數據平台已成為現代企業不可或缺的數位基礎設施。企業透過數據平台整合各類數據來源,提升資料管理效率,並加速決策流程。根據市場研究,全球主動資料倉儲市場規模持續成長,涵蓋多產業與各種企業規模。數據平台的普及反映出企業對數據整合與分析能力的高度重視。
一、定義:什麼是數據平台?
1.基本概念
數據平台是一種整合多元資料來源、協助企業進行數據收集、儲存、處理與分析的軟體系統。它不僅僅是傳統資料庫的延伸,更強調數據的流通與應用。資料庫主要負責資料的儲存與查詢,客戶資料平台(CDP)則聚焦於個人化行銷與客戶資料整合。數據平台則涵蓋更廣,能結合AI與IT/OT系統,實現即時異常檢測、專案進度監控,並提升生產效率與降低風險。
企業導入數據平台後,能夠有效整合來自不同部門或外部的資料,進行深入分析。
2.核心價值
數據平台為企業帶來多方面的核心價值,促進數位轉型與營運效率提升。
- 製造業:紡織大廠儒鴻企業導入AI技術,將訂單處理時間從48小時縮短至2小時,效率提升24倍,並節省超過一半作業人力。
- 金融業:金融機構利用ETL工具整合多部門客戶數據,建立統一客戶視圖,提升交叉銷售成功率與服務品質。
- 零售業:沃爾瑪整合銷售、庫存及供應鏈數據,透過數據平台提升需求預測與庫存管理效率,顯著提升營運效率。
- 數位轉型市場規模:根據Mordor Intelligence的報告,全球數位轉型市場規模在2026年已正式突破2兆美元大關,預計2031年將增長至5.33兆美元,五年期間的年複合增長率(CAGR)高達21.55%。
- 企業數位轉型策略普及率高達70%,涵蓋金融、醫療等多個重要行業。
- 客戶體驗提升:37%的IT專案聚焦於改善客戶體驗,運用AI、雲端及物聯網技術提供更個人化服務。
- 營收增長:數位化程度高的企業營收增長可達45%,顯示數據平台與數位轉型帶來顯著財務效益。
這些案例顯示,數據平台已成為企業提升競爭力、推動創新與實現數位轉型的關鍵工具。
二、數據平台的主要功能
1.數據收集
數據收集是數據平台的第一步。企業需從各種來源獲取資料,包括內部系統、外部合作夥伴、物聯網設備及雲端服務。有效的數據收集能協助企業掌握營運現況,並為後續分析提供基礎。
- 數據平台可集中收集效能數據,涵蓋CPU使用率、記憶體、磁碟I/O、網路流量、資料庫查詢效能、交易速率及錯誤率等多層級指標。
- 企業會依據來源、用途或環境區隔效能數據,例如將生產與非生產數據分開,或將效能目標與商務計量分離,提升監控效率。
- 平台也能收集應用程式效能數據,像是利用Azure Application Insights收集遙測數據(請求速率、回應時間、例外狀況等),並支援分散式追蹤,協助關聯多元事件。
- 作業系統層級的數據收集,特別在IaaS環境下,會定期取樣CPU、記憶體、磁碟、網路等性能計數器,確保基礎設施運作正常。
2.數據整合
數據整合是將來自不同來源、格式與結構的資料進行彙整與標準化。這個步驟能消除資料孤島,讓企業獲得全貌資訊。FineBI 提供高效的資料整合能力,透過視覺化拖曳操作無縫整合多源資料(如資料庫、檔案、即時串流),並支援智慧合併(JOIN/UNION)、靈活轉換資料結構(行列轉置/分組)等操作。業務人員無需程式碼即可自助完成清洗、關聯與標準化,快速建構統一分析視圖,大幅提升資料準備效率,釋放分析精力。
3.數據儲存
數據儲存是確保資料安全、可用與高效存取的核心功能。企業需根據資料特性與應用需求,選擇合適的儲存架構。
- 直接附加儲存(DAS)因直接連接伺服器,具備高效能、快速存取及低成本優勢,虛擬化技術更提升其靈活性,適合高效能運算需求。
- 共享儲存設備則強調打破資料孤島,支援多種通訊協定(如SMB、NFS、S3),結合自動分層技術與大容量硬體,兼顧成本與安全性。
- 全快閃儲存已成為市場主流,市佔率超過50%,企業若未採用即落後市場趨勢。
- 2025年全球下一代儲存市場規模約為712.6億美元,2026年預估達到753.0億美元,2031年預計將成長至965.5億美元,年複合成長率約5.10%。AI推動的儲存市場2025年規模約468億美元,2026年預估為549億美元,2034年預計達1984億美元,其中亞太區增長力道最強。
4.數據處理
數據處理是數據平台不可或缺的核心功能。企業透過數據處理技術,能將原始資料轉換為可用資訊,進行清洗、轉換、分類與標註。這些步驟確保資料品質,並為後續分析打下基礎。數據處理不僅提升資料一致性,也能協助企業即時掌握客戶行為與交易資訊,主動規劃流程效率,進行異常辨識與調查,避免服務中斷。
數據處理技術結合機器資料與企業資料,優化資料倉儲架構,降低查詢延遲,支援多型態資料分析。這些應用有效提升企業運營效率,減少成本並強化服務品質。
三、如何構建數據平台?
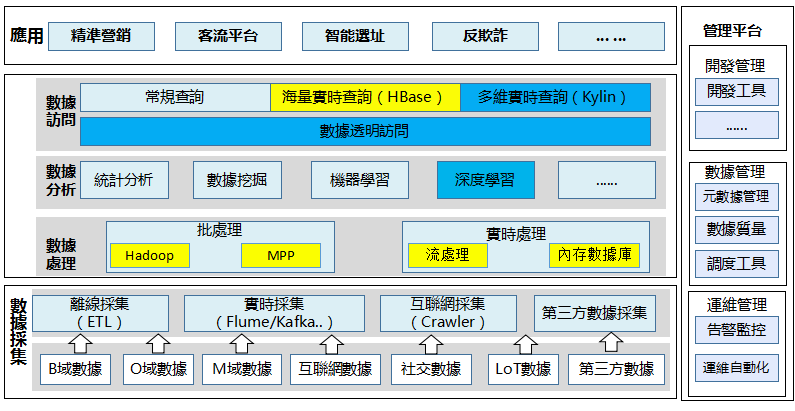
1、數據採集層
離線批量採集,採用的是HADOOP,這個已經成為當前流線採集的主流引擎了,基於這個平台,需要部署數據採集應用或工具。
諸如BAT都是自己研發的產品,一般企業,可以採用商用版本,現在這類選擇很多,比如華為BDI等等,很多企業技術實力有,但起步的時候往往對於應用場景的理解比較弱,細節做工很差,導致做出來的產品難以達到要求,比如缺乏統計功能等,跟BAT差距很大,傳統企業去採購這類產品,要謹慎小心。
一個建議是,當採購產品的時候,除了技術先進性和指標外,更多的應該問問是版本啥時候上線的,是否在哪裡成功部署,是否有足夠多的客戶,如果能做個測試就更好,否則,你就是小白鼠哦,這個坑踩了不少。
能做和做成產品是兩個境界的事情,小的互聯網企業當然也能做出對於自己好用的採集工具,但它很難抽象並打造出一個真正的產品,BAT自研其實形成了巨大的優勢。
實時採集現在也成了大數據平台的標配,估計主流就是FLUME+KAFKA,然後結合流處理+內存資料庫吧,這個技術肯定靠譜,但這類開源的東西好是好,但一旦出現問題往往解決周期往往比較長。
除了用FLUME,針對ORACLE資料庫的報表製作為了實現實時採集,也可以採用OGG/DSG等技術實現實時的日誌採集,可以解決傳統數據倉庫抽全量表的負荷問題。
爬蟲當前也逐漸成為很多企業的採集標配,因為互聯網新增數據主要靠它,可以通過網頁的解析獲取大量的上網信息,什麼輿情分析、網站排名啥的,建議每個企業都應該建立企業級的爬蟲中心,如果它未在你的大數據平台規劃內,可以考慮一下,能拿的數據都不拿,就沒什麼好說了。
企業級的爬蟲中心的建設難度蠻大,因為不僅僅是需要爬蟲,還需要建立網址和應用知識庫,需要基於網頁文本進行中文分詞,倒排序及文本挖掘等,這一套下來,挑戰很大,當前已經有不少開源組件了,比如solr、lucent、Nutch、ES等等,但要用好它,路漫漫其修遠兮。
還有一個就是,如果有可能,筆者建議將數據採集平台升級為數據交換平台,因為其實企業內有大量的數據流動,不僅僅是單向的數據採集,而且有很多數據交換,比如需要從ORACLE倒數據到GBASE,從HBASE倒數據到ASTER等等,對於應用來講,這個價值很大。
既然數據採集和數據交換有很多功能非常類似,為什麼不做整合呢?也便於統一管理,感覺企業的數據交換大量都是應用驅動,介面管理亂七八糟,這也是我的一個建議。
總得來講,建設大數據採集平台非常不易,從客戶的角度講,至少要達到以下三個要求:
- 多樣化數據採集能力:支援對錶、文件、消息等多種數據的實時增量數據採集(使用flume、消息隊列、OGG等技術)和批量數據分布式採集等能力(SQOOP、FTP VOER HDFS),比基於傳統ETL性能有量級上的提升,這是根本。
- 可視化快速配置能力:提供圖形化的開發和維護界面,支援圖形化拖拽式開發,免代碼編寫,降低採集難度,每配置一個數據介面耗時很短,以降低人工成本。
- 統一調度管控能力:實現採集任務的統一調度,可支援Hadoop的多種技術組件(如 MapReduce、Spark 、HIVE)、關係型資料庫存儲過程、 shell腳本等,支援多種調度策略(時間/介面通知/手工)。
2、數據處理層
Hadoop的HIVE是傳統數據倉庫的一種分布式替代。應用在傳統ETL中的數據的清洗、過濾、轉化及直接匯總等場景很適合,數據量越大,它的性價比越高。但目前為止看,其支撐的數據分析場景也是有限的, 簡單的離線的海量分析計算是它所擅長的,相對應的,複雜的關聯交叉運算其速度很慢。
一定程度講,比如企業客戶統一視圖寬表用HIVE做比較低效,因為涉及到多方數據的整合,但不是不可以做,最多慢點嘛,還是要講究個平衡。
hadoop到了X000台集群的規模也撐不住了,當前很多企業的數據量應該會超過這個數量,除了像阿里等自身有研發能力的企業(比如ODPS),是否也要走向按照業務拆分Hadoop集群的道路?諸如浙江行動已經拆分了固網、移網、創新等多個hadoop集群。
Hadoop的SPARK的很適合機器學習的迭代,但能否大規模的應用於數據關聯分析,能否一定程度替代MPP,還需要實踐來驗證。
MPP應該來說,是採用分布式架構對於傳統數據倉庫最好的替代,畢竟其實際上是變了種的關係型資料庫,對於SQL提供完整支援,在HIVE做了轉化分析後,數據倉庫的融合建模用它來做性能綽綽有餘,其性價比較傳統DB2更好一點,比如經過實用,Gbase30-40台集群就能超過2台頂配的IBM 780。
MPP現在產品很多,很難做優劣判斷,但一些實踐結果可以說下,GBASE不錯,公司很多系統已經在上面跑了,主要還是國產的,技術服務保障相對靠譜,ASTER還有待觀望,自帶一些演算法庫是有其一些優勢,GreenPlum、Vertica沒用過,不好說。
現在有個說法是MPP最終也要被Hadoop那套框架替代,畢竟諸如SPARK啥的都在逐步穩定和成熟,但在短期內,我覺得還是很靠譜的,如果數據倉庫要採用漸進的演化方式,MPP的確是很好的選擇。
大數據平台的三駕馬車,少不了流處理。
對於很多企業來講,其顯然是核武器般的存在,大量的應用場景需要它,因此務必要進行建設,比如在IOE時代不可想像的實時、准實時數據倉庫場景,在流處理那裡就變得很簡單了,以前統計個實時指標,也是很痛苦的事情,當前比如反欺詐實時系統,一天系統就申請部署好了。
只嘗試過STORM和IBM STREAM,推薦IBM STREAM,雖然是商業版本,但其處理能力超過STORM不是一點半點,據說STORM也基本不更新了,但其實數據量不大,用啥都可以,從應用的角度講,諸如IBM這種商業智慧版本,是不錯的選擇,支撐各類實時應用場景綽綽有餘。
流處理集群以流處理技術結合內存資料庫,用以實時及准實時數據處理,基於IBM Streams流處理集群承載公司的實時業務:
3、數據分析層
先談談語言,R和Python是當前數據挖掘開源領域的一對基友,如果要說取捨,筆者真說不出來,感覺Python更偏向工程一點,比如有對分詞啥的直接支撐,R的繪圖能力異常強大。但他們原來都以樣本統計為主,因此大規模數據的支撐有限。
筆者還是更關注分布式挖掘環境,SPARK是一種選擇,建議可以採用SPARK+scala,畢竟SPARK是用scala寫的,對很多原生的特性能夠快速支援。
TD的MPP資料庫ASTER也內嵌了很多演算法,應該基於並行架構做了很多優化,似乎也是一種選擇,以前做過幾度交往圈,速度的確很快,但使用資料屈指可數,還需要老外的支援。
傳統的數據挖掘工具也不甘人後,SPSS現在有IBM SPSS Analytic Server,加強了對於大數據hadoop的支撐,業務人員使用反饋還是不錯的。
也許未來機器學習也會形成高低搭配,高端用戶用spark,低端用戶用SPSS,也是要適應不同的應用場景。
深度學習現在漸成潮流,TensorFlow是個選擇,公司當前也部署了一套,希望有機會使用,往人工智慧方向演進是大勢所趨。
無論如何,工具僅僅是工具,最終靠的還是建模工程師駕馭能力。
4、數據開放層
有些工程師直接將HIVE作為查詢輸出,雖然不合理,也體現出計算和查詢對於技術能力要求完全不同,即使是查詢領域,也需要根據不同的場景,選擇不同的技術。
HBASE很好用,基於列存儲,查詢速度毫秒級,對於一般的百億級的記錄查詢那也是能力杠杠的,具有一定的高可用性,我們生產上的詳單查詢、指標庫查詢都是很好的應用場景。但讀取數據方面只支援通過key或者key範圍讀取,因此要設計好rowkey。
Redis是K-V資料庫,讀寫速度比HBASE更快,大多時候,HBASE能做的,Redis也能做,但Redis是基於內存的,主要用在key-value 的內存緩存,有丟失數據的可能,當前標籤實時查詢會用到它,合作過的互聯網或廣告公司大多採用該技術,但如果數據越來越大,那麼,HBASE估計就是唯一的選擇了?
另外已經基於IMPALA提供互聯網日誌的實時線上查詢應用,也在嘗試在行銷平台採用SQLFire和GemFire實現分布式的基於內存的SQL關聯分析,雖然速度可以,但也是BUG多多,引入和改造的代價較大。
Kylin當前算是基於hadoop/SPARK的多維分析的殺手級工具,應用的場景非常多,希望有機會使用。
5、數據應用層
每個企業應根據自己的實際規劃自己的應用,其實搞應用藍圖很難,大數據架構越上層越不穩定,因為變化太快,以下是運營商對外變現當前階段還算通用的一張應用規劃圖,供參考:

6、數據管理層
大數據平台的管理有應用管理和系統管理之分,從應用的角度講,比如我們建立了DACP的可視化管理平台,其能適配11大搭數據技術組件,可以實現對各類技術組件的透明訪問能力,同時通過該平台實現從數據設計、開發到數據銷毀的全生命周期管理,並把標準、質量規則和安全策略固化在平台上,實現從事前管理、事中控制和事後稽核、審計的全方位質量管理和安全管理。
其它諸如調度管理、元數據管理、質量管理當然不在話下,因為管住了開發的源頭,數據管理的複雜度會大幅降低。
從系統管理的角度看,公司將大數據平台納入統一的雲管理平台管理(私有雲),雲管理平台包括支援一鍵部署、增量部署的可視化運維工具、面向多租戶的計算資源管控體系(多租戶管理、安全管理、資源管理、負載管理、配額管理以及計量管理)和完善的用戶許可權管理體系,提供企業級的大數據平台運維管理能力支撐,當然這麼宏大的目標要實現也非一日之功。
數據平台已成為企業數位轉型的核心工具。企業可根據不同受眾行為,設定個人化行銷內容,並透過多渠道監測成效。隨著第三方Cookie逐步淘汰,企業更重視自有數據管理。選擇合適的數據平台,有助於提升決策效率與市場競爭力。建議企業持續學習數據相關知識,並諮詢專業團隊,強化數據素養,迎接未來數位挑戰。







免費資源下載