什么是数据集成?详解ETL数据处理步骤,盘点高质ETL工具!
在大型企业和政府部门的信息化和数字化过程中,信息数据系统的建设通常呈现出阶段性和分布性的特征,由此产生了“数据孤岛”和“数据烟囱”等问题。这些问题导致系统内存在大量冗余和垃圾的数据,无法确保数据的一致性,从而降低了数据的利用效率。
为解决这一问题.人们开始关注数据集成研究。
一、数据集成的基本概念
数据集成旨在维护整体数据源的一致性,提高数据共享利用的效率,核心任务是将相互关联的分布式异构数据源整合在一起,用户无需关心如何实现对异构数据源的访问,只需关注以何种方式访问何种数据。而实现数据集成的系统便被称为数据集成系统,它为用户提供统一的数据源访问接口,执行用户对数据源的访问请求。
数据集成的数据源可以包括各种类型的数据,具体取决于组织的需求和数据集成系统的设计。以下是一些常见的数据源类型:
- 关系型数据库:包括MySQL、PostgreSQL、Oracle、SQL Server等关系型数据库中的数据。
- 非关系型数据库:包括NoSQL数据库,如MongoDB、Cassandra、Redis等,用于存储和检索非结构化或半结构化数据。
- 文件系统:可以包括本地文件、网络文件系统(如NFS)、分布式文件系统(如Hadoop的HDFS)等。
- Web服务和API:通过HTTP或其他协议提供数据的Web服务,以及各种应用程序接口(API)提供的数据。
- 实时流数据:包括实时生成的数据流,如传感器数据、日志数据、事件流等。
- 企业应用系统:例如,企业资源计划(ERP)系统、客户关系管理(CRM)系统、人力资源管理系统等。
- 云服务:云存储、云数据库等云服务提供的数据源。
二、数据集成的难点
数据集成是信息系统集成的基础和关键。好的数据集成系统要保证用户以低代价、高效率使用异构的数据。要实现这个目标,必须解决数据集成中的一些难题。
数据集成的难点可以概括为以下几个主要方面:
- 异构性:被集成的数据源通常是独立开发的,其数据模型存在明显的异构性,给集成带来很大困难。这种异构性主要体现在数据的语义、相同语义数据的表达形式以及数据源的使用环境等方面。
- 分布性:数据源是异地分布的,依赖网络传输数据,这就存在网络传输的性能和安全性等问题。
- 自治性:各个数据源具有较强的自治性,它们可以在不通知集成系统的前提下自行更改自身的结构和数据,给数据集成系统的鲁棒性(计算机系统的稳健性)带来了一定的挑战。
三、数据集成技术:ETL
ETL是数据集成的一种主流技术,通常也是数据仓库和商业智能项目中的核心组成部分。ETL代表抽取(Extraction)、转换(Transformation)和装载(Loading),这个过程涉及从一个或多个数据源中提取数据,对数据进行转换,然后将转换后的数据加载到目标数据库、数据仓库或其他数据存储系统中。
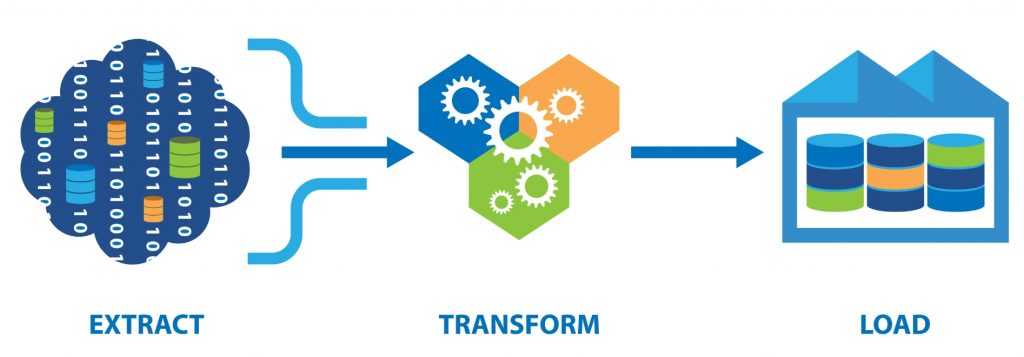
抽取(Extraction)
这一步涉及从源系统中提取数据。源系统可以是关系型数据库、非关系型数据库、文件系统、Web服务、API等。抽取的数据可能是全量数据或增量数据,具体取决于数据集成的需求。
- 定义数据源:确定需要从哪些数据源中提取数据,这可以是关系型数据库、非关系型数据库、文件系统、Web服务、API等。
- 选择提取方式:选择全量提取还是增量提取。全量提取是指从源系统中获取所有数据,而增量提取是只获取自上次提取以来发生变化的数据。
- 执行抽取:使用ETL工具或自定义脚本执行实际的数据提取操作。数据可能以批量或流式方式被抽取,并通过网络传输到下一个处理阶段。
转换(Transformation)
这个阶段对抽取的数据进行转换,包括清理数据、过滤数据、合并数据、计算派生字段等操作,以确保数据符合目标系统的需求和标准。
- 清理数据:检测和纠正源数据中的错误或不一致性,确保数据的质量。
- 过滤数据:根据预定的条件过滤掉不需要的数据,以减少数据量并提高效率。
- 合并数据:将来自不同源的数据进行合并,以创建更全面、一致的数据集。
- 派生字段:根据业务规则计算新的字段或指标,以满足目标系统的需求。
- 数据格式转换:将数据从源格式转换为目标格式,确保数据在整个过程中的一致性。
装载(Loading)
这个阶段将转换后的数据加载到目标系统中,目标系统可以是数据仓库、数据湖、数据集市或其他数据存储系统。
- 选择加载方式:选择将数据加载到目标系统的方式,可以是全量加载还是增量加载。增量加载通常与抽取步骤中的增量提取相对应。
- 执行加载:将经过转换的数据加载到目标数据库、数据仓库或其他数据存储系统中。这可能包括将数据写入数据库表、文件系统或数据湖中。
- 维护元数据:记录有关加载的元数据,例如加载时间、加载者、数据质量指标等。元数据对于数据仓库管理和监控至关重要。
四、ETL工具推荐
在整个ETL过程中,通常需要考虑数据的安全性、一致性和完整性。ETL工具的使用可以简化这个过程,并提供可视化的界面和预定义的功能,以便更轻松地设计、调度和监控ETL作业。
以下是一些常见和受欢迎的ETL工具,供您参考:
1. Apache NiFi:NiFi 是一个开源的数据集成工具,提供直观的用户界面和强大的数据流处理能力。它支持从各种源系统抽取、转换和加载数据。
2. Talend:Talend 是一个开源的数据集成工具套件,提供ETL、数据质量和实时大数据集成。它有一个图形界面,同时支持Java代码,适用于多种数据集成场景。
3. Apache Spark:Spark 并不是专门为ETL设计的工具,而是一个通用的大数据计算框架。然而,它的Spark SQL模块和DataFrame API使其成为处理大规模数据的强大工具,也可用于ETL任务。
4. Apache Camel:Camel 是一个开源的集成框架,虽然不是专门为ETL设计的,但它提供了广泛的连接器和组件,可用于构建灵活的数据集成和工作流。
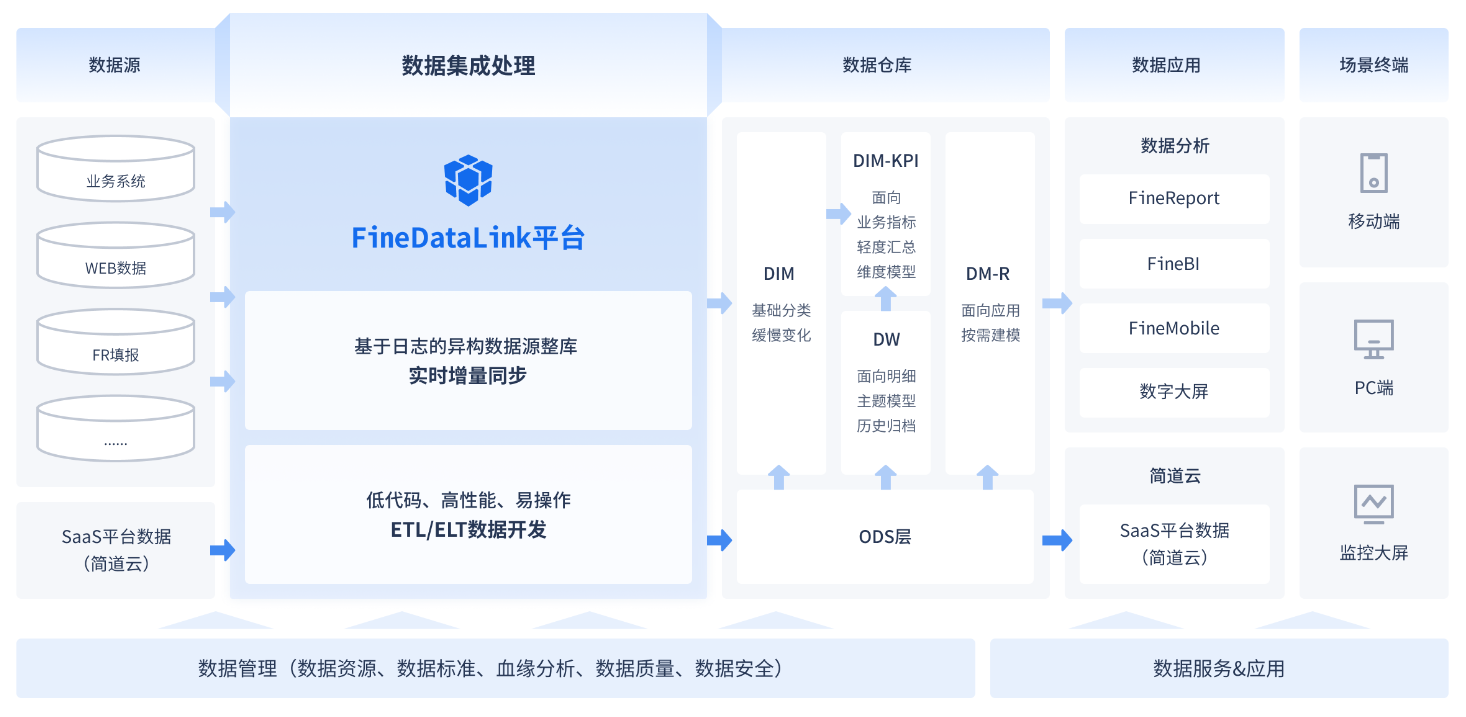
5. FineDataLink:FineDataLink 是一款国产的低代码/高时效的企业级一站式数据集成平台,面向大数据场景下实时和离线数据采集、集成、管理的诉求,提供快速连接、高时效融合各种数据、灵活进行ETL数据开发的能力,帮助企业打破数据孤岛,大幅激活企业业务潜能,使数据成为生产力。
FineDataLink有以下特点:
- 多源数据采集,支持关系型、非关系型、接口、文件等多种数据源;
- 零侵入式实时同步,实现多表/整库数据同步,提升业务数据时效性;
- 低成本构建数据服务,依托于 API 构建企业级数据资产,互通共享;
- 高效智能运维,任务支持灵活调度、运行状态实时监控,便捷的操作将会释放运维人员巨大的工作量;
- 平台拓展能力,内置 SparkSQL ,支持调用 SHELL 脚本等;
- 高效数据开发,ELT、ETL双核引擎,针对不同业务场景提供定制化解决方案;
- 五大数据同步方式,时间戳、触发器、全表同比、全表比对增量装载、日志解析等,实现各种情况下的数据同步需求;
- 产品安全特性,支持数据加密解密、SQL 防注入等等;
- 低代码、流程化操作,快速上手,更高的易用性、更低的学习成本带来更高的开发效率。
这些功能皆助力数据处理人员将多种异构数据源一键接入数据平台,并使用灵活的ETL数据开发和任务引擎,为上层应用预先处理数据,帮助企业处理出质量更高、更利于展示与分析的数据。
五、结语
综上所述,数据集成在当今信息化时代扮演着至关重要的角色,它不仅关乎数据的有序流动,也关系到企业决策和业务流程的高效推动。而在数据集成的过程中,ETL起到了关键性作用,通过抽取数据、进行转换和最终加载到目标系统,实现了异构数据源之间的协同工作。
为了更高效地实现ETL过程,各种专业的ETL工具也应运而生。企业在选择ETL工具时,需根据项目需求、数据规模、集成复杂性以及技术栈等因素进行仔细权衡。不同的工具有不同的优势,但最终目标是实现数据的高效、可靠和安全的流动,为企业的决策和创新提供可靠的支持。
帆软软件深耕数字行业,能够基于强大的底层数据仓库与数据集成技术,为企业梳理指标体系,建立全面、便捷、直观的经营、财务、绩效、风险和监管一体化的报表系统与数据分析平台,并为各业务部门人员及领导提供PC端、移动端等可视化大屏查看方式,有效提高工作效率与需求响应速度。
若想了解更多关于ETL数据处理相关的知识,并想试用数据集成产品FineDataLink,可以点击下方的图片👇,免费试用产品,强化企业数据集成及数据仓库的落地!







 立即沟通
立即沟通

