在資料驅動決策的時代,企業面臨的挑戰已非「缺乏數據」,而是「如何高效儲存、管理與分析海量數據」。傳統關聯式資料庫在面對TB、PB級的巨量資料時捉襟見肘,迫使企業必須尋求新一代的解決方案。本文將為您系統性解析如何依據資料量級、型態、查詢需求、部署環境與團隊能力,挑選最合適的大數據資料庫,並列舉免費開源大數據資料庫清單供您參考。
一、 為什麼需要大數據資料庫?
企業升級大數據架構的核心驅動力,源於傳統關聯式資料庫已無法滿足現代業務對海量數據處理的需求。其瓶頸主要體現在橫向擴充困難與I/O讀寫限制上。
1. 傳統關聯式資料庫處理海量數據的運算瓶頸
傳統關聯式資料庫如MySQL、SQL Server,其架構設計本質上適合處理結構化、高一致性的交易型數據。然而,當數據量從GB成長至TB甚至PB級時,單機部署將面臨嚴重的I/O瓶頸。硬碟讀寫速度成為系統性能的極限,即使進行垂直擴充(升級硬體),成本效益也急遽下降。更關鍵的是,這類資料庫難以進行有效的橫向擴充(Scale-out),無法簡單地透過增加節點來分散運算與儲存負載,導致企業在處理巨量報表分析、即時查詢時,面臨查詢超時、系統當機的風險。
2. 現代企業升級分散式大數據儲存系統的商業迫切性
商業上的迫切性來自於對「速度」與「洞察」的追求。市場競爭要求企業能即時分析用戶行為、預測銷售趨勢、優化供應鏈效率。根據常見實務觀察,仍依賴傳統資料庫進行大數據分析的企業,往往需要耗費數小時甚至數天才能產出營運報表,完全無法支援敏捷決策。升級至分散式大數據儲存系統,已非技術選項,而是維持競爭力的商業必需品,它能將分析時間從天縮短至分鐘級,釋放數據的即時價值。
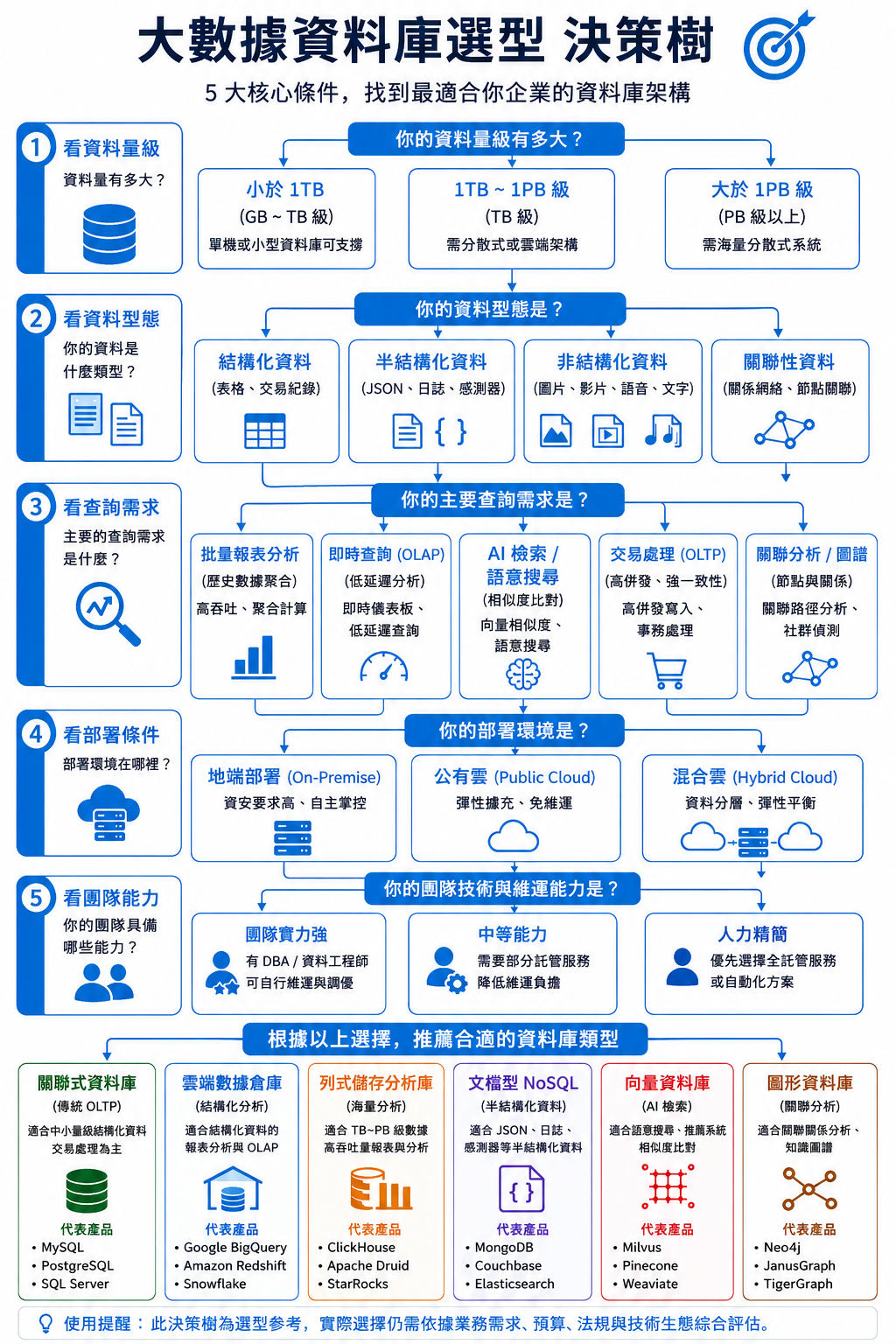
二、 挑選大數據資料庫前,企業應先確認哪些評估條件?
挑選大數據資料庫不能僅憑技術熱度,必須回歸業務與技術現實面,系統性評估以下五個核心條件。
1. 看資料量級:GB、TB 還是 PB
資料量級是決定資料庫架構的起點。GB級數據或許仍可適用單機增強型關聯式資料庫;TB級則必須考慮分散式架構或雲端數據倉庫;若預期將成長至PB級,則需選擇專為海量數據設計的分散式檔案系統(如HDFS)搭配列式儲存資料庫(如ClickHouse),以確保查詢效能。
2. 看資料型態:結構化、半結構化、非結構化
數據型態直接決定儲存模型。結構化表格數據(如交易紀錄)適合雲端數據倉庫或分散式SQL資料庫。半結構化數據(如JSON格式的API日誌、感測器資料)則建議採用文檔型NoSQL資料庫(如MongoDB)。非結構化數據(如圖片、影片、語音文字稿)則需仰賴向量資料庫(如Milvus)或圖形資料庫(如Neo4j)進行特徵儲存與關聯分析。
3. 看查詢需求:報表分析、即時查詢、AI 檢索或交易分析
查詢模式是關鍵。批量報表分析強調高吞吐的聚合計算,適合列式儲存資料庫。即時查詢(OLAP) 要求低延遲,需考量記憶體快取與索引優化。AI檢索(如語意搜尋)依賴向量資料庫的相似度比對能力。若仍需高併發的交易處理(OLTP),則需評估HTAP(混合交易/分析處理)資料庫或維持傳統關聯式架構。
4. 看部署條件:地端、公有雲或混合雲
部署環境涉及資安、成本與彈性。對資安要求極高的金融、國防業,地端部署是首選。追求彈性擴充與免維運的企業,公有雲託管服務(如Google BigQuery, Amazon Redshift)是最佳路徑。多數企業則採用混合雲架構,將敏感性資料留地端,分析運算上雲端,取得平衡。
5. 看團隊能力:是否有 DBA、資料工程與維運人力
技術團隊能力是最現實的門檻。擁有頂尖DBA與資料工程師的大型企業,可駕馭需要深度調優的開源分散式集群(如Cassandra)。技術人力精簡的團隊,則應優先選擇全託管雲服務或內建自動化調優機制的開源方案(如TiDB),以降低運營複雜度。
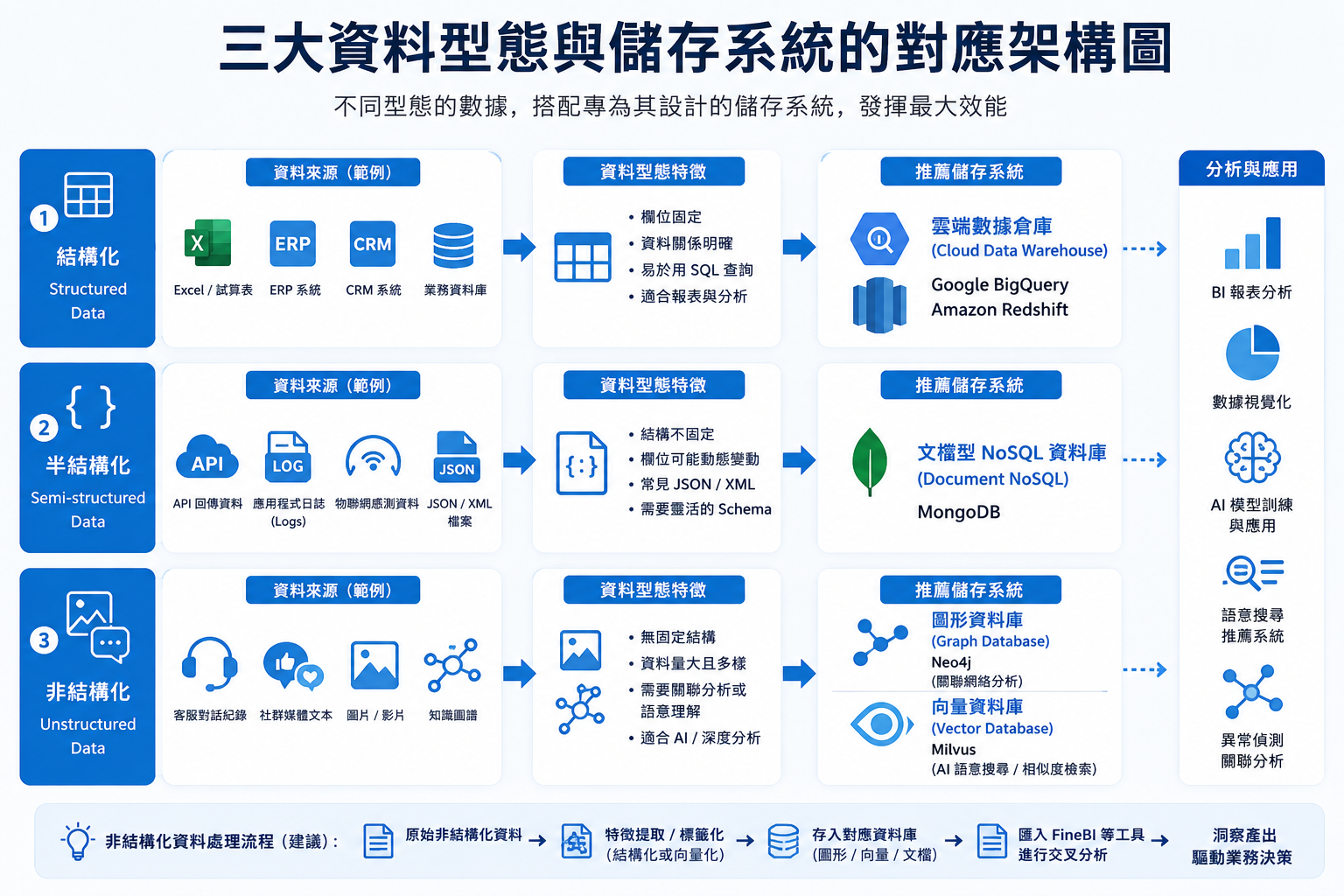
三、 依資料型態盤點:結構化與非結構化數據的適用存儲系統
不同型態的數據需搭配專為其設計的儲存系統,才能發揮最大效能。現代企業數據環境通常是三者混合,因此多模態資料庫或混合架構日益重要。
1. 結構化方案:雲端數據倉庫(Cloud Data Warehouse)
對於規格化的表格數據,如來自ERP、CRM的業務資料,雲端數據倉庫已成為主流選擇。例如 Google BigQuery 與 Amazon Redshift,它們提供全託管服務、近乎無限的彈性擴充能力,並採用按查詢用量計費的模式,讓企業無需預先規劃硬體規模。其最大優勢在於能快速執行跨PB級數據的複雜SQL查詢,大幅簡化數據倉庫的建置與維護工作。
2. 半結構化方案:文檔型 NoSQL 架構
針對API回傳資料、應用程式日誌(Logs)、物聯網感測資料等常見的JSON或XML格式,文檔型NoSQL資料庫是更自然的選擇。以 MongoDB 為例,它能直接儲存動態結構的文檔,無需預先定義嚴格的Schema(資料表結構),提供靈活的查詢與索引功能。這讓工程師能快速迭代應用,並高效處理變動頻繁的半結構化數據。
3. 非結構化方案:圖形與 AI 向量資料庫
面對客服對話紀錄、社群媒體文本、知識圖譜或影像特徵這類非結構化數據,傳統資料庫已力不從心。此時需要根據分析目的選擇專用資料庫:若要分析實體間複雜的關聯網絡(如詐騙偵測、推薦系統),圖形資料庫如 Neo4j 能提供遠優於關聯式資料庫數十倍的遍歷查詢效能。在AI時代,若要進行語意搜尋、相似圖片檢索,則需 向量資料庫如 Milvus,它能高效儲存與比對由AI模型產出的高維度特徵向量。在實務中,常先從非結構化資料提取出結構化標籤或向量,再匯入如 FineBI 等視覺化工具進行交叉分析。
四、 依查詢需求盤點:如何依業務成熟度挑選資料庫底層架構
企業的數據分析能力是逐步成熟的,對應的底層資料庫架構也應循序漸進升級,從「描述過去」邁向「預測未來」。
1. 描述與診斷分析:利用列式資料庫與資料湖進行歷史數據追溯
在數據應用初期,企業首要目標是看清營運現況,回答「發生了什麼?」、「問題出在哪裡?」。這時需要能快速掃描歷史數據、產出彙總報表的系統。列式儲存資料庫(如ClickHouse、Apache Druid) 或建基於Hadoop/雲端物件儲存之上的資料湖(Data Lake) 是理想選擇。它們能對海量數據進行高速聚合,支援業務人員透過BI工具進行多維度的交叉鑽取與診斷分析。
2. 預測與處方分析:結合時序與分散式資料庫支援 AI 機器學習建模
當企業具備穩固的描述性分析基礎後,便可邁向更高階的「預測未來趨勢」與「自動化決策」。這階段需要資料庫能提供高吞吐的即時數據流,供AI模型訓練與線上預測。時序資料庫(如InfluxDB) 擅長處理帶時間戳記的串流數據;而具備強大即時處理能力的分散式資料庫(如Apache Flink搭配Kafka),則能構建從數據攝取、特徵工程到模型推論的完整管道,實現即時異常預警或動態調價等進階應用。
3. 企業循序漸進升級大數據資料庫系統的策略
對於台灣的B2B企業,最常見的失敗原因就是「好高騖遠」,在基礎資料品質與口徑尚未統一前,就盲目導入複雜的AI預測平台。務實的策略是:先利用合適的資料庫與BI工具(如FineBI)打好「描述與診斷」的基底,確保各部門對核心KPI的定義一致,並建立流暢的報表產出流程。待資料架構穩定、數據文化成熟後,再逐步引入「預測與處方」所需的機器學習平台與即時資料庫架構,方能穩健地釋放數據價值。
五、 依部署型態盤點:地端、純雲端與混合雲架構的優劣對比
部署型態的選擇是在數據自主權、資安合規、成本與敏捷性之間取得平衡。每種模式各有其明確的適用場景。
1. 地端私有雲部署(On-Premises):極致資安與數據自主權的選擇
對於高科技製造業、金融業或政府單位,數據自主權與合規性是最高原則。地端私有雲部署讓企業完全掌控硬體、網路與資料。在此環境下,可選用如 Greenplum、TiDB 等開源分散式資料庫,將機密數據留存在自有機房,避免潛在的雲端資安外洩風險。然而,此模式需承擔高昂的初期建置成本與後續的硬體維護、升級開銷。
2. 純公有雲託管(Cloud-Native):免維護與彈性自動擴充的優勢
對於追求敏捷創新、希望將資源聚焦於核心業務的中小型企業或新創公司,純公有雲託管是最佳途徑。直接採用AWS Aurora、Google BigQuery或Azure Synapse Analytics等全託管服務,企業無需管理底層伺服器、儲存與網路,並能享受近乎無限的彈性擴充與按用量付費的優勢。這能大幅降低IT維運負擔,讓團隊專注於數據分析與應用開發。
3. 混合雲架構(Hybrid Cloud):兼顧核心安全與高併發查詢的妥協方案
混合雲架構已成為現代企業的主流選擇,它巧妙地折衷了前兩者的優點。具體做法是:將包含個人識別資訊等高度敏感的核心業務數據保留在地端資料庫;同時,定期將已去識別化、聚合後的數據同步至公有雲數據倉庫,進行大規模的機器學習訓練與高併發分析查詢。此架構既能滿足資安法規,又能利用雲端的強大算力,是兼具安全與效率的務實解方。
六、 依團隊能力盤點:應根據企業開發實力挑選合適系統
最頂尖的技術不一定是最適合的選擇。企業應依據自身技術團隊的規模與能力,挑選「可駕馭」的系統,方能確保系統穩定與長期運營成本可控。
1. 具備頂尖 DBA 與架構師團隊:首推高度自主、需手動調優的專家級開源集群
若企業擁有全職的資料庫管理員(DBA)、大數據架構師與運維團隊,則可以挑戰需要深度調優的專家級開源解決方案。例如 ClickHouse(追求極致查詢速度)、Apache Cassandra(追求高可用與線性橫向擴充)或 Greenplum(大規模MPP分析)。這類系統能讓技術團隊最大化發揮實力,透過細緻的參數調整、集群架構設計與自定義插件,打造出貼合業務需求的極致效能,但需承擔相應的運維複雜度。
2. 技術人力精簡或偏向業務導向:首推全託管雲端數據倉庫與低代碼直連架構
對於技術人力有限,或希望業務團隊能更自主進行數據分析的企業,選擇的關鍵在於「降低使用門檻」與「減少維運負擔」。全託管的雲端數據倉庫(如BigQuery、Snowflake) 是最直接的選擇。此外,像 TiDB 這類具備HTAP能力、提供簡化管理介面的開源分散式資料庫也是優秀選項。更重要的是,將這類資料庫直接與 FineBI 等低代碼BI工具串接,能讓業務人員透過直觀的拖拉拽介面直接分析百萬級數據,無需頻繁依賴IT部門撰寫SQL,大幅提升分析效率與自主性。
七、10 款熱門的免費與開源資料庫清單
開源生態系提供了豐富的大數據資料庫選擇,以下針對不同技術架構盤點10款熱門項目,供企業評估與測試。
1. 分散式分析與列式儲存資料庫:ClickHouse, Apache Cassandra, Apache Druid
- ClickHouse:以其驚人的列式儲存與向量化執行引擎聞名,在執行海量數據的聚合查詢(如SUM、COUNT)時,速度可較傳統資料庫快上百倍,極適合即時分析儀表板。
- Apache Cassandra:分散式鍵值寬列儲存資料庫,主打高可用性與無單點故障,寫入性能卓越,適合需要跨地域部署、處理大量時間序列或日誌數據的場景。
- Apache Druid:專為即時串流攝取與快速多維度OLAP查詢設計,能同時處理歷史批次數據與即時流入數據,常用於廣告技術、網路監控等需要亞秒級查詢回應的應用。
2. 關聯式與多模態擴充資料庫:PostgreSQL, Greenplum, TiDB
- PostgreSQL:功能最強大的開源關聯式資料庫,以其穩定性、豐富的資料型態與擴充性著稱。透過外掛模組(如Citus)可擴展為分散式集群。
- Greenplum:基於PostgreSQL的大規模平行處理(MPP) 資料倉庫,專為PB級數據的複雜分析查詢而建,適合大型企業的地端數據倉庫場景。
- TiDB:雲原生分散式HTAP資料庫,同時支援線上交易處理(OLTP)與線上分析處理(OLAP)。其與MySQL協議高度兼容,且支援彈性擴縮容,是遷移至分散式架構的平滑選擇。
3. 文件與鍵值型 NoSQL 資料庫:MongoDB, Redis, Apache HBase
- MongoDB:市佔率最高的文件型資料庫,使用類似JSON的BSON格式儲存資料,Schema靈活,開發者體驗佳,廣泛用於內容管理、物聯網等領域。
- Redis:極速的記憶體內鍵值儲存資料庫,亦提供持久化功能。除快取外,也常用於會話儲存、排行榜、訊息佇列等需要超高併發讀寫的場景。
- Apache HBase:建構在Hadoop HDFS之上的分散式寬列儲存資料庫,適合需要隨機、即時讀寫超大規模數據集的應用(如Facebook早期訊息系統)。
4. 圖形與 AI 向量型大數據資料庫:Neo4j, Milvus
- Neo4j:領先的開源圖形資料庫,使用節點、關係與屬性來儲存數據,專門高效處理深度關聯查詢,如社交網絡分析、詐騙偵測、推薦引擎。
- Milvus:專為AI應用設計的向量資料庫,能高效儲存、索引與搜索由深度學習模型產生的大量向量,是實現圖像搜尋、語意檢索、個性化推薦的基礎設施。
八、 開源資料庫的部署挑戰:企業環境下的運營限制與技術門檻
選擇開源方案雖能節省可觀的授權費用,但企業必須正視其背後隱藏的技術門檻與長期運營成本,避免因小失大。
1. 零授權費背後隱藏的高昂技術維護與人力運營成本
免費的開源資料庫,其真正的成本在於「人力」與「風險」。分散式集群的部署、監控、調優、升級與故障排除,高度依賴頂尖的DBA與系統架構師。根據一般產業觀察,要穩定運營一個中等規模的開源大數據集群,至少需要2-3名資深工程師全職投入。這類人力在市場上薪資高昂,長期下來,總體擁有成本(TCO)可能超過商業授權費。
2. 缺乏原廠即時技術支援對企業核心業務系統的資安風險
當開源資料庫出現嚴重漏洞或集群發生無法自行診斷的故障時,企業若僅依賴社群論壇與公開文件,可能面臨漫長的問題排查期,導致核心業務中斷。更嚴重的是,缺乏及時的安全補丁與專業的資安諮詢,可能使系統暴露於攻擊風險下。因此,對於業務關鍵型系統,許多企業會選擇購買第三方商業支援服務(如Red Hat, Confluent等提供),或直接採用具備企業級支援的雲端託管版本。
九、 建立高效率數據流程:如何讓開源大數據資料庫與前端視覺化完美協作
導入強大的大數據資料庫只是第一步,更重要的是建立一個能讓業務人員輕鬆獲取洞察的端到端數據流程。關鍵在於串接開源資料庫與現代BI工具。
1. 利用大數據資料庫內建語法進行數據清洗與異質系統整合
在數據進入分析階段前,必須先進行清洗與整合。現代大數據資料庫(如PostgreSQL、TiDB)通常提供強大的SQL功能,可用於數據轉換。實務上的流程是:透過ETL工具或自定義腳本,將地端ERP、CRM等業務系統的資料,以及雲端行銷平台的日誌,同步至中央的大數據資料庫或資料湖中,進行清洗、關聯與建模,建立「單一真實來源」。
2. 結合 FineBI 實現百萬級數據即時直連
當數據在開源資料庫(如ClickHouse或TiDB)中準備就緒後,即可透過 FineBI 的直連功能進行分析。FineBI能直接對接多種資料庫,進行高速數據抽取。業務人員無需撰寫SQL,僅需透過全滑鼠點選的拖拉拽操作,即可完成複雜的維度切換、指標計算與圖表製作,輕鬆處理百萬甚至千萬級的數據集,快速建立動態戰情室與管理儀表板。

3. 跨部門指標統一與工時縮短的台灣企業量化成功故事
在我們過去輔導台灣零售品牌導入數據分析平台的經驗中,最常見的障礙並非工具使用困難,而是底層大數據資料庫與前端報表間的「指標口徑不一致」。例如,行銷部門與財務部門對「活躍會員」的定義不同,導致報表數字永遠對不上。某知名零售客戶在徹底統一定義,並將開源大數據資料庫透過FineBI直連後,各部門得以在同一個可信數據源上作業。其直接效益是:每月例行營運報表的產出時間,從過去的3個人工天,大幅縮短至30分鐘內,讓團隊能將時間專注於解讀數據與制定策略,而非整理資料。
FAQs
各大開源專案的官方網站(如 clickhouse.com、mongodb.com)均提供社群版免費下載。若需真實數據集進行測試,推薦 Kaggle Datasets 與 UCI 機器學習資料庫,它們提供各產業去識別化數據。若要分析台灣市場,可善用「政府資料開放平臺」或「臺北市資料大平臺」,皆提供豐富的免費開放資料。
最核心的兩個標準是「資料型態」與「擴充方式」。若資料多為固定結構的交易表格,推薦分散式 SQL 或雲端數據倉庫(如 BigQuery, TiDB);若是結構多變的日誌或社群文字,則推薦 NoSQL 資料庫(如 MongoDB、Cassandra)。同時需評估系統能否以符合成本效益的方式,滿足未來數據量成長的擴充需求。
Excel 單張工作表有 104 萬列的限制。企業端建議將資料移轉至輕量級開源資料庫(如 PostgreSQL),或直接導入內建大數據運算引擎的 BI 工具(如 FineBI)。後者可讓使用者以拖拉拽方式,直接對接資料庫並分析百萬級以上的數據,無需依賴 Excel 或撰寫複雜程式碼。
因為 ClickHouse 採用獨特的列式儲存架構與向量化執行引擎。在進行聚合查詢(如計算各區域銷售總額、年度轉換率)時,它只需讀取相關的數據列,而非整行資料, I/O 效率極高,因此查詢速度可比傳統行式資料庫快上數百倍,特別適合即時分析場景。
開源大數據資料庫(如 ClickHouse, PostgreSQL)是指原始碼公開、允許使用者自由下載、修改與部署的系統。與 Oracle、SQL Server 等商用資料庫最大的差別在於授權模式:開源資料庫免去初期軟體授權費,但企業需自行負責部署、維護、調優與資安;商用資料庫則需支付授權費,但通常包含原廠技術支援與穩定性保證。
此類資料無法直接以表格形式處理。建議先以文檔型 NoSQL 資料庫(如 MongoDB)儲存原始對話紀錄。若需進行語意分析或智能檢索,可進一步使用 AI 模型將文字轉為向量,並存入向量資料庫(如 Milvus)。最終可將分析後的結構化結果(如客訴分類、情緒標籤)匯入 BI 工具(如 FineBI)製成圖表儀表板。
最常見的失敗原因並非技術選型錯誤,而是「資料品質不佳」與「跨部門協作斷層」。若底層數據本身雜亂、口徑不一(Garbage in, garbage out),再強大的資料庫也無用。導入前必須先進行基礎的資料治理,確保 IT 與業務部門對核心 KPI 的定義與計算邏輯達成共識。
完全可以。現代 BI 工具如 FineBI,已將複雜的 SQL 語法(如過濾、分組、關聯合併)轉化為直觀的視覺化操作。使用者只需透過滑鼠點選和拖放,工具便會自動生成高效的查詢語句,從後端大數據資料庫中抽取並分析資料,讓業務人員無需程式背景也能進行深度數據探索。







免費資源下載