数据集成是什么?为什么这么难?来点数据集成平台推荐!
一、数据集成是什么意思?
想象一下,你进入了一个房间,到处都散落着不同的拼图碎片,每个碎片上都绘有一幅图案。如果你想要看到完整的图案,你会怎么做呢?是不是要把所有的碎片都集中在一起,把它们逐一拼接起来,完成整幅拼图?这正好对应了数据集成的概念——将多个不同来源的数据汇集到一个中央仓库中,形成一个供企业与组织依赖的“真实单一数据源”,以获得统一且更有价值的全局数据视图。
在企业制定数字化转型策略时,数据集成显得尤为重要,因为要想改善运营、降本增效、提高客户满意度,并在日益数字化的世界中进行竞争,就需要对所有数据进行系统地挖掘与分析。
二、数据集成为什么这么难?
如今各大企业拥有大量的 OA、CRM、ERP、WMS、PLM 以及 SaaS 等系统,他们并不连通,形成了数据壁垒,无法进行有效的数据联合分析,导致数据无法发挥其最大价值。而数据集成的四大难点,分别为:数据采集时效低、数据处理效率低、人工开发和维护成本高、数据管理难度大。
1、数据采集时效低
根据不同业务场景,数据采集一般分为离线数据采集和实时数据采集:
- 离线数据采集主要包括从数据库中采集,如MySQL、Oracle、MongoDB等。每天凌晨会抽取前一天的数据(T+1),对于维度数据一般采用每次全量采集,对于业务数据,采用每天增量采集,然后将T+1的数据合并成新的全量数据。
- 实时数据采集主要是一些页面日志的采集,也就是我们常说的用户行为分析数据。用户的每个操作都会产生一个操作日志,但并不是每生成一条日志就实时上报至服务器,而是在产生日志后,先暂存在客户端本地,再结合着相应的上报控制策略进行数据上报。
在数据分析应用过程中,海量数据的分析计算及分析报告生成需要强大的算力支持,而数据ETL的时候也需要数小时才能完成,故而很多分析场景中,为了保证系统的稳定运行,会牺牲一定的时效性。但是在实际业务中,越好的时效性保证,越能尽快地发现问题并及时应对。所以,数据的时效性可谓决定了企业的行动力与竞争力。
2、数据处理效率低
1)字段定义或指标口径不一致
在整合数据源的过程中,很可能出现这些情况:
- 两个数据源中都有一个字段名字叫“Payment”,但其实一个数据源中记录的是为员工发放的薪水,另一个数据源中是应收账款的还款。
- 两个数据源中都有一个字段名字叫“Salary”,但其实一个数据源中记录的是为员工税前工资,另一个数据源中是员工税后实际工资。
上面这两种情况是在数据集成中常发生的,造成这个问题的原因在于现实生活中语义的多样性以及公司数据命名规则的不统一。
2)字段结构不一致
数据结构问题的产生是数据集成中几乎必然会产生的。在整合多个数据源时,这样的问题就是数据结构问题:
- 字段数据类型不同。如,同样是为员工发放薪水的Salary字段,一个数据源中存为INTEGER型,另一个数据源中存为CHAR型。
- 字段数据格式不同。如,同样是为员工发放薪水的Salary数值型字段,一个数据源中使用逗号分隔,另一个数据源中用科学记数法。
- 字段单位不同。如,同样是为员工发放薪水的Salary数值型字段,一个数据源中单位是人民币,另一个数据源中是美元。
这类问题,均拖低了企业数据工程师进行字段合并、数据整合的效率!
3)数据的冗余与重复
- 数据冗余:如果一个属性能由另一个或另一组属性值推导出,则这个属性可能是冗余的。
- 数据重复:数据收录过程中,会出现两个不同字段指代同一个属性的问题:如数据集成中一个数据库中的customer_id和另一数据库中的cust_no是指相同的属性。
过多的冗余可能会导致不一致、效率低下、时间延迟以及存储空间和处理能力成本增加。确保数据的准确性和完整性,同时最大限度地减少冗余是设计和实施高效数据库系统的重要考虑因素。
3、人工开发和维护成本高
1)数据开发周期长、工作量大
传统的数据集成工具开发流程,首先需要在目的端创建数据表,其次通过工具进行数据表字段类型的映射、选择增量或全量同步规则和编写清洗规则,最后将开发好的任务配置发布到调度 Sequence 中。如果一个数据源需要 20 张数据表,意味着至少需要开发 20 个任务。
2)维护成本高
传统 ETL需要依靠调度配置任务的依赖关系,存在数据同步的先后次序。这样不仅拉长了数据消费的周期,增加了运营成本;也需要运营人员充分了解数据之间的依赖关系,增加了运营的难度;且同步采用的单表同步方式,导致数据同步数量庞大,增加了监控的难度。
3)源端数据表结构变化监控难
随着业务的发展,源端的数据表结构会做对应的调整,为保证数据的准确性和一致性,目的端也需要能够及时做响应。传统的数据集成工具很难实现源端数据表结构变化的自适应。
4、数据管理难度大
1)数据管理混乱
- 企业没有相应的数据管理制度,数据出问题无法找到解决流程,解决方法;
- 没有相关的数据管理组织,角色分工不清晰,没有建立追责机制;
- 数据管理系统不完善,数据的添加,删除,变更,销毁,通知等操作,无法实现。
2)数据安全无法保障
- 组织内部数据权限划分不清,没有设置访问人,审核人,管理人等;
- 数据没有对信息的机密程度进行分层管理,导致机密信息泄露;
- 账号与权限没有进行关联跟踪,不知道是谁何时何地访问,遇到问题,无法进行追责,非正常访问也无法捕捉。
三、数据集成平台推荐
FineDataLink是一款由帆软公司开发的低代码、高时效的企业级一站式数据集成平台,满足用户以单一平台对不同业务场景的数据进行采集、集成、调度和管理等诉求,帮助企业打破数据孤岛,大幅激活企业业务潜能,使数据成为生产力。
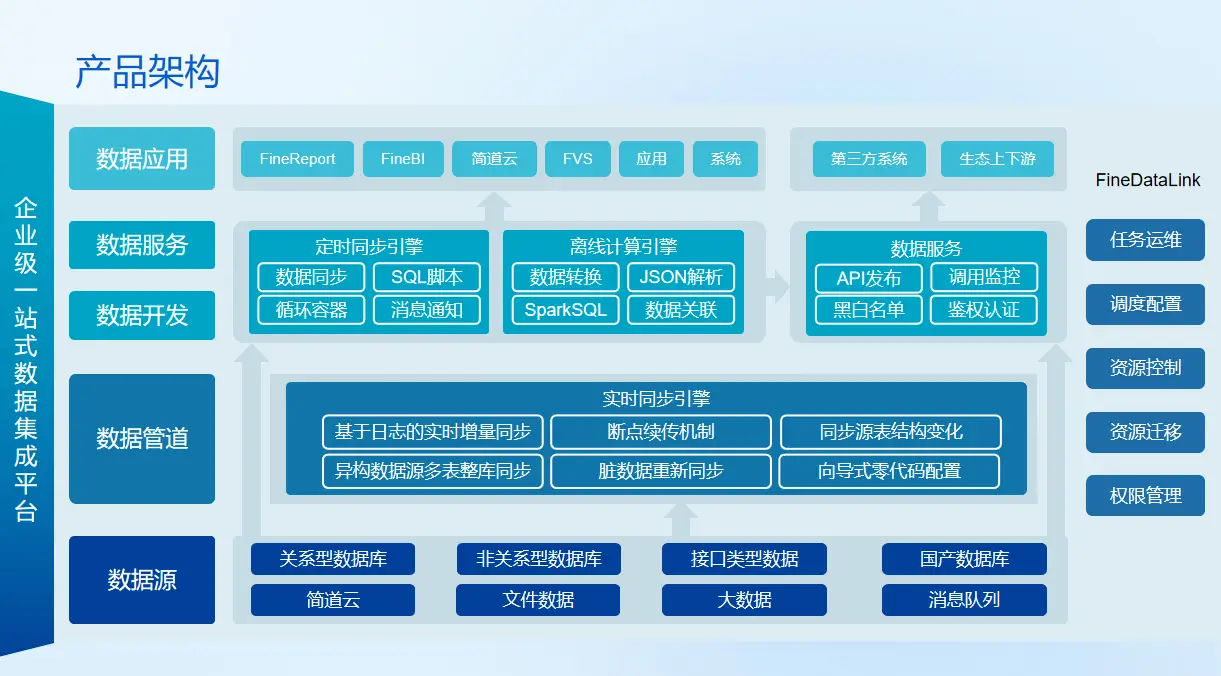
1、功能结构
数据处理人员将多种异构数据源,一键接入数据平台,使用灵活的ETL数据开发和任务引擎,为上层应用预先处理数据,帮助企业处理出质量更高、更利于展示与分析的数据。
2、核心价值
FineDataLink以其强大的核心功能,满足用户多种数据诉求:
- 多源数据采集,支持关系型、非关系型、接口、文件等多种数据源;
- 高效数据开发,ELT、ETL双核引擎,针对不同业务场景提供定制化解决方案;
- 零侵入式实时同步,实现多表/整库数据同步,提升业务数据时效性;五大数据同步方式,时间戳、触发器、全表同比、全表比对增量装载、日志解析等,实现各种情况下的数据同步需求;
- 高效智能运维,任务支持灵活调度、运行状态实时监控,便捷的操作将会释放运维人员巨大的工作量;
- 产品安全特性,支持数据加密解密、SQL 防注入等等;
- 低代码、流程化操作,提供全程可视化、拖拉拽的全新操作界面,从任务管理页面,到每一个ETL任务的节点,都致力于做到简单易懂、直接上手可用。
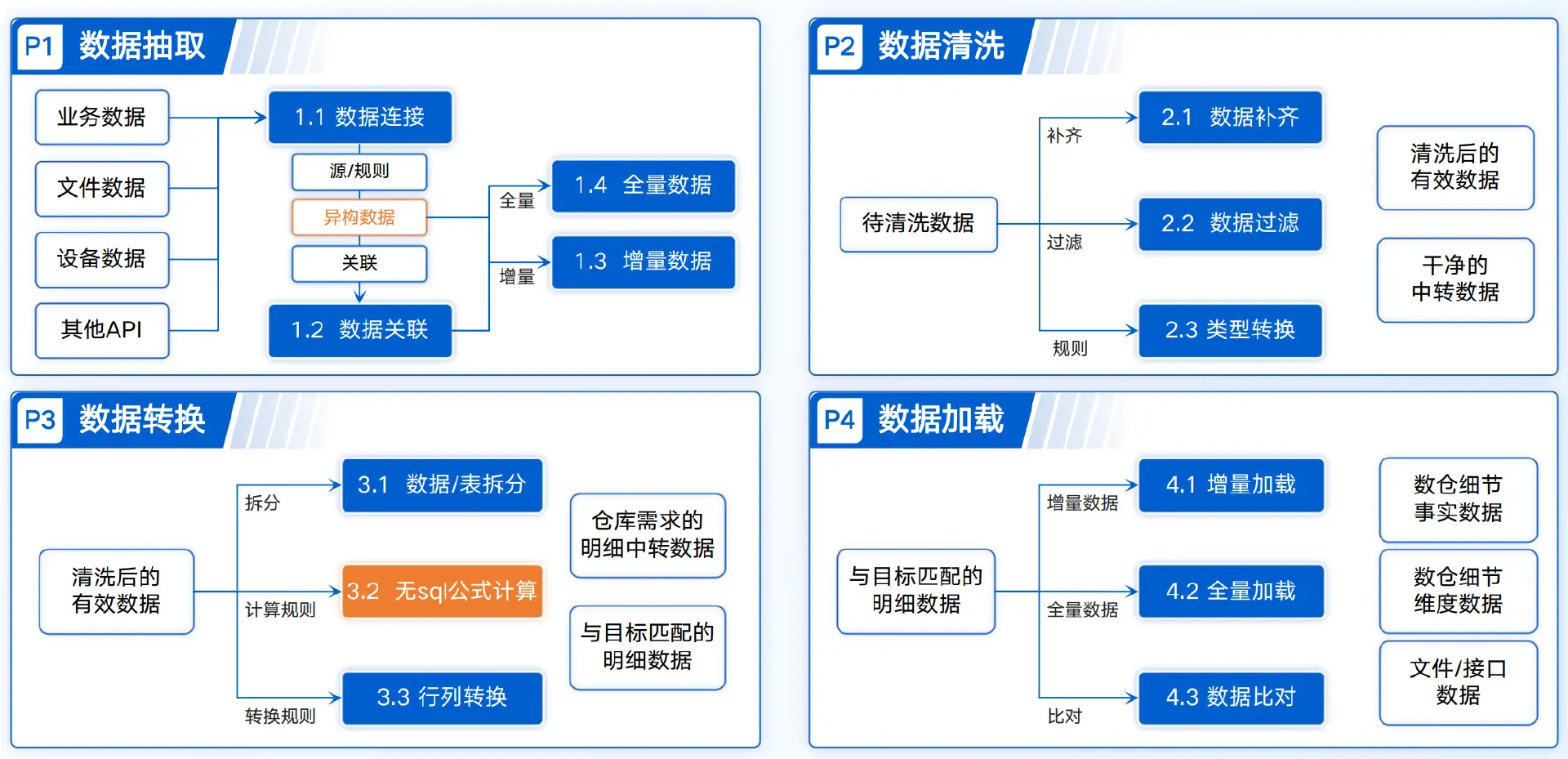
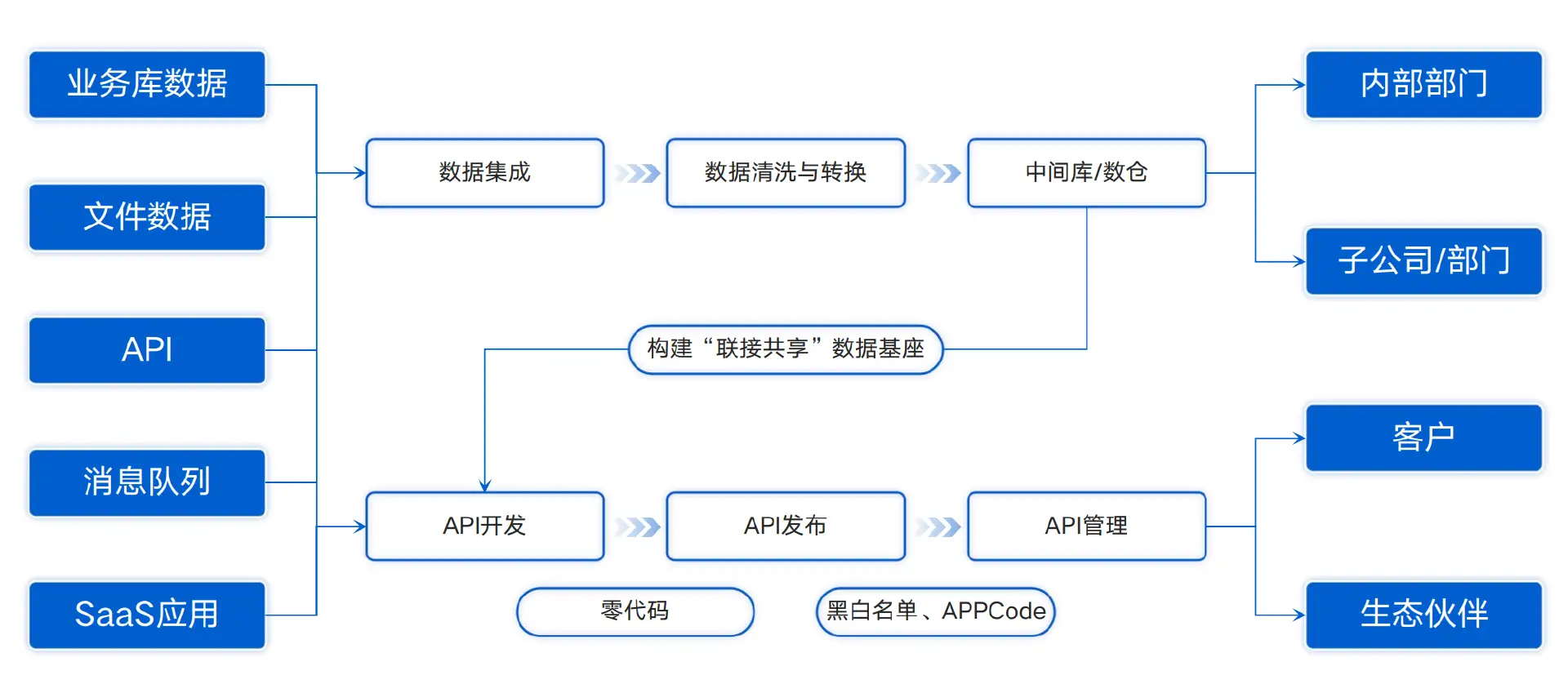
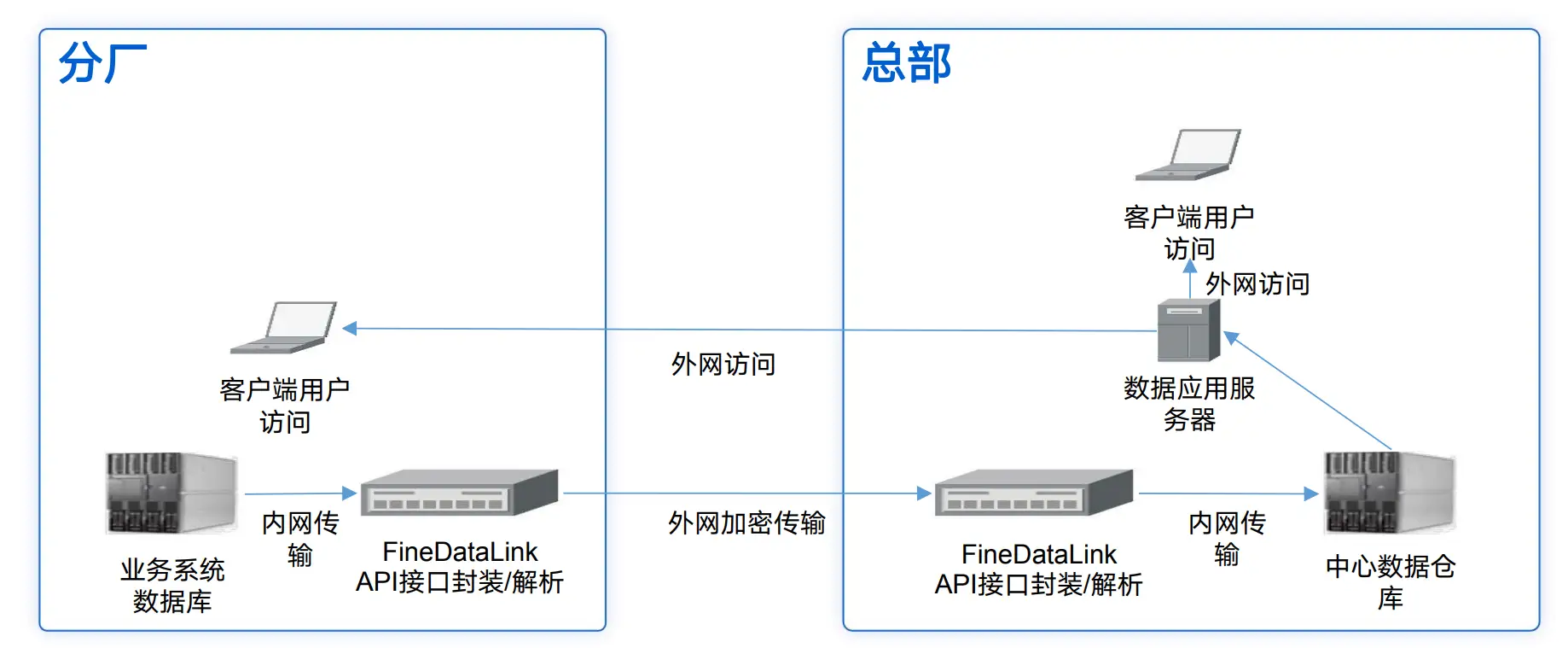
四、总结
数据集成将来自不同来源、不同系统的数据整合在一起,是实现数据驱动决策、提升效率和增强组织竞争力的关键步骤,有助于确保组织在快速变化的商业环境中能够做出明智的决策并保持灵活性。
虽然实现完整高效的数据集成十分棘手,但FineDataLink可助力企业快速、便捷地打造一个具备开放的、一站式、标准化、可视化、高性能和可持续交付的自助化数据集成平台。
若需要使用FineDataLink,点击下方图片👇







 立即沟通
立即沟通

