企業在選擇資料模型時,常面臨資料結構、查詢模式、擴展性、效能與開發時間等多重考量。舉例來說,電商平台若資料高度結構化,多會採用關聯式資料庫;若業務需快速擴展,NoSQL資料庫則成為主流。資料探索與模型指標比較有助於判斷模型優劣,交叉驗證則提升預測精度。根據2020年調查,MySQL、Oracle、PostgreSQL等資料庫在業界廣泛應用,反映資料模型選擇需緊貼業務需求與技術趨勢。
一、資料模型的定義與目的
1.1 什麼是資料模型?
資料模型是一種用來描述資料結構、資料間關係與規則的抽象工具。它協助開發者、分析師與決策者理解資料的本質與邏輯。根據學術研究,機器學習模型屬於「不依賴規則設計的數據學習算法」,而統計模型則以數學方程式形式正式化變量間的關係。這些模型在資料科學 領域中各有應用,並根據不同需求進行分類。SAS institute的資料科學宇宙圖示也清楚展示了各種資料模型的分類與定義。McKinsey的實例進一步說明,統計模型與機器學習模型在風險預測等應用場景中,因假設條件與運算方式不同,表現也有所差異。
1.2 核心目的:描述、溝通、設計
資料模型的核心目的包括描述資料、促進溝通與指導設計。模型建立過程中,描述能協助團隊明確定義資料內容與結構。溝通則讓開發者、使用者與決策者在系統設計與應用時有共同語言。設計則確保資料模型能順利轉化為實際系統,提升使用體驗。以教育資訊能力檢測為例,研究發現類神經網路模型因分類能力強,適合不同場景下的資訊素養評估。這顯示資料模型的定義與目的會直接影響其應用成效。此外,優秀的圖表設計與統計概念結合,能提升資料溝通的說服力。專家強調,若分析結果無法有效溝通,即使正確也可能失敗,凸顯溝通與設計的重要性。
1.3 重要性:資料管理與系統開發基石
資料模型在資料管理與系統開發中扮演基石角色。
- 系統規劃階段,透過保密協定與存取控制管理顧客知識,確保資料安全。
- 系統開發設計時,利用版本控制與著作權保護管理演算法與原始碼,防止成果被竄改。
- 系統測試與維護階段,結合存取控制與合約保障,確保系統穩定與智慧財產權保護。
這些措施顯示,資料模型不僅協助知識管理,也保障系統安全與創新成果。研究者透過多重資料來源與三角檢證,提升研究信度與效度,進一步證明資料模型在實務中的關鍵作用。
二、資料模型的主要類型與層次
2.1 概念模型 (Conceptual Model)
概念模型屬於資料模型的最高層次。它著重於描述業務需求與資料之間的邏輯關係。設計人員常用概念模型來與業務部門溝通,確保雙方對資料結構有共同認知。
概念模型不關心技術細節,只聚焦於「資料是什麼」與「資料之間有何關聯」。舉例來說,醫院資訊系統的概念模型會標示「病人」、「醫師」、「診斷」等實體,並指出它們之間的關聯。這種模型適合在專案初期,協助團隊快速建立資料全貌。
2.2 邏輯模型 (Logical Model)
邏輯模型進一步細化概念模型。它將抽象的業務需求轉換為具體的資料結構。設計人員會在邏輯模型中定義每個實體的屬性、主鍵、外鍵與資料型態。
- 邏輯模型不受限於特定資料庫技術。
- 它強調資料的完整性與一致性。
- 設計人員常用邏輯模型來規劃資料表與欄位。
例如,學校管理系統的邏輯模型會將「學生」定義為一個實體,並列出「學號」、「姓名」、「班級」等屬性。這有助於後續的資料庫設計與開發。
2.3 實體模型 (Physical Model)
實體模型屬於資料模型的最底層。它將邏輯模型轉換為實際的資料庫結構。設計人員會根據選用的資料庫系統,決定資料表的儲存方式、索引、分區等細節。
舉例來說,電子商務平台在實體模型階段,會根據MySQL或PostgreSQL等資料庫特性,設計分區表或索引,以提升查詢效能。設計人員需根據實際需求,靈活選擇合適的資料模型層次,確保系統穩定與高效。
三、資料模型的常見建模方法
3.1 關聯式建模 (ER Model)
實體-關係模型是一種基於實體(Entity)和關係(Relationship)的資料模型。它透過實體描述真實世界的物件或概念,以屬性(Attribute)描述實體的特徵,透過關係描述實體之間的關聯。實體-關係模型以ER圖(Entity-Relationship Diagram)的形式視覺化,使用圖形符號表示實體、屬性和關係之間的連結。 ER模型的關鍵概念包括實體、屬性、關係、主鍵和外鍵,這些概念用於描述和建模資料之間的邏輯關係。
3.2 維度建模 (Dimensional Modeling)
是資料倉儲大師Ralph Kimball提出的一種用於資料倉儲(Data Warehouse)的建模技術。用於設計資料倉儲(Data Warehouse)和商業智慧(Business Intelligence)系統。它以事實表(Fact Table)和維度表(Dimension Table)為中心,用於分析和報告業務指標。
在維度建模中,事實表包含事實(Facts)和度量(Measures),描述業務事實的數值或數量。維度表包含描述事實的上下文信息,如時間維度、產品維度、地理位置維度等,用於為事實提供詳細的分析維度。維度建模透過將資料轉化為多維結構,提供了更強大和靈活的分析能力,以支援資料分析和決策支援。
3.3 非關聯式建模 (Key-Value, Document, Graph等)
非關聯式建模適合處理彈性高、結構多變的資料。常見類型包括Key-Value、Document與Graph模型。
- Key-Value模型以鍵值對儲存資料,適合快取與即時查詢。
- Document模型(如MongoDB)能儲存半結構化資料,支援複雜文件查詢。
- Graph模型(如Neo4j)專注於資料間的關聯,適合社群網路、推薦系統等應用。
設計人員會根據業務需求選擇最合適的資料模型。例如,社群平台需分析用戶關係時,Graph模型能大幅提升查詢效率。非關聯式建模靈活度高,能快速因應業務變化,成為現代資料科學不可或缺的工具。
四、建構資料模型的關鍵步驟
在BI裡面,常用維度建模。在將業務需求和資料轉換為合適的資料模型時,通常會有以下流程:
4.1 理解業務需求與規則
了解業務需求是維度建模的第一步。透過和業務相關的人員交流,澄清需求、目標和資料要求。這樣能夠更好地掌握資料建模的方向和重點。
在實務應用中,設計人員常透過以下方式強化需求分析:
- 可發現:確保資料來源清楚、可追蹤,提升資料可信度。
- 可存取:設計安全機制與授權控管,保障資料品質。
- 可除錯:具備辨識與修正資料異常的能力,維持資料穩定。
- 可部署:讓資料與模型能順利應用於實際業務流程,創造價值。
許多案例顯示,設計人員會結合資料探索、預處理、預測模型與關聯規則分析,將業務規則轉化為可操作的模型。例如,客戶產品推薦與行為序列分析,能協助企業精準行銷與風險控管。
4.2 定義維度和度量
透過業務需求確定需要的維度和度量。維度可以是時間、產品、客戶等描述業務特徵的數據,而度量則是需要分析和決策的業務指標或數據值,如銷售額、訂單數量等。
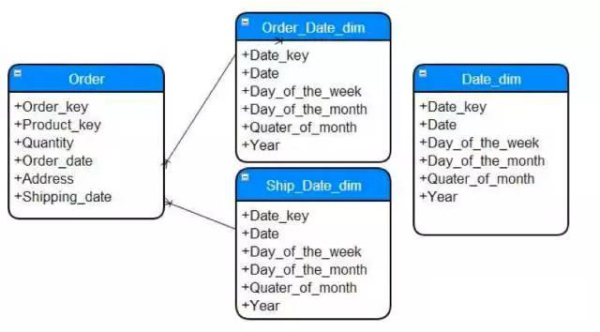
4.3 設計事實表(Fact Table)
事實表是維度建模中最核心的資料結構之一。它透過與多個維度表(Dimension Tables)進行關聯建立起來,並儲存度量資訊。事實表常常是依照業務事件或時間週期進行組織,如銷售事實表、訂單事實表等。
4.4 設計維度表(Dimension Tables)
維度表是描述維度資料的資料結構,與事實表進行關聯。在設計維度表時需要確定維度的層次結構、屬性、關係等資訊。常見的維度包括時間維度、產品維度、顧客維度等。
4.5 建立模型
在此步驟中,建立維度表和事實表之間的邏輯關係,並建立完整的維度模型。在維度模型中,事實表是一個中心的資料集合,與多個維度表之間形成關聯。
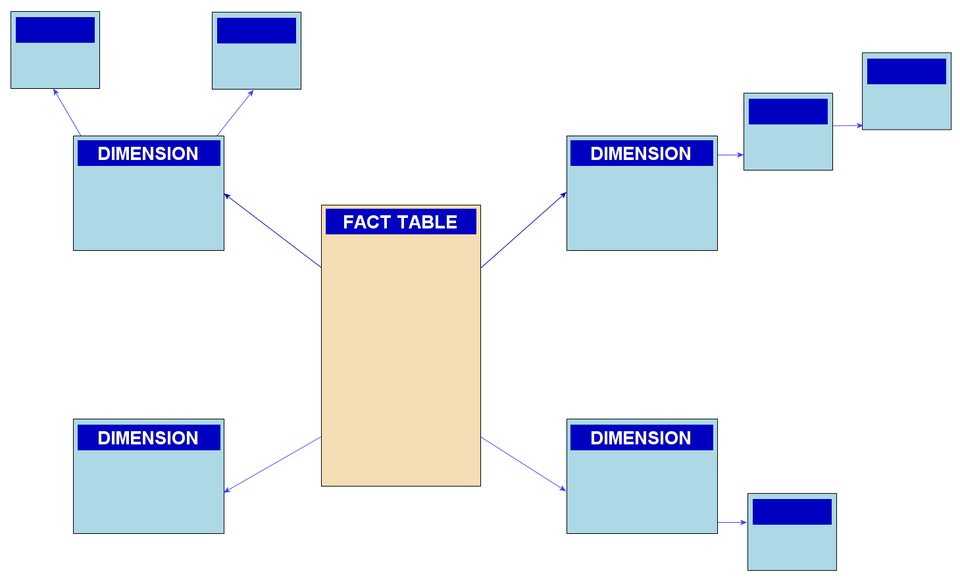
星模式(Star Schema)與雪花模式(Snowflake Schema):
星型模式是維度建模中最常用的資料結構之一,它採用了一個中心的事實表(Fact Table)與多個維度表(Dimension Tables)的關聯結構,形成一個類似星星的圖形。模式簡單、易於理解和使用,適用於大多數數據分析場景。
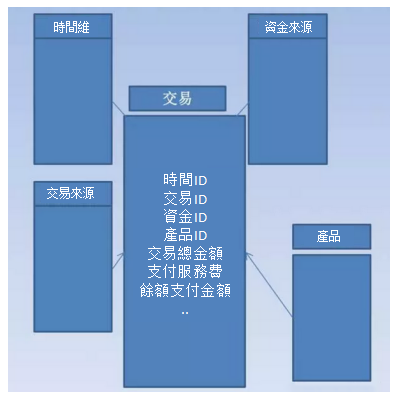
而雪花模式是星型模式的擴展,它在維度表之間建立了更多的關聯關係,形成像雪花一樣的圖形。雪花模式用於複雜的維度結構,能夠提供更精細的維度分析能力。
4.6 優化性能
優化效能是維度建模流程的最後一步。在此步驟中進行模型最佳化、索引最佳化、資料載入和更新等工作,以提高查詢效能、系統效率,提升使用者體驗。
選擇資料模型時,設計人員應以實際需求為出發點,靈活結合各類型模型的優勢。持續關注資料模型技術的發展,有助於提升系統效能與應用價值。建議讀者根據自身業務場景,善用本文比較與選擇指南,做出最適合的決策。歡迎留言分享經驗或提出問題,讓更多人受益於實務交流。







免費資源下載