探索式資料分析是一種在正式建模或決策前,先用統計摘要、視覺化與資料檢查來理解資料的分析方法。它的價值不在於直接下定論,而在於發現問題、辨識模式、形成假設、避免錯誤決策。
對企業來說,探索式資料分析不只是資料科學家的前置工作,也越來越常出現在行銷、業務、製造、財務與營運團隊的日常分析流程中。當資料量增加、欄位變多、來源更分散時,能否快速做好 EDA,往往決定後續分析效率與決策品質。
一、探索式資料分析是什麼
探索式資料分析是用來「先看懂資料,再決定怎麼分析」的方法。它的核心任務是理解資料結構、檢查品質、找出分布與關聯,並為後續報表、模型或決策提供方向。
1. 探索式資料分析的定義與核心目的
探索式資料分析(Exploratory Data Analysis)通常簡稱 EDA,指的是在正式統計檢定、機器學習建模或商業決策之前,先透過圖表、摘要統計與欄位檢查來理解資料。
它通常聚焦在以下幾件事:
- 資料長什麼樣子:有多少欄位、多少筆資料、資料型態是否正確
- 資料是否可信:是否有缺失值、重複值、異常值、格式錯誤
- 資料有什麼模式:分布是否偏態、是否有季節性、是否有群組差異
- 變數之間有何關聯:相關性、交叉影響、可能的重要因子
- 下一步該怎麼做:要不要補值、要不要分群、要不要建立模型或重新定義問題
簡單說,探索式資料分析不是為了立刻證明某個結論,而是為了避免在錯的資料基礎上做對的計算。
2. eda 是什麼?從 exploratory data analysis 中文概念理解
eda 是 exploratory data analysis 的縮寫,中文常翻作探索式資料分析或探索性資料分析。兩種說法在實務上常互通使用,但企業與教學場景中,多數會以「探索式資料分析」稱呼。
從中文概念來看,「探索式」有兩層重點:
- 不是先假設答案,而是先觀察資料
- 分析過程具有迭代性,會一邊看資料一邊修正問題
這點很重要。因為真實世界的資料很少像教科書範例那樣乾淨、完整、結構一致。以常見產業情境來說:
- 電商資料可能有退貨、取消單、重複會員
- 製造資料可能存在感測器漂移、空值、極端波動
- 業務資料可能因人工作業造成欄位格式不一
- 財務資料可能跨系統口徑不同,月結時間也不一致
因此,EDA 的真正價值,在於幫助分析者從「看似有資料」走向「真的理解資料」。
3. 探索型分析與傳統報表分析的差異
探索型分析強調找問題與找原因;傳統報表分析強調固定指標的穩定呈現。兩者不是互斥,而是分析流程中的不同階段。
| 比較面向 | 探索式資料分析 | 傳統報表分析 |
|---|---|---|
| 主要目的 | 發現模式、異常、原因與假設 | 追蹤既定 KPI 與營運結果 |
| 問題形式 | 開放式、需要逐步釐清 | 明確式、答案格式固定 |
| 資料操作 | 常需切片、下鑽、交叉檢視 | 以固定欄位與定義呈現 |
| 使用者 | 分析師、資料團隊、業務主管 | 管理層、營運單位、例行使用者 |
| 輸出結果 | 洞察、假設、分析方向 | 月報、週報、看板、KPI 報表 |
| 適用場景 | 找業績下滑原因、找異常來源 | 看營收達成率、追出貨進度 |
若企業只有報表,通常只能知道「發生了什麼」;若能加入探索式資料分析,才更容易回答「為什麼發生」以及「下一步怎麼做」。
二、探索式資料分析的標準流程
探索式資料分析沒有唯一做法,但實務上通常會遵循一套可重複的流程:先定義問題,再盤點資料、檢查品質、視覺化觀察,最後整理洞察與後續方向。
1. 問題定義與資料盤點
EDA 的第一步不是畫圖,而是先確認你要回答什麼問題,以及你手上的資料能不能回答。
常見的問題定義方式包括:
- 業績為何在最近三個月下滑?
- 某產品線退貨率為何高於平均?
- 某製程站點的不良率是否在特定班別偏高?
- 新會員首購率下降,是流量品質變差還是商品結構改變?
接著要做資料盤點,確認:
- 資料來源有哪些:ERP、CRM、POS、Excel、API、IoT
- 觀測粒度是什麼:訂單級、會員級、設備級、日級、月級
- 時間範圍是否足夠
- 欄位定義是否清楚
- 是否有必要的維度欄位,例如地區、產品、通路、班別
如果在這一步就發現資料不足、欄位缺漏或口徑不明,後面做再多圖表也可能只是誤判。
2. 資料清理、欄位檢查與品質驗證
資料清理的重點是讓分析建立在可信基礎上。常見檢查包含欄位型態、缺失值、重複值、異常格式與不合理數值。
實務上建議至少檢查以下項目:
-
欄位型態是否正確
例如日期被讀成字串、數值欄位混入文字、類別欄位被當連續數值。 -
缺失值比例與分布
不只要看有多少空值,也要看空值是否集中在特定期間、地區、產品或設備。 -
重複資料與主鍵異常
例如訂單編號重複、會員 ID 不唯一、感測資料時間戳重疊。 -
異常值與邏輯錯誤
例如負銷售額、超大交易量、出生日期晚於註冊日期、溫度值超出機台合理範圍。 -
口徑一致性
同樣是「營收」,是否包含稅額、折讓、退貨沖回,必須先確認。
這一步在企業導入時往往最花時間。若資料來自多系統,建議將資料整合與治理先做好;若需要整合層支援,通常會搭配資料整合工具處理,再進入分析層。
3. 視覺化檢視、假設形成與初步洞察
EDA 的核心是透過視覺化快速看出資料分布、差異與關聯。圖表不是為了美觀,而是為了更快發現模式。
常見的視覺化方式包括:
- 折線圖:看時間趨勢,例如月營收、流量變化
- 長條圖:看項目比較,例如各區業績、各產品銷量
- 堆疊圖:看結構占比與變化,例如通路組成
- 圓餅圖:只適合少量分類的占比展示
- 漏斗圖:看轉換流程,例如註冊到付費
- 散點圖:看關聯性,例如投放成本與轉單率
透過這些圖表,分析者通常會產生初步假設,例如:
- 某區域客單價下降可能與折扣活動有關
- 某產線夜班的不良率明顯較高
- 某產品退貨高峰出現在促銷後兩週
- 會員轉換率下滑可能與新流量來源品質較差有關
這些假設不等於最終結論,但它們是後續驗證、建模或決策的重要起點。
4. 結果整理與後續分析方向規劃
EDA 的輸出不應只是一堆圖,而應該是可行的分析結論與下一步建議。
建議整理成以下格式:
- 發現了什麼現象
- 可能原因有哪些
- 目前資料是否足以支持判斷
- 還需要哪些補充資料
- 下一步要做什麼分析或驗證
例如:
- 發現北區新客轉換率在 4 月起明顯下滑
- 下滑集中於某兩個投放渠道
- 目前缺少廣告素材與受眾標籤資料
- 下一步建議串接投放平台資料,檢查素材與受眾品質差異
對企業團隊而言,這一步若能搭配 BI 工具進行共享,會比單次簡報更有價值,因為其他部門能延續同一份分析主題繼續下鑽與協作。
三、常見方法與分析重點
探索式資料分析常見方法可分成單變量、雙變量與多變量三類。先看單一欄位是否合理,再看變數間關聯,最後才處理更複雜的結構與異常模式。
1. 單變量檢查:分布、離群值與缺失值
單變量檢查是最基本也最重要的一步。因為若連單一欄位都沒看清楚,後面做相關性或模型很容易失真。
常見檢查重點如下:
- 分布型態:常態、偏態、雙峰、多峰
- 集中趨勢:平均數、中位數、眾數
- 離散程度:標準差、四分位距、最大最小值
- 缺失情況:空值比例、空值集中在哪些群組
- 異常值:極端高低值是否合理
舉例來說,如果客單價平均值很高,但中位數很低,通常代表少數大單把平均數拉高;如果設備溫度分布突然出現雙峰,可能代表不同機台狀態被混在一起。
在實務上,單變量檢查常能率先發現:
- 資料讀取錯誤
- 單位不一致
- 極端值未處理
- 缺失值非隨機分布
- 需分群分析的跡象
2. 雙變量與關聯分析:相關性、交叉分析與趨勢判讀
雙變量分析的目的,是看兩個變數之間是否存在關聯、差異或共同變動。
常見方法包括:
- 數值對數值:散佈圖、相關係數、趨勢線
- 類別對數值:箱型圖、群組平均比較
- 類別對類別:交叉表、堆疊圖、比例分析
- 時間對數值:趨勢圖、移動平均、分段變化
不過要注意,相關不等於因果。比如廣告費與營收同時上升,可能是活動季節導致,而不一定是單純的投入造成結果。
雙變量分析常見可回答的問題有:
- 折扣率越高,退貨率是否也越高?
- 不同地區的客單價是否有顯著差異?
- 設備速度提升後,不良率是否跟著上升?
- 新舊會員在促銷期間的回購模式是否不同?
若這一步做得扎實,很多管理問題其實不必立刻進入複雜模型,就已能找到決策方向。
3. 探索式多變量資料分析的應用重點
多變量分析適合在欄位多、影響因素複雜、單一變數難以解釋現象時使用。重點是辨識結構,而不是只看單點差異。
常見應用包括:
- 分群觀察:找出不同客群、產品群、設備群的特徵
- 降維輔助理解:在高維資料中觀察群聚或異常分布
- 共變結構檢查:辨識高度相關欄位,避免重複資訊
- 異常組合辨識:單欄位看正常,但欄位組合異常
例如,在客戶分析中,單看消費金額未必有用,但若同時看購買頻率、品類廣度、回購週期與折扣敏感度,就可能分出高價值會員、活動型會員與流失風險會員。
在企業情境中,多變量探索式資料分析通常很適合用於:
- 客群分層
- 商品組合分析
- 製程異常因子初步篩選
- 交叉部門 KPI 關聯檢視
4. eda 工程資料分析中的欄位特徵與異常偵測
工程資料分析中的 EDA,重點常落在時間序列、設備訊號、欄位漂移與製程異常。與一般商業資料相比,工程資料更重視連續性與上下限邏輯。
常見檢查方式包括:
- 欄位範圍檢查:是否超出設備允許值
- 時間序列波動檢查:是否突然跳點、平線、雜訊增加
- 欄位漂移檢查:同一感測欄位在不同週期是否逐步偏移
- 群組比對:不同機台、線別、班別是否存在系統性差異
- 異常事件前後比較:故障前的指標是否已有先兆
例如某溫度欄位平均值正常,但標準差逐週提高,就可能表示設備穩定性下降。又例如某壓力值在白班正常、夜班異常偏高,可能反映人員操作或維護差異。
這類資料若只看月報平均值,常會錯過異常早期訊號,因此探索型分析比固定報表更能支援現場改善。
四、常用工具與 Python 實作方向
探索式資料分析既可以用 Python 進行程式化處理,也可以用 BI 工具做快速視覺探索。選擇哪一種,不只取決於技術能力,也取決於分析速度、協作需求與使用者角色。
1. 探索式資料分析python 的常見工具組合
如果使用 Python 做探索式資料分析,常見工具組合大致如下:
| 工具 | 主要用途 |
|---|---|
| pandas | 資料讀取、清理、欄位檢查、彙總 |
| numpy | 數值運算與陣列處理 |
| matplotlib | 基礎圖表繪製 |
| seaborn | 統計視覺化與關聯圖 |
| plotly | 互動式圖表 |
| scipy | 基礎統計方法 |
| ydata-profiling 類工具 | 快速生成資料概況報告 |
典型流程通常是:
- 讀取 CSV、Excel、資料庫資料
- 檢查 shape、dtypes、head、describe
- 計算缺失值與唯一值
- 畫分布圖、箱型圖、散佈圖
- 建立群組統計與交叉比較
- 整理異常與洞察
Python 的好處是彈性高、可重複執行、適合客製分析,也有利於之後接機器學習流程。
2. eda 資料分析 python 的基本操作流程
Python 版 EDA 的基本操作,通常遵循「讀資料、看結構、檢查品質、視覺化、整理發現」這五步。
可概念化成以下流程:
-
載入資料
匯入 DataFrame,確認列數、欄位數與欄位名稱。 -
檢查欄位型態
確認日期是否為 datetime、數值欄位是否可運算、類別欄位是否需轉型。 -
查看摘要統計
透過平均數、中位數、分位數、標準差了解欄位輪廓。 -
檢查缺失值與重複值
計算比例,判斷是否需補值或排除。 -
視覺化分布與關聯
先單變量,再雙變量,必要時做群組切分。 -
形成分析備忘錄
把異常、假設與下一步整理下來,而不是只停留在 notebook 畫面。
對個人分析師來說,這種流程很有效;但若要給業務、主管或其他部門反覆查看,仍需轉成更易共享的分析介面。
3. 何時適合用程式化 EDA,何時適合用 BI 工具
如果重點是高度客製、批次處理、需接模型流程,適合用 Python;如果重點是快速探索、多人協作、跨部門共享,通常更適合用 BI 工具。
可以用下表快速判斷:
| 情境 | Python EDA | BI 工具 |
|---|---|---|
| 需要客製轉換或演算法 | 很適合 | 較有限 |
| 資料科學建模前分析 | 很適合 | 可輔助 |
| 業務單位自行下鑽分析 | 不一定方便 | 很適合 |
| 跨部門共同查看結果 | 需另做介面 | 很適合 |
| 重複性高的管理分析 | 可自動化,但門檻較高 | 很適合 |
| 非技術人員使用 | 門檻高 | 門檻低 |
以企業導入來說,常見做法不是二選一,而是資料科學團隊用 Python 深挖、業務與管理單位用 BI 工具持續探索與應用。
像 FineBI 這類自助式分析平台,就很適合放在探索式資料分析的日常使用層。它強調拖拉式操作、多維分析、視覺化建模與共享協作,對不熟 SQL 或程式的部門使用者尤其友善。
五、實務應用情境與產品推薦
探索式資料分析的價值,在於能把「資料很多」轉成「知道該看什麼」。在不同行業中,EDA 的任務不同,但核心都一樣:找異常、找原因、找方向。
1. 行銷與業務分析中的探索式資料分析應用
在行銷與業務場景中,探索式資料分析最常被用來找轉換差異、客群特徵與業績變化原因。
常見應用包括:
- 流量品質分析:不同渠道帶來的會員註冊率、首購率、回購率是否不同
- 客群分層探索:新客、老客、高價值客、沉睡客的行為差異
- 商品與活動分析:哪些商品在促銷後提升銷量但壓低毛利
- 業績異常追蹤:某區域業績下滑,是人員、通路還是產品結構造成
例如某電商團隊發現營收上升但獲利下降,透過探索式資料分析可能會發現:
- 銷量成長集中在低毛利商品
- 折扣活動提升了訂單數,但客單價下降
- 新客增加,但回購品質不佳
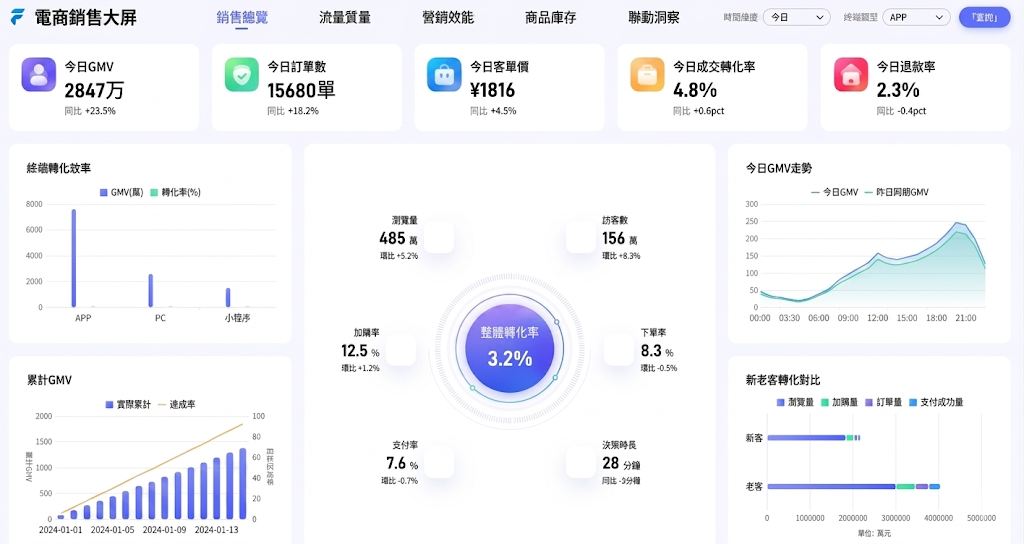
這種情況下,單看傳統營收報表很難看出結構問題,必須透過多維探索分析才能定位原因。
2. 製造與營運場景中的探索型分析實例
在製造與營運場景中,探索型分析常用來檢查製程穩定性、設備異常、出貨效率與成本變化。
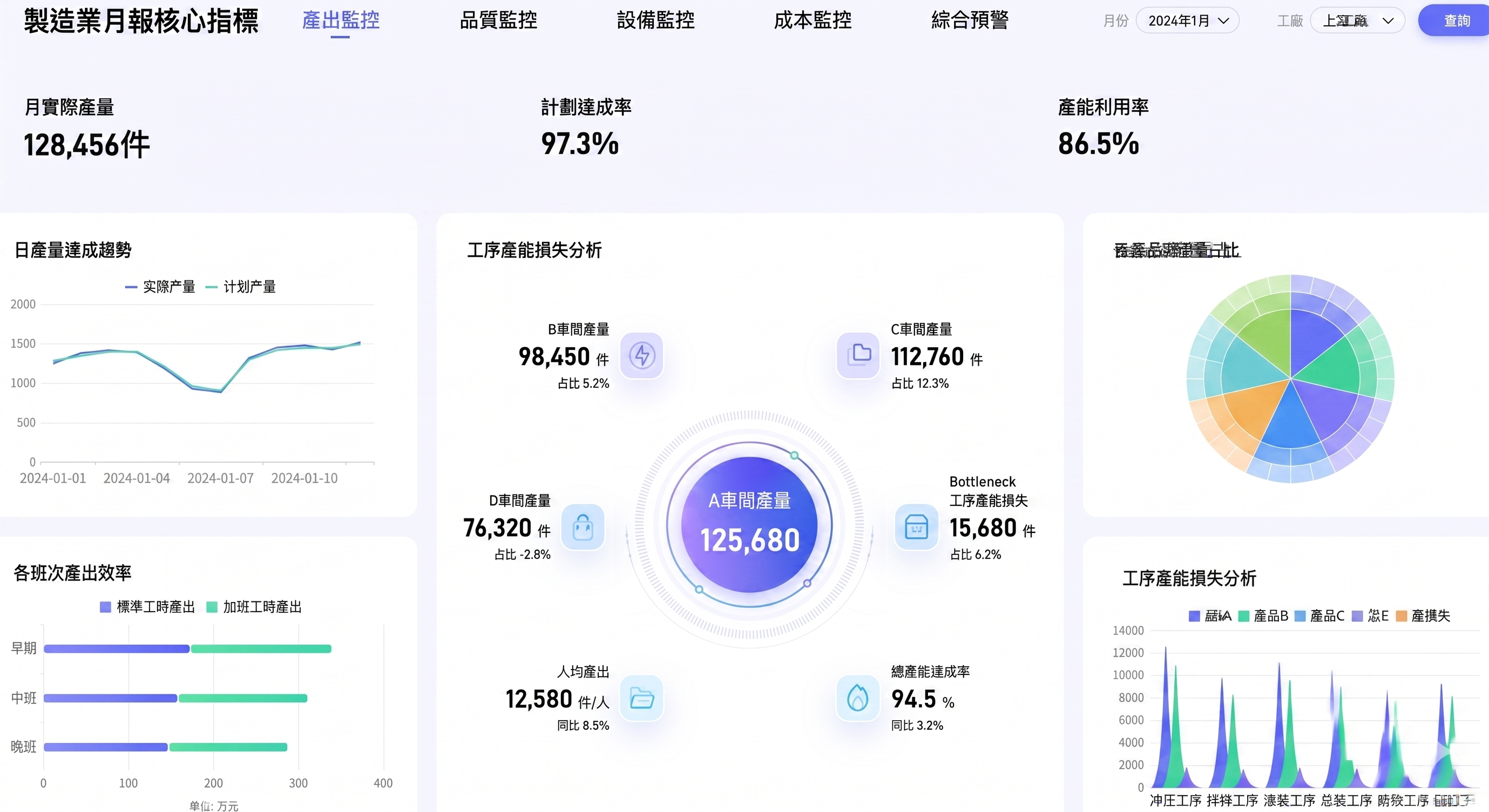
典型實例如下:
- 不良率異常分析:從產品別、機台別、批次別、班別下鑽
- 設備監控探索:觀察溫度、壓力、轉速等欄位的波動與異常點
- 交期與出貨分析:找出延遲集中在哪些倉別、客戶別或流程節點
- 營運成本拆解:分析成本上升是否來自人工、原料、能源或報廢
舉例來說,若某產線不良率突然升高,EDA 可以先做:
- 比較異常前後的機台參數分布
- 分析是否集中於特定班別或原料批次
- 交叉檢視不良類型與設備狀態
- 找出最可能的影響因子,再交由工程團隊驗證
這種分析流程,往往比只看固定監控指標更能早一步找到問題源頭。
3. FineBI 如何加速 exploratory data analysis 流程
FineBI 適合用來加速 exploratory data analysis,特別是在企業需要讓更多非技術使用者參與分析時。它的強項是把資料探索、視覺化分析與協作分享放在同一平台內完成。

對 EDA 流程來說,FineBI 的幾個實務優勢很明確:
- 拖拉式操作,降低技術門檻
業務、營運、財務人員不必高度依賴 SQL,就能做切片、下鑽與交叉分析。
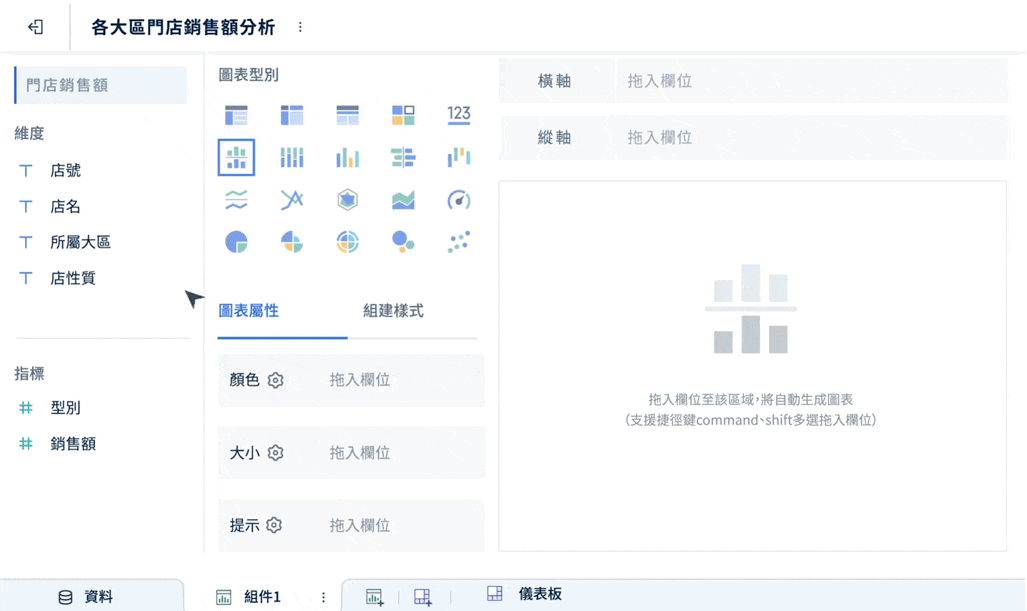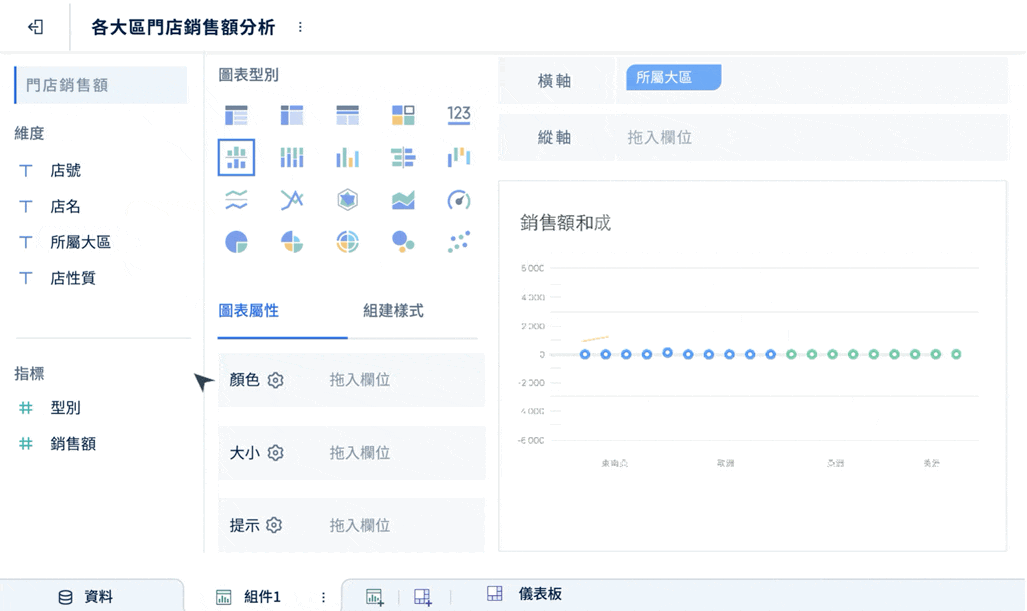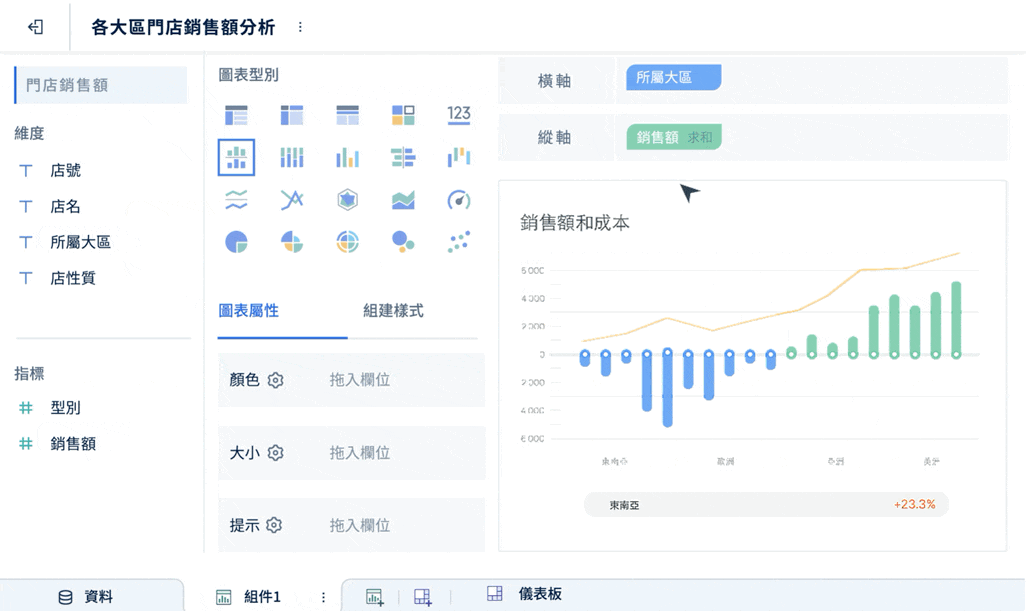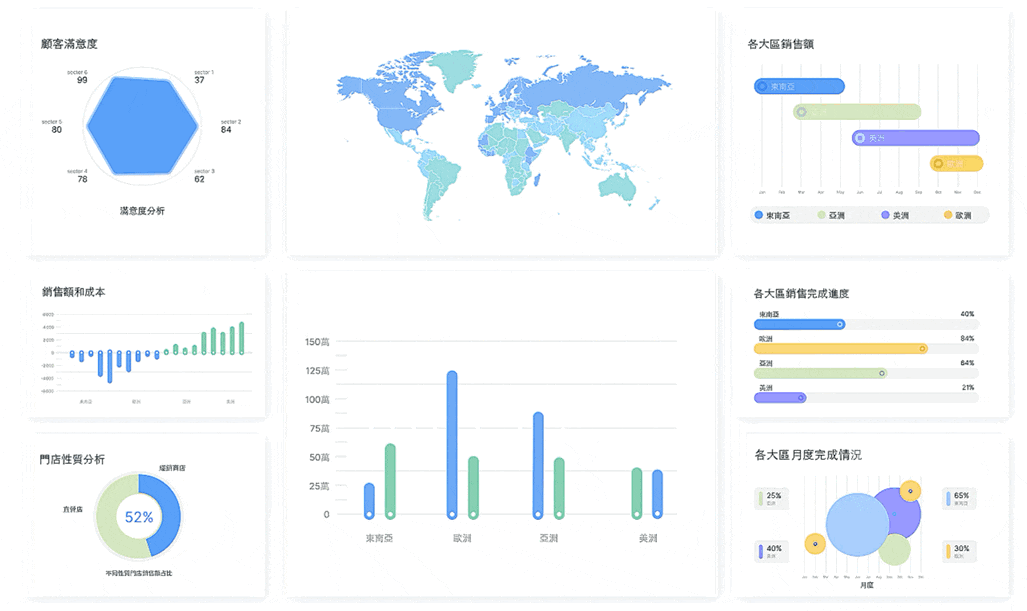
-
主題模型支援多表分析
在多表關聯場景下,可透過視覺化主題模型整理表關係與指標邏輯,減少手動對表與 VLOOKUP 式作業。 -
分析、視覺化、發佈一體化
從資料到看板不必在多工具間頻繁切換,適合需要快速迭代的探索分析流程。 -
多人共享與持續使用
分析結果不會停在個人電腦,可直接發佈、協作、複用,讓洞察變成團隊資產。
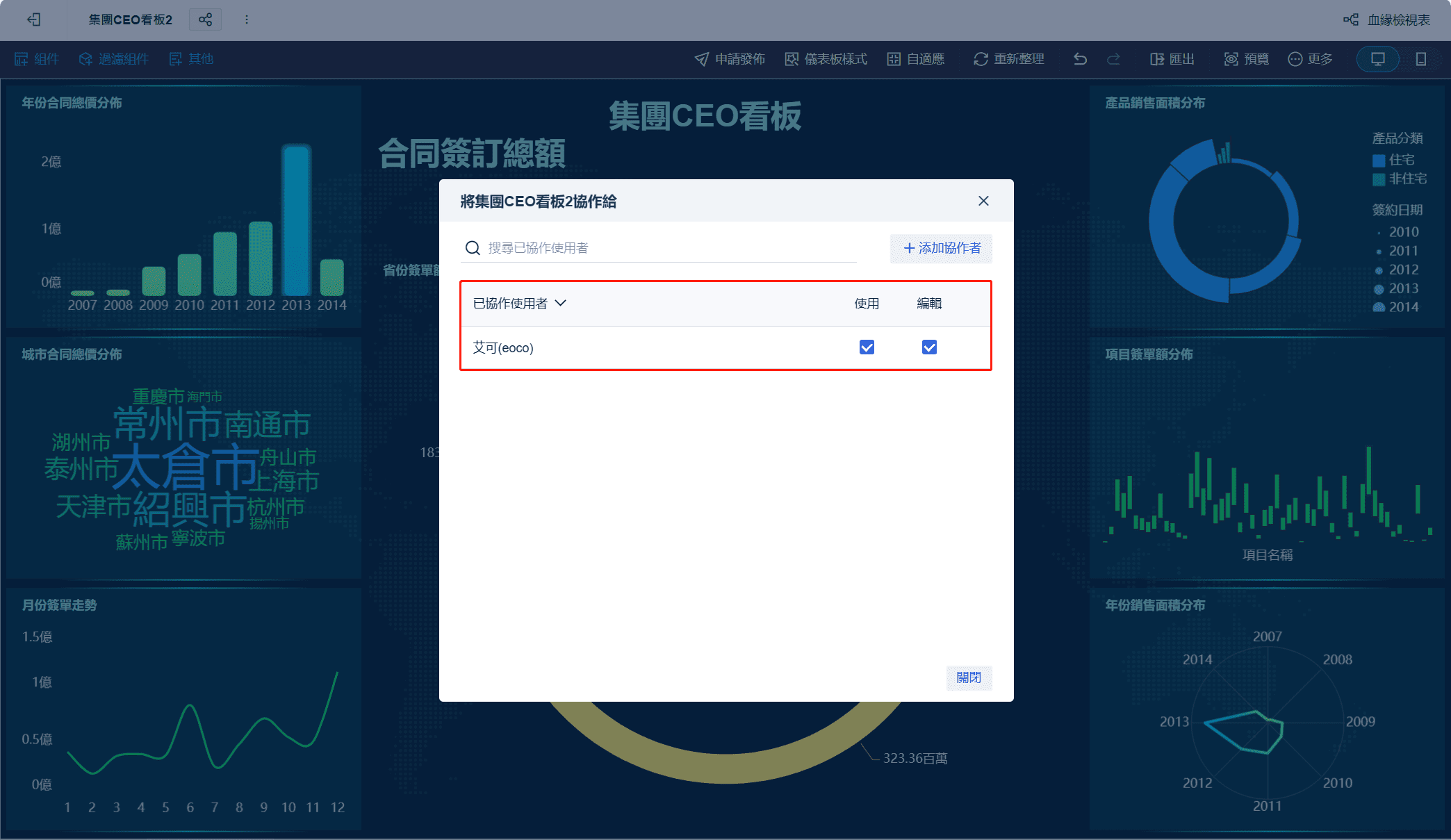
用一句話概括:FineBI 更像是把探索式資料分析從個人技術工作,擴展成企業可持續運作的分析能力。
4. FineBI 在跨部門資料探索與儀表板協作的實務場景
當企業的資料探索不只是一位分析師在做,而是要橫跨業務、營運、財務、管理層共同使用時,工具是否支援協作就很關鍵。
FineBI 在這類場景中的實務價值,通常表現在以下幾點:
-
建立統一分析入口
透過數據門戶與個人化首頁,使用者可以更快找到常用看板與分析主題,減少入口分散問題。 -
支援多維下鑽與共用視角
同一份主題可由不同角色從不同維度檢視,例如業務看客戶、營運看區域、管理層看 KPI 匯總。
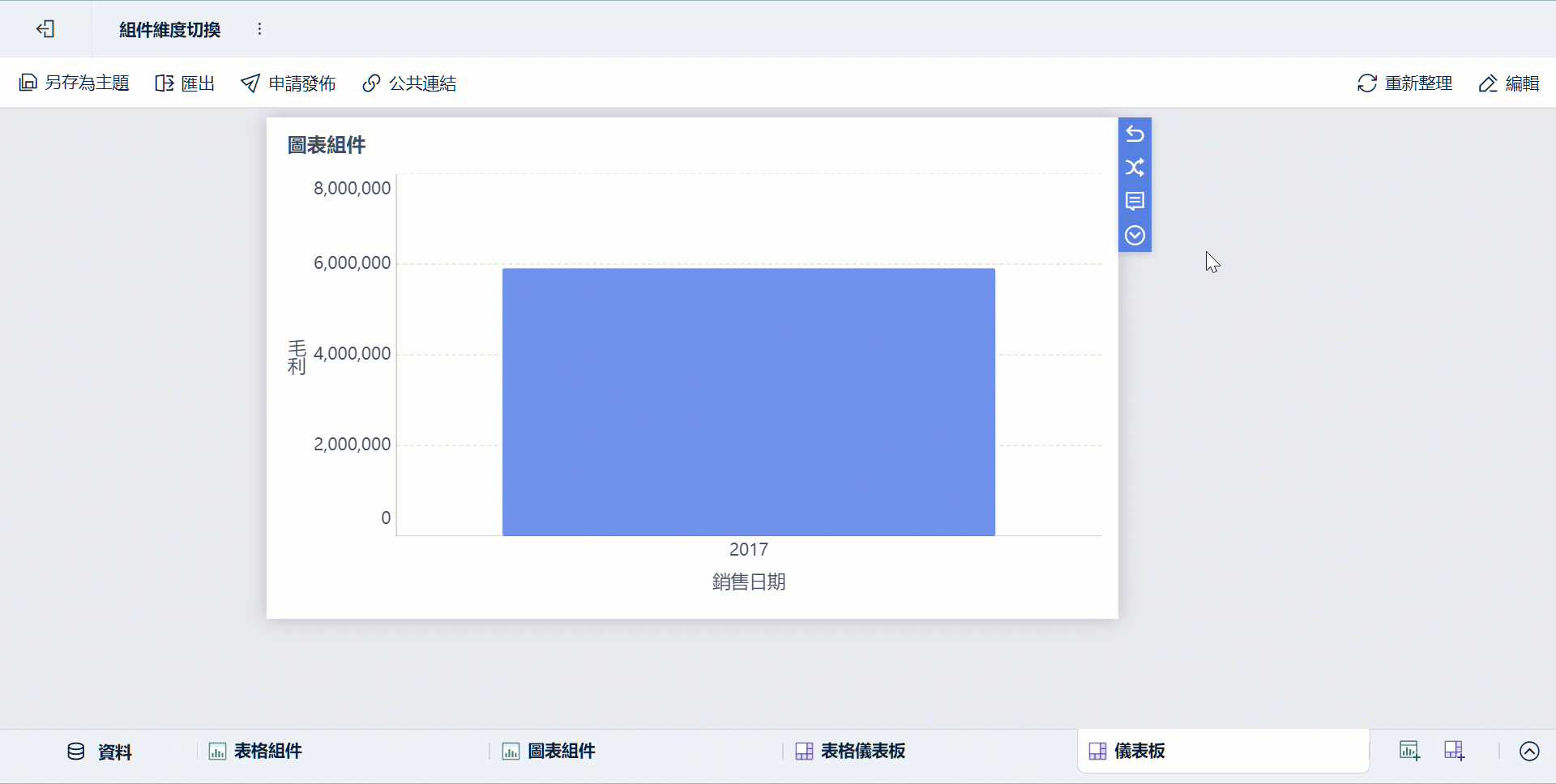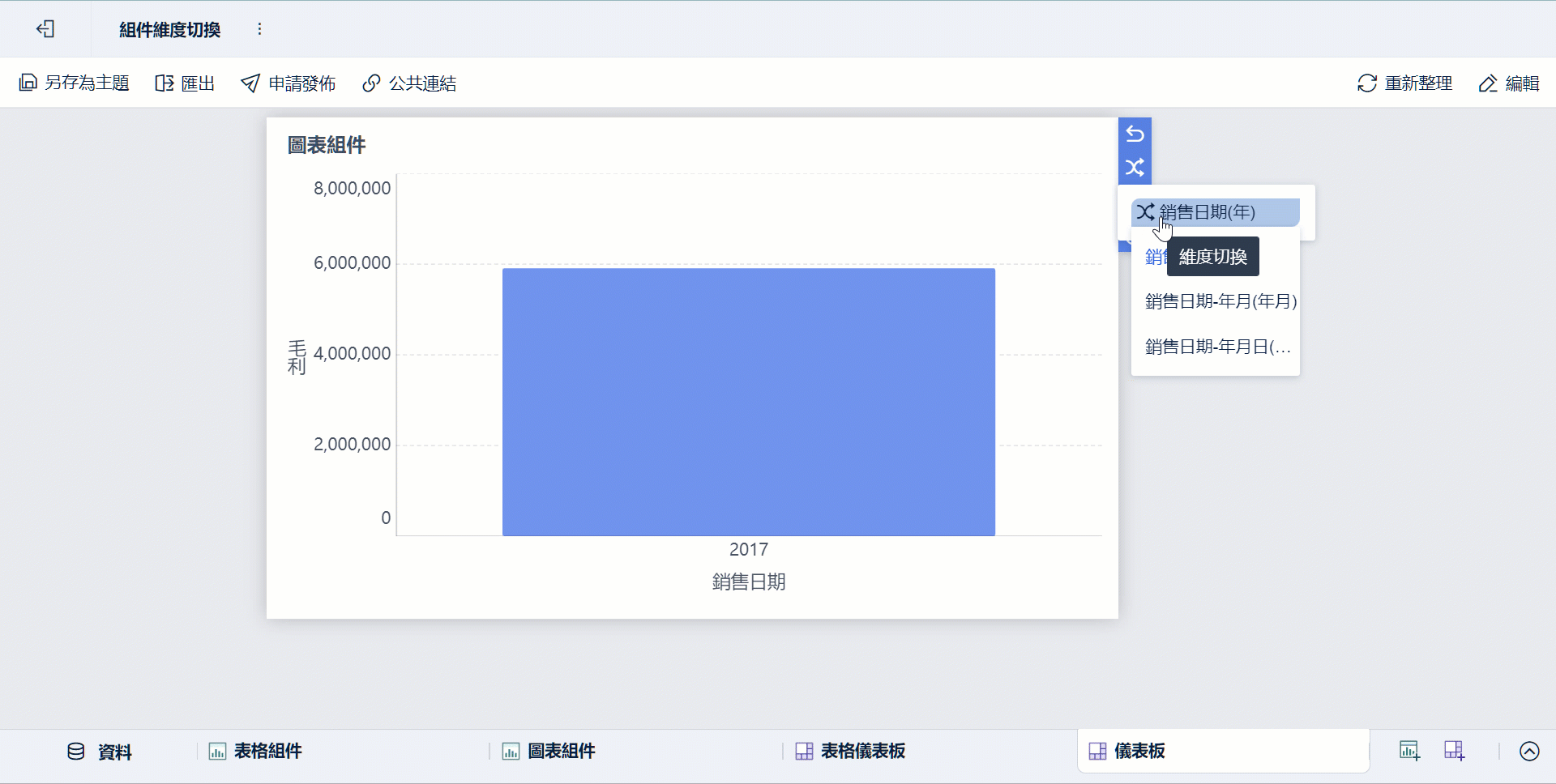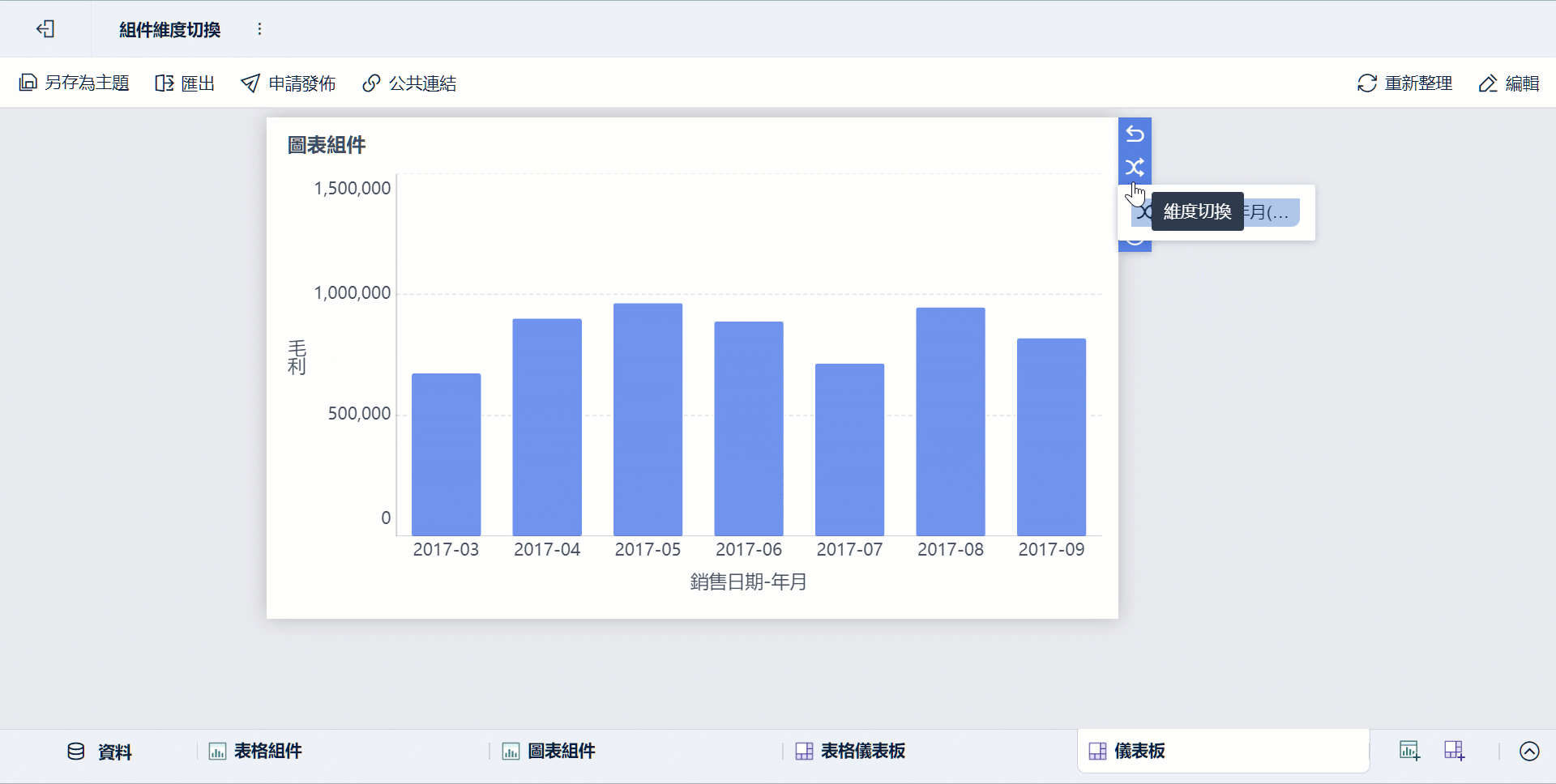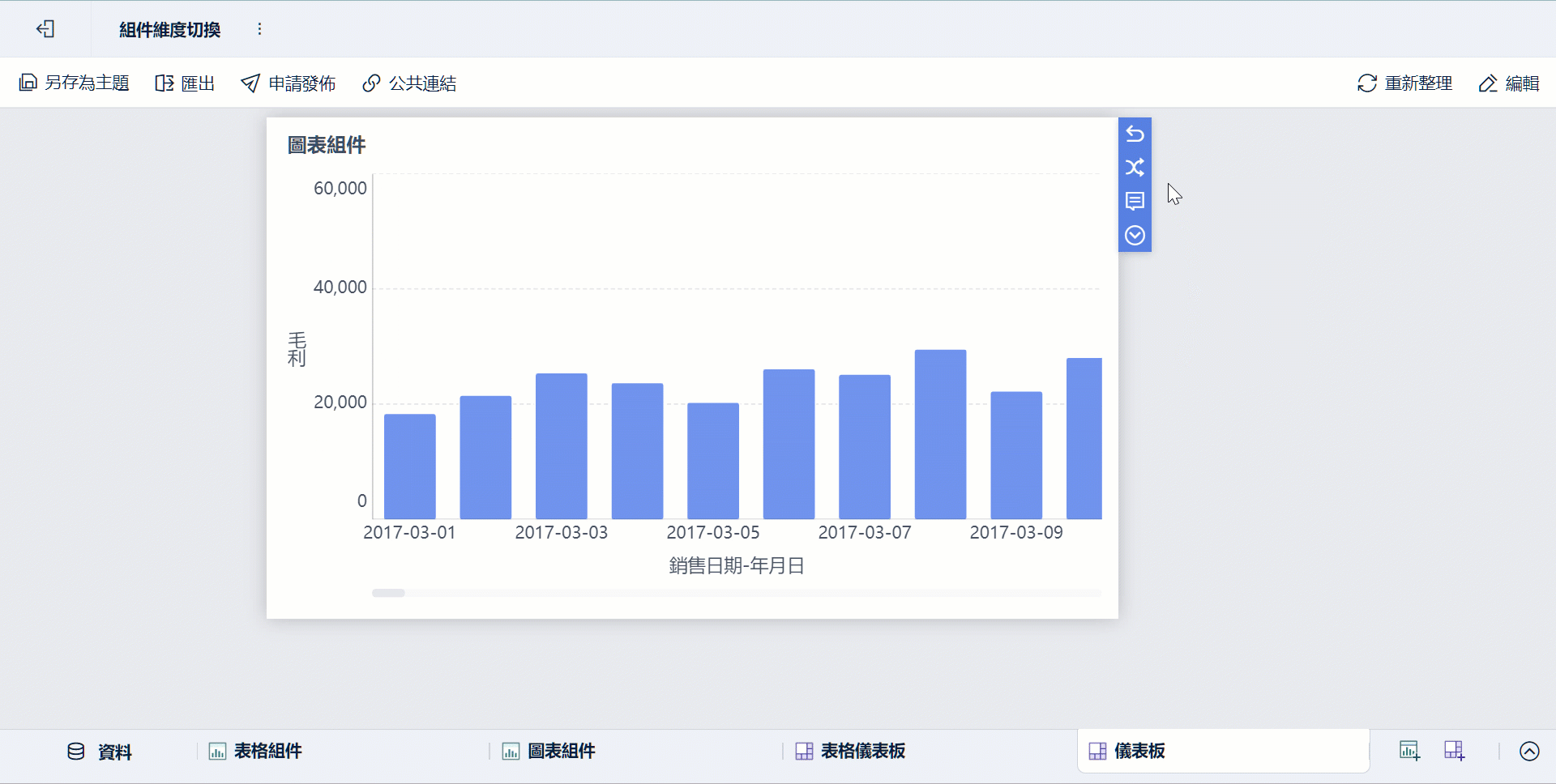
-
分析成果可沉澱與複用
強關聯看板可打包封裝,讓單次分析成果成為後續可重複使用的分析應用。 -
降低 IT 反覆製表負擔
常見企業情境是 IT 先建立基礎模型,部門再自行探索,這能明顯減少重複性報表需求。
例如在月營運檢討會中,主管看到某地區獲利下降,若使用一般靜態報表,通常只能回頭請分析師重做;但若使用 FineBI,現場就能依地區、產品、客戶群、折扣與費用結構逐層下鑽,更快定位原因。
六、導入探索式資料分析的常見挑戰與建議
導入探索式資料分析最大的難點,通常不是缺工具,而是資料基礎、指標口徑與組織使用習慣尚未成熟。要讓 EDA 真的產生決策價值,必須同時處理資料、流程與人。
1. 資料來源分散與口徑不一致的處理方式
資料來源分散與口徑不一致,是企業做探索式資料分析最常見的阻礙。若同一指標在不同系統定義不同,分析結果就很難被採信。
建議處理方式如下:
-
先定義核心指標口徑
例如營收、毛利、活躍會員、訂單數,要明確定義計算方式。 -
建立資料分層與整合流程
原始層、明細層、彙總層、應用層分開管理,可降低資料混亂。 -
保留欄位血緣與版本說明
知道數據從哪裡來、怎麼算出來,才能支援跨部門溝通。 -
區分整合工具與分析工具角色
資料同步、ETL、治理應由整合層處理;探索分析則由 BI 層承接。
如果企業資料來源很多,通常需要先完成資料整合基礎,再放大 EDA 的效果。否則每次分析都在花時間對口徑。
2. 從 exploratory data analysis 到決策落地的關鍵做法
探索式資料分析若只停留在發現現象,就很難真正產生商業價值。從 EDA 走向決策落地,關鍵是把洞察轉成行動。
建議可遵循以下做法:
- 每次探索都對應明確業務問題
- 將分析發現轉成可驗證假設
- 設定後續行動與責任人
- 把結果回寫到報表或儀表板中持續追蹤
- 對重要異常建立預警與例行檢視機制
例如發現某產品退貨率偏高,不應只寫成「需持續觀察」,而應具體轉成:
- 針對特定批次抽驗
- 針對高退貨通路調整說明頁
- 兩週後回看退貨率與客服標籤變化
這樣 EDA 才不會只是分析展示,而是實際推動改善。
3. 企業建立探索式資料分析機制的導入建議
企業若想把探索式資料分析變成常態能力,建議不要只買工具,而是從制度、模型與使用習慣一起建立。
可參考以下導入順序:
-
先選一到兩個高價值場景試點
例如業績異常分析、不良率追因、會員流失分析。 -
建立可複用的資料主題與核心指標
讓不同部門在同一語意基礎上探索。 -
區分角色與分析深度
IT 負責資料基礎與權限,分析師負責方法,業務單位負責場景應用。 -
搭配培訓與內部社群
實務上,企業若有持續教育、問題交流與案例分享,分析擴散速度會更快。 -
讓探索結果能沉澱到平台中
不要讓洞察只存在簡報或個人檔案,而要變成組織可重複使用的資產。
從常見企業推動經驗來看,若能搭配像 FineBI 這類自助式分析平台,會更容易把分析能力從少數人擴展到部門層級,進而形成資料驅動的工作習慣。
探索式資料分析的本質,不是炫技,也不是畫很多圖,而是在不確定中快速看懂資料、找出問題、縮小決策盲點。不論你是資料分析師、產品經理、營運主管,還是正在導入 BI 的企業團隊,只要面對的不是單純固定報表,而是需要找原因、看結構、判斷下一步,EDA 就會是非常關鍵的一步。
如果你正在評估如何讓探索式資料分析從個人能力變成團隊能力,那麼除了 Python 這類程式化方法,也很值得把 FineBI 納入工具選項。對多數企業而言,真正重要的不只是能不能分析,而是能不能讓更多人持續、有效、在同一平台上完成分析與協作。
FAQs
AI 能自動化資料清理、報表與部分分析流程,但商業問題定義、洞察解讀、指標設計與決策支援仍需要資料分析師,因此更偏向協作而非完全取代。
EDA(Exploratory Data Analysis,探索性資料分析)是透過統計與視覺化方法,先了解資料分布、異常值、趨勢與關聯性的分析流程。
在 Taiwan,初階數據分析師薪資通常約月薪 4–5 萬台幣;具備 SQL、Python、BI 工具或相關經驗者,薪資通常更高。
大數據分析流程通常可分為:資料蒐集 → 資料清理與整合 → 資料分析 → 視覺化與決策應用。







免費資源下載