来看看相对成熟的BI工具有什么?
我更喜欢数据分析用BI,BI数据可视化
如今,有大量功能强大的可视化工具和BI工具能快速的实现数据可视化,帮助业务分析推动决策。
在本文中,笔者将比较近两年国内外市场份额较高,也是相对成熟的BI工具,对比其主要功能,为个人使用或企业IT工具选型提供一个参考。
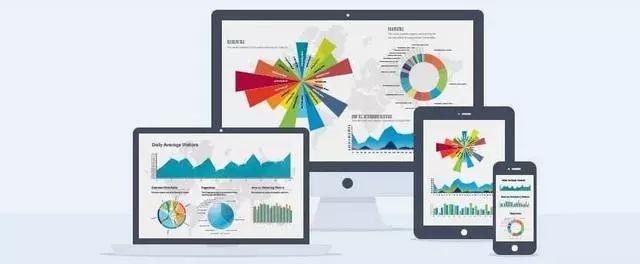
在搜索商业智能(BI)工具时,可能每个BI供应商都将其产品称为唯一的“最佳”解决方案进行宣传,晕乎转向。笔者身边有很多在数据中心工作的朋友,也有各种IT信息部的大佬,也见惯了各家上门兜售产品的厂商。所以对BI产品的好坏,各中优劣有所了解。也恰逢前阵子在整理一些相对成熟的BI工具产品资料,便有了下文。如果你想了解功能性产品的真实价值,避免被大肆宣传的广告和评论误导,那你来对地方了。
比如FineBI就很好用
FineBI
FineBI是列表中唯一上榜的国产BI工具,帆软公司的。
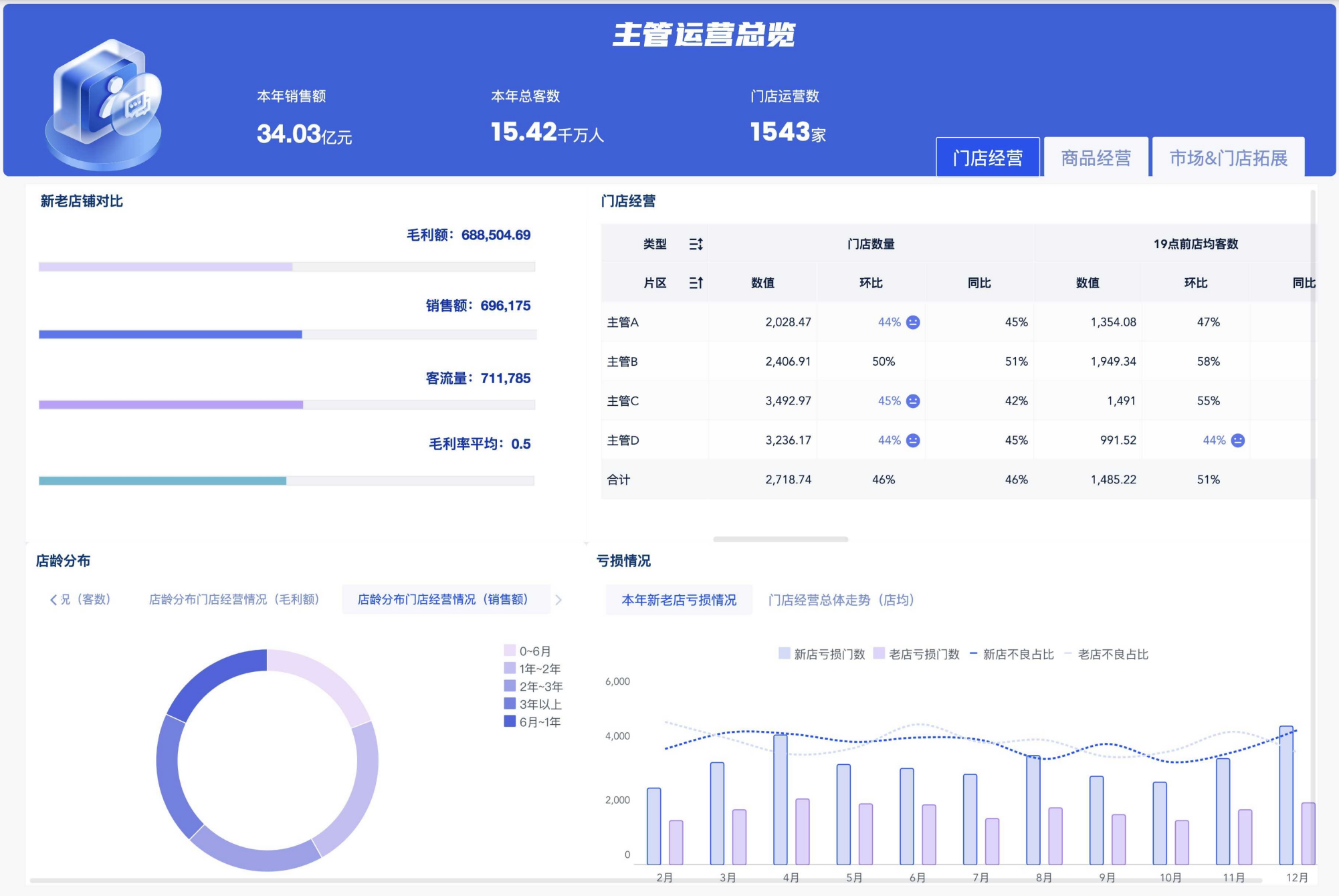
FineBI是一套企业数据化管理和可视化BI的方案,意思是在具备可视化BI功能的同时,又侧重于帮助企业打造数据化管理的一个应用。从其使用流程中可以看出:分别为管理员创建业务包(准备数据),业务人员新建仪表板(可视化和探索性分析),业务人员新建螺旋分析(前端再处理数据),领导查看分析(对外分享报告)。
创建业务包就是准备数据,这个工作一般让信息部去做,把数据转化成业务分析人员可理解的数据(一般会准备大而全的明细数据)。然后,业务人员拿着业务包里的明细数据,根据需求做分析,比如做一个销售dashboard,分析每个产品、每个地区、每个销售员的销售情况综合判断。在没有分析目标的情况下,可以尝试探索性分析,甚至数据挖掘:聚合、预测等,都有现成的模型。
产品差异化
FineBI连接数据的方式,包括直接对接数据库的实时数据引擎,和抽取数据的引擎,统称为Spider计算引擎。用户可以根据数据量、实时性要求、使用频次等,自由选择实时或抽取的方式。实时数据与抽取数据方式的无缝切换,将更加灵活高效支撑前端的大数据量高性能分析。
Spider数据引擎可灵活支撑不同数据量级的分析,在数据量激增之后,可横向扩展机器节点,利用Spider引擎专为支撑海量大数据分析而生的分布式方案。
Spider引擎分布式方式,结合Hadoop大数据处理思路,以最轻量级的架构实现大数据量高性能分析。此分布式方案集成了Alluxio 、Spark、 HDFS、zookeerer等大数据组件,结合自研大数据量高性能分析算法,列式存储、并行内存计算、计算本地化加上高性能算法,解决大数据量高性能分析问题与在FineBI中快速展示的问题。同时从架构上保证了计算引擎系统全年可正常使用。
优势:
(1)引擎支撑前端快速地展示分析,真正实现亿级数据,秒级展示。
(2)用户可以根据数据量、实时性要求、使用频次等,自由选择实时或抽取的方式,灵活满足实时数据分析与大数据量历史数据分析的需求。
(3)抽取数据的高性能增量更新功能,可满足多种数据更新场景,减少数据更新时间,减少数据库服务器压力。
(4)合理的引擎系统架构设计可保证全年无故障,全年可正常使用。
特性
FineBI可以自动关联数据表之间的关系,通过键自动建模。
再者与其他不同BI工具不同的是,FineBI有移动端、PAD端、以及大屏。
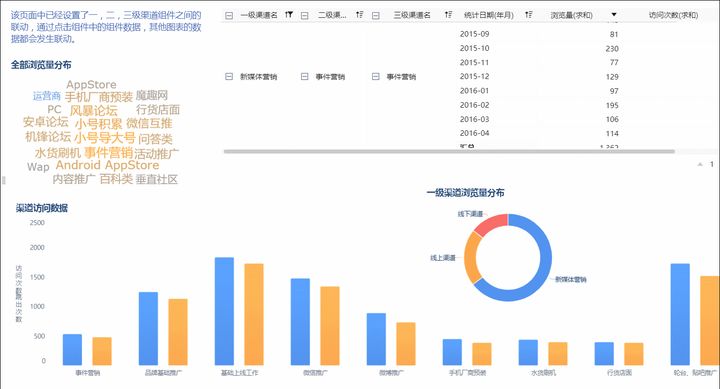
FineBI还有类似办公协同软件OA的一套数据协同管理,主要出于数据安全考虑。可以设置部门只能看部门内的数据,个人只能看个人权限范围内的数据,dashboard制作完分享给别人时,也可以指定分享给谁,被分享者收到通知后登录门户时,可以看到报表出现在桌面中,然后修改、批注。笔者觉得这一点好太多,尤其是出于数据安全的考虑,更能适应本土化的需求。
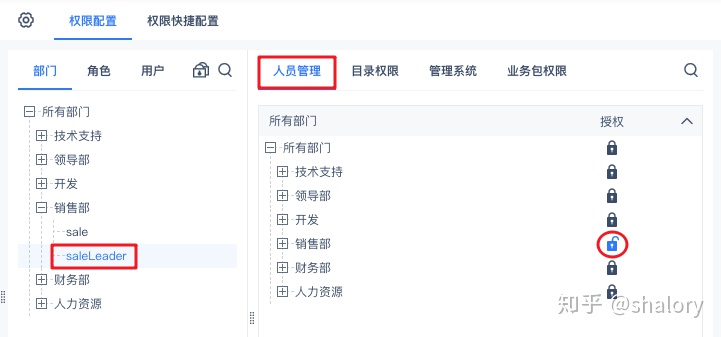
可用性
FineBI属于自助式BI,使用简单,具有丰富的可视化和前端分析操作,能可视化地进行数据钻取,数据切片和数据旋转等多维分析操作。前端探索性分析操作类似Tableau。配合帮助文档和教学视频能轻松上手,无需付额外培训费用驻场培训。
定价
FineBI的定价不同于其他产品按年按人数付费,FineBI是按照功能模块买断,多维数据库引擎、决策门户、OLAP分析组件、管理驾驶舱等功能组件,类似于电话的自选套餐,一般企业的产品整体打包价格几十万。



 立即沟通
立即沟通