

관계형 데이터베이스는 정보를 표 형태로 저장하고, 서로 연결된 데이터를 효율적으로 관리할 수 있는 시스템입니다.
당신이 학교에서 사용하는 성적표처럼, 각각의 과목과 점수를 표로 정리해 두면 원하는 정보를 빠르게 찾을 수 있습니다.
FanRuan의 FineReport와 FineBI는 이런 데이터베이스를 활용해 복잡한 데이터를 시각적으로 보여주고, 분석할 수 있게 도와줍니다.
여러분은 정보를 정리할 때 표를 자주 사용하나요? 예를 들어, 학교에서 친구들의 이름과 전화번호를 정리할 때 표를 만들면 한눈에 정보를 볼 수 있습니다. 관계형 데이터베이스도 이와 비슷합니다. 정보를 표(테이블) 형태로 저장하고, 각 칸에 데이터를 차곡차곡 쌓아 나갑니다.
이 방식은 데이터를 빠르게 찾고, 정렬하고, 원하는 정보를 쉽게 꺼낼 수 있게 도와줍니다.
E. F. Codd의 1970년 논문 'A Relational Model of Data for Large Shared Data Banks'에서는 관계형 데이터베이스를 수학적 모델로 정의하며, 도메인과 속성, 정규화 개념을 다룹니다. 이 논문은 관계형 데이터베이스의 개념적 기초를 제공하는 공식적인 자료입니다.
관계형 데이터베이스는 여러분이 사용하는 엑셀 시트와 매우 비슷합니다. 각 행은 한 사람의 정보, 각 열은 이름, 전화번호, 주소처럼 정보를 구분합니다.
이렇게 표로 데이터를 관리하면, 수백 명의 정보를 한 번에 정리하고, 필요한 데이터를 빠르게 찾을 수 있습니다.
아래 표는 관계형 데이터베이스의 핵심 개념을 쉽게 정리한 것입니다.
여러분은 데이터베이스라는 단어를 들으면, 단순히 정보를 저장하는 공간이라고 생각할 수 있습니다. 하지만 관계형 데이터베이스는 단순 저장소와 다릅니다.
일반 데이터베이스는 정보를 아무 구조 없이 쌓아둘 수 있습니다. 반면, 관계형 데이터베이스는 정보를 표로 정리하고, 각 표 사이의 관계를 명확하게 설정합니다.
예를 들어, 도서관에서 책 정보를 관리한다고 생각해 보세요.
관계형 데이터베이스는 데이터를 표로 정리하고, 표와 표 사이의 연결고리를 만들어줍니다.
여러분은 이 구조 덕분에 데이터를 더 안전하게 관리하고, 원하는 정보를 빠르게 찾을 수 있습니다.
관계형 데이터베이스에서 정보를 저장할 때, 표를 사용합니다. 이 표를 테이블이라고 부릅니다.
테이블은 여러 행과 열로 이루어져 있습니다. 각 행은 하나의 개체, 예를 들어 한 명의 학생이나 한 권의 책을 나타냅니다.
열은 개체의 속성을 의미합니다. 학생 테이블이라면 이름, 학년, 전화번호가 각각 열이 됩니다.
각 셀에는 하나의 값만 들어갑니다.
행과 열의 순서는 중요하지 않습니다.
아래는 테이블 구조를 쉽게 보여주는 예시입니다.
테이블은 릴레이션이라고도 부르며, 행은 튜플, 열은 속성이라고 합니다.
각 행은 서로 달라야 하며, 열마다 고유한 이름이 있습니다.
테이블에는 여러 행이 있습니다.
각 행을 구별하려면 특별한 값이 필요합니다.
이때 사용하는 것이 키입니다.
기본키는 테이블에서 각 행을 유일하게 식별하는 열입니다.
학생 테이블에서는 학생ID가 기본키가 될 수 있습니다.
기본키는 중복될 수 없고, 반드시 값이 있어야 합니다.
기본키가 없으면, 여러 행이 같은 정보를 가질 수 있어 데이터 관리가 어려워집니다.
외래키는 다른 테이블의 기본키를 참조하는 열입니다.
예를 들어, 성적 테이블에서 학생ID가 외래키가 되어 학생 테이블의 기본키와 연결됩니다.
외래키 덕분에 여러 테이블의 정보를 쉽게 연결할 수 있습니다.
스키마는 테이블의 구조와 규칙을 정의합니다.
스키마에는 테이블 이름, 열 이름, 데이터 타입, 키 정보 등이 포함됩니다.
관계형 데이터베이스에서는 데이터를 저장할 때 반드시 스키마를 따라야 합니다.
이렇게 하면 데이터의 무결성과 일관성을 유지할 수 있습니다.
스키마를 변경하려면 ALTER TABLE 같은 명령어를 사용합니다.
스키마는 복잡한 관계를 지원하고, 데이터 처리와 질의 성능에도 영향을 줍니다.
관계형 데이터베이스는 엄격한 스키마 덕분에 데이터 구조가 명확하고 안정적입니다.
데이터 무결성은 데이터가 정확하고 일관되며, 유효하게 유지되는 것을 의미합니다.
관계형 데이터베이스를 사용하면 데이터가 잘못 입력되거나, 중복되거나, 연결이 끊어지는 일을 막을 수 있습니다.
당신은 아래와 같은 방법으로 데이터 무결성을 지킬 수 있습니다.
관계형 데이터베이스에서는 테이블 생성 시 제약조건을 설정합니다. 조건에 맞지 않는 데이터는 입력되지 않습니다. 관계를 연결하는 데이터가 삭제되는 것도 막을 수 있습니다. 데이터베이스 관리 시스템(DBMS)은 데이터 회복과 복구 기능도 제공합니다.
관계형 데이터베이스는 ACID 원칙을 따릅니다. ACID는 네 가지 핵심 특성으로 구성됩니다.
이 원칙 덕분에 당신은 데이터가 항상 안전하고 신뢰할 수 있음을 보장받습니다.
원자성은 트랜잭션의 모든 작업이 모두 성공하거나 모두 실패하도록 보장합니다.
당신이 은행에서 송금할 때, 돈이 빠져나가고 들어오는 작업이 동시에 이루어져야 합니다. 하나라도 실패하면 전체 작업이 취소됩니다.
일관성은 트랜잭션이 끝난 후 데이터베이스가 항상 규칙을 지키는 상태를 유지하도록 합니다.
당신이 규칙에 맞지 않는 데이터를 입력하려고 하면, 데이터베이스는 이를 막아줍니다.
고립성은 여러 사용자가 동시에 데이터를 수정해도 서로 영향을 주지 않도록 합니다.
당신이 친구와 동시에 같은 데이터를 수정해도, 데이터가 꼬이지 않습니다.
지속성은 트랜잭션이 성공적으로 끝나면 그 결과가 시스템 장애가 발생해도 영구적으로 저장됩니다.
당신은 갑작스러운 정전이나 시스템 오류에도 데이터가 안전하게 보존된다는 점에서 안심할 수 있습니다.
ACID 원칙은 금융 거래처럼 민감한 데이터 처리 환경에서 필수적입니다. 데이터의 안정성과 신뢰성을 확보하는 데 중요한 역할을 합니다.
관계형 데이터베이스는 구조가 명확하지만, 필요에 따라 쉽게 확장하거나 변경할 수 있습니다.
당신은 새로운 테이블을 추가하거나, 기존 테이블의 구조를 바꿀 수 있습니다.
스키마를 수정하면 데이터베이스가 새로운 요구에 맞게 빠르게 적응합니다.
이런 유연성 덕분에 다양한 비즈니스 환경에서 관계형 데이터베이스를 활용할 수 있습니다.
관계형 데이터베이스는 데이터 구조가 바뀌어도 안정적으로 데이터를 관리할 수 있습니다. 변화하는 요구에 맞춰 쉽게 확장할 수 있습니다.

여러분은 데이터베이스를 선택할 때 MySQL과 Oracle을 자주 접하게 됩니다.
Oracle은 대기업과 은행처럼 대규모 시스템에서 많이 사용합니다. MySQL은 중소기업이나 웹 애플리케이션에서 인기가 높습니다.
최근 6년간 글로벌 DBMS 시장에서는 Oracle 중심의 상용 제품 점유율이 줄어들고 있습니다. 2021년에는 상용 DBMS 5개 기업이 86.9%의 점유율을 차지했지만, 2024년에는 80.6%로 감소했습니다.
오픈소스 DBMS인 MySQL과 PostgreSQL의 선호도가 높아지고 있습니다. 개발자들은 비용 절감과 빠른 배포, 자유로운 커스터마이징 때문에 오픈소스를 선택합니다.
Oracle은 다양한 운영체제를 지원하고 대량 데이터를 빠르게 처리합니다. MySQL은 무료로 사용할 수 있고, 속도가 빠르며 확장성이 뛰어납니다.
아래 표는 두 제품의 특징을 비교한 것입니다.
MySQL Community Edition은 무료로 사용할 수 있습니다. 기본적인 보안과 백업 기능을 제공합니다.
MySQL Enterprise Edition은 Oracle이 소유하며, 고급 보안, 고가용성, 확장성, 성능 모니터링 등 다양한 기능을 추가했습니다.
Oracle DBMS는 데이터 암호화, 방화벽, 감사, 마스킹 등 기업용 보안 기능을 강화해 대규모 조직의 요구를 충족합니다.

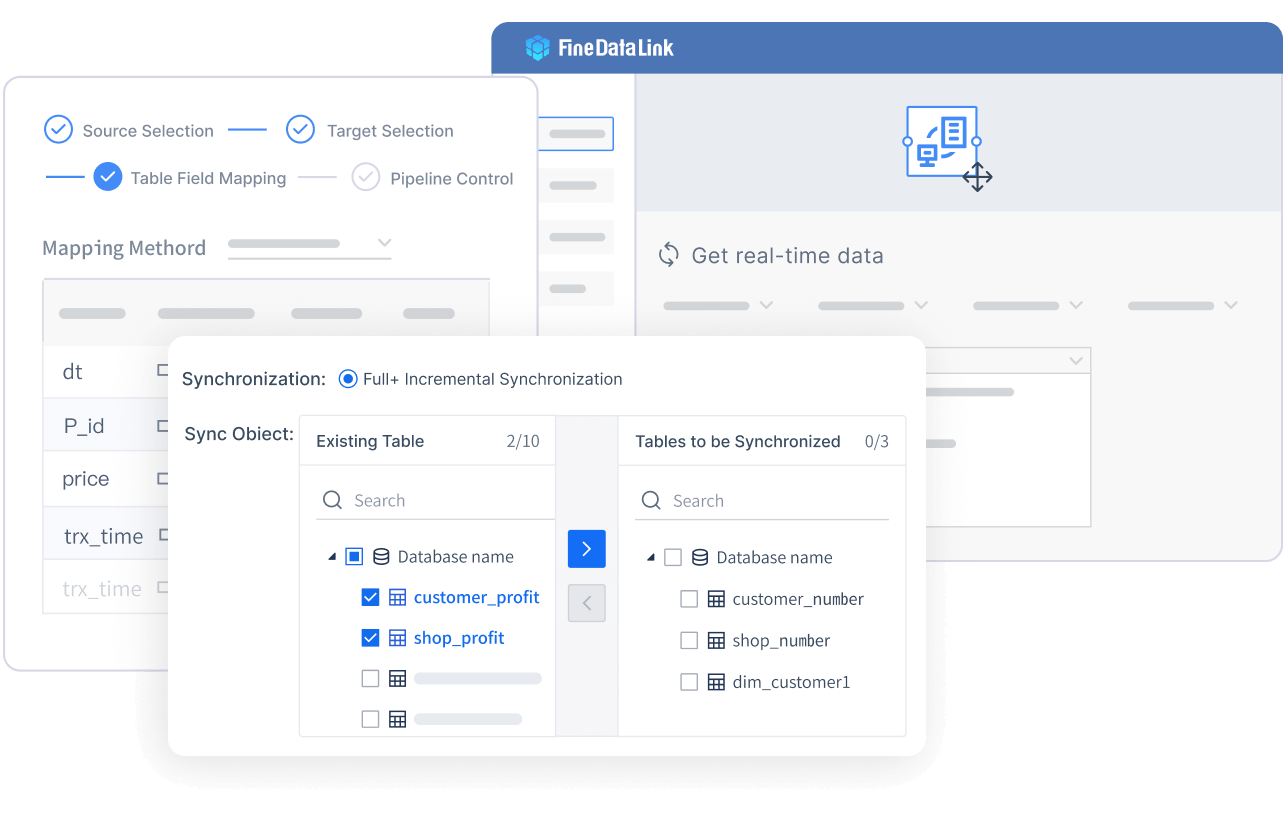
여러분은 여러 데이터 소스와 시스템의 정보를 한 곳에 모으고 싶을 때 FineDataLink를 활용할 수 있습니다.
FineDataLink는 데이터 통합 플랫폼으로, 다음과 같은 주요 기능을 제공합니다.
FineDataLink는 100개 이상의 데이터 소스를 지원합니다. 시각적이고 현대적인 인터페이스 덕분에 누구나 쉽게 사용할 수 있습니다.
실제 활용 예시를 들어볼까요?
여러분이 기업에서 데이터 웨어하우스를 구축한다고 가정해봅시다.
FineDataLink를 사용하면, 다양한 관계형 데이터베이스(MySQL, Oracle 등)에서 데이터를 실시간으로 모으고, 자동으로 변환하여 분석에 적합한 형태로 저장할 수 있습니다.
실시간 동기화 기능을 통해, 여러 시스템의 최신 정보를 한 번에 확인할 수 있습니다.
API 기능을 활용하면, SaaS 애플리케이션이나 클라우드 환경에서도 데이터를 자유롭게 주고받을 수 있습니다.
아래와 같은 상황에서 FineDataLink가 큰 도움이 됩니다.
FineDataLink는 복잡한 데이터 통합 과정을 간소화하고, 데이터 품질과 분석 효율을 높여줍니다.
여러분은 데이터 관리와 분석 업무를 훨씬 쉽게 처리할 수 있습니다.
관계형 데이터베이스를 사용하면 정보를 체계적으로 관리할 수 있습니다.
당신은 데이터를 표로 정리해서 빠르게 찾을 수 있습니다.
데이터의 정확성과 일관성을 쉽게 유지할 수 있습니다.
여러 사람이 동시에 데이터를 수정해도 안전하게 관리할 수 있습니다.
데이터를 추가하거나 수정할 때 실수로 잘못된 값을 넣는 일이 줄어듭니다.
트랜잭션 기능 덕분에 중요한 작업을 한 번에 처리할 수 있습니다.
실패하면 모든 작업을 취소할 수 있어서 데이터가 꼬이지 않습니다.
팁: 관계형 데이터베이스는 은행, 학교, 병원처럼 많은 정보를 다루는 곳에서 널리 사용됩니다.
당신은 데이터가 많아져도 쉽게 확장할 수 있습니다.
아래 표는 주요 장점을 정리한 것입니다.
관계형 데이터베이스에도 단점이 있습니다.
당신은 데이터 구조를 미리 정해야 합니다.
새로운 종류의 데이터를 추가하려면 테이블 구조를 바꿔야 합니다.
복잡한 데이터를 저장할 때 제약이 생길 수 있습니다.
대량의 데이터를 처리할 때 성능이 떨어질 수 있습니다.
관계가 복잡해지면 관리가 어려워집니다.
주의: 데이터베이스를 설계할 때 구조를 잘못 정하면 나중에 수정하기 어렵습니다.
당신은 데이터가 자주 바뀌는 환경에서는 다른 방식도 고려해야 합니다.
아래 리스트는 한계를 쉽게 보여줍니다.
당신이 데이터를 저장할 때 어떤 구조를 사용하는지에 따라 데이터베이스의 종류가 달라집니다.
관계형 데이터베이스는 행과 열로 이루어진 2차원 테이블 구조를 사용합니다. 데이터를 저장하기 전에 미리 스키마(구조)를 정해야 합니다.
반면, 비관계형 데이터베이스는 문서, 키-값, 컬럼, 그래프 등 다양한 형태로 데이터를 저장합니다.
비관계형 데이터베이스는 동적 스키마를 지원합니다. 새로운 데이터 구조가 필요할 때 자유롭게 추가하거나 변경할 수 있습니다.
이런 유연성 덕분에 비정형 데이터나 빠르게 변하는 데이터를 저장할 때 유리합니다.
예를 들어, SNS에서 올라오는 다양한 형태의 게시글, 이미지, 댓글 데이터를 저장할 때 비관계형 데이터베이스가 많이 쓰입니다.
관계형과 비관계형 데이터베이스는 각각 강점과 약점이 다릅니다.
아래 표를 보면 두 방식의 차이를 한눈에 알 수 있습니다.
관계형 데이터베이스 (RDBMS)
장점:
단점:
주 용도
비관계형 데이터베이스 (NoSQL)
장점:
단점:
주 용도:
비정형 데이터, 확장성과 성능 중요
비관계형 데이터베이스는 MongoDB처럼 BASE 트랜잭션 방식을 사용합니다.
이 방식은 가용성과 확장성을 높이지만, 데이터 일관성은 느슨하게 유지합니다.
CAP 이론에 따르면, 비관계형 데이터베이스는 가용성과 분할 허용성을 우선시합니다.
관계형 데이터베이스는 ACID 원칙을 지켜 데이터의 신뢰성과 무결성을 보장합니다.
당신이 데이터베이스를 선택할 때는 데이터의 성격과 목적을 먼저 생각해야 합니다.
아래 표를 참고하면 어떤 상황에 어떤 데이터베이스가 적합한지 쉽게 알 수 있습니다.
만약 당신이 은행, 병원, 학교처럼 데이터의 정확성과 일관성이 중요한 환경에서 일한다면 관계형 데이터베이스가 더 적합합니다.
반대로, 소셜 미디어, 로그 데이터, IoT처럼 데이터 구조가 자주 바뀌거나 대용량 데이터를 빠르게 처리해야 한다면 비관계형 데이터베이스를 고려하세요.
관계형 데이터베이스는 특정 환경에서 특히 강점을 보입니다.
아래와 같은 상황에서 사용하면 높은 효율을 기대할 수 있습니다.
데이터 구조가 명확하고, 데이터 간의 관계가 중요한 업무라면 관계형 데이터베이스가 가장 적합합니다.
새로운 데이터베이스 시스템을 도입할 때는 몇 가지 중요한 점을 먼저 생각해야 합니다.
당신은 아래 항목을 체크리스트로 활용할 수 있습니다.
도입 전에 실제 업무에 맞는 데이터베이스 구조를 설계하고, 필요한 기능과 예산을 꼼꼼히 따져보는 것이 중요합니다.
처음 데이터베이스를 배우거나 도입하려면, 다음과 같은 방법으로 시작하면 좋습니다.
처음에는 어렵게 느껴질 수 있지만, 기본부터 차근차근 연습하면 데이터 분석과 관리가 점점 쉬워집니다.
실습 프로젝트를 통해 직접 데이터를 다뤄보면 자신감도 함께 자랍니다. 😊
관계형 데이터베이스는 정보를 표로 정리하고, 안전하게 관리할 수 있는 시스템이다.
당신은 데이터 구조가 명확하고, 여러 테이블의 관계가 중요한 환경에서 이 방식을 선택하면 좋다.
실무에서는 데이터베이스 연결 설정이나 Dialect 지정 오류가 자주 발생한다. 아래 표를 참고하면 실수를 줄일 수 있다.
데이터 통합이 필요할 때 FineDataLink를 활용하면 여러 소스의 데이터를 빠르게 모으고, 실시간으로 동기화할 수 있다.
초보자라면 아래 책을 참고하면 쉽게 배울 수 있다.
데이터베이스를 처음 시작할 때 실수해도 괜찮다. 차근차근 연습하면 누구나 전문가가 될 수 있다. 😊
FanRuan
https://www.fanruan.com/ko-kr/blogFanRuan은 FineReport의 유연한 리포팅, FineBI의 셀프서비스 분석, FineDataLink의 데이터 통합 기능을 바탕으로 전 산업 분야에 걸쳐 강력한 BI 솔루션을 제공합니다. FanRuan의 올인원 플랫폼은 조직이 원시 데이터를 실행 가능한 인사이트로 전환하여 비즈니스 성장을 실현할 수 있도록 강력하게 지원합니다.
관계형 데이터베이스는 정보를 표(테이블)로 저장하고, 여러 표의 데이터를 서로 연결해서 관리하는 시스템이에요.
당신은 학생 명단, 성적표처럼 정보를 쉽게 찾고 정리할 수 있어요.
관계형 데이터베이스는 표 구조를 사용해요. 비관계형 데이터베이스는 문서, 키-값, 그래프 등 다양한 형태로 데이터를 저장해요.
당신이 정형 데이터를 다룰 때는 관계형, 비정형 데이터에는 비관계형이 더 적합해요.
키는 각 행을 구별하는 역할을 해요.
기본키는 중복 없이 한 행을 정확히 찾게 도와줘요.
외래키는 다른 표와 연결해 정보를 쉽게 합칠 수 있게 해줘요.
여러 데이터 소스를 한 곳에 모으고 싶을 때, 실시간 데이터 동기화가 필요할 때 FineDataLink를 사용하세요.
당신은 복잡한 데이터 통합 작업을 빠르고 쉽게 처리할 수 있어요.
SQL 언어를 먼저 익히세요.
MySQL 같은 쉬운 데이터베이스로 연습하세요.
기본 명령어와 테이블 구조를 직접 만들어보면 이해가 빨라져요.
데이터 무결성은 데이터가 정확하고 일관되게 유지되는 것을 말해요.
당신은 잘못된 데이터 입력이나 중복을 막을 수 있어요.
정확한 정보 관리에 꼭 필요해요.
네, FineDataLink는 코딩 없이 5분 만에 API를 만들 수 있어요.
당신은 다양한 시스템과 데이터를 쉽게 연결할 수 있어요.






