在數據驅動決策的時代,能夠駕馭海量資料並轉化為洞察是一項關鍵競爭力。Python,以其豐富的生態系與直觀的語法,已成為大數據分析領域無可爭議的首選工具。本文將提供一份完整的學習路徑圖,從資料獲取、清洗處理、進階分析到視覺化呈現,系統性地帶你掌握 Python 大數據分析的實務精髓。
一、Python大數據分析的核心價值與應用場景
Python 在大數據分析領域的核心價值,在於它能以單一語言串聯從資料爬取、清洗、分析到機器學習建模的完整流程,大幅降低技術複雜度與團隊協作成本。
1. 為何選擇Python作為大數據分析的首選語言
選擇 Python 的首要原因在於其「易學易用」與「生態系完整」。相較於其他語言,Python 語法接近英語,學習曲線平緩,非常適合資料科學家、分析師或業務人員跨領域學習。根據常見產業觀察,Python 龐大的開源函式庫生態系,如 Pandas、NumPy、Scikit-learn,幾乎涵蓋了數據處理與分析的所有需求,使得開發者能快速建構分析流程,無需重複造輪子。
2. 大數據分析工具python的比較與生態系優勢
當我們比較大數據分析工具時,Python 的優勢在於其整合性。例如,R 語言雖在統計分析上強大,但在生產部署與軟體工程實踐上較為吃力;SQL 擅長資料查詢但缺乏靈活的演算法實作能力。Python 則完美橋接了兩者:透過 Pandas 可執行類似 SQL 的資料操作,利用 Scikit-learn 能快速實作機器學習模型,再結合 Dask 或 PySpark 便能處理分散式大數據運算,形成一個從單機到叢集皆可擴展的完整解決方案。
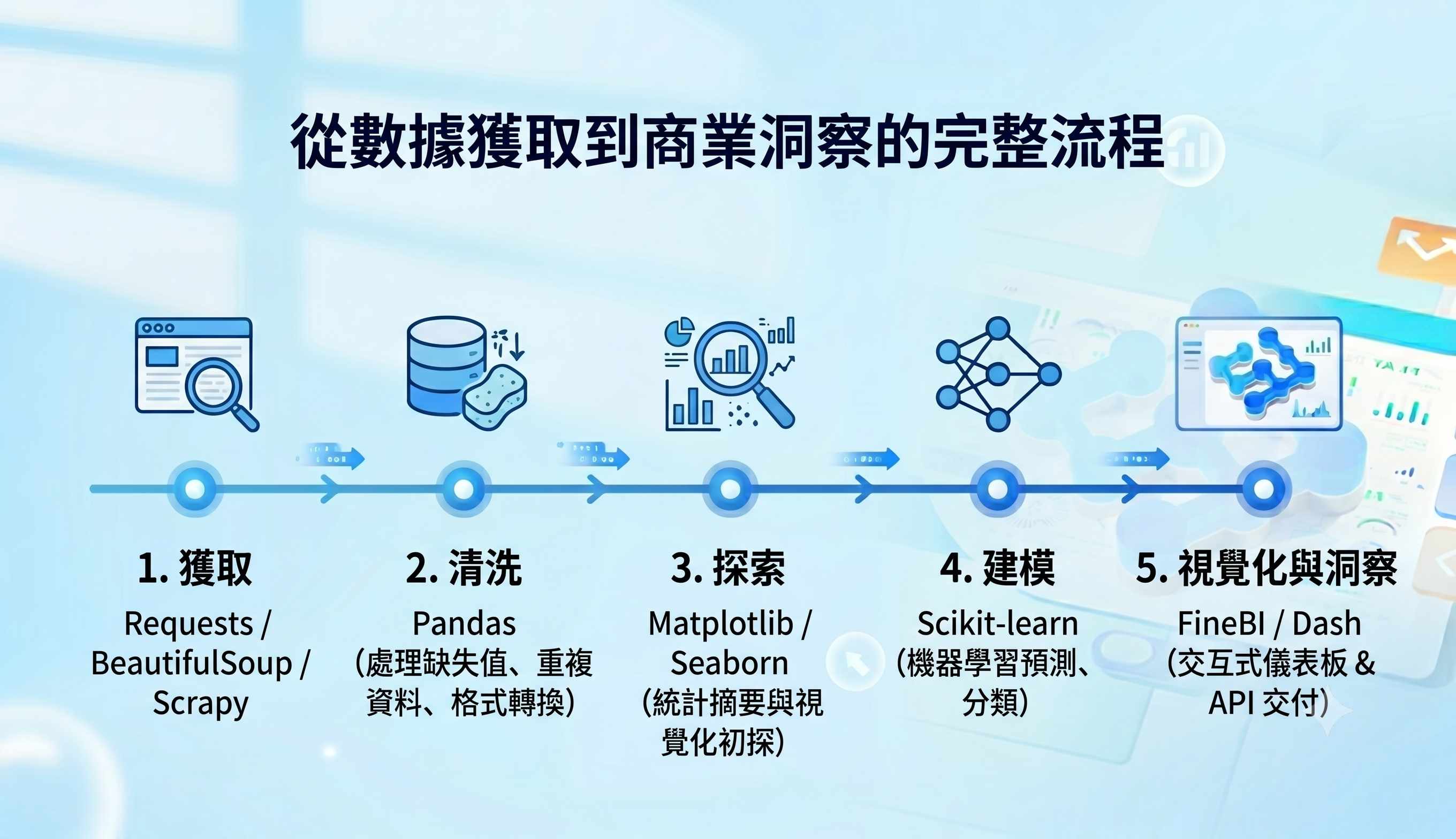
3. 從資料爬取到商業洞察的完整流程概述
一個標準的 Python 大數據分析流程包含五個階段:獲取(使用 Requests、BeautifulSoup、Scrapy 進行網路爬蟲)、清洗(使用 Pandas 處理缺失值、重複資料與格式轉換)、探索(進行統計摘要與視覺化初探)、建模(應用機器學習演算法進行預測或分類)與部署(將模型或洞察透過儀表板、API 交付)。Python 能一站式支援所有階段,確保流程連貫、可重現。
4. 產業實務:電商、金融與物聯網的python大數據應用案例
在產業實務中,Python 大數據分析已成為核心引擎。電商業者常用其分析用戶瀏覽與購買日誌,進行商品推薦與庫存預測;金融機構則運用時間序列分析偵測異常交易,並建立信用風險模型。在物聯網領域,Python 負責處理來自感測器的海量串流數據,進行即時監控與預測性維護。這些案例的共同點是,皆依賴 Python 高效處理結構與非結構化資料的能力,將原始數據轉為可行動的商業智慧。
二、資料獲取與處理:從爬蟲到資料清洗的實戰技巧
資料獲取與處理是分析的基石,其品質直接決定了後續洞察的可靠性。此階段目標是將原始、混亂的資料轉化為乾淨、可分析的結構化資料集。
1. 高效網路爬蟲設計與反爬蟲策略
設計高效爬蟲的重點在於遵守規則與提升穩定性。除了使用 Requests 與 BeautifulSoup 外,進階實務會採用非同步套件如 aiohttp 來提升大量頁面抓取速度。面對反爬蟲機制,工程師需要模擬瀏覽器標頭、管理 Cookies、設置請求延遲,或使用 Selenium 處理動態渲染的網頁。關鍵在於平衡資料獲取效率與對目標網站的尊重,避免造成對方伺服器負擔。
2. 結構化與非結構化資料的擷取與解析
資料擷取需應對多樣格式。對於結構化資料(如 CSV、JSON、關聯式資料庫),Python 的 Pandas 與 SQLAlchemy 提供了直接的讀取介面。對於非結構化資料(如網頁文本、PDF 文件、圖片),則需結合 BeautifulSoup 解析 HTML、PyPDF2 提取文字,或 OpenCV、PIL 處理影像資訊。解析的核心是將雜亂資訊轉為結構化欄位,以便後續分析。
3. 打通 Excel 到 Python 的橋樑:使用 Pandas 進行千萬級資料清洗
對於習慣使用 Excel 的業務人員,Pandas 是無痛進入 Python 大數據分析的關鍵。它可以輕鬆讀寫 .xlsx 檔案。然而,當資料量達數十萬甚至千萬列時,Excel 會變得緩慢甚至崩潰,而 Pandas 配合適當的記憶體管理技巧則能高效處理。常見的清洗操作包括:處理缺失值 (fillna, dropna)、移除重複資料 (drop_duplicates)、資料型別轉換 (astype)、以及使用向量化運算取代迴圈來提升處理速度,這些都是確保資料品質的必要步驟。

4. 資料品質驗證與異常值處理的最佳實務
資料清洗後必須進行品質驗證。最佳實務包括:檢查欄位數值範圍是否合理、驗證業務邏輯約束條件(例如,訂單日期是否晚於出貨日期)、並識別異常值。對於異常值,不宜盲目刪除,而應探究成因。可能是輸入錯誤,也可能是重要的極端事件(如詐騙交易)。Pandas 結合 Seaborn 的箱形圖可快速視覺化異常值,再根據領域知識決定修正、保留或剔除。
三、進階分析與建模:掌握python大數據的關鍵技術
當資料準備就緒,便可進入分析與建模階段,從中挖掘深層模式、關聯與預測未來趨勢。
1. 統計分析與探索性資料分析(EDA)方法
探索性資料分析是正式建模前的必要步驟,旨在透過統計與視覺化理解資料特性。使用 Pandas 的 describe() 可快速獲得分佈摘要,Seaborn 的 pairplot 或 heatmap 可檢視變數間的相關性。EDA 的重點是發現資料的分佈、偏態、以及潛在的群聚現象,這能為後續的特徵工程與模型選擇提供重要方向。
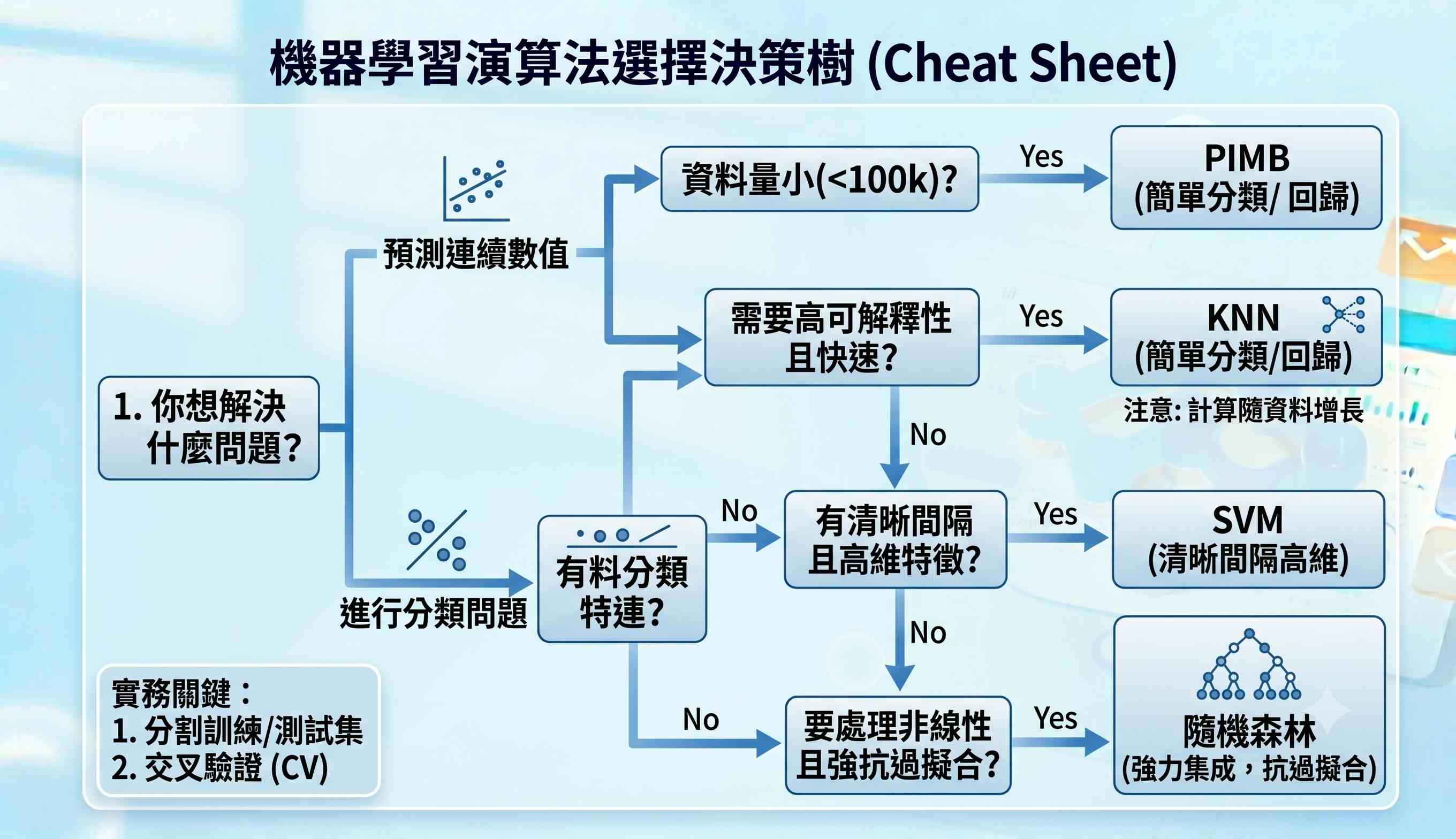
2. 機器學習預測實務:掌握 KNN、隨機森林與 SVM 等核心演算法
Python 的 Scikit-learn 庫讓機器學習實作變得直觀。對於初學者,應從核心演算法理解其應用場景:KNN 適用於簡單的分類與回歸,但計算成本隨資料量增長;隨機森林 作為集成學習方法,能有效處理非線性關係且抗過擬合能力強,是許多實務問題的強力基準模型;SVM 則在高維度空間中表現優異,特別適合於有清晰間隔的分類問題。實務關鍵在於正確分割訓練集與測試集,並使用交叉驗證評估模型泛化能力。
3. 時間序列分析與即時數據流處理
針對帶有時間標籤的數據,如銷售額、股價、感測器讀數,需採用時間序列分析。Pandas 提供了強大的時間序列索引與重取樣功能。對於預測,可使用 statsmodels 進行 ARIMA 建模,或使用 Prophet、深度學習模型如 LSTM。若涉及即時數據流(如物聯網、線上交易),則需引入 Kafka 搭配 PySpark Streaming 或 Faust 等框架進行即時處理與分析,實現低延遲洞察。
4. 產品切入段:整合FineBI提升大數據分析流程效率
在複雜的分析流程中,Python 負責繁重的資料處理與模型訓練,而將最終結果導入商業智慧工具如 FineBI,能極大化分析價值。分析師可在 Python 中完成資料清洗與指標計算,將處理好的結果 DataFrame 輸出至資料庫,再由 FineBI 直接連線進行直觀的拖拉拽式視覺化與儀表板製作。這種協作模式讓資料科學家專注於演算法,而業務分析師則能快速在 FineBI 中自由探索資料、製作報表,加速從分析到決策的循環。
四、資料視覺化與洞察呈現:溝通分析結果的藝術
再精闢的分析,若無法有效溝通,價值將大打折扣。資料視覺化是連結數據分析與商業決策的橋樑。
1. 使用Matplotlib與Seaborn製作專業圖表
Matplotlib 是 Python 視覺化的基石,高度靈活但需較多設定。Seaborn 建構於其之上,提供更高階的 API 與美學預設,能輕鬆繪製統計圖形(如分布圖、迴歸圖)。製作專業圖表的要點在於:選擇正確的圖表類型(趨勢用折線圖、比較用長條圖、組成用圓餅圖或堆疊圖)、精簡且明確的標籤、以及一致的色彩主題,避免圖表過於花俏而失焦。
2. 互動式視覺化:Plotly與Dash應用
靜態圖表適合報告,互動式視覺化則能提供更深入的探索體驗。Plotly 庫可以創造具備縮放、懸停顯示資料點等互動功能的網頁圖表。更進一步,使用 Dash 框架,分析師可以直接用 Python 建構完整的互動式網頁分析儀表板,無需精通 JavaScript。這使得複雜的分析結果能以更生動、更易於探索的方式呈現給終端使用者。
3. 建構儀表板:將python分析結果轉化為商業儀表
儀表板的核心是將關鍵績效指標與重要圖表集中於單一畫面,提供即時監控與決策支援。使用 Dash 或 Streamlit 可快速從 Python 腳本建立儀表板應用。設計時應遵循「由上至下」原則,將最重要的整體指標放在上方,細節資料與向下鑽研功能置於下方,並確保資料能定期或觸發更新,以維持儀表板的即時性。
4. 實務場景段:結合FineBI進行協作式商業智慧分析
在企業實務中,儀表板的維護與協作分享同等重要。將 Python 處理後的乾淨資料對接至 FineBI 這類專業 BI 平台,可以發揮更大效益。FineBI 提供了強大的協作功能,團隊成員可基於同一數據來源,根據各自權限製作與分享儀表板。其自助式分析功能允許業務人員在不寫程式的情況下,自由篩選、鑽取、組合維度與指標,實現真正的「全民資料分析」。這種 Python + FineBI 的組合,兼顧了專業建模的深度與商業洞察的普及速度。
五、完整學習路徑圖與資源規劃
掌握 Python 大數據分析需要系統性學習與持續實作。以下提供一條清晰的路徑規劃,助你從新手穩健成長為實戰專家。
1. 對齊業界標準:TQC 大數據認證考綱指南與學習資源地圖
TQC 大數據認證等專業考試的考綱,可作為檢驗學習成果的良好參考。它通常涵蓋資料處理、統計分析、視覺化與機器學習基礎。學習者可依據考綱查漏補缺。學習資源地圖建議如下:從 Codecademy、Coursera 的 Python 入門課開始,接著學習「Python for Data Analysis」掌握 Pandas,再到 Udemy 或國內平臺的實戰專案課程,同時大量閱讀官方文件與 Scikit-learn、Matplotlib 的使用指南。
2. 專案導向學習:從零到一的實作規劃建議
理論學習必須搭配實作。建議規劃一系列由淺入深的專案:
- 初階:針對公開資料集(如政府開放資料、Kaggle 入門賽題)進行完整的 EDA 與視覺化報告。
- 中階:自選主題(如電商商品評論、社群媒體趨勢)進行網路爬蟲、建立資料管道、並執行情感分析或主題模型。
- 高階:選擇一個預測性問題(如房價預測、客戶流失預測),從資料獲取、特徵工程、模型訓練與調參,到最終部署為簡易的 Web API 或儀表板。
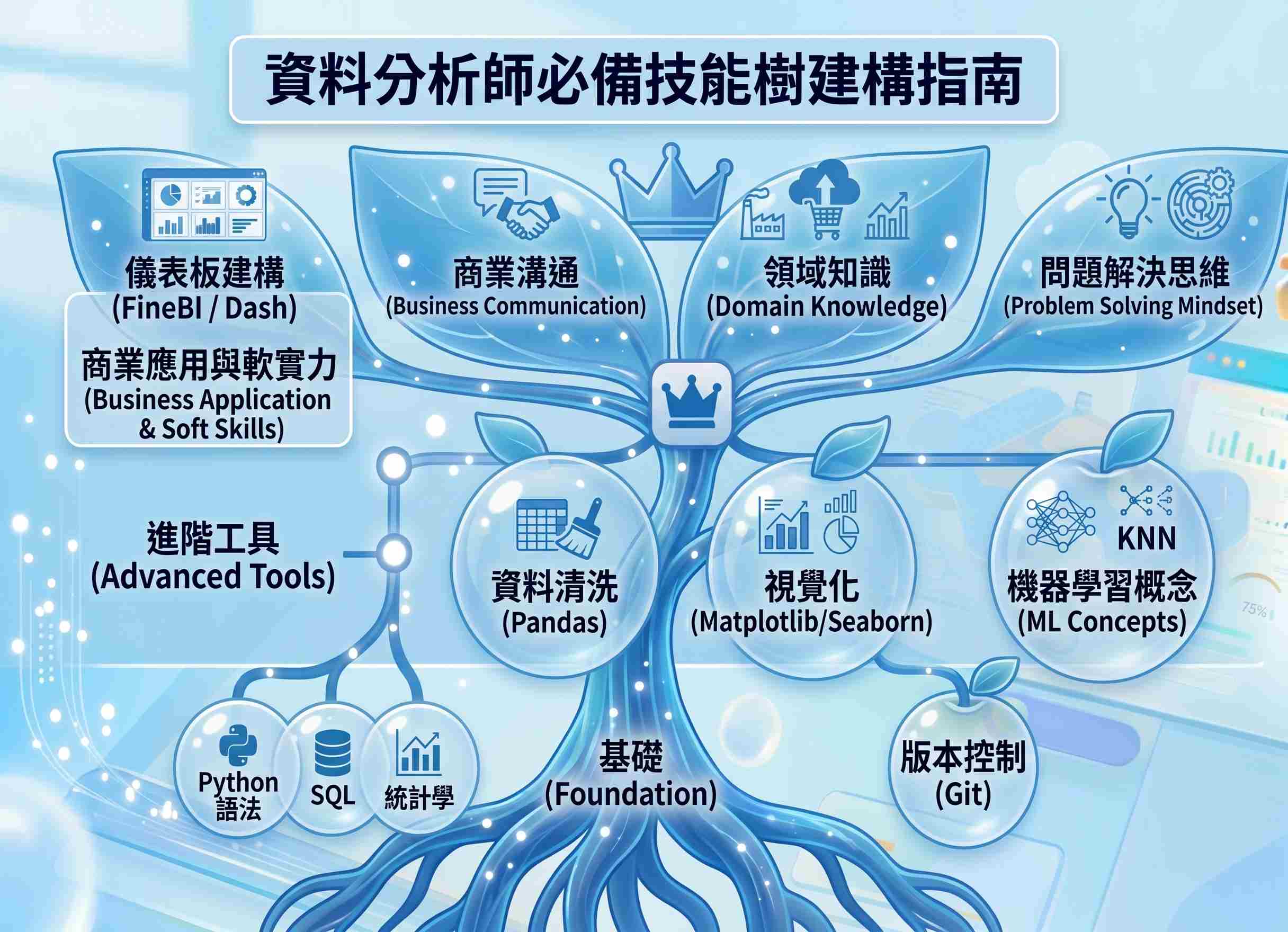
3. 職涯發展與技能樹建構指南
Python 大數據分析能力能開啟多種職涯路徑,包括資料分析師、資料科學家、商業智慧工程師等。建構技能樹時,除了精進 Python 與相關函式庫,也應橫向擴展:理解資料庫與 SQL、熟悉雲端平台服務、掌握版本控制工具 Git,並培養紮實的領域知識與溝通能力。技術會演進,但透過資料解決問題的核心思維與持續學習的習慣,才是職涯長期發展的關鍵。
FAQs
Python語法簡單易學,且擁有如Pandas、NumPy、Scikit-learn等龐大且完整的開源函式庫生態系,能一站式涵蓋從資料爬取、清洗、分析到機器學習建模的完整流程,大幅降低技術門檻與協作成本。
可以使用Pandas函式庫來讀取Excel檔案,它能高效處理Excel無法負荷的海量資料。關鍵在於運用向量化運算取代迴圈,並善用記憶體管理技巧來處理缺失值、刪除重複資料及轉換資料型別,以確保清洗效率與資料品質。
一個標準流程包含五個階段:資料獲取(如網路爬蟲)、資料清洗與處理、探索性資料分析、機器學習建模,以及最終的結果視覺化與洞察部署,Python能提供完整的工具鏈支援所有階段。
建議從公開資料集進行探索性分析與視覺化開始,進階則可進行網路爬蟲專案建立資料管道,高階則可挑戰預測型專案,如房價或客戶流失預測,並完成從特徵工程、模型訓練到部署為API或儀表板的完整流程。
除了使用Matplotlib、Seaborn製作靜態報告圖表,更能利用Plotly、Dash或Streamlit建立互動式網頁儀表板。實務上也可將處理好的數據輸出至商業智慧工具如FineBI,讓業務人員能進行自助式拖拉拽分析與協作分享,加速決策循環。







免費資源下載