Here are the top 10 platforms for real-time ai inference in 2026: FanRuan FineChatBI, AWS SageMaker, AWS Bedrock, Google Vertex AI, Hugging Face Inference Endpoints, Together AI, Fireworks AI, GMI Cloud, Groq, SambaNova, and Baseten & Modal. Real-time ai inference lets you analyze data instantly and make decisions without delay. You want the best real-time data solutions for ai inference, so check out what matters most:
| Criteria | Description |
|---|---|
| Deployment Efficiency | Fast time-to-production for instant results. |
| Operational Costs | Transparent pricing for easy budgeting. |
| Performance Optimization | Technical enhancements for peak speed and accuracy. |
You should look for platforms with flexible deployment, built-in monitoring, and high performance. These features help you keep your ai models running smoothly and deliver real-time insights.
Top AI Inference Platforms 2026

Ranked List & Selection Criteria
You want to know which ai inference platforms stand out in 2025. Here’s a ranked list based on performance and scalability. These platforms deliver real-time insights and help you make fast decisions.
- FineChatBI
- AWS SageMaker & Bedrock
- Google Vertex AI
- Hugging Face Inference Endpoints
- Together AI
- Fireworks AI
- GMI Cloud
- Groq
- SambaNova
- Baseten & Modal
When you compare each inference platform, you should look at more than just speed. The best ai platforms offer strong reasoning, reliable enterprise deployment, and mature safety features. You also want openness and easy integration with your existing tools.
| Criteria | Description |
|---|---|
| Frontier Capability and Reasoning | Advanced capabilities for complex tasks. |
| Enterprise Distribution and Reliability | Smooth deployment and stable performance. |
| Safety and Governance Maturity | Strong safety protocols and governance. |
| Openness and On-Prem Viability | Works with open-source and on-premise setups. |
| Ecosystem and Tooling | Integrates with your current tools and workflows. |
Tip: If you need real-time analytics, focus on platforms that support instant data processing and interactive dashboards.
FineChatBI in the Top 10
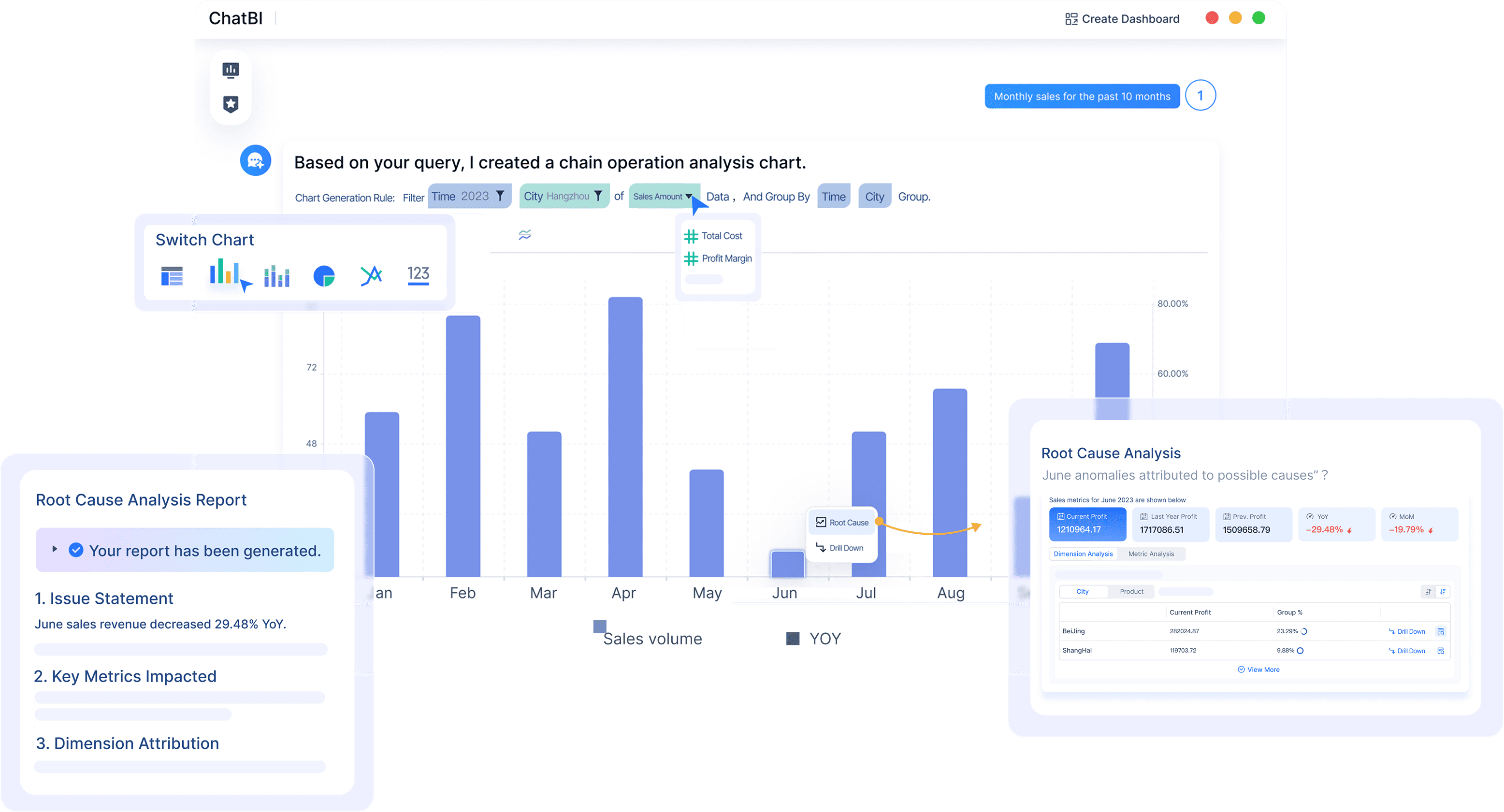
FineChatBI deserves a spot among the top ai inference platforms. You can ask questions in plain language and get instant answers, even if you have no technical background. The advanced Text2DSL technology ensures the system accurately interprets your queries every time, delivering reliable results without ambiguity. The AI intelligently proposes hypotheses about your data patterns and generates exploratory visuals automatically. You get reliable insights for quick decision-making, automated tasks, and strategic planning—all through an intuitive interface that democratizes data analytics.
AI Inference: Definition & Importance
What Is Real-Time AI Inference?
You might wonder what real-time ai inference means. It’s all about using trained ai models to get answers from new data instantly. When you send data to an ai system, it runs calculations and gives you results in milliseconds. This speed is possible because of powerful hardware and optimized models. You don’t have to wait for long processing times. You get insights right when you need them.
Here’s a quick look at how experts define it:
| Aspect | Description |
|---|---|
| Definition | AI inference is the deployment and execution of a trained AI model to produce outcomes based on new input data. |
| Real-time Capability | With the right hardware and optimized models, inference can occur in milliseconds, enabling real-time decisions. |
| Importance of Infrastructure | Low-latency infrastructure is crucial for handling complex calculations necessary for real-time applications. |
You use real-time ai inference to make decisions quickly. It helps you improve efficiency and gives your customers a better experience. Optimized models and fast infrastructure make this possible.
Why It Matters in 2026
You see ai everywhere now, but in 2026, real-time inference will be even more important. Businesses want instant answers and smarter automation. You need systems that respond fast and handle huge amounts of data. Several new technologies make this possible:
- Model optimization techniques help ai give quick and precise responses.
- AI inference as a service lets you access powerful tools through the cloud.
- Sustainable ai solutions focus on saving energy and reducing environmental impact.
- Hardware advancements, like better GPUs and TPUs, boost speed and performance.
- Explainable ai adoption builds trust by showing how decisions are made.
- Deep generative models create new data, like images and text, for more advanced tasks.
If you want to stay ahead, you need real-time ai inference. It helps you react to changes, spot trends, and make better decisions. You get more value from your data and keep your business moving forward.
Best Real-Time Data Solutions for AI Inference
1. FineChatBI
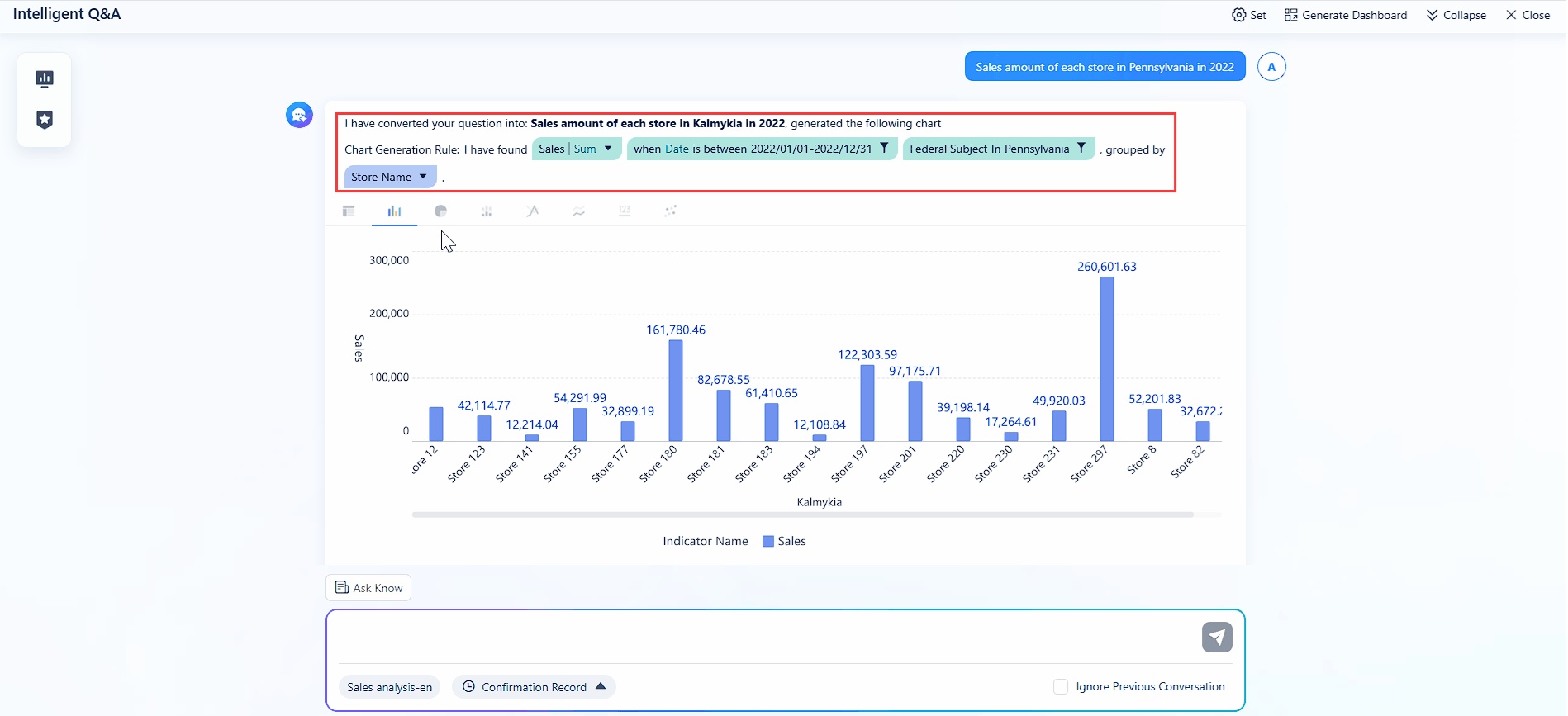
You want a platform that makes data analysis easy and fast. FineChatBI gives you conversational business intelligence with real-time predictions and instant insights. You can ask questions in plain language and get answers backed by enterprise data. FineChatBI connects to over 100 data sources, so you never worry about missing information. The platform uses Text2DSL technology, which helps you verify how the system understands your query. This builds trust and keeps your analysis transparent.
Website: https://www.fanruan.com/en/finechatbi
FineChatBI combines rule-based and large models for high performance. You get descriptive and prescriptive analytics in one place. The system guides you through the entire analysis loop, from spotting trends to making recommendations. You can export results, switch chart types, and drill down for deeper analysis. The subscription-based pricing model makes it scalable for any enterprise. You can use FineChatBI for manufacturing, financial services, retail, and more. It works well for real-time performance monitoring, predictive analytics, and seamless data integration.
| Feature | Description |
|---|---|
| Real-Time Performance Monitoring | Essential for organizations to track operations in real-time. |
| Predictive Analytics | Helps in forecasting future trends based on historical data. |
| Data Integration | Allows seamless integration of data from various sources. |
| Pricing Model | Subscription-based, making it scalable for enterprises. |
Tip: FineChatBI stands out among the best real-time data solutions for ai inference because it combines speed, transparency, and flexibility. You get sub-100ms latency for instant results and scalable ai capabilities for any business size.

2. AWS SageMaker & Bedrock
You want a cloud solution that handles everything from training to deployment. AWS SageMaker and Bedrock offer powerful tools for high-performance inference. SageMaker lets you build, train, and deploy models with a pay-as-you-go pricing model. You pay for notebook instances, training jobs, and inference. You can save money by using Spot Instances and auto-scaling. Bedrock gives you access to multiple foundation models and custom training through a unified API. You choose pay-as-you-go for on-demand inference or provisioned throughput for predictable workloads.
Website: https://aws.amazon.com/bedrock/
The cost structure changes based on your usage. SageMaker can run between $2,000 to $10,000 per month for production deployments. Bedrock’s pay-per-use model helps you control costs, especially if you have steady traffic. Both platforms support optimization strategies, so you get the best real-time data solutions for ai inference with sub-100ms latency and cost-effectiveness.
- SageMaker Pricing: Pay-as-you-go for training and inference.
- Optimization: Use Spot Instances, auto-scaling, and monitor utilization.
- Bedrock Features: Unified API, multiple models, custom training.
- Bedrock Pricing: On-demand or provisioned throughput.
3. Google Vertex AI
You want a platform that delivers low-latency ai and real-time predictions. Google Vertex AI gives you optimized performance for high-performance ai applications. You can use it for e-commerce recommendations, fraud detection, chatbots, healthcare predictions, and media analysis. Vertex AI integrates with BigQuery and Google Data Cloud, so you handle data at petabyte scale.
Website: https://cloud.google.com/vertex-ai
| Key Feature | Use Case Description |
|---|---|
| Low Latency | Optimized for real-time predictions. |
| Real-Time Recommendations | E-commerce platforms generate personalized suggestions. |
| Fraud Detection | Financial institutions analyze transactions instantly. |
| Natural Language Processing | Chatbots process user queries in real-time. |
| Healthcare Predictions | Medical models provide instant insights. |
| Image & Video Analysis | Content moderation and object detection. |
You get connectors for data preparation and analytics. Vertex AI supports optimization for sub-100ms latency, making it one of the best real-time data solutions for ai inference.
4. Hugging Face Inference Endpoints
You want easy integration and scalability. Hugging Face Inference Endpoints let you deploy models directly from the Hugging Face Hub. You get autoscaling, dedicated infrastructure, and high-performance inference for production use. The platform adjusts resources based on request volume, so you never pay for unused capacity.
Website: https://endpoints.huggingface.co/
| Feature | Description |
|---|---|
| Autoscaling | Adjusts resources for optimal performance and cost-efficiency. |
| Ease of Integration | Deploy models with minimal setup. |
| High-Performance Infrastructure | Dedicated hosting for continuous production use. |
You can use Hugging Face for chatbots, content moderation, and any application needing sub-100ms latency. The platform supports optimization and cost-effective solutions for scalable ai capabilities.
5. Together AI
You want adaptive learning and flexible pricing. Together AI uses the ATLAS system, which improves performance by adapting to traffic patterns and user behavior. Optimized kernels boost memory access and processing efficiency, giving you 2-5x better performance. You pay per token, per minute, or hourly for GPU clusters. This flexibility helps you choose the best real-time data solutions for ai inference.

Website: https://www.together.ai/
Together AI works well for high-performance inference in dynamic environments. You get cost-effectiveness and optimization for real-time predictions. The platform suits businesses that need scalable ai capabilities and sub-100ms latency.
6. Fireworks AI
You want speed, flexibility, and reliability. Fireworks AI offers serverless inference with a pay-per-token model. You can rent dedicated GPUs for consistent performance, which is cheaper for high traffic. The platform supports advanced fine-tuning and batch processing with discounts for non-immediate tasks.
Website: https://fireworks.ai/
| Pricing Model | Description | Cost Structure |
|---|---|---|
| Serverless Inference | Pay-per-token model using shared resources. | Costs can increase with high usage. |
| On-Demand GPU Deployment | Rent dedicated GPUs for consistent performance. | Cheaper for high traffic, hourly rates. |
| Advanced Fine-Tuning | Train models on custom data. | Initial training fee only. |
| Batch Processing API | Discounted rates for non-immediate tasks. | 40% discount on real-time rates. |
Fireworks AI lets you fine-tune and host models without rebuilding infrastructure. You get optimization for speed and cost, making it one of the best real-time data solutions for ai inference.
7. GMI Cloud
You want a platform built for enterprise needs. GMI Cloud simplifies deployment and scaling with container management and real-time dashboards. You get granular access management, high-performance GPUs, and InfiniBand networking for ultra-low latency ai. The inference engine delivers sub-100ms latency and automatic scaling.
Website: https://www.gmicloud.ai/
| Feature | Description |
|---|---|
| Container Management | Simplifies deployment and scaling. |
| Real-Time Dashboard | Live monitoring and analytics. |
| Access Management | Granular control for secure collaboration. |
| High-Performance GPUs | Flexible deployment across clouds. |
| InfiniBand Networking | Ultra-low latency and high throughput. |
| Secure and Scalable | Maximum uptime and security in Tier-4 data centers. |
| Inference Engine | Ultra-low latency and automatic scaling. |
| Cluster Engine | GPU orchestration and secure networking. |
| GPU Compute Service | Instant access to NVIDIA H100/H200 GPUs. |
You can customize GMI Cloud for voice agents, image/video generation, medical imaging, and fraud detection. The platform supports optimization and cost-effective solutions for high performance.
8. Groq
You want instant results and energy efficiency. Groq uses LPUs with SRAM memory for instant data access. You get hundreds of tokens per second per user, which is 18 times faster than traditional GPUs. Groq’s inference engine delivers sub-100ms latency and high efficiency at scale.
Website: https://groq.com/
| Feature | Groq LPU | Traditional GPU |
|---|---|---|
| Memory Type | SRAM | DRAM |
| Data Access Speed | Instant | Slower |
| Inference Speed | Hundreds of tokens per second | Slower |
| Cost Efficiency | High efficiency at scale | Lower efficiency |
| Power Consumption | 1/3 of traditional GPUs | Higher |
Groq is perfect for high-performance ai applications that need near-instantaneous responses. You get optimization for speed and energy use, making Groq a disruptive choice among the best real-time data solutions for ai inference.
9. SambaNova
You want advanced hardware and flexible service tiers. SambaNova uses a unique dataflow architecture and three-tier memory design for enhanced performance. You can bundle multiple models and swap them in milliseconds for fast inference. The platform offers simple API integration and supports open-source models like DeepSeek and Llama.
Website: https://sambanova.ai/
| Capability/Model | Description |
|---|---|
| Advanced Hardware | Unique architecture for high performance. |
| Model Bundling | Hot-swapping models in milliseconds. |
| API Integration | Easy onboarding for applications. |
| Service Tiers | Free, Developer, and Enterprise options. |
| Open-Source Models | Supports efficient AI inference. |
| Energy Efficiency | Maximum tokens per watt. |
You can start with the Free Tier, move to Developer Tier for higher limits, or choose Enterprise Tier for scaling. SambaNova gives you cost-effective solutions and optimization for high-performance inference.
10. Baseten & Modal
You want integration and scalability with minimal effort. Baseten and Modal use NVIDIA Blackwell GPUs for improved performance. They optimize models with NVIDIA Dynamo and TensorRT-LLM frameworks, increasing throughput and reducing inference times. Baseten Cloud provides a managed environment for rapid deployment and scaling.
Website: https://www.baseten.co/
| Evidence Description | Key Technologies Used | Impact |
|---|---|---|
| Blackwell GPUs | NVIDIA Blackwell GPUs | Improved performance and scalability. |
| Model Optimization | NVIDIA Dynamo, TensorRT-LLM | Increased throughput, reduced inference times. |
| Managed Environment | Baseten Cloud | Quick scaling, minimal infrastructure management. |
You get the best real-time data solutions for ai inference with sub-100ms latency and high performance. Baseten & Modal work well for teams that want operational simplicity and scalable ai capabilities.
Note: You should always match your platform choice to your business needs. Look for optimization, cost-effectiveness, and high performance to get the most value from your ai investments.
AI Model Inference Comparison
Feature Matrix Table
You want to pick the right ai model inference platform for your needs. Let’s look at a feature matrix that compares the top choices. This table helps you see which platforms excel at scaling, model deployment, and real-time performance.
| Platform | Real-Time Speed | Scaling Options | Model Deployment | Data Integration | Cost Efficiency | Hardware Specialization |
|---|---|---|---|---|---|---|
| FineChatBI | Sub-100ms | Auto & Manual | API, Visual | 100+ sources | High | Enterprise-grade CPUs |
| AWS SageMaker | Sub-100ms | Auto | API, SDK | AWS ecosystem | Moderate | GPUs, TPUs |
| Google Vertex AI | Sub-100ms | Auto | API, SDK | BigQuery, Cloud | Moderate | TPUs |
| Hugging Face Endpoints | Sub-100ms | Auto | API | Hugging Face Hub | High | GPUs |
| Together AI | Sub-100ms | Dynamic | API | Flexible | High | Custom kernels |
| Fireworks AI | Sub-100ms | Serverless | API | Flexible | High | Dedicated GPUs |
| GMI Cloud | Sub-100ms | Auto | API, Container | Custom | High | InfiniBand GPUs |
| Groq | Sub-100ms | Auto | API | Custom | High | LPUs |
| SambaNova | Sub-100ms | Auto | API | Custom | High | Dataflow ASICs |
| Baseten & Modal | Sub-100ms | Auto | API, Managed | Flexible | High | Blackwell GPUs |
Tip: If you need fast ai model inference and easy scaling, focus on platforms with specialized hardware and flexible model deployment options.
Cost & Performance Overview
You care about cost and speed. The ai model inference market is changing fast. Tech giants and startups compete to lower prices. Open-source solutions push costs down even more. Companies use specialized hardware like TPUs and LPUs to boost performance and cut expenses.
Here are the main drivers:
- Hardware specialization moves from general GPUs to custom chips. You get better performance and lower costs.
- Model compression techniques like quantization and pruning make ai model inference faster and cheaper.
- Smarter architectures, such as Mixture-of-Experts, activate only what’s needed. This saves resources during scaling.
You see platforms offering pay-as-you-go pricing, serverless options, and discounts for batch processing. Scaling is easier than ever. You can deploy models quickly and adjust resources as your needs change. Most platforms support instant model deployment and real-time scaling, so you never worry about lag.
If you want to maximize value, choose a platform that combines hardware innovation, smart scaling, and flexible model deployment. You get the best ai model inference experience with low latency and predictable costs.
Choosing the Right AI Inference Platform
Key Factors to Consider
When you pick an ai inference platform, you want to make sure it fits your business needs. Start by looking at the complexity of your models. Some models need more computing power than others. You should check how fast you need results. If your application needs instant feedback, low latency is a must. Hardware acceleration can boost performance, so look for platforms with specialized processors. Think about where you plan to deploy your solution. Security and compliance matter, especially for sensitive data. Scalability is also important. As your data grows, your platform should handle more requests without slowing down.
| Factor | Description |
|---|---|
| Model Complexity | The size, architecture, and computational demands of the model are critical to consider. |
| Latency Requirements | Understanding acceptable delays between input and output is essential for real-time applications. |
| Hardware Acceleration | Using specialized processors to speed up inference workloads is crucial for performance. |
| Deployment Environment | The environment where the inference workload runs must support security and compliance requirements. |
| Scalability | The model's ability to expand inference capacity as data volume increases is essential. |
You should also match your platform choice to your organization’s ai maturity. Assess your performance needs and budget. Make sure you meet compliance standards and use optimization strategies.
Matching Platforms to Use Cases
Every business has unique needs. Some platforms work better for high-speed ai tasks, while others shine in compliance or integration. For example, Groq and Cerebras deliver lightning-fast results, making them perfect for applications that need instant responses. Microsoft Azure is a strong choice if you need strict compliance for healthcare or finance. Hugging Face is great for open-source projects and easy integration.
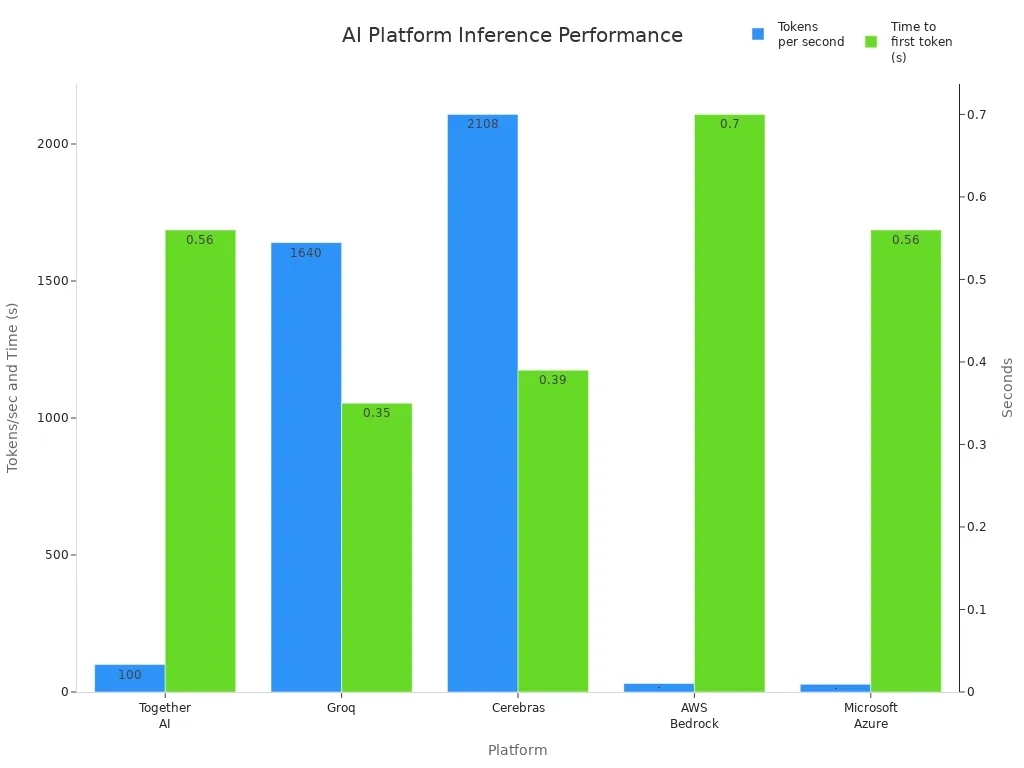
The chart above shows how different platforms perform in terms of tokens per second and time to first token. If you need fast ai inference, platforms like Cerebras and Groq stand out. If you want flexibility and a wide range of models, Hugging Face and AWS Bedrock are solid options.
FanRuan Solutions for Manufacturing & Analytics
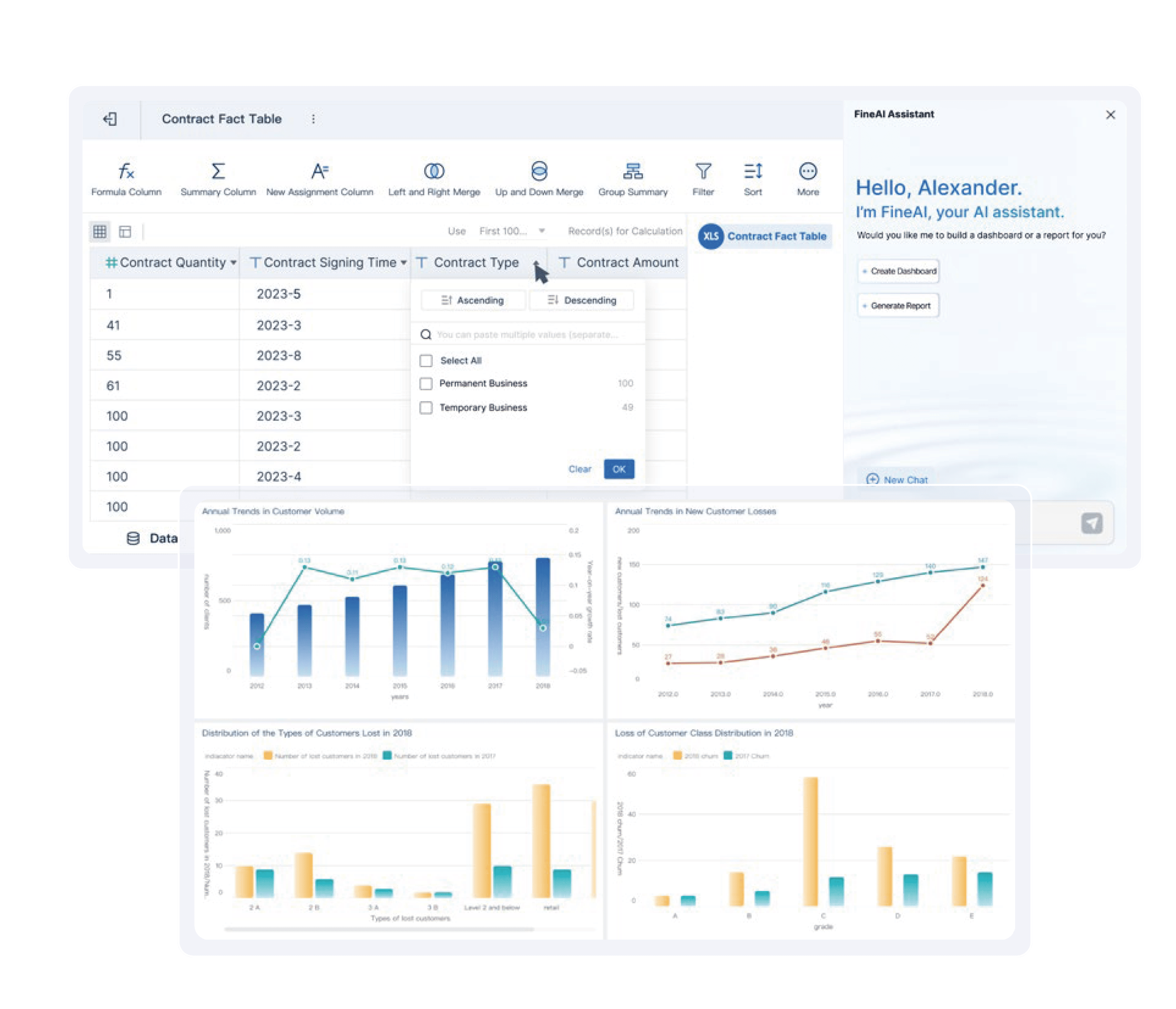
If you work in manufacturing or analytics, FanRuan offers solutions that make ai easy to use and powerful. FineChatBI lets you ask questions in plain language and get instant answers. You can connect to over 100 data sources and see real-time dashboards. In smart factories, FanRuan helps you monitor production, track quality, and optimize logistics with ai-driven insights. The NFC intelligent inspection solution supports paperless quality checks and real-time data analysis. Companies like Merry Electronics and UnionPay Data Services have improved efficiency and decision-making with FanRuan’s tools. You get reliable data, fast analysis, and scalable ai capabilities for any business size.
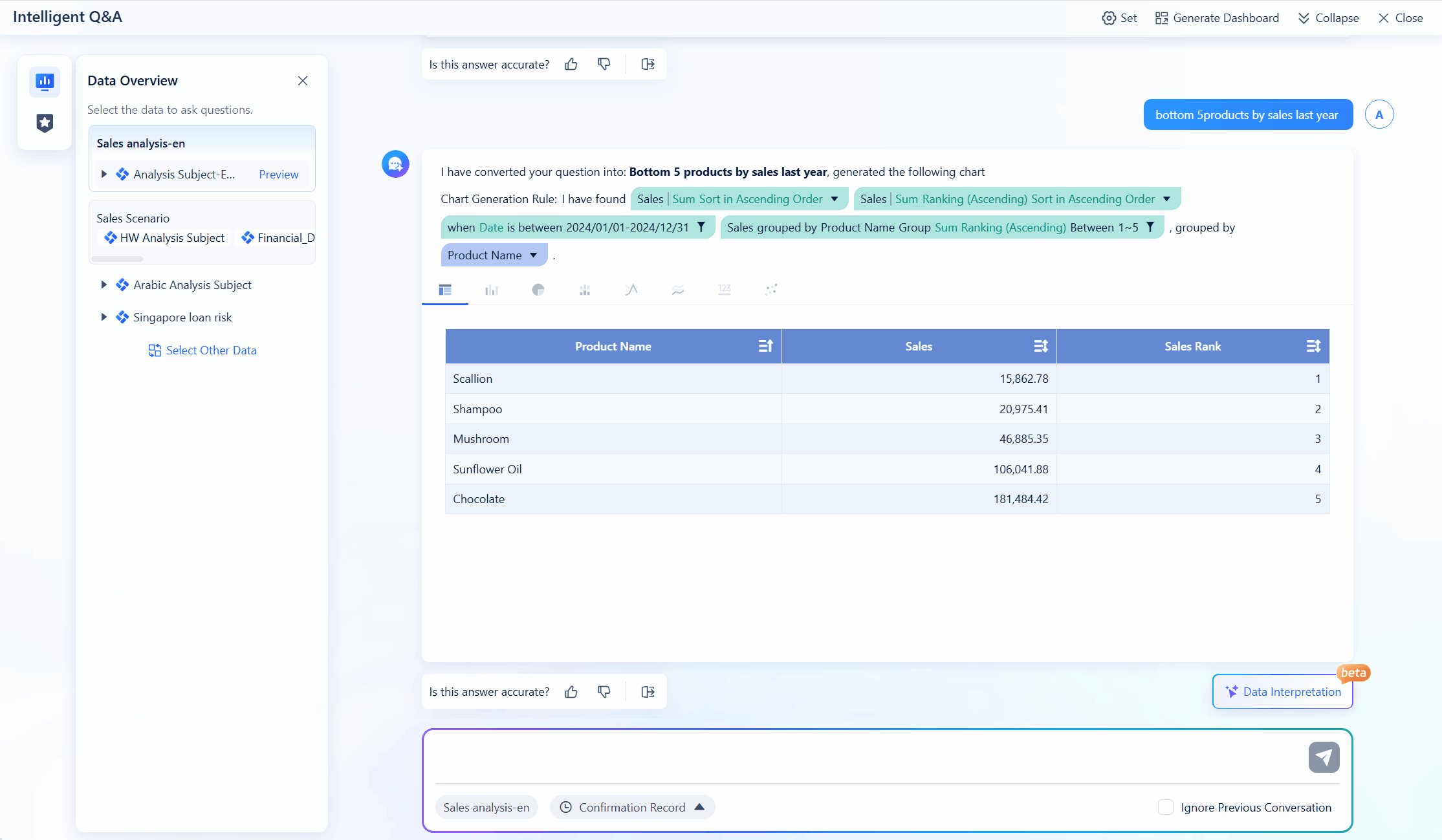
Tip: Choose a platform that matches your speed, security, and integration needs. FanRuan gives you the flexibility to grow and adapt as your business changes.
You’ve seen how top ai inference platforms stack up. Each tool offers different strengths in latency, scalability, and hardware support. Here’s a quick look:
| Tool | Latency | Scalability | Hardware Support | Pricing Model |
|---|---|---|---|---|
| Nvidia TensorRT | ultra-low (< 5ms) | excellent | GPU-optimized | usage-based |
| Intel OpenVINO | low (5-10ms) | very good | multi-platform | free/enterprise |
| Google Cloud AI | moderate (10-20ms) | exceptional | cloud-native | subscription |
You should:
- Test ai workloads under real conditions.
- Validate integration and security.
- Monitor performance and reliability.
- Stay updated on ai trends and infrastructure growth.
Choosing the right ai platform helps you adapt, innovate, and future-proof your business. Explore resources like articles on ai inference to keep learning.




FAQ

The Author
Lewis
Senior Data Analyst at FanRuan
Related Articles

Data Analysis Using AI for Non-Technical Teams: 7 Tools, Real Use Cases, and Key Limits
For non technical teams, $1 means turning business questions into usable answers without waiting in line for SQL queries, dashboard builds, or analyst bandwidth. Marketing managers want campaign answers today, sales lead
Saber Chen
May 29, 2026

AI With Access to Real Time Data: 10 Free Apps Compared for Business Teams in 2026
AI with access to real time data is software that uses live web signals, current business metrics, or connected internal systems to generate answers, insights, and actions based on what is happening now rather than yeste
Saber Chen
Jun 12, 2026
Google AI Sustainability Reporting: How to Build a Workflow Using Google’s Playbook
Google AI sustainability reporting is not just about drafting a better report faster. It is about building a controlled, traceable workflow that helps sustainability leaders, finance teams, legal reviewers, and data owne
Yida Yin
Jun 16, 2026