在當今的數位化時代,資料已成為企業最寶貴的資產之一。隨著大數據、雲端計算和人工智慧等技術的興起,企業對於資料的儲存、處理和分析需求日益增長。資料湖泊作為應對這些需求的創新解決方案,已經成為企業資料管理戰略的核心組成部分。
資料湖泊是一個集中化的儲存庫,它能夠以原始格式儲存海量的結構化、半結構化和非結構化資料。與傳統的資料倉庫相比,資料湖泊提供了更高的靈活性和擴充套件性,允許企業在不進行預先定義資料模型的情況下,儲存和處理各種型別的資料。這種設計不僅降低了資料預處理的成本,而且提高了資料的可訪問性和可分析性,為企業的資料驅動決策提供了強有力的支援。
本文將深入探討資料湖泊的概念、關鍵技術以及應用場景,並介紹幾種常見的資料湖泊解決方案。透過本文的介紹,讀者將全面瞭解資料湖泊如何幫助企業解鎖資料的潛力,推動業務的創新和發展。
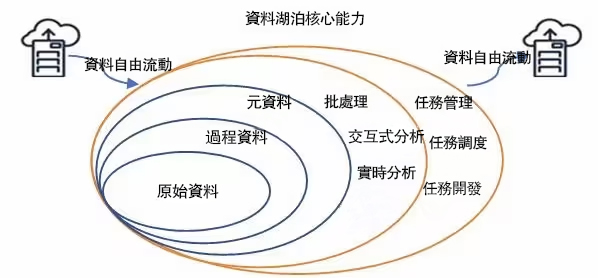
一、資料湖泊概念
根據AWS關於資料湖泊的定義,資料湖泊可以認為是”一個集中式儲存庫,允許您以任意規模儲存所有結構化和非結構化資料。您可以按原樣儲存資料(無需先對資料進行結構化處理),並執行不同型別的分析 – 從控制面板和視覺化到大數據處理、實時分析和機器學習,以指導做出更好的決策。“
資料湖泊的目的在於提供一個靈活的環境,允許企業和組織儲存大量資料,並在需要時進行分析和處理,從而支援更深入的資料探索和業務決策。資料湖泊主要有以下特點:
1、多樣化資料儲存
資料湖泊設計之初就考慮到了儲存多種資料格式的需求。它們能夠容納從簡單文字到複雜二進位制檔案的所有內容。這種設計允許企業捕獲和利用傳統資料倉庫可能無法處理的資料型別,如社交媒體資料、感測器資料、交易日誌等。
2、原始資料保持
資料湖泊中的資料保持其原始狀態,這意味著資料在沒有經過任何清洗、轉換或聚合的情況下被儲存。這種方式保留了資料的完整性,使得資料科學家能夠從最全面的資料集進行分析,從而獲得更深入的洞察。
3、集中式儲存庫
資料湖泊提供了一個統一的儲存位置,可以集中儲存來自企業各個部門和系統的資料。這種集中化有助於打破資料孤島,促進跨部門的資料共享和協作,同時也簡化了資料安全和合規性管理。
4、靈活性和可擴充套件性
資料湖泊通常建立在開源技術或雲服務之上,這些技術能夠靈活地擴充套件以適應資料量的增長。例如,雲端資料湖泊解決方案可以自動擴充套件儲存容量,無需人工干預。
5、資料可追溯性
資料湖泊記錄了資料的完整歷史,包括資料的來源、如何被處理以及如何被使用。這種可追溯性對於理解資料的上下文、審計和遵守資料法規至關重要。
資料湖泊的這些特點使其成為現代企業資料架構的重要組成部分,它們支援企業從大量複雜資料中提取價值,推動業務創新和增長。
資料湖泊作為一個集中化的資料儲存系統,為資料的多樣性和可擴充套件性提供了支援,而且也為企業利用這些資料進行深入分析和獲得商業洞察提供了可能。然而,要實現資料湖泊的這些優勢,需要依賴一系列重要技術。
二、支援資料湖泊關鍵技術有哪些
資料湖泊的核心在於其能夠儲存和處理大規模的、多樣化的資料集合,這要求一系列先進技術的支援。從分散式儲存系統到計算引擎,從資料治理到安全保護,每一個環節都是資料湖泊能夠成功實施併發揮其價值的關鍵。
1、分散式儲存技術
分散式儲存技術允許資料湖泊跨多個伺服器和資料中心儲存資料,提供了資料的高可用性和災難恢復能力。HDFS是一個分散式檔案系統,允許對儲存在成百上千個伺服器上的檔案進行儲存和檢索。雲端儲存服務如Amazon S3和阿里雲OSS提供了類似的功能,同時增加了按需擴充套件和按使用付費的能力。
2、元資料管理
元資料管理是資料湖泊的核心,它提供了資料的結構、屬性和關係等資訊。元資料管理系統如Apache Atlas可以捕獲資料的血統、分類、流向和安全策略,幫助資料科學家和分析師更好地理解資料。
3、計算引擎
計算引擎如Apache Spark提供了對資料湖中資料的複雜處理能力。Spark支援批處理、流處理、機器學習等多種計算模式,能夠處理結構化、半結構化和非結構化資料。
4、資料處理框架
Apache NiFi等資料處理框架提供了資料流的視覺化設計和管理。它們允許資料工程師建立資料管道,自動化資料的收集、轉換和交付過程。
5、資料整合工具
資料整合工具如FineDataLink支援從各種資料來源提取資料,並將其載入到資料湖泊中。這些工具通常提供資料轉換和清洗的功能,確保資料的質量。
這些重要技術共同構成了資料湖泊的技術棧,使資料湖泊能夠支援從資料儲存、處理到分析的全流程,滿足企業在資料驅動決策、大數據分析和人工智慧等方面的需求。隨著大數據技術的不斷進步,資料湖泊的重要技術也在不斷髮展和完善。
三、資料湖泊有哪些應用場景
資料湖泊作為一種集中式儲存庫,能夠儲存和處理大規模的多樣化資料,因此它在多種應用場景中都非常有用。以下是一些常見的資料湖泊應用場景:
1、大數據分析
資料湖泊可以儲存大量的原始資料,這些資料可以是結構化的,也可以是非結構化的。企業可以使用大數據分析工具,如Apache Hadoop和Spark,來執行復雜的資料處理和分析任務,從而獲得業務洞察。例如,零售商可能使用資料湖泊來分析客戶購買模式,最佳化庫存管理。
2、機器學習和人工智慧
資料湖泊中的資料可以用於訓練機器學習模型,因為它們提供了豐富的、未加工的資料樣本。這些模型可以用於預測未來事件,如銷售趨勢或裝置故障。AI演算法也可以從資料湖泊中提取複雜的特徵,用於影象識別、語音處理和其他智慧應用。
3、實時分析
資料湖泊可以與實時資料處理系統,如Apache Storm或Flink整合,提供實時資料分析能力。這對於需要即時反饋的業務場景至關重要,如金融市場分析、實時推薦系統或欺詐檢測。
4、 資料科學
資料科學家可以在資料湖泊中自由地探索和實驗,利用其豐富的資料資源進行假設測試和模型構建。資料湖泊的靈活性允許科學家使用不同的工具和技術,如R、Python和SQL,來處理和分析資料。
5、資料治理和合規性
資料湖泊可以實現資料治理,包括資料質量、資料安全和合規性管理。資料治理工具,如Apache Atlas,可以幫助企業監控資料的使用情況,確保遵守資料保護法規,如GDPR或HIPAA。
6、日誌分析
資料湖泊可以收集和儲存系統、應用程式和網路裝置生成的日誌資料。日誌分析工具,如ELK Stack(Elasticsearch, Logstash, Kibana), 可以用於搜尋、分析和視覺化日誌資料,幫助企業監控系統性能,檢測異常行為,提高安全性。
資料湖泊的這些應用場景展示了其在現代企業資料戰略中的多功能性和靈活性。隨著技術的不斷進步,資料湖泊的應用場景還將繼續擴充套件和深化。
然而,要充分利用資料湖泊的潛力,企業需要一套完整的解決方案來應對資料湖泊構建和運維中的各種挑戰。
四、 資料湖泊解決方案
以下是市面上常見的幾種資料湖泊解決方案:
1. AWS資料湖泊解決方案
AWS的資料湖泊解決方案是一個綜合性的服務,它允許使用者在AWS雲平臺上構建和實施資料湖泊架構。資料湖泊通常是指儲存所有結構化和非結構化資料的集中式儲存庫,它支援多種資料型別和資料來源,使得資料可以以原始形式儲存,以便於後續的分析和處理。以下是AWS資料湖泊解決方案的幾個核心功能:
(1) 資料儲存與管理
AWS資料湖泊解決方案以Amazon S3為核心,提供資料儲存與管理服務:
- Amazon S3:為資料湖泊提供了一個高度可擴充套件、可靠和成本效益高的儲存基礎。S3能夠儲存任意型別和規模的資料,支援資料的版本控制和生命週期管理。
- AWS Glue Data Catalog:作為AWS資料湖泊的資料目錄服務,它自動生成和維護資料的元資料,使使用者能夠發現、組織和使用資料。
(2)資料整合與ETL
- AWS Glue:提供ETL功能,允許使用者從各種資料來源抽取資料,將其轉換為分析所需的格式,並載入到資料湖泊中。AWS Glue是一個無伺服器服務,可以顯著降低ETL作業的複雜性和管理開銷。
(3)資料安全與訪問控制
- AWS Identity and Access Management (IAM):透過IAM,使用者可以建立具有特定許可權的角色和策略,精確控制誰可以訪問資料湖泊中的資源。
- AWS Key Management Service (KMS):提供資料加密服務,確保資料在傳輸和靜態儲存時的安全性。
(4)資料分析與BI
- Amazon Athena:允許使用者直接在Amazon S3上執行SQL查詢,獲取資料洞察,按查詢量計費,無需設定或管理任何基礎設施。
- Amazon Redshift Spectrum:擴充套件了Amazon Redshift的資料倉庫功能,可以直接查詢Amazon S3上的資料,實現資料倉庫與資料湖泊的無縫整合。
(5)資料治理與合規性
- AWS Lake Formation:簡化了資料湖泊的建立和操作,提供了資料治理、安全和審計的自動化工具。它幫助使用者定義資料訪問策略,確保資料的合規性和治理。
(6)機器學習與高階分析
- Amazon SageMaker:一個端到端的機器學習平臺,它提供了資料科學家和開發者所需的工具,來構建、訓練和部署機器學習模型。
這些核心功能共同構成了AWS資料湖泊解決方案的基礎,使其成為一個強大、靈活且安全的大資料分析平臺,適用於各種規模和複雜性的資料處理需求。
2. Azure資料湖泊解決方案
Azure的資料湖泊解決方案是一個整合的大數據平臺,它提供了一套完整的服務和工具,用於資料儲存、處理、分析和管理。以下是Azure資料湖泊解決方案的的核心模組:
(1)儲存層
- Azure Data Lake Storage (ADLS)
– ADLS有兩種型別:ADLS Gen1和ADLS Gen2,後者是較新的服務,提供了更高階的功能。
– 支援所有Azure服務的熱、冷、存檔儲存層,適用於資料生命週期管理。
– 支援數百PB的儲存,具有極高的資料吞吐量。
- Azure Blob Storage
– 與ADLS整合,提供了一個物件儲存解決方案,適用於備份、災難恢復和歸檔。
(2)計算層
- Azure Data Lake Analytics (ADLA)
– 一個基於U-SQL的服務,U-SQL是SQL的一個擴充套件,支援使用者定義函式(UDF)和自定義程式碼。
– ADLA的作業可以並行執行,自動擴充套件以處理大量資料。
- Azure HDInsight
– 提供了全託管的Hadoop、Spark、Kafka和HBase等開源服務。
– 支援多種計算模式,包括批處理、流處理和互動式查詢。
- Azure Databricks
– 一個基於Apache Spark的分析服務,提供了協作、效能和安全性。
– 支援機器學習和深度學習,集成了Databricks Runtime,優化了Spark的效能。
(3)分析與BI整合
- U-SQL
– 支援在資料湖泊上執行復雜的SQL查詢,同時允許執行自定義的NET程式碼。
– U-SQL的作業可以在Visual Studio、VS Code和Azure Portal中開發和除錯。
- Azure Synapse Analytics
– 結合了資料倉庫和資料湖泊的功能,提供了無限制的分析能力。
– 支援直接連線到Power BI和其他BI工具,實現即時的業務洞察。
(4)整合與開發工具
- Azure Data Factory
– 提供了資料管道的建立、排程和管理,支援資料的移動、轉換和處理。
– 支援各種資料來源和目標系統,包括本地和雲端服務。
- Azure DevOps
– 支援CI/CD管道的建立,允許自動化資料管道的測試和部署。
Azure的資料湖泊解決方案透過提供這些深入的特性和服務,幫助使用者在雲端中構建一個強大、靈活且安全的資料分析平臺,以支援各種規模和複雜性的資料處理需求。
3. Google Cloud資料湖泊解決方案
Google Cloud的資料湖泊解決方案是一個整合的雲端平臺,旨在幫助企業儲存、處理和分析大規模的資料集。以下是Google Cloud資料湖泊解決方案的詳細介紹:
(1)資料湖泊架構的四個階段
- 資料攝取
– 使用Pub/Sub和Dataflow,可以實時地將資料直接攝取和儲存到Cloud Storage中,支援根據資料量進行擴充套件。
- 資料儲存
– Cloud Storage是Google Cloud資料湖泊的中央儲存庫,具有高容量、永續性、成本效率和安全性。
- 資料處理和分析
– 利用BigQuery進行資料分析,支援SQL查詢,能夠對PB級別的資料進行分析。
- 工作流建立和實施
– 包括資料集市、實時分析、機器學習等,可以透過ETL流程將資料納入BigQuery資料倉庫,然後使用SQL查詢資料。
(2)核心元件
- Google Cloud Storage (GCS):提供了高容量、永續性、成本效率的儲存解決方案,支援大規模資料集的儲存。支援多種儲存類別,如標準、近線、冷儲存等,以滿足不同訪問頻率和成本效益的需求。
- BigQuery:一個無伺服器的雲端資料倉庫,提供高效能的SQL查詢能力,適用於分析大規模資料集。
支援實時分析,允許使用者快速獲取資料洞察。 - Dataproc:是Google Cloud的託管Hadoop和Spark服務,提供大數據處理和機器學習模型訓練的能力。
- Dataflow:一個完全託管的流處理和批處理服務,允許使用者在雲端中執行Apache Beam管道。
- Pub/Sub:提供實時訊息傳遞服務,適用於資料攝取,能夠處理高吞吐量的資料流。
- Dataplex:提供智慧資料結構服務,實現資料治理和安全功能,簡化資料的發現和管理。
- AI Platform:提供機器學習服務,支援模型的訓練、預測和自動化機器學習。
(3)關鍵特性
- 儲存最佳化:GCS提供了高耐用性的資料儲存,設計為99.999999999%的年度耐久性。
- 計算分離:計算和儲存的分離設計,使使用者可以根據需求選擇最適合的計算引擎,而無需擔心底層儲存。
- 無縫整合: Google Cloud的資料湖泊服務之間高度整合,提供一致的使用者體驗和簡化的工作流程。
- 可擴充套件性:支援從小型資料集到EB級別的大規模資料湖泊,可以動態擴充套件以滿足業務需求。
- 智慧資料管理:Dataplex使用元資料來組織資料資產,提供自動資料發現和模式推斷。
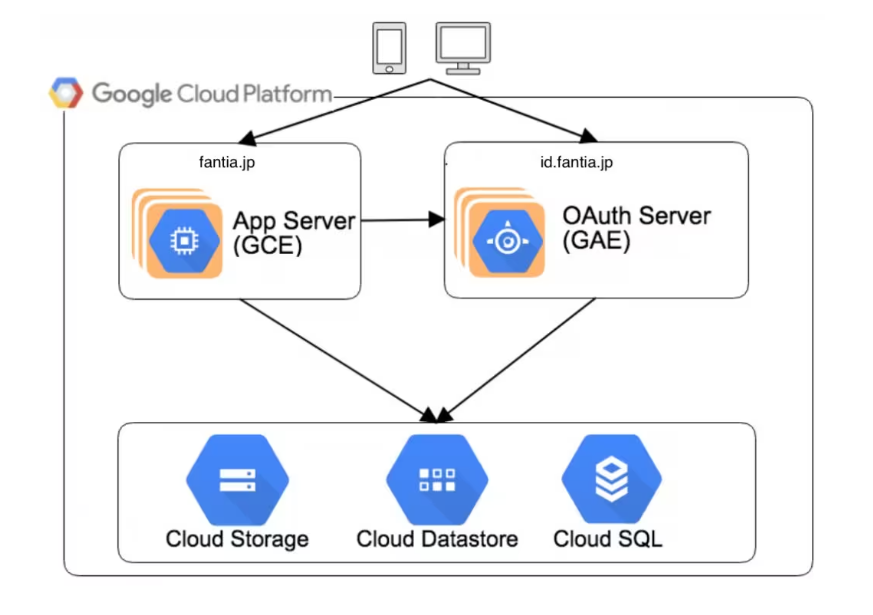
Google Cloud的資料湖泊解決方案透過提供這些服務和工具,幫助使用者在雲端中構建一個強大、靈活且安全的資料分析平臺,以支援各種規模和複雜性的資料處理需求。
4. IBM的資料湖泊解決方案
IBM的資料湖泊解決方案是一個為企業級資料管理、分析和人工智慧(AI)應用設計的全面平臺。它旨在幫助組織更有效地儲存、處理、分析和獲取洞察力,從大量結構化和非結構化資料中。以下是IBM資料湖泊解決方案的詳細介紹:
(1)核心服務和元件
- IBM Cloud Object Storage:
– 提供一個高度可擴充套件和安全的物件儲存服務,適用於儲存海量資料。
- IBM Data Lake:
– 允許組織在IBM Cloud或本地環境中部署資料湖泊,支援多種資料型別和資料來源。
- IBM Big SQL:
– 一個與Hadoop整合的SQL引擎,可以無縫訪問Hive、HBase和Spark SQL中的資料。
- IBM Big Replicate:
– 提供資料複製功能,確保資料一致性,支援資料從一個地方複製到另一個地方。
- IBM Streams:
– 一個複雜的流計算平臺,允許實時分析來自各種來源的流資料。
- IBM Watson Studio:
– 提供資料科學工具,支援資料探索、模型構建和機器學習。
- IBM Watson Knowledge Catalog:
– 提供資料治理工具,幫助組織發現、分類和編目資料資產。
(2)關鍵特性
- 資料整合與管理:
– 支援從不同來源整合資料,包括關係型資料庫、NoSQL資料庫和流資料。
- 資料處理能力:
– 利用IBM Streams和Spark等工具,支援批處理和實時資料處理。
- 分析與機器學習:
– 透過Watson Studio和Big SQL,支援高階分析和機器學習模型的開發。
- 資料治理與安全:
– 利用Watson Knowledge Catalog和其他工具,提供資料治理、資料質量控制和安全訪問控制。
- 元資料管理:
– 透過元資料管理工具,幫助使用者理解資料的結構、來源和使用情況。
- 可擴充套件性與效能:
– 設計用於大規模資料處理,可以水平擴充套件以滿足不斷增長的資料量。
IBM的資料湖泊解決方案透過提供這些服務和工具,幫助使用者在企業內部構建一個強大、靈活且安全的資料分析平臺,以支援各種規模和複雜性的資料處理需求。
五、 總結
隨著資料湖泊技術的發展和應用,企業現在擁有了前所未有的能力來處理複雜的資料挑戰。資料湖泊不僅改變了資料儲存和分析的方式,還促進了跨部門的資料共享和協作,為企業提供了更深入的業務洞察力和更快的決策能力。透過採用合適的資料湖泊解決方案,企業能夠實現資料資產的最大化利用,推動數位轉型,最終實現可持續的競爭優勢。
展望未來,隨著技術的不斷進步,資料湖泊架構將繼續演化,以滿足更廣泛的業務需求。企業需要持續關注資料湖泊領域的最新動態,評估和採納創新的資料湖泊解決方案,以保持其在資料驅動時代的領先地位。透過不斷最佳化資料湖泊的建設和管理,企業將能夠更好地駕馭資料的力量,開啟智慧商業的新篇章。







免費資源下載