Python 數據分析是指利用 Python 語言及其函式庫,進行資料獲取、清理、分析到視覺化的完整流程。它的核心價值在於處理 Excel 無法負荷的巨量資料、執行複雜的統計模型,並將重複性高的分析工作自動化,從而提煉出支持商業決策的深度洞察。
這篇文章將以顧問視角,完整解析 Python 數據分析的定義、商業價值,以及它如何解決 BI 工具難以處理的複雜問題。我們將聚焦於它如何賦能分析師,將您從「拉報表的角色」轉變為「提供商業洞察的策略夥伴」,並說明它如何與 FineBI 等工具協作,最大化數據價值。

一、Python 數據分析的完整定義與流程
Python 數據分析是利用 Python 程式語言及其開源生態系,將原始數據轉化為商業洞察的系統化過程。對分析師而言,它不僅是寫程式,更是一套解決複雜商業問題的思維框架,能以可重複、可擴展的方式,處理從數據獲取到洞察產出的完整流程。
1. 核心定義:從數據到可操作洞察的橋樑
Python 數據分析的核心,是應用 Python 及其函式庫(如 Pandas, NumPy)進行資料獲取、清理、轉換、分析、建模與視覺化的過程。其最終目標非常明確:將雜亂的原始數據,提煉成能支持精準商業決策的「可操作洞察」(Actionable Insights),回答「為什麼發生」與「未來會如何」等關鍵問題。
2. 標準化工作流程:數據分析的 5 個階段
一個專業的 Python 數據分析專案,會遵循標準化的工作流程以確保分析的嚴謹性與可重現性。這五個階段是解決商業問題的通用框架:
- 資料獲取 (Data Acquisition):從多樣來源取得資料,如讀取 CSV/Excel、透過 SQL 連接資料庫、呼叫外部 API,或利用網路爬蟲獲取公開資訊。
- 資料清理與預處理 (Data Cleaning & Preprocessing):此階段最為耗時但至關重要,約佔據專案 80% 的時間。工作包含處理遺失值、修正格式錯誤、移除重複項,確保數據品質。
- 探索式資料分析 (Exploratory Data Analysis, EDA):透過統計摘要和視覺化圖表,快速理解資料分佈、找出異常值,並發掘變數間的潛在關聯,為後續建模提供方向。
- 模型建立與特徵工程 (Modeling & Feature Engineering):根據業務問題應用統計或機器學習模型,如建立銷售預測或客戶流失預警模型。同時,也可能從現有數據創造新變數(特徵)來提升模型準確度。
- 資料視覺化與溝通 (Data Visualization & Communication):將分析結果製作成清晰圖表,並撰寫報告,向管理層或業務團隊有效溝通發現與建議。
3. 在企業工具中的定位:Excel 與 BI 平台間的數據中樞
在企業的數據工具版圖中,Python 扮演著承先啟後的「數據中樞」角色。它完美銜接了輕量級的 Excel 和專注於視覺化呈現的 BI 平台,彌補了兩者在深度數據處理上的不足。Python 並非要取代它們,而是成為其強力夥伴,負責處理最複雜的底層數據準備與建模工作。
二、為什麼資料分析師該學 Python?與 Excel、SQL 的根本差異
當分析師需要回答「為什麼」、「未來會如何」等深入問題時,會發現單靠 Excel 和 SQL 往往力不從心。企業在數據分析場景的最大挑戰,是處理日益增長的數據量與分析複雜度,而 Python 提供的彈性、可重現性與擴充性,正是突破職涯瓶頸的關鍵。
1. Excel 的天花板:巨量資料、複雜邏輯與自動化的瓶頸
Excel 是出色的入門工具,但其天花板非常明顯。當資料量超過百萬筆或分析邏輯變得複雜時,Excel 的瓶頸就會浮現。例如,分析超過 2GB 的用戶行為日誌時,Excel 可能直接崩潰。若每月重複此分析,手動操作不僅效率低下且極易出錯,而 Python 的 Pandas 函式庫能輕鬆處理千萬筆資料,並將流程寫成可重複執行的腳本。
2. SQL 的侷限:擅長取數彙總,難以執行進階統計與建模
SQL 是從資料庫取數的王者,然而其核心功能是資料查詢與彙總,對於進階分析任務則力不從心。例如,預測客戶流失率時,SQL 可以撈取歷史數據,卻無法直接建立羅吉斯迴歸模型來計算流失機率。實務上,分析師會用 SQL 取數,再交由 Python 進行建模分析,兩者完美協作。
3. Python 的核心優勢:高度彈性、可重現性與銜接 AI 的能力
Python 之所以成為現代資料分析師的必備技能,是因為它提供了 Excel 和 SQL 無法比擬的核心優勢。根據 O'Reilly 的調查,Python 長期以來都是數據科學領域最受歡迎的語言,這使其成為一項高回報的職涯投資。
| 比較面向 | Python | Excel | SQL |
|---|---|---|---|
| 資料量處理 | 幾乎無上限,受限於記憶體 | 有 104 萬列的硬性限制 | 擅長處理資料庫內的大量數據 |
| 自動化能力 | 極高,可排程執行完整分析流程 | 有限,依賴 VBA,彈性較差 | 主要用於數據庫內的排程任務 |
| 分析複雜度 | 極高,支援統計、機器學習、AI | 中等,限於內建函數與樞紐分析 | 偏低,主要為彙總與聚合 |
| 可重現性 | 極高,程式碼即文件,結果可被驗證 | 偏低,點擊操作難以追溯與重現 | 高,查詢語句清晰 |
| 生態系與擴充 | 極其豐富,海量開源函式庫 | 封閉,依賴官方與第三方增益集 | 侷限於資料庫本身的功能 |
三、Python 能解決哪些 BI 工具難以處理的商業問題?
BI 工具在互動式儀表板上非常強大,但許多深度商業問題,需要在數據進入 BI 前就透過 Python 進行複雜的處理與建模。Python 就像是 BI 工具的「數據前處理與增強引擎」,為前端分析提供更高品質的資料來源。
1. 行銷成效分析:建立客製化歸因模型與顧客分群
標準 BI 工具通常只提供「最終點擊歸因」,這會嚴重低估行銷旅程前期的渠道價值。利用 Python,分析師可以串接各平台 API,建立客製化的多觸點歸因模型,更公平地評估 ROI。同時,還能基於用戶行為進行 RFM 顧客分群,為 BI 工具提供更精準的分析維度。
2. 銷售預測與客戶管理:建立流失預警與 LTV 預測模型
BI 儀表板能呈現「已經流失」的客戶,卻無法主動預測「未來可能流失」的高風險客戶。數據分析師可使用 Python 整合客戶行為數據,建立流失預警模型,為每位客戶計算「流失風險分數」,讓業務團隊能優先關懷高風險客群,實現從被動反應到主動預防的轉變。
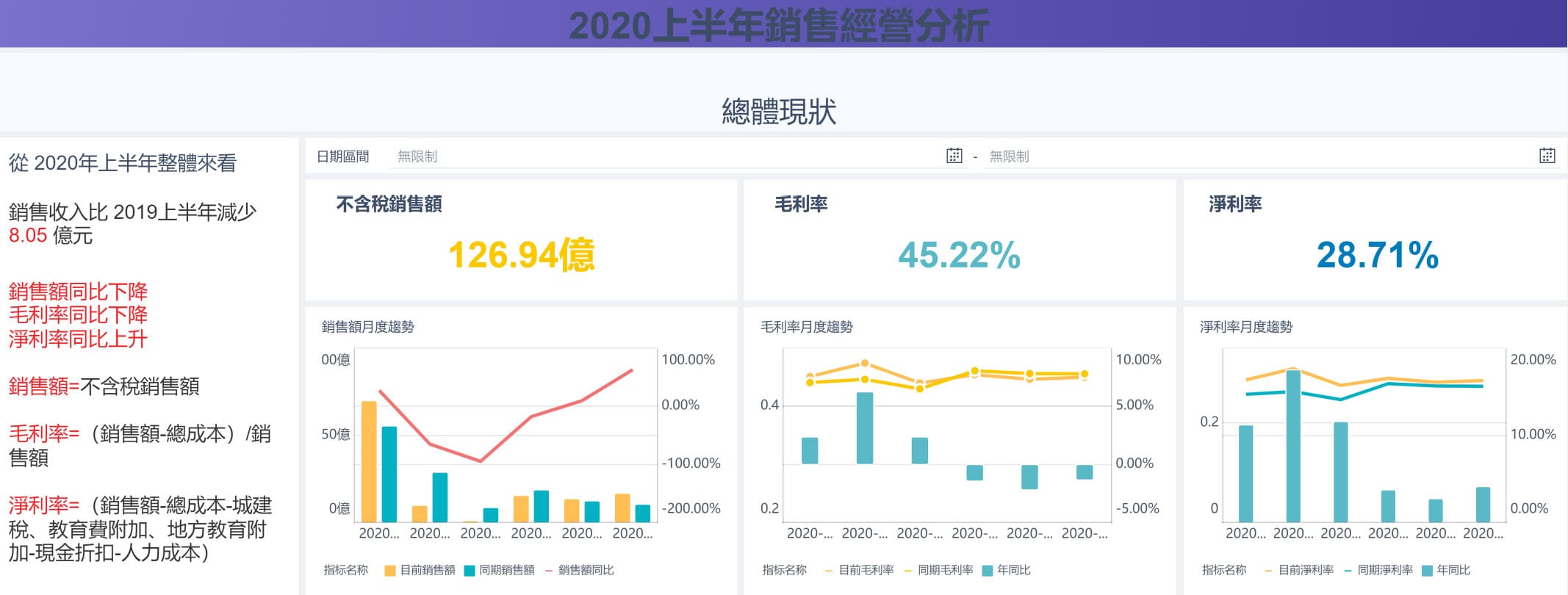
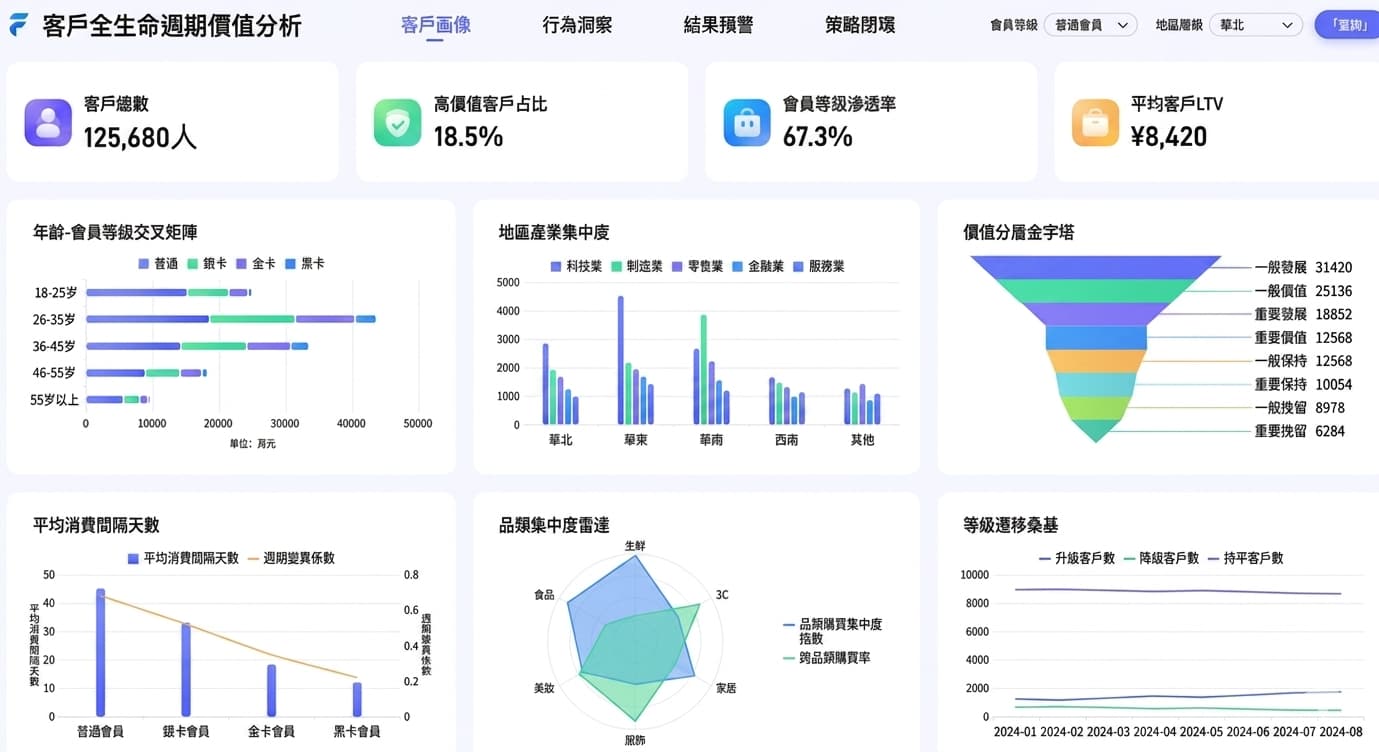
3. 營運效率優化:自動化產出每日業績報表與供應鏈分析
許多企業分析師每天需花費 1-2 小時從不同系統下載 Excel,手動製作報表。透過 Python 撰寫自動化腳本,可設定在每日凌晨自動抓取資料、合併計算,並生成報表寄送給主管。根據產業觀察,導入自動化流程後,分析師平均可將 30% 的手動作業時間,轉移至高價值的洞察分析工作。
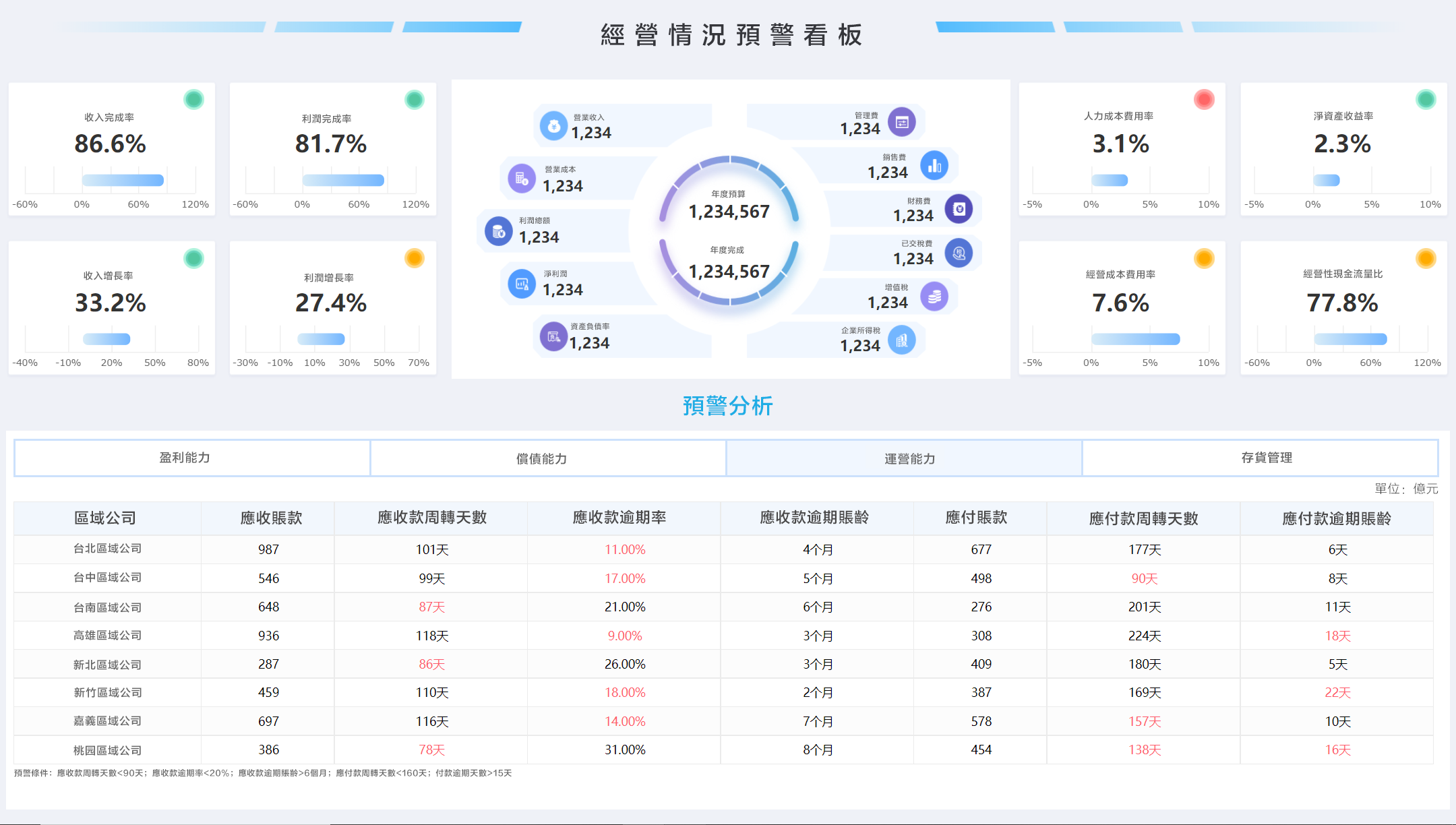
四、導入 Python 數據分析前需要克服的學習門檻
企業或個人在導入 Python 數據分析時,最大的挑戰是從視覺化操作轉向程式碼邏輯的思維轉換。雖然 Python 優勢眾多,但從習慣 Excel 或 BI 工具的圖形介面,到以程式碼為主的分析模式,確實存在一條學習曲線。提前了解這些挑戰,有助於更順利地度過轉型期。
- 程式思維轉換:從「點擊哪個按鈕」的視覺化思維,轉換為「如何用指令告訴電腦做什麼」的邏輯化思維,是初期的最大挑戰。
- 環境設定與套件管理:安裝 Python、設定虛擬環境、處理套件版本衝突,是新手最常見的「撞牆期」。使用 Anaconda 等發行版可大幅簡化此流程。
- 核心函式庫的學習曲線:掌握 Pandas 的 DataFrame 操作邏輯,如索引、資料對齊、鏈式呼叫等,需要投入專門時間學習,這是區分新手與專業分析師的關鍵。
- 理解執行效能:Python 作為直譯語言,執行速度相對較慢。雖然對多數商業分析已足夠,但在需要毫秒級響應的高頻交易等極端場景,則需搭配其他技術優化。
五、開始 Python 數據分析的必學工具與函式庫
踏入 Python 數據分析的世界,選對工具可以事半功倍。以下是業界公認的標準配備,幾乎是每位資料分析師的起手式,構成了一個高效的數據分析工作流程。
-
互動式開發環境:Jupyter Notebook Jupyter Notebook 是一個互動式的網頁開發環境,允許將程式碼、執行結果、文字說明和圖表整合在同一文件中,是進行探索式資料分析 (EDA) 的業界標準。
-
核心資料處理函式庫:Pandas 與 NumPy Pandas 提供了 DataFrame 資料結構,是 Python 世界的超級 Excel,負責所有表格型資料操作。NumPy 則是高效能科學計算的基礎,許多 Pandas 的底層運算都依賴它。
-
主流資料視覺化工具:Matplotlib 與 Seaborn Matplotlib 是最基礎、最靈活的視覺化函式庫,提供極高的客製化彈性。Seaborn 基於 Matplotlib 封裝,能用更簡潔的程式碼畫出更美觀的統計圖表,是商業分析的首選。
-
機器學習函式庫:Scikit-learn 當需要進行預測性分析時,Scikit-learn 是功能強大且語法一致的機器學習函式庫,涵蓋分類、迴歸、分群等常見演算法,是從資料分析師邁向資料科學家的必經之路。
六、Python 如何與 BI 工具協作,提升企業決策效率
Python 與 BI 工具的關係是相輔相成,而非互相取代。一個高效的數據分析流程是讓 Python 負責複雜的「後端」數據工程與建模,而 BI 工具專注於「前端」的視覺化探索與分享,讓不同職能的員工都能從數據中獲益。
1. FineBI:承接 Python 處理後的乾淨數據,實現業務端自助式探索
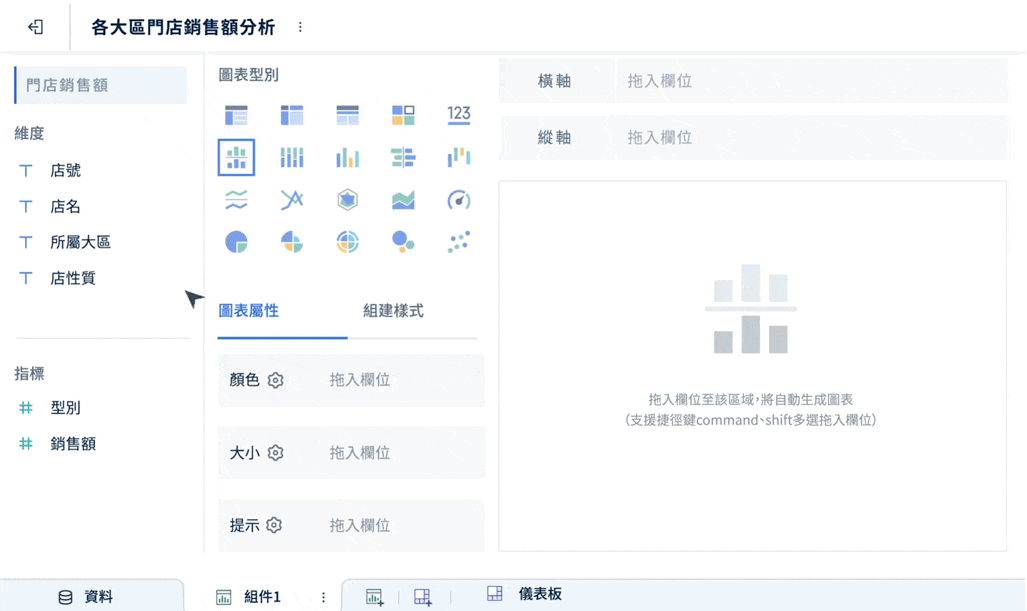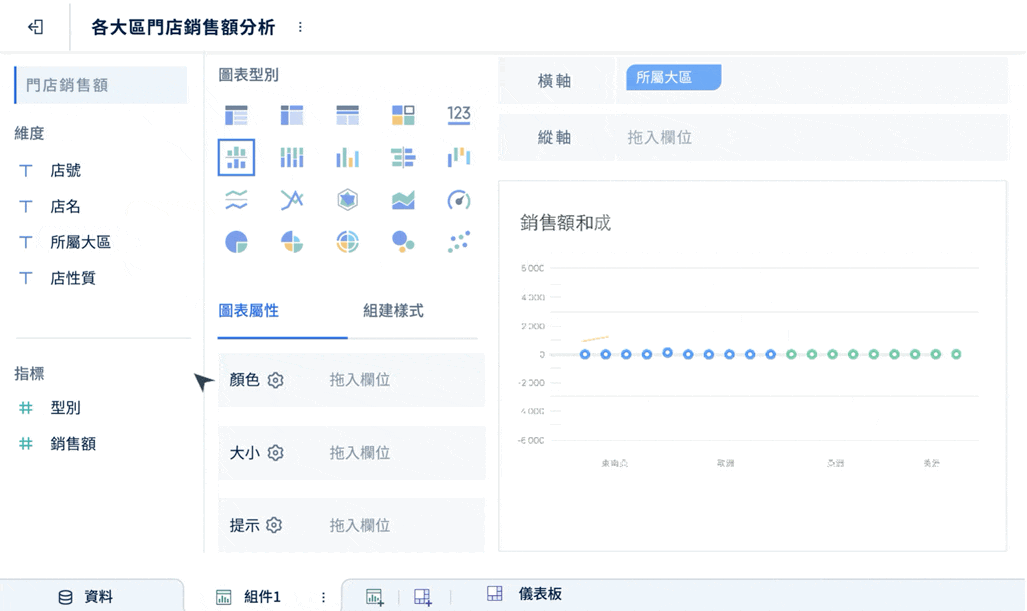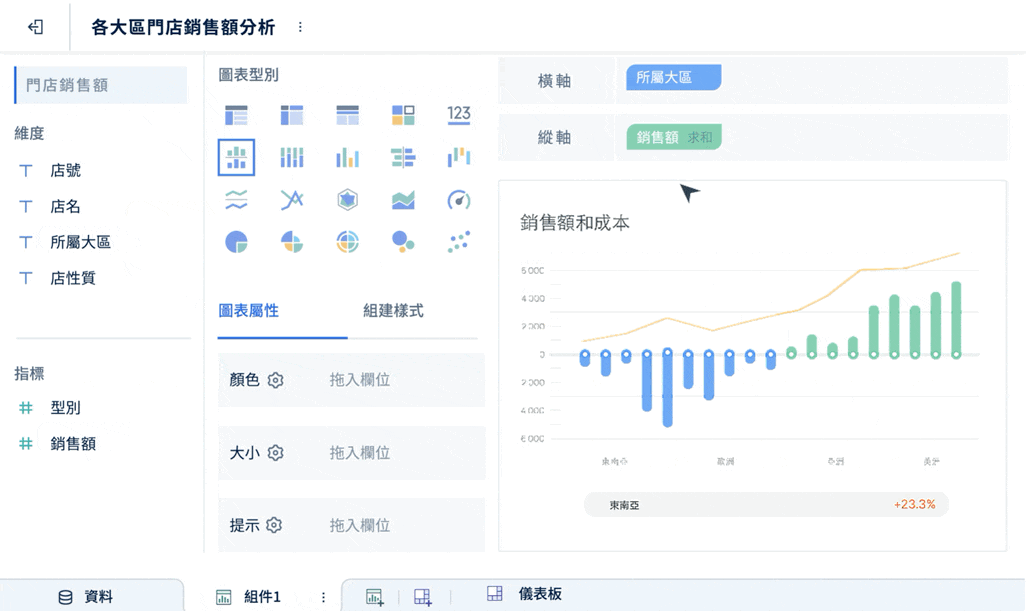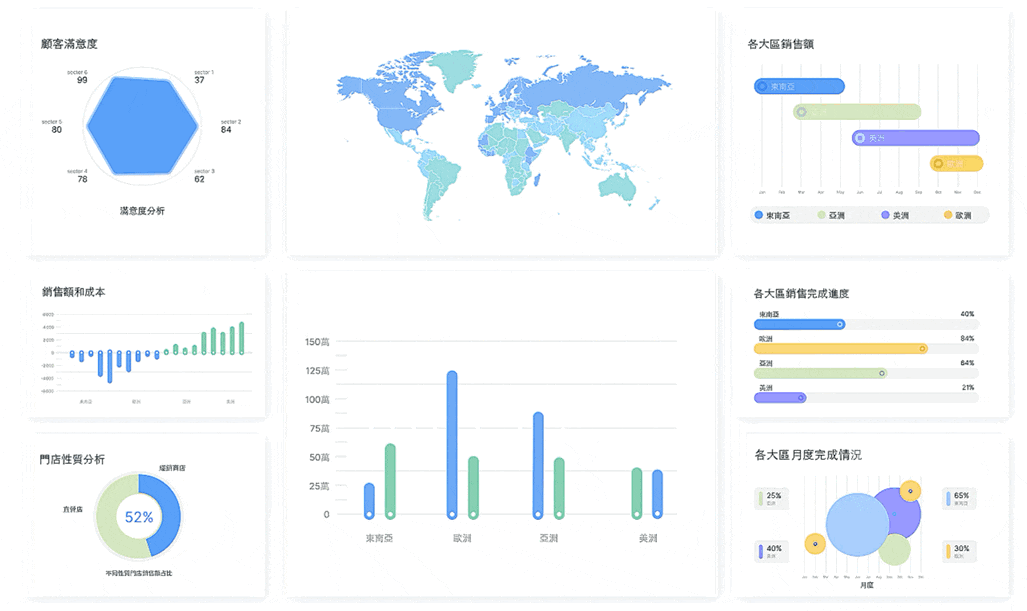
Python 建模產出的客戶 LTV 分數、流失風險評分等高品質數據,可以存回資料庫。這時,像 FineBI 這類的自助式 BI 工具就能發揮巨大作用。行銷或業務經理不需撰寫程式碼,即可直接連接數據源,透過拖拉點選的方式,自行建立儀表板,從不同維度下鑽分析。Python 負責產生高品質的「食材」,FineBI 則提供了讓業務人員輕鬆「烹飪」的廚房。
2. FineReport:將 Python 分析結果,自動化產出為複雜固定格式報表
對於格式固定、需要大規模分發的報表(如生產良率報告、財務月報),BI 工具的彈性反而成為限制。這時企業級報表工具 FineReport 更為適合。IT 人員可利用其類 Excel 設計器,將 Python 的分析結果整合進符合嚴格規範的報表範本中,並設定排程自動生成 PDF 或 Excel,穩定地傳遞到每個管理節點。
七、新手學習 Python 的三大常見誤區
許多分析師在學習 Python 時,常因方法不當而事倍功半。要成功將 Python 應用於工作,關鍵在於建立正確的學習心態與路徑,避免以下三個常見的誤區,才能將學習時間轉化為實際的生產力。
-
誤區一:為學而學,缺乏商業問題驅動
- 錯誤作法:從頭到尾看語法教學,卻未思考「這能解決我工作上的哪個痛點」。
- 正確作法:從一個具體工作痛點出發,例如「自動合併每週的 5 個 Excel 檔」。以解決問題為目標,學習路徑會更清晰,成就感也更強烈。
-
誤區二:沉迷複雜演算法,忽略資料清理與業務理解
- 錯誤作法:一頭栽進深度學習等酷炫模型,卻對公司業務與數據來源一知半解。
- 正確作法:先將基本功做扎實,熟練掌握 Pandas 進行資料清理,並花時間與業務部門溝通,深刻理解數據的商業意涵。高品質的數據搭配簡單模型,效果常勝過髒數據搭配複雜模型。
-
誤區三:試圖用 Python 取代所有工具
- 錯誤作法:認為學了 Python 後,Excel、SQL 和 BI 工具就再也用不上。
- 正確作法:建立「工具組合」思維。用 SQL 高效取數,用 Python 進行複雜處理與建模,用 BI 工具進行視覺化探索與分享。聰明的分析師懂得根據任務選擇最適當的工具。
總結來說,Python 數據分析不僅是一項技能,更是一種賦能分析師解決複雜商業問題的思維方式。當企業的數據應用從「看報表」走向「智慧決策」時,Python 正是串連起數據、模型與商業洞察的關鍵橋樑。當您將 Python 清理和建模後的數據,交由 FineBI 這類工具進行視覺化探索時,就能真正實現數據驅動的閉環。
FAQs
對於想在業界發展的資料分析師,優先學習 Python 通常是更穩妥的選擇。Python 是一門通用型語言,除了數據分析,還能無縫應用於網站開發、自動化腳本等領域,讓企業在招募與團隊協作上更具彈性,職涯發展也更廣。
取決於您的職涯目標。若工作主要是製作固定儀表板,精通 SQL 和 BI 已足夠。但若想處理更複雜的專案,如建立預測模型、執行深度診斷分析或將流程完全自動化,學習 Python 是突破職涯天花板、從「數據呈現者」轉變為「價值創造者」的必經之路。
是的。Low-Code 工具在處理標準化任務時非常高效,但 Python 的核心價值在於其無可比擬的「彈性」與「客製化深度」。當您需要處理獨特的業務邏輯、串接非標準 API 或建立客製化演算法時,Python 提供了 Low-Code 工具無法企及的終極解決能力。







免費資源下載