Python統計分析,是用 Python 完成資料清理、描述統計、推論分析、視覺化與結果解讀的一套流程。對個人來說,它能提升分析效率;對企業來說,它能把零散資料轉成可重複、可擴充、可落地的決策依據。
如果你正在找的是「python 統計分析到底從哪開始、要裝什麼、怎麼實作、企業怎麼導入」,這篇文章會依照實務順序整理,讓你從觀念、工具、流程到應用一次看懂。
一、Python統計分析是什麼?先掌握核心概念與學習地圖
Python統計分析,簡單說就是用程式化方式處理資料並進行統計推論。它不只是在算平均數或畫圖,而是把資料蒐集、整理、分析、驗證與呈現串成一條可重複執行的流程。
1. Python統計分析的定義與常見工作流程
python 統計分析的核心,不是「會寫多少語法」,而是能不能把問題轉成可分析的資料與指標。常見工作流程通常包含以下幾步:
- 定義問題
- 例如:本月銷售下滑,是因為客單價下降,還是訂單數減少?
- 蒐集資料
- 可能來自 Excel、CSV、資料庫、API 或內部系統。
- 資料清理
- 處理缺值、重複值、格式錯誤、欄位型態不一致。
- 描述統計
- 先看平均數、中位數、標準差、分布、群組差異。
- 推論統計或建模
- 例如 t 檢定、卡方檢定、相關分析、回歸分析。
- 視覺化與解讀
- 用圖表與文字說明結果是否具有商業意義。
- 輸出報告或儀表板
- 讓團隊能持續使用分析成果,而不是只停留在一次性檔案。
這套流程的優勢在於:同一段程式可以重複執行,當新資料進來時,只要更新資料來源即可重新分析。
2. Python統計分析入門該先學哪些基礎能力
初學者要學 python 統計分析,建議先建立「資料處理能力」再進入「統計方法」。因為實務上,花最多時間的通常不是跑模型,而是把資料整理到能分析。
建議先掌握這幾類基礎能力:
- Python基本語法
- 變數、串列、字典、函式、條件判斷、迴圈
- 資料表觀念
- 欄位、列、索引、型態、主鍵、日期格式
- pandas操作
- 篩選、排序、分組、合併、欄位轉換
- 基礎統計概念
- 平均數、中位數、變異數、標準差、常態分布、抽樣
- 圖表判讀能力
- 長條圖、折線圖、直方圖、盒鬚圖、散佈圖
- 結果表達能力
- 能說清楚「發現了什麼」與「這代表什麼」
如果你是商業、行銷、財務、營運背景,其實不一定要先成為工程師。多數人一開始只要能處理表格資料、理解統計意義,就能開始做出有價值的分析。
3. 利用Python進行資料分析與一般報表工具的差異
Python適合做深入分析;一般報表工具適合快速呈現與共享。兩者不是互斥,而是不同階段各有優勢。
實務上常見的最佳做法是:用 Python 做資料清理、統計分析與模型計算,再把結果接到 BI 工具進行視覺化與共享。這也是後面會提到 FineBI 的重要價值所在。
二、開始做Python統計分析前,要準備哪些工具與環境?
開始做 python 統計分析前,最重要的不是裝最多工具,而是建立一個穩定、好維護、容易除錯的分析環境。對初學者而言,先求能順利執行,再追求進階配置。
1. 常見開發環境與執行方式整理
Python統計分析常見的執行方式,大致可分成以下幾種:
- Jupyter Notebook / JupyterLab
- 最適合教學、探索式分析、逐段測試程式
- 優點是可以一邊寫程式、一邊看圖表與文字說明
- VS Code
- 適合想兼顧開發效率與擴充彈性的人
- 可同時處理 Python 腳本、Notebook、Git 版本控制
- PyCharm
- 適合偏正式開發、模組化專案與大型分析流程
- Google Colab
- 不用本地安裝,打開瀏覽器就能執行
- 適合快速練習與分享教學範例
- 命令列執行 .py 檔
- 適合批次任務、自動排程、正式部署
如果你是初學者,通常建議從 Jupyter Notebook 或 Colab 開始;如果你之後會把分析流程制度化,則可逐步轉向 VS Code + 虛擬環境 + Git。
2. Python統計套件怎麼選:NumPy、pandas、SciPy、statsmodels
這四個套件,是 python 統計分析最常見的核心工具。理解它們的分工,會比死記函式更有用。
實務上可這樣理解:
- NumPy:底層數值計算基礎
- pandas:日常資料分析主力
- SciPy:補足檢定與進階數學函式
- statsmodels:強調統計意義與模型解讀
如果你的工作重點是商業分析,通常最常用的是 pandas + matplotlib / seaborn + statsmodels 的組合。
3. Python資料分析pdf與官方文件該怎麼搭配閱讀
最有效率的學法,不是只看 PDF 教材,也不是一開始就硬啃官方文件,而是兩者搭配。
建議閱讀順序如下:
- 先用教學 PDF 或入門教材建立全貌
- 先理解資料分析流程、常見函式與實作情境
- 遇到實作需求時查官方文件
- 例如
groupby、merge、fillna、回歸模型參數
- 例如
- 用小型資料集邊學邊做
- 單看教材容易懂得快、忘得也快
- 建立自己的筆記與範例庫
- 把常用程式片段整理成可重用模板
官方文件的價值在於精準與完整;PDF 或教學文章的價值在於降低理解門檻。兩者合用,才是多數分析師在實務上的常見做法。
三、Python統計分析的標準流程:從資料整理到結果解讀
Python統計分析的標準流程,可以概括成四件事:整理資料、確認分布、選對方法、正確解讀。很多分析失準,不是因為工具不夠強,而是前處理與解讀出了問題。
1. 資料蒐集與前處理:常見的Python資料處理範例
資料前處理通常占整體分析工時的很大比例。根據常見產業實務,資料欄位不一致、日期格式混亂、缺漏值與重複列,是最常見的問題。
以下是典型前處理任務:
- 匯入 CSV、Excel 或資料庫資料
- 統一欄位名稱
- 轉換日期與數值型態
- 去除重複資料
- 補值或排除缺值
- 合併多張表
- 建立分析欄位,例如月份、地區、客群分層
簡單範例概念如下:
import pandas as pd
df = pd.read_csv("sales_data.csv")
df.columns = df.columns.str.strip()
df["order_date"] = pd.to_datetime(df["order_date"], errors="coerce")
df["revenue"] = pd.to_numeric(df["revenue"], errors="coerce")
df = df.drop_duplicates()
df = df.dropna(subset=["order_date", "revenue"])
monthly = df.groupby(df["order_date"].dt.to_period("M"))["revenue"].sum()
這段程式看似簡單,但已經涵蓋實務中最常見的清理動作。會處理髒資料,往往比會背統計公式更重要。
2. 描述統計、推論統計與視覺化分析的實作重點
描述統計用來「看清資料長什麼樣」;推論統計用來「判斷差異是否具有意義」;視覺化則用來「讓結果可溝通」。
可用下列表格快速理解:
實作時要特別注意:
- 先看資料分布,再選方法
- 不是所有資料都適合直接做參數檢定
- 樣本數會影響解讀
- 樣本太小時,結果容易不穩定
- 統計顯著不等於商業重要
- 即使 p 值達標,也要看效果量與實際影響
- 圖表要對應問題
- 比較類問題用長條圖或盒鬚圖;趨勢類問題用折線圖
3. Python資料分析範例:用簡單案例看完整分析流程
假設你是電商分析人員,想回答這個問題:促銷活動後,整體訂單金額是否明顯提升?
可以依下列流程進行:
- 定義分析區間
- 活動前 30 天 vs 活動後 30 天
- 清理資料
- 排除取消訂單、異常金額、重複紀錄
- 計算描述統計
- 比較前後平均訂單金額、中位數、標準差
- 畫圖
- 盒鬚圖看分布,折線圖看每日變化
- 做統計檢定
- 若條件合適,可用兩組平均數檢定
- 解讀結果
- 不只看是否顯著,也要看增幅是否足以支撐活動成本
這樣的範例很接近真實商業場景,因為企業真正關心的不是「模型有沒有跑出來」,而是「結果能不能支持決策」。
4. Python數據分析練習該如何設計,才能真正提升實戰能力
最有效的練習方式,是用接近工作情境的題目,而不是只做教科書式的函式練習。
建議把練習分成三層:
- 第一層:函式熟悉
- 例如排序、篩選、分組、合併、轉型
- 第二層:完整分析小題
- 例如找出退貨率最高品類、比較地區轉換率差異
- 第三層:商業情境專題
- 例如會員流失分析、促銷成效分析、來客趨勢分析
好的練習題要具備三個條件:
- 資料不完美
- 讓你練習清理,而不是只算答案
- 問題有決策背景
- 讓你學會為什麼要分析
- 需要文字解讀
- 訓練你把結果講給非技術主管聽
如果你想更快進入企業實務,建議用自己產業的資料來練習,效果會遠高於只做公開教學範例。
四、常見方法與實務應用情境:企業可以怎麼用Python統計分析?
企業使用 python 統計分析,最有價值的地方,不在於工具本身,而在於它能把營運問題量化、驗證並持續追蹤。只要資料結構化程度足夠,大多數部門都能找到應用點。
1. 銷售、行銷與營運管理中的Python資料分析應用
在商業場景中,Python常用來處理這幾類問題:
- 銷售分析
- 比較各區域、通路、產品線業績差異
- 分析客單價、回購率、促銷影響
- 行銷分析
- 評估廣告投放成效
- 分析轉換漏斗、顧客分群、活動成效
- 營運管理
- 監控庫存週轉、出貨效率、客服量能
- 找出異常波動與關鍵原因
例如,若某月營收下滑,Python可以快速拆解成:
- 訂單數是否下降?
- 新客還是舊客流失?
- 哪個產品線跌幅最大?
- 是流量下降,還是轉換率下降?
- 是否與促銷、價格、庫存有關?
這些問題若只靠手動報表,往往很慢;若用 Python 建立流程,則能定期自動更新並追蹤。
2. 製造、零售與服務業的統計分析情境整理
不同產業的分析重點不同,但底層邏輯相通:從資料中發現偏差、變化與因果線索。
舉例來說:
- 製造業會關注某批次不良率是否異常升高
- 零售業會分析不同門市的坪效與會員回購
- 服務業會比較不同時段的人力配置與服務品質
這些都很適合用 python 統計分析建立標準化流程,讓分析不只做一次,而是能反覆使用。
3. 從單次分析到持續監控:企業導入分析流程的關鍵
企業真正需要的,不是一次漂亮分析,而是能持續運作的分析機制。要從單次專案走向常態化監控,關鍵通常有三個:
- 資料定義一致
- 例如營收、毛利、活躍會員的口徑必須統一
- 流程可重複
- 資料匯入、清理、計算、輸出都能固定化
- 結果能共享
- 不是只有分析師看得懂,而是管理者也能使用
很多企業卡住的地方,不是 Python 不夠強,而是分析結果無法順利交付到業務與管理層。這也是為什麼後續常需要搭配 BI 平台,將分析結果轉成可互動、可追蹤的管理介面。
五、FineBI如何搭配Python統計分析提升決策效率
Python適合做深度計算,FineBI 適合做共享分析與決策呈現。兩者搭配的最佳價值,在於把「分析能力」與「使用效率」連接起來,讓結果不只停留在程式碼或單次報告中。

1. FineBI與Python分析流程的整合方式
最常見的整合方式,是先用 Python 完成資料清理、統計計算或模型輸出,再把結果寫回資料庫、CSV 或中介資料表,最後由 FineBI 讀取並視覺化呈現。
典型流程如下:
- Python取數與前處理
- Python進行統計分析或特徵計算
- 輸出結果到資料庫或資料表
- FineBI建立主題模型與圖表
- 部門透過儀表板查看、下鑽與共享
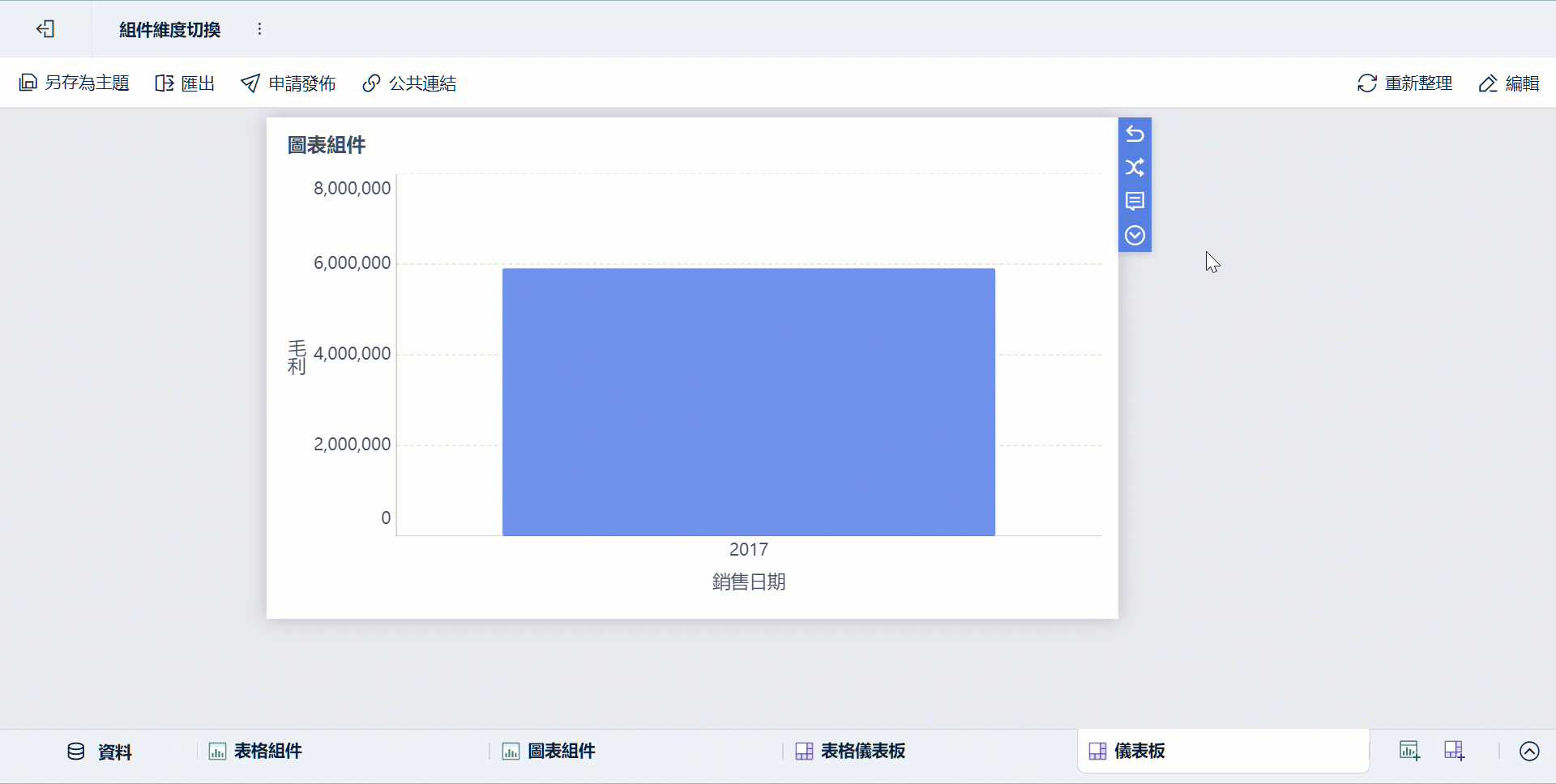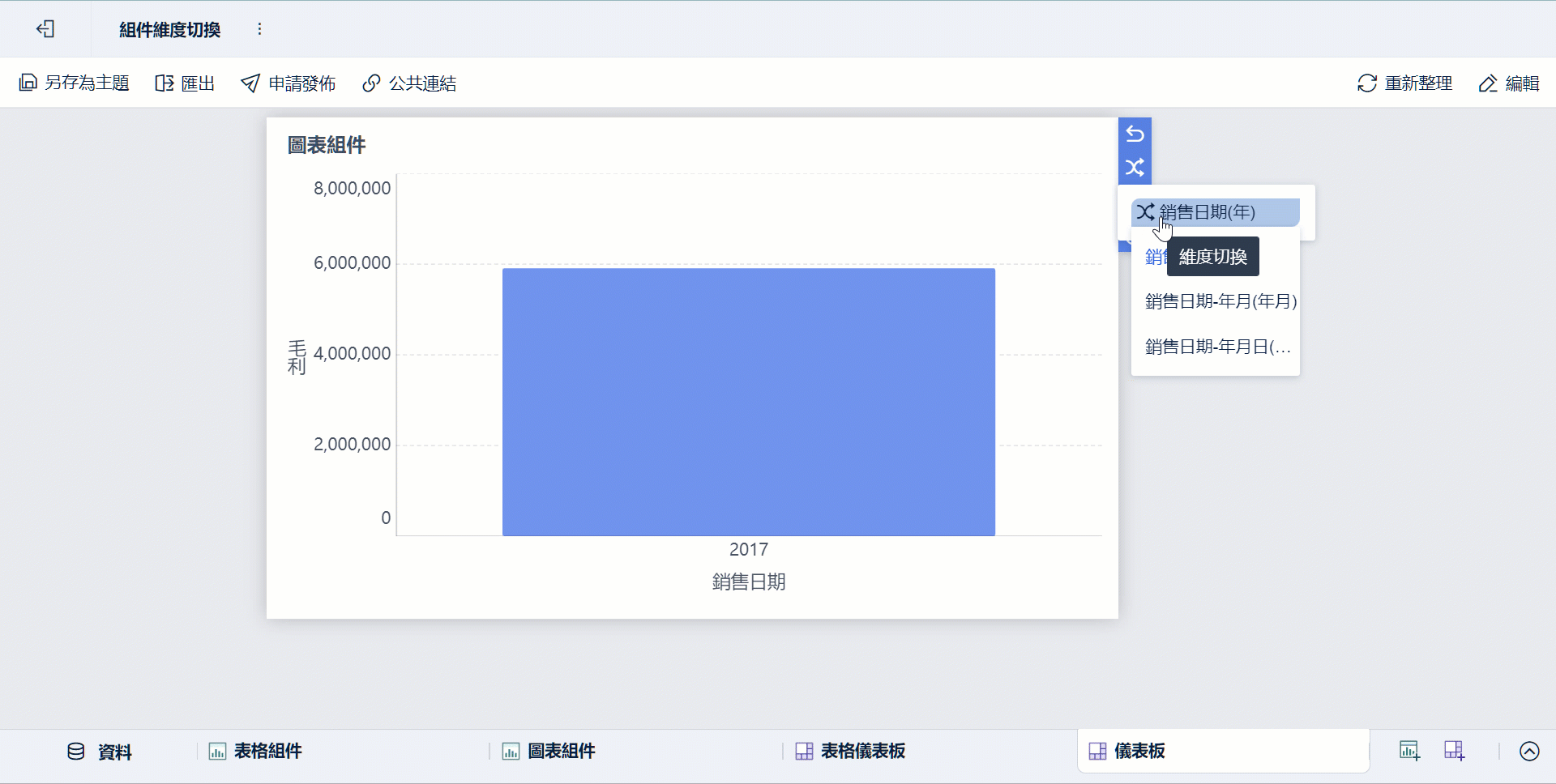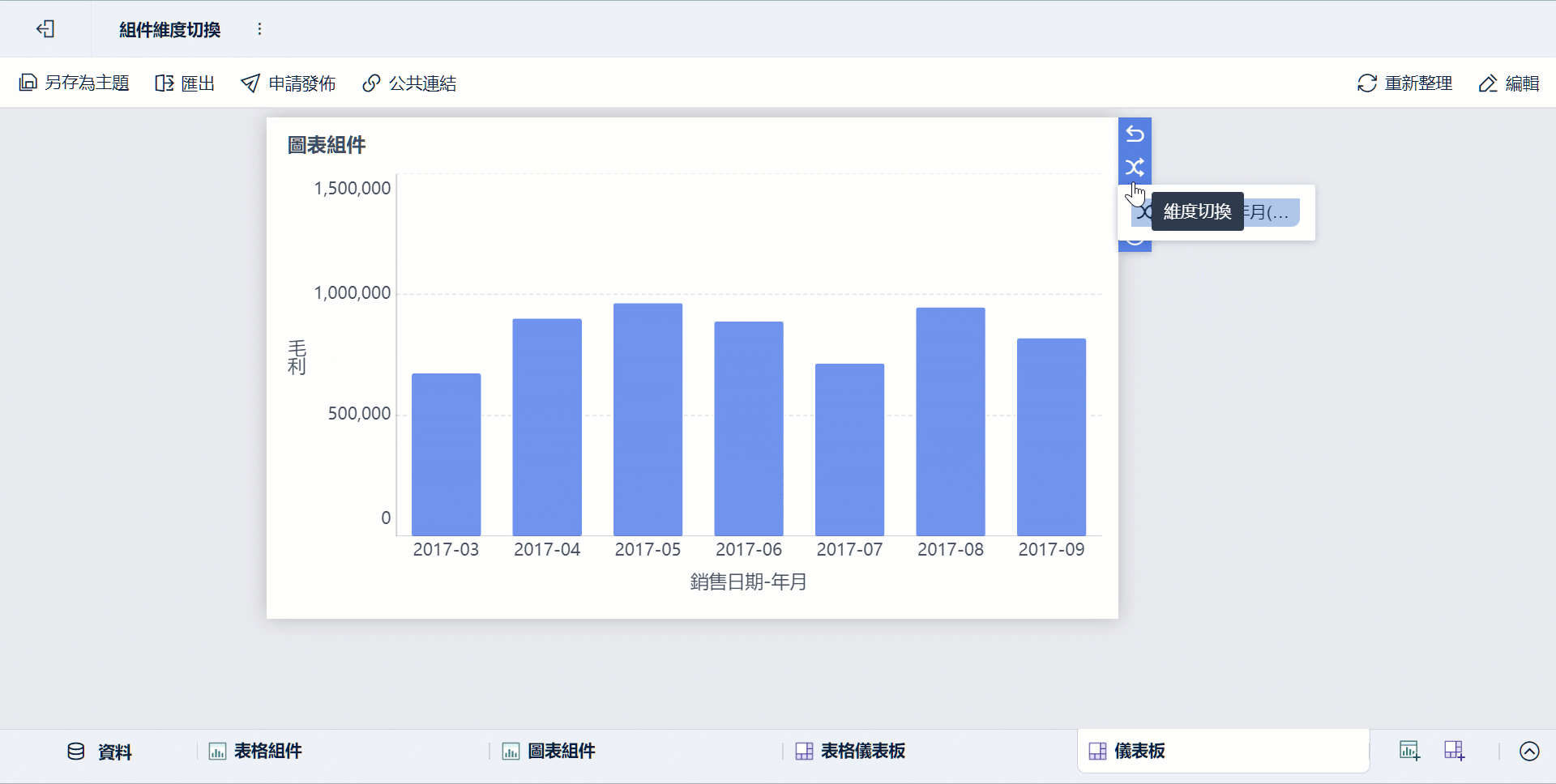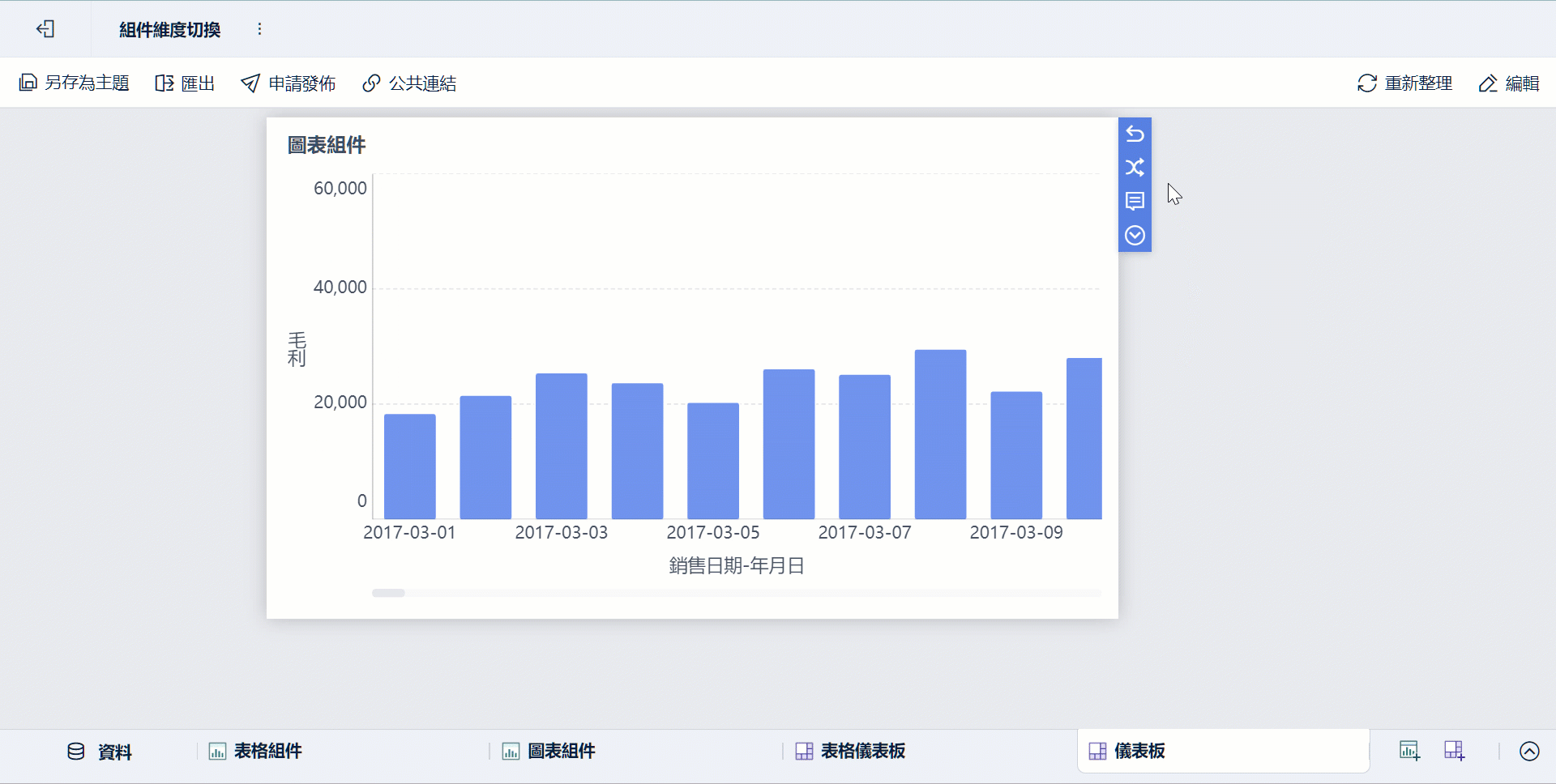
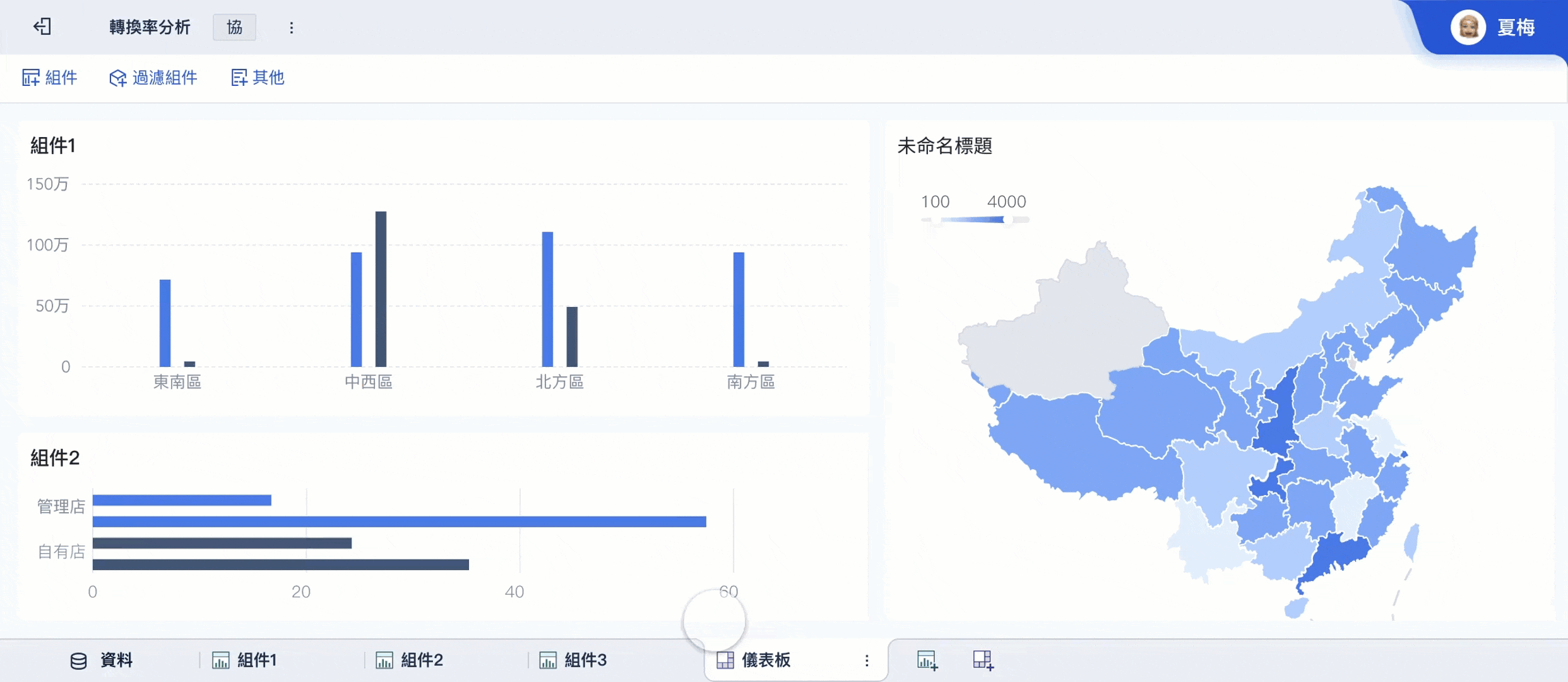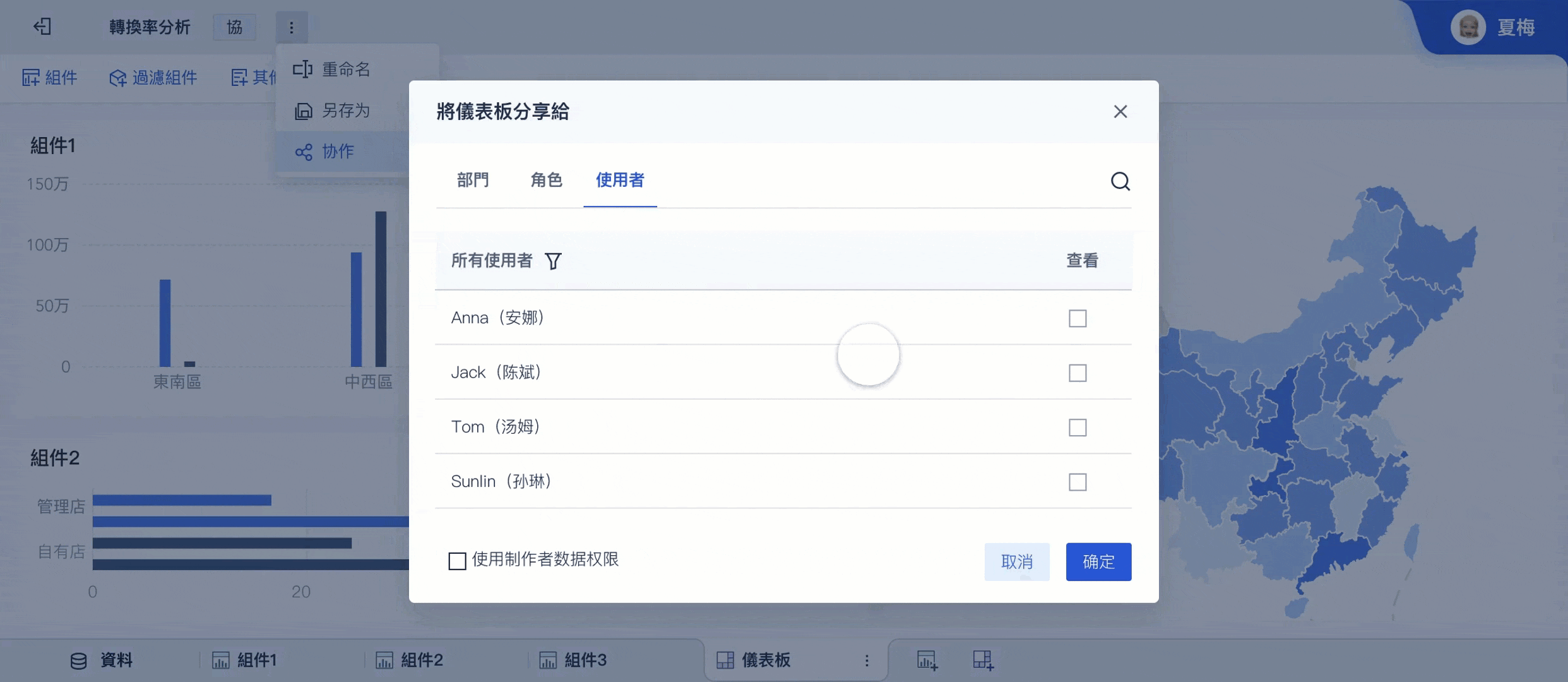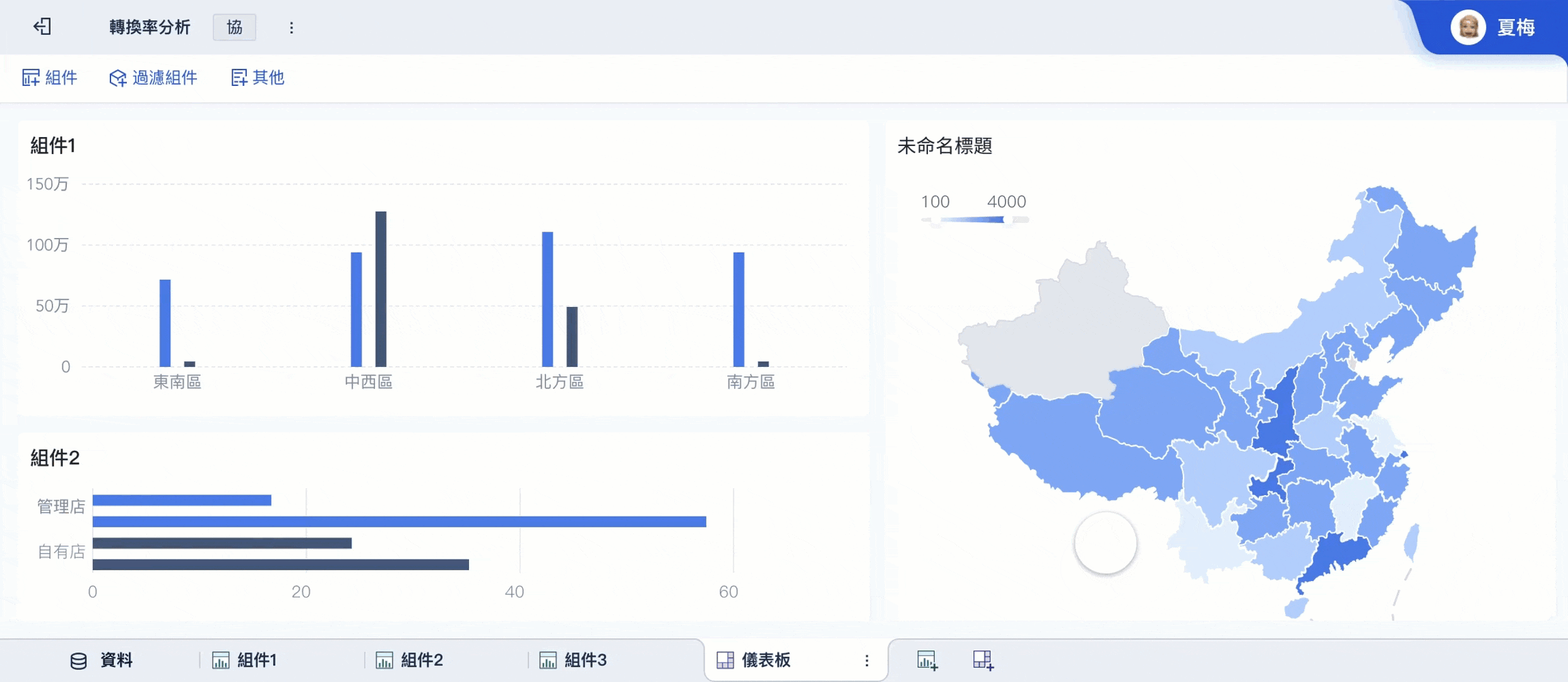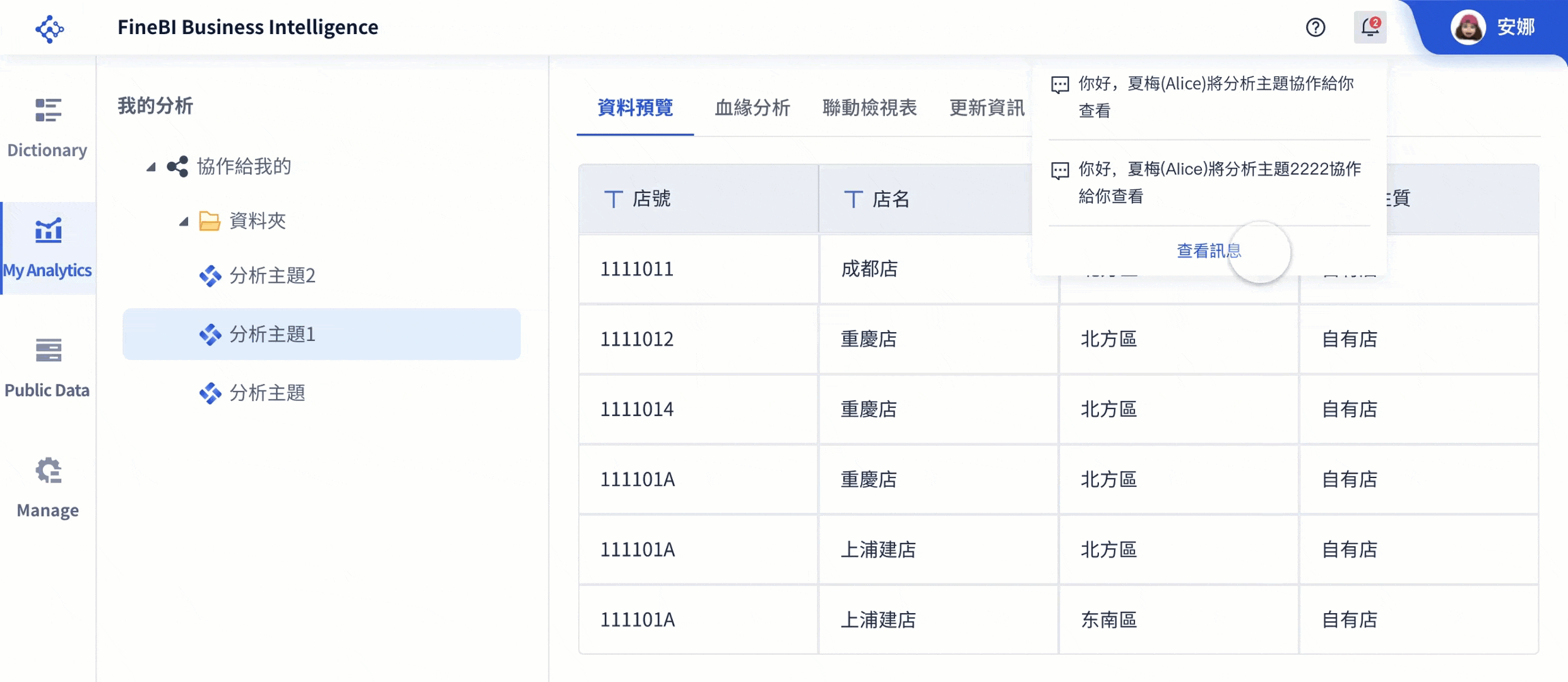
這種分工很實用,因為:
- Python保留高度分析彈性
- FineBI負責低門檻使用與跨部門擴散
- 分析成果可被持續追蹤,而非一次性簡報
根據常見企業導入做法,FineBI的優勢在於資料處理、分析與可視化可以在同一平台完成較多工作,比起需要多工具切換的模式,更適合讓非技術部門長期使用。
2. 實務場景:將Python分析結果接入FineBI儀表板
當 Python 已經算出關鍵結果,接下來最重要的是讓決策者快速看懂。
例如,你可以用 Python 先完成:
- 每日銷售預測值
- 顧客流失風險分數
- 促銷成效比較指標
- 異常訂單偵測標記
- 地區別營運績效排名
接著把這些欄位接入 FineBI,做成以下儀表板:
- 高風險客戶清單
- 各區域異常警示圖
- 行銷活動成效比較面板
- 產品線趨勢追蹤圖
- 主管用 KPI 戰情板
相較只交付 Excel 或 PDF,FineBI 的價值是讓使用者可以進一步篩選、聯動、鑽取與追查。換句話說,Python負責算答案,FineBI負責讓更多人使用答案。
3. 實務場景:跨部門共享Python資料分析成果與管理指標
企業分析常失敗,不是因為沒有結論,而是結論無法被跨部門共同採用。這時候,FineBI 就能成為 Python 成果的落地層。
常見共享方式包括:
- 業務部看營收、客戶與區域績效
- 行銷部看活動轉換、投放回報與客群變化
- 營運部看庫存、出貨與異常波動
- 管理層看整體 KPI 與趨勢預警
FineBI 在這類情境的優勢,通常有幾點:
- 拖拉式操作較容易推廣到業務部門
- 主題模型可整理跨表資料關係
- 儀表板共享比單次報表更適合持續管理
- 可把分析結果變成部門共用指標語言
若企業希望把 Python 分析從個人能力升級為組織能力,FineBI 是很適合的承接工具。對於想降低前線使用門檻的團隊來說,除了 FineBI,不少企業也會評估像 FineBI 這類強調分析落地與共享效率的產品思路,核心目標都相同:讓分析結果真正進入決策流程,而不是停在技術端。
六、初學者與企業常見問題:如何降低導入Python統計分析門檻
降低導入門檻的重點,不是把所有人都訓練成資料科學家,而是讓每個角色都能在適合的層次上使用分析。初學者先建立基本流程,企業則先建立共同標準。
1. Python統計分析入門最常見的學習誤區
初學者最常見的問題,不是學太少,而是學太雜。以下幾個誤區尤其常見:
- 一開始就追求機器學習
- 但連資料清理、分組統計都還不熟
- 只看影片不動手做
- 看懂不等於會做
- 只背函式,不理解分析目的
- 容易遇到資料一變就卡住
- 忽略統計基本概念
- 會寫程式,但不會解讀結果
- 只做乾淨範例
- 真實工作資料通常不整齊
比較好的做法是:先把描述統計、資料整理、基本視覺化練熟,再往推論統計與模型分析走。
2. 該先看教學、做範例,還是直接從公司資料開始
最好的答案是:先用小範例建立手感,再盡快碰真實資料。
這樣安排通常最有效:
- 先學最基本操作
- 讀檔、篩選、分組、合併、畫圖
- 做2到3個完整範例
- 熟悉標準分析流程
- 再接公司資料
- 從一個明確問題開始,不要一次做太大
- 逐步建立模板
- 把可重用程式整理起來
如果一開始直接碰公司完整資料,常會因為欄位混亂、定義不清而挫折;但如果只做教學範例,又容易無法接軌實務。折衷做法通常效果最好。
3. 如何建立可重複使用的分析流程與團隊協作機制
企業要真正用好 python 統計分析,關鍵不是個人高手,而是流程標準化。
建議優先建立這些機制:
- 統一資料欄位與指標定義
- 避免不同部門各算各的
- 建立分析模板
- 例如月報、活動成效、異常監控等固定腳本
- 使用版本控制
- 讓程式與邏輯可追蹤
- 將輸出結果接入 BI
- 提高共享效率與使用頻率
- 安排分層培訓
- 分析人員學 Python,業務部門學看板使用
根據常見企業推動經驗,真正可持續的模式通常是:
- 分析師用 Python 做深度處理
- 業務與主管用 FineBI 看結果與追蹤指標
- IT 或資料團隊負責資料串接與治理
這樣的分工能兼顧分析深度與組織擴散,導入阻力也相對較低。
如果你想開始做 python 統計分析,最實際的起點不是一次學完所有套件,而是先選一個真實問題,用一份資料做完一次完整流程。當你能從資料清理、描述統計、方法選擇到結果解讀走完一輪,之後再加入更進階的統計工具、視覺化方法與 BI 平台,學習速度會快很多。
而對企業來說,Python 負責「分析深度」,FineBI 負責「決策落地」。當兩者搭配得當,分析就不再只是技術工作,而會成為日常營運與管理的一部分。
FAQs
AI 能自動化資料清理、報表製作與部分分析流程,但需求定義、商業洞察、指標設計與決策支援仍需要數據分析師,因此更可能是協作而非完全取代。
Python 相對適合初學者,語法較簡潔、學習資源多,常被用於資料分析、AI、自動化與程式入門教學。







免費資源下載