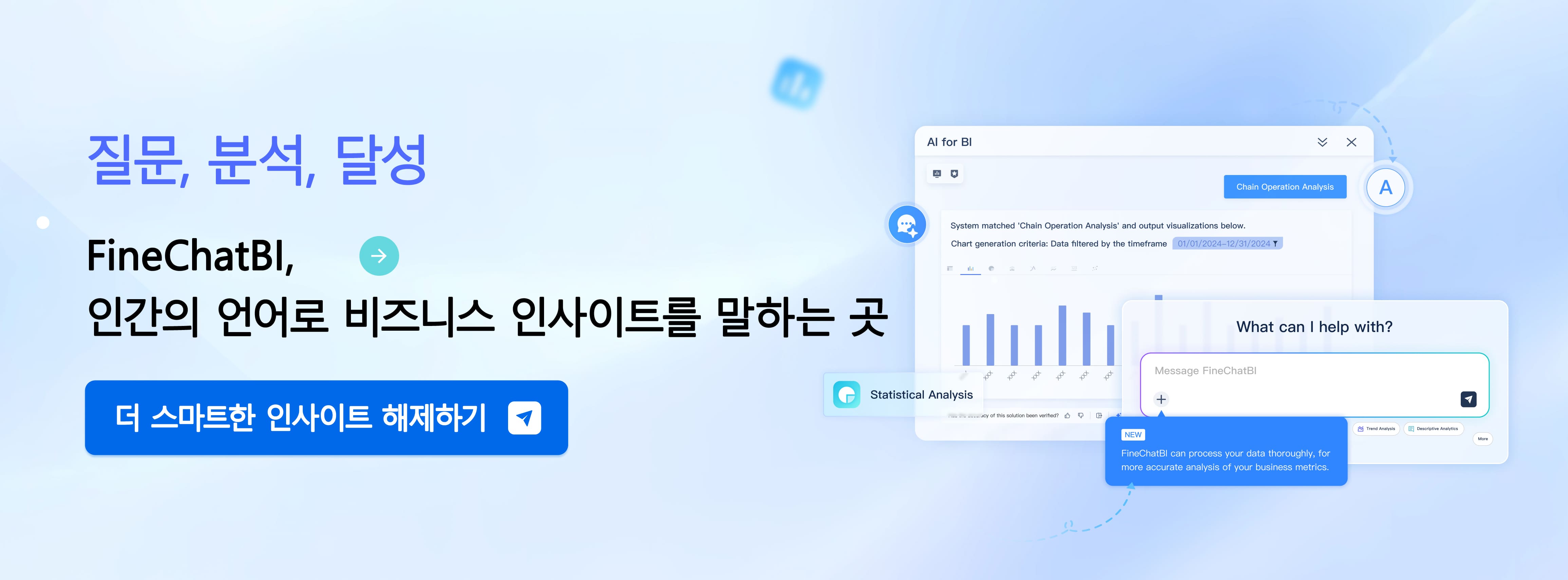
FineChatBI는 대화형 BI 환경에서 머신러닝과 딥러닝 기술을 효과적으로 결합한다. 사용자는 복잡한 데이터 분석 지식 없이도 자연어로 질문을 입력한다. FineChatBI는 Text2DSL 기술을 활용해 사용자의 질문을 데이터 표준 쿼리 구조로 변환한다. 여러 모델을 결합해 사용자의 의도를 정확하게 해석하고, 신뢰할 수 있는 분석 결과를 제공한다.
다중 턴 대화와 문맥 이해 기능은 사용자가 연속적으로 질문할 때도 정확한 답변을 지원한다. FineChatBI는 시각화 및 대시보드 생성 기능을 통해 분석 결과를 직관적으로 보여준다.
아래 표는 FineChatBI에서 머신러닝과 딥러닝 기술이 적용된 구체적 사례를 정리한 것이다.
FineChatBI는 최신 데이터와 강력한 분석 엔진을 바탕으로, 사용자가 올바른 비즈니스 질문을 제기하면 실시간 인사이트를 제공한다. 대화형 분석과 시각화 기능은 기업의 데이터 활용을 한 단계 높인다.
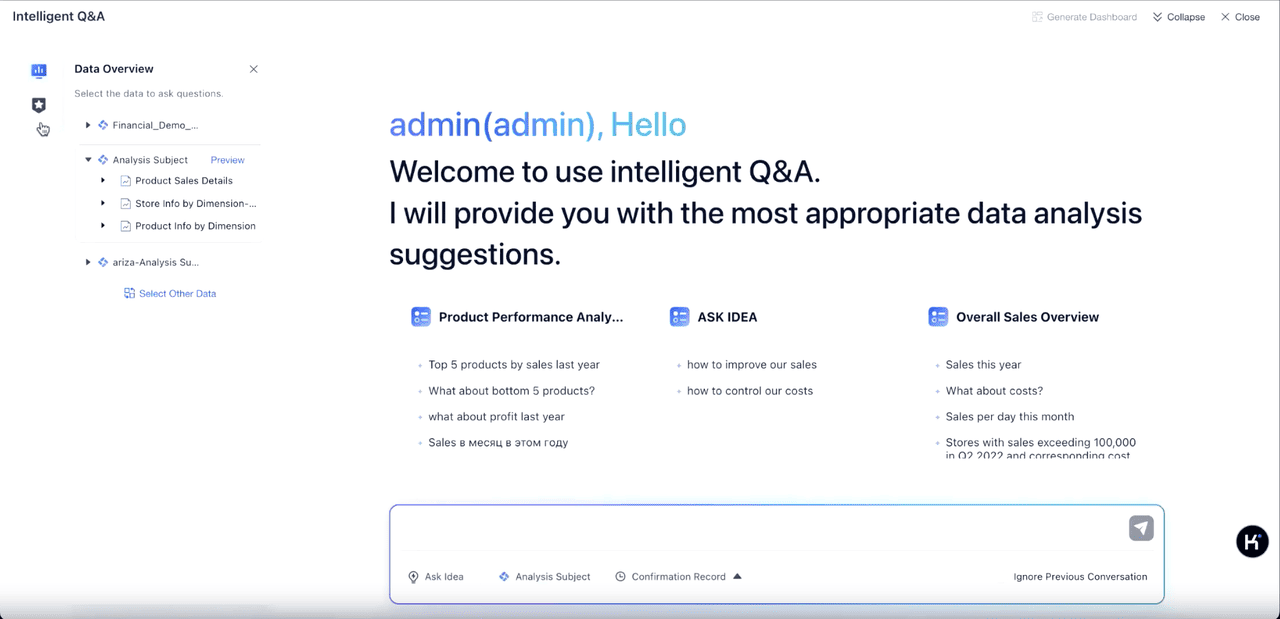
머신러닝과 딥러닝 중 어떤 기술을 선택해야 할지 고민하는 경우가 많다. 실제로 데이터의 크기, 형태, 문제의 복잡성, 그리고 사용할 수 있는 자원에 따라 선택 기준이 달라진다. 아래 표는 주요 선택 기준을 정리한 것이다.
예를 들어, 고객 이탈 예측이나 문서 분류처럼 수치나 범주형 데이터가 중심이 되는 문제에는 머신러닝이 적합하다. 반면, 얼굴 인식이나 자연어 처리처럼 이미지나 텍스트 등 복잡한 데이터를 다루는 경우에는 딥러닝이 더 좋은 성능을 보인다.
머신러닝 딥러닝의 선택은 데이터와 문제의 특성, 그리고 사용 가능한 리소스에 따라 달라진다.
머신러닝 딥러닝 기술은 앞으로도 빠르게 발전할 전망이다. IDC의 보고서에 따르면, 2024년 생성형 AI 시장 규모는 약 401억 달러에 이를 것으로 예상된다. 2027년에는 1,511억 달러까지 성장할 것으로 보인다.
FineChatBI와 같은 최신 BI 솔루션은 이러한 기술 발전을 적극적으로 반영하고 있다.
이처럼 BI 솔루션은 머신러닝 딥러닝의 발전과 함께 더욱 똑똑해지고 있다. 앞으로 기업들은 더 쉽고 빠르게 데이터를 분석하고, 실시간으로 인사이트를 얻을 수 있을 것이다.
딥러닝은 머신러닝의 하위 집합으로, 심층 신경망을 사용해 인간 두뇌의 복잡한 의사결정 능력을 모방한다. 데이터가 적고 문제 구조가 단순하면 머신러닝이 적합하다. 이미지, 음성, 자연어처럼 복잡한 데이터를 다룰 때는 딥러닝이 효과적이다.
앞으로 AI 기술은 초거대 생성형 AI, Transformer, GAN, AutoML, 설명 가능한 AI 등 다양한 분야에서 혁신을 이끌 전망이다. 아래 표는 주요 발전 기술과 기대 효과를 정리한다.
FanRuan
https://www.fanruan.com/ko-kr/blogFanRuan은 FineReport의 유연한 리포팅, FineBI의 셀프서비스 분석, FineDataLink의 데이터 통합 기능을 바탕으로 전 산업 분야에 걸쳐 강력한 BI 솔루션을 제공합니다. FanRuan의 올인원 플랫폼은 조직이 원시 데이터를 실행 가능한 인사이트로 전환하여 비즈니스 성장을 실현할 수 있도록 강력하게 지원합니다.
머신러닝은 사람이 직접 특징을 뽑아야 합니다. 딥러닝은 인공 신경망이 스스로 특징을 찾아냅니다. 딥러닝은 복잡한 데이터에 더 강합니다.
FineChatBI는 Text2DSL 기술을 사용합니다. 규칙 기반 모델과 대규모 모델을 결합해 자연어를 데이터 쿼리로 바꿉니다. 이 과정에서 머신러닝과 딥러닝 기술을 모두 활용합니다.
딥러닝은 많은 데이터와 강력한 하드웨어가 필요합니다. 데이터가 적거나 단순한 문제에는 머신러닝이 더 효율적입니다. 상황에 따라 적합한 기술을 선택해야 합니다.
FineChatBI는 여러 모델을 결합합니다. Text2DSL 기술로 자연어를 표준 쿼리로 변환합니다. 이 과정에서 규칙 기반 모델이 결과의 신뢰성을 높입니다.
기본적인 수학과 프로그래밍 지식이 필요합니다. 파이썬 같은 언어를 익히면 도움이 됩니다. 데이터 분석과 인공 신경망의 원리를 이해하면 학습이 쉬워집니다.






