2026 最新數據分析軟體推薦:從免費開源工具、公開資料庫到企業 BI 實戰指南
在數據驅動決策的時代,選擇合適的分析工具與資料庫是企業與個人提升競爭力的關鍵。面對琳瑯滿目的選項,從免費開源工具到功能強大的企業級商業智慧平台,該如何做出明智的選擇?本文將為您提供一份全面的2026年實戰指南,涵蓋選擇策略、工具實戰、平台評估與未來趨勢,助您建構高效能的數據分析環境。
一、大數據分析軟體的選擇策略
在開始比較各式軟體之前,建立清晰的選擇策略至關重要。一個好的策略能幫助您避開常見陷阱,找到最符合當前需求與未來發展的工具。
1. 釐清分析需求與資料規模:篩選工具的第一步
首先,必須明確回答幾個核心問題:您要分析的資料是結構化的(如銷售表格),還是非結構化的(如社群媒體文字、影像)?資料的規模與增長速度如何?是GB級、TB級,還是即將進入PB級?分析的目的在於描述現況、預測趨勢,還是需要進行即時決策?例如,若您需要處理來自物聯網設備的即時串流數據,那麼對工具的即時處理能力要求就會遠高於僅需每週產出一次銷售報告的情境。釐清這些需求,是篩選出合適候選名單的基石。
2. 評估團隊技術能力與預算考量
工具的強大功能若無人能駕馭,便形同虛設。評估團隊現有的技術棧(如熟悉Python還是R?是否具備SQL能力?)與學習曲線容忍度。同時,預算是現實的緊箍咒。免費開源工具雖可節省授權費用,但可能需投入更多開發與維護人力成本;商業軟體則提供完整的技術支援與教育訓練,但需支付可觀的訂閱費用。務必進行全盤考量,包含隱形成本如伺服器架設、顧問費用等。
3. 一刀切客觀標準:從開源到商業方案
沒有一個工具能適用所有場景。我們可以建立一個簡單的客觀評估矩陣,包含以下維度:功能性(能否滿足核心分析需求?)、易用性(使用者介面是否直觀?)、整合性(能否與現有系統如CRM、ERP無縫連接?)、社群與支援(開源專案的活躍度如何?商業產品的客服品質?)以及擴充性。例如,對於需要高度客製化演算法的團隊,Python生態系可能是首選;而追求部門間協作與快速視覺化的企業,則應優先評估FineBI這類強調自助分析的商業智慧平台。
4. 工具的可擴充性與未來發展潛力
技術迭代迅速,今日的選擇必須能適應明日的挑戰。評估工具的架構設計是否支援模組化擴充?當資料量增長10倍時,能否透過水平擴展(增加節點)來因應?此外,關注該工具或平台的發展路線圖與市場接受度。一個活躍開發中的開源專案或持續創新的商業產品,更能保障您的投資不會在幾年後因技術過時而需全部重來。
二、免費開源分析工具與資料庫實戰
對於預算有限或追求高度彈性的使用者而言,開源生態系提供了無比豐富的資源。善用這些工具,足以建構出媲美商業方案的強大分析能力。
1. 強大開源分析工具:R 與 Python 生態系應用
R語言在統計分析與學術研究領域深耕已久,擁有如ggplot2(繪圖)、dplyr(資料處理)等成熟套件,特別適合深入的統計建模與資料探索。Python則以其通用性與簡潔語法,在數據科學界後來居上,藉由pandas、NumPy、scikit-learn等庫,從資料清洗、分析到機器學習都能一手包辦。兩者皆擁有龐大的開源套件庫(CRAN for R, PyPI for Python)和活躍社群,是資料科學家的核心武器。
2. 公開資料庫資源指南:從政府開放資料到學術資料庫
分析始於資料。台灣的政府資料開放平台提供了涵蓋經濟、交通、衛生、教育等各領域的豐富資料集,是進行公共議題分析或市場研究的寶庫。國際上,如Google Dataset Search、Kaggle Datasets、世界銀行開放資料等,則提供了跨國的巨量資料。對於學術研究,IEEE DataPort、Dryad等學術資料庫收藏了經過同儕審查的研究數據。學會查找並運用這些公開資料,能大幅降低資料取得門檻。
3. 開源視覺化工具實作:快速產生洞察報告
資料視覺化是溝通洞察的關鍵。Apache Superset 和 Metabase 是兩款極受歡迎的開源BI與視覺化工具,它們提供了友善的網頁介面,讓使用者能透過拖曳方式連接資料庫並建立互動式儀表板。對於需要嵌入應用程式或高度客製化圖表的開發者,JavaScript 生態系的 D3.js 提供了無與倫比的彈性,而 Plotly 庫則在Python與R中提供了強大的互動式繪圖功能。
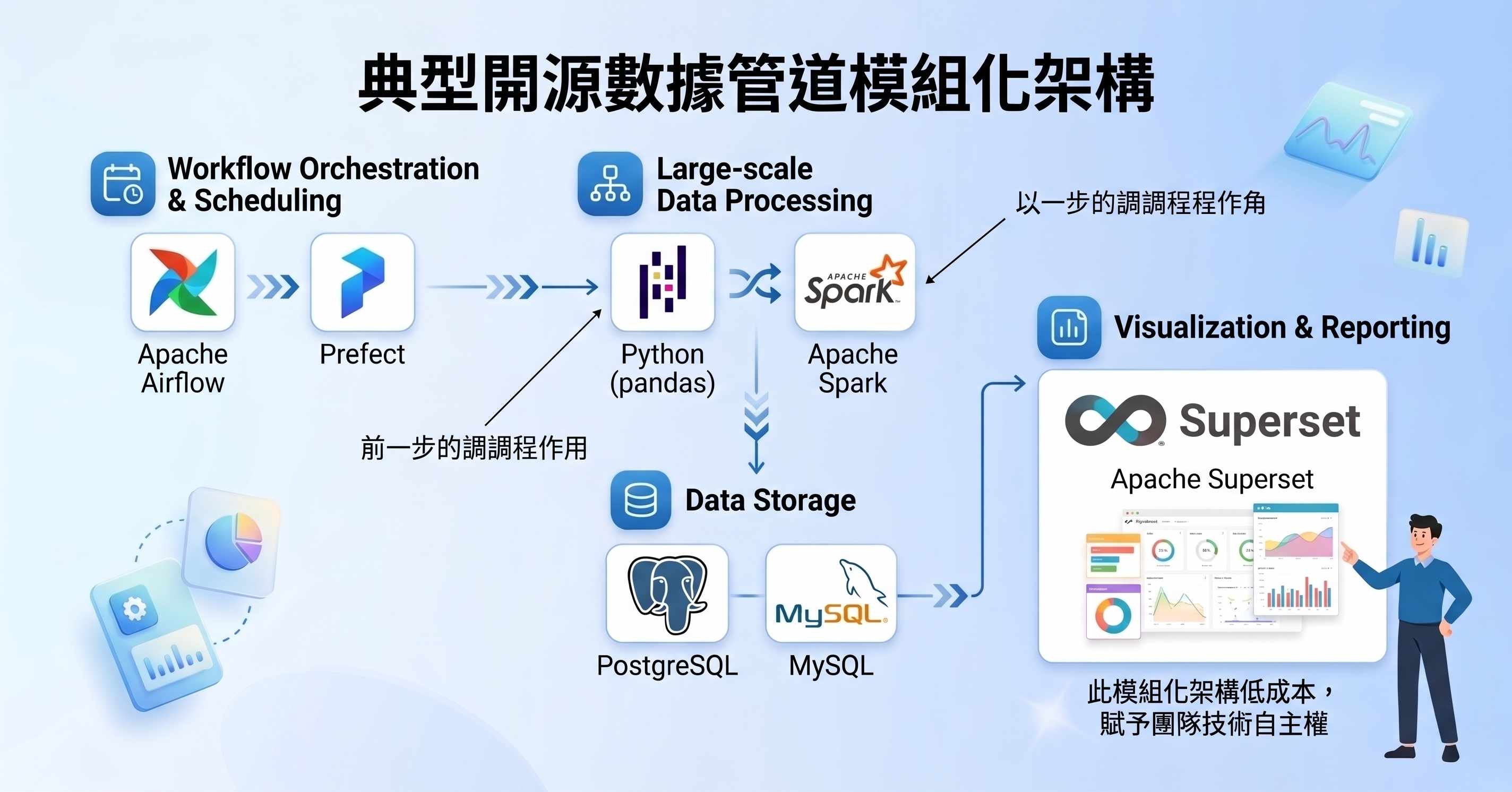
4. 整合開源工具鏈:打造低成本分析環境
單一工具難以面面俱到,但透過整合便能發揮最大效益。一個典型的開源數據管道可以是:使用 Apache Airflow 或 Prefect 進行工作流排程與協調,用 Python (pandas) 或 Apache Spark 進行大規模資料處理,將結果存入 PostgreSQL 或 MySQL 資料庫,最後透過 Superset 產生視覺化報告。這種模組化架構不僅成本低廉,也賦予團隊最大的技術自主權。
三、企業級商業智慧(BI)平台評估
當組織規模擴大,跨部門協作、資料安全管控與系統穩定性成為首要考量時,企業級BI平台便成為不可或缺的基礎建設。
1. 主流企業 BI 平台功能比較
目前市場上主流的三大企業級平台各有千秋,您可以參考下方的綜合比較表,根據團隊現況進行評估:
| 比較面向 | Tableau | Power BI | FineBI |
|---|---|---|---|
| 核心優勢 | 高階探索分析與極致的視覺化 | 微軟生態系的無縫深度整合 | 零程式門檻與全公司自助分析 |
| 視覺化能力 | 表現極強,圖表自由度最高 | 佳,適合基礎與中階企業報表 | 豐富,足以應付多數企業管理與戰情室場景 |
| 學習曲線 | 較陡峭,進階功能需要較長學習時間 | 中等,與 Excel 操作邏輯相似 | 最平易近人,主打拖拉式直覺操作 |
| 主要目標受眾 | 具備專業背景的資料分析師 | 習慣使用 Office 365 的 IT 與行政團隊 | 包含行銷、業務、營運在內的「非 IT 部門」 |
| 協作與權限治理 | 可做共享,但企業級治理需額外規劃 | 依賴微軟的權限架構 | 內建極為細緻的企業級權限管控,重視跨部門推廣 |
Tableau:適合專業數據分析師
Tableau 在資料視覺化領域長期保持領先,能製作出高度客製化、極具美感的圖表 [1, 2]。它非常適合處理複雜的探索性分析需求,但因為學習曲線相對較陡,對於沒有 IT 背景的業務人員來說,獨立上手的難度較高 [1]。
Power BI:適合微軟重度使用企業
Power BI 最大的優勢在於能與 Excel 及 Office 365 生態系深度整合,加上較低的初期學習門檻,是許多企業在建立基礎內部報表時的常見選擇 [2]。
FineBI:適合推動「全公司數據民主化」
如果你希望不寫 Code 的業務、行銷與營運主管也能自己拉報表,那麼 FineBI 在易用性與企業推廣上最有優勢 [1, 3]。它專為企業應用而生,將資料接入、處理、分析與視覺化整合在同一平台 [4]。透過拖拉式自助分析介面與細緻的權限治理,FineBI 能讓跨部門的資料整合在同一個平台上完成,徹底解放 IT 部門反覆撈取資料的產出壓力 [4, 5]。
2. 雲端原生與地端部署方案分析
部署方式關係到資安、成本與維運複雜度。雲端原生(SaaS) 方案如 Power BI Service、Tableau Online,優勢在於快速部署、自動更新、無需管理硬體,且易於實現跨地域協作。地端部署(On-Premises) 如 Tableau Server、FineBI 的私有化部署版本,則將資料與系統完全掌控在企業內部防火牆後,滿足高度敏感的資料合規要求。許多平台也提供混合部署選項,以兼顧靈活性與安全性。
3. 安全控管、協作與行動化支援
企業級平台的核心價值之一在於治理與協作。需評估其權限管控是否細緻(能否控制到列/欄層級?)、單一登入(SSO) 支援、審計日誌是否完整。在協作方面,是否支援註解、分享、訂閱報告等功能?此外,隨著行動辦公普及,平台的行動應用程式體驗是否流暢,能否離線瀏覽關鍵指標,都直接影響決策速度與員工採納意願。
4. 總擁有成本(TCO)與投資報酬率(ROI)估算
選擇BI平台是一項長期投資。總擁有成本不僅包含軟體授權費(按使用者數、核心數或資料量計價),還應計入硬體成本(地端部署時)、實施與顧問費、教育訓練費及持續維運人力成本。估算ROI時,可從「提升決策效率縮短的時間」、「透過數據洞察發現的新營收機會或節省的成本」以及「減少各部門重複製作報表的人力浪費」等角度進行量化評估。例如,導入像FineBI這樣強調自助分析的平台,能顯著降低業務單位對IT部門的報表需求,從而釋放IT資源,此即為重要的無形成本節省。
四、資料庫選擇:SQL、NoSQL 與資料倉儲
資料庫是數據分析的基石,根據資料特性與應用場景選擇合適的資料庫,是確保分析效能與穩定性的關鍵。
1. 關聯式資料庫(SQL)在結構化資料的優勢
對於需要高度一致性、事務處理(ACID)以及複雜查詢(JOIN)的結構化資料,關聯式資料庫仍是首選。PostgreSQL 因其先進的功能、對JSON等非結構化資料的支持以及強大的擴充性,被譽為「最先進的開源關聯式資料庫」。MySQL 則憑藉其簡易性與廣泛的生態系整合,在網路應用中佔據主流地位。雲端託管服務如 Amazon RDS、Google Cloud SQL 則大幅降低了維運負擔。
2. 大數據資料庫推薦:分散式 NoSQL 系統
當面對海量、快速增長且格式多變的數據時,NoSQL資料庫提供了水平擴展的能力。Apache Cassandra 以其無單點故障的架構與極高的寫入吞吐量,適合需要全球覆蓋的應用。MongoDB 作為文件資料庫的代表,其靈活的Schema設計非常適合產品目錄、內容管理等場景。對於即時分析查詢,Apache Druid 是處理時間序列資料的佼佼者。在選擇時,需考量資料模型(鍵值、文件、列式、圖形)、一致性要求與社群支援度。
3. 雲端資料倉儲服務:現代資料堆疊的核心
資料倉儲專為分析查詢優化,是現代數據堆疊的核心。Snowflake 以其獨特的存儲與計算分離架構、跨雲能力及近乎無限的彈性擴展聞名。Google BigQuery 與 Amazon Redshift 則分別深度整合於GCP與AWS生態系,提供強大的無伺服器查詢服務。這些雲端資料倉儲能輕鬆整合來自各業務系統的資料,成為企業唯一的真相來源,並直接與FineBI、Tableau等BI工具連接,進行高速分析。
4. 混合多雲資料庫架構的實務考量
為避免被單一雲端供應商綁定,或為滿足不同地區的法規要求,混合多雲架構日益普遍。實務上可能將核心交易資料放在地端的Oracle或PostgreSQL,將日誌等半結構化資料送至雲端的MongoDB Atlas,最後將所有資料匯總至Snowflake進行分析。此架構的挑戰在於資料同步(需使用CDC工具如Debezium)、網路延遲與成本管理。選擇支援開放標準與多雲部署的資料庫產品,能為未來保留更多彈性。
五、2026年資料分析趨勢與實戰指南
掌握工具是基礎,洞察趨勢方能致遠。以下是2026年值得關注的數據分析發展方向與實戰建議。
1. 人工智慧輔助分析(Augmented Analytics)的興起
AI正從分析對象轉變為分析夥伴。增強分析功能,如自然語言查詢(用口語提問自動生成SQL與圖表)、智慧型資料準備(自動偵測並修復資料品質問題)、自動化洞察生成(系統主動發現數據中的異常點、相關性與趨勢),將被深度整合至BI平台中。這意味著未來業務人員無需深諳技術,也能透過如FineBI內建的智慧化功能進行深度數據探詢,大幅降低分析門檻。
2. 即時串流資料處理實務場景
批次處理已無法滿足所有場景。電商欺詐偵測、物聯網設備監控、即時行銷活動優化等,都需要即時串流處理能力。技術棧上,Apache Kafka 作為訊息骨幹,搭配 Apache Flink 或 ksqlDB 進行即時計算,已成為業界標準。企業在規劃數據架構時,應預留即時處理的擴充能力,並思考哪些業務指標可以從「昨日報告」升級為「當下洞察」。
3. 資料治理與法規遵循的整合策略
隨著個資法(如GDPR、台灣個人資料保護法)日趨嚴格,資料治理不再是選配而是必備。未來的分析平台必須內建資料血緣追蹤(追蹤資料從來源到報表的完整歷程)、敏感性資料自動標記與遮罩、以及完善的存取與使用審計功能。在選擇工具時,必須驗證其是否符合相關法規的技術要求,並能將治理策略貫徹到每一個分析流程中。
4. 建立可持續運維的資料驅動文化
技術與工具最終是為人服務,建立資料驅動文化往往比單純導入昂貴軟體更具挑戰。一個成熟的數據文化需要高層支持與明確的數據指標體系(OKR/KPI),並持續投資員工的數據素養。
然而,理論與實務往往有極大落差。在我們過去輔導數十家知名零售與製造品牌的經驗中發現,企業推動數據文化最常卡關的痛點,往往不是缺乏高階分析技術,而是「分析工具門檻太高,導致只有 IT 會用」以及 「各部門的數字對不上」。
因此,企業在選型時,必須高度重視平台「易用性」與「統一指標管理」。以我們輔導過的一家大型零售商為例,為了破除各部門的資料孤島,我們協助他們梳理了指標,並導入主打「零程式碼、拖拉式自助分析」的 FineBI 作為全公司的統一數據底座。這讓第一線業務也能輕鬆拉取所需圖表,不僅統一了跨部門對「活躍會員」的計算口徑,消除了會議上的無效爭吵,更將他們每個月底苦熬產出結算報表的時間,從整整 3 天大幅縮短到了 30 分鐘以內。

總結而言,2026年的數據分析領域充滿機會與挑戰。無論是選擇靈活彈性的開源工具鏈,還是投資於功能完備的企業級BI平台如FineBI,關鍵在於緊扣自身需求、團隊能力與未來藍圖。同時,密切關注AI增強分析、即時處理與資料治理的趨勢,並著手培養組織的數據文化,方能讓數據真正成為驅動企業成長的核心引擎。
FAQs
首先釐清您的資料類型、規模與分析目的,接著評估團隊的技術能力與預算,並考量工具的整合性與未來擴充潛力。沒有一個工具能適用所有場景,必須根據自身條件客製化選擇。
免費開源工具如R、Python生態系彈性高、成本低,但需要較強的技術能力進行開發與維護。企業級BI平台如FineBI、Power BI提供完整的視覺化、協作、安全管控與技術支援,適合追求穩定、易用與跨部門協作的組織。
建議從Python搭配pandas、NumPy等庫開始,因其語法簡潔且應用廣泛。同時可以利用Apache Superset或Metabase這類開源視覺化工具,快速將分析結果轉為互動式儀表板,建立完整的學習路徑。
若您的資料高度結構化且需要複雜查詢與事務一致性,應選擇PostgreSQL或MySQL這類SQL資料庫。若需處理海量、快速增長或格式多變的數據,則應考量如MongoDB、Cassandra等具水平擴展能力的NoSQL系統。
主要趨勢包括人工智慧輔助分析降低使用門檻、即時串流資料處理需求增長,以及資料治理與法規遵循變得至關重要。企業應選擇能整合這些趨勢的工具,並著手培養內部的數據驅動文化。







免費資源下載