A big data pipeline is a system designed to manage and transform massive datasets efficiently. It ensures the seamless movement of data between systems while maintaining speed, scalability, and reliability. You can think of it as a series of steps that extract raw data from various sources, process it into a usable format, and load it into storage or analytical tools. This process, known as ETL (Extract, Transform, Load), plays a critical role in cleaning, enriching, and normalizing data for meaningful insights. By handling both structured and unstructured data, it empowers organizations to make informed, data-driven decisions.

Big data pipelines play a vital role in modern data management. They ensure that organizations can handle vast amounts of information efficiently while maintaining accuracy and speed. By enabling seamless data flow, these pipelines empower businesses to unlock the full potential of their data.

You rely on accurate and timely data to make informed decisions. A big data pipeline ensures that raw data from multiple sources is processed and transformed into actionable insights. This process allows you to analyze trends, predict outcomes, and respond to challenges effectively. Without a pipeline, decision-making becomes slower and less reliable due to incomplete or outdated information. For example, businesses using real-time data pipelines can monitor customer behavior instantly, enabling them to adjust strategies and improve customer experiences.
Manual data handling often leads to errors and inefficiencies. A big data pipeline automates repetitive tasks, such as data extraction, cleaning, and transformation. Automation reduces human error and saves time, allowing you to focus on analyzing results rather than managing data. Streamlined workflows also ensure that data moves smoothly between systems without delays. For instance, e-commerce platforms use automated pipelines to process transaction data, ensuring accurate inventory updates and personalized recommendations for customers.
As your data grows, managing it becomes more challenging. A big data pipeline provides the scalability needed to handle increasing volumes of structured and unstructured data. It adapts to your organization’s needs, ensuring consistent performance even as data complexity rises. Efficient pipelines also optimize resource usage, reducing costs while maintaining speed. For example, cloud-based pipelines allow businesses to scale their operations without investing heavily in physical infrastructure, making them ideal for growing companies.

A big data pipeline consists of several essential components that work together to ensure the smooth flow and processing of data. Each component plays a specific role in transforming raw data into valuable insights.
Data ingestion is the first step in a big data pipeline. It involves collecting raw data from various sources and bringing it into the pipeline for processing. These sources can include databases, APIs, IoT devices, social media platforms, or even logs from applications. Tools like Apache Kafka and Google Cloud Dataflow are commonly used for this purpose. They enable you to handle both batch and real-time data ingestion efficiently.
For example, Apache Kafka supports high-throughput data streaming, making it ideal for scenarios where you need to process continuous streams of data, such as monitoring website traffic or tracking sensor data in real time. By automating the ingestion process, you can ensure that data flows seamlessly into the pipeline without delays or interruptions.
Once data enters the pipeline, preprocessing becomes crucial. This step cleans, organizes, and transforms raw data into a usable format. Preprocessing often includes tasks like removing duplicates, handling missing values, and converting data into a consistent structure. Without this step, analyzing data accurately becomes challenging.
Tools like Apache Spark and dbt excel in preprocessing large datasets. Apache Spark, for instance, performs in-memory data processing, which speeds up transformations and ensures scalability. Preprocessing also involves enriching data by combining it with other datasets to provide more context. For example, you might merge customer transaction data with demographic information to gain deeper insights into purchasing behavior.

After preprocessing, storing the data securely and efficiently is essential. Data storage ensures that processed data remains accessible for analysis, reporting, or further transformations. Depending on your needs, you can choose between on-premises storage solutions or cloud-based platforms.
Cloud-based storage options, such as those integrated with Google Cloud Dataflow, offer scalability and flexibility. They allow you to store vast amounts of structured and unstructured data without worrying about physical infrastructure. Additionally, these platforms often provide built-in security features to protect sensitive information. Efficient storage solutions ensure that your data remains organized and ready for use in downstream processes like visualization or machine learning.
Data transformation is a critical step in a big data pipeline. It involves converting raw, unstructured, or semi-structured data into a structured and analyzable format. This process ensures that the data aligns with your specific requirements for analysis, reporting, or machine learning tasks. Transformation often includes operations like filtering, aggregating, enriching, and normalizing data.

Tools like Apache Spark, Hadoop, and Flink excel in handling large-scale data transformations. For instance, Apache Spark performs in-memory processing, which speeds up transformations and supports both batch and streaming data. You can use SQL-based tools like Upsolver to simplify the transformation process further by automating complex tasks. These technologies allow you to process massive datasets efficiently, ensuring that your data is ready for downstream applications.
For example, if you are working with customer data, transformation might involve merging transaction records with demographic details. This enriched dataset can then be used to identify purchasing trends or predict future behaviors. By transforming your data effectively, you unlock its full potential for generating actionable insights.
Once the data is transformed, the next step is delivering it to the appropriate destination and visualizing it for decision-making. Data delivery ensures that the processed data reaches storage systems, analytical tools, or dashboards where it can be accessed and utilized. Visualization, on the other hand, translates complex datasets into easy-to-understand charts, graphs, or reports.
Technologies like Google Cloud Dataflow and Apache Kafka facilitate seamless data delivery. These tools support both real-time and batch processing, ensuring that your data reaches its destination without delays. For visualization, platforms like Tableau or Power BI are commonly used. They allow you to create interactive dashboards that provide a clear view of your data.

For instance, an e-commerce company might use a big data pipeline to deliver real-time sales data to a dashboard. This dashboard could display metrics like revenue, customer behavior, and inventory levels, enabling quick and informed decisions. By combining efficient delivery with intuitive visualization, you can make your data accessible and actionable for your team.
Big data pipelines come in various forms, each tailored to specific data processing needs. Understanding these data pipelines helps you choose the right approach for your organization’s goals and challenges.
Batch data pipelines process large volumes of data at scheduled intervals. This type is ideal when you need to analyze historical data or perform tasks that do not require immediate results. For example, you might use a batch pipeline to generate daily sales reports or aggregate customer feedback collected over a week.
Batch pipelines excel in handling structured and unstructured data efficiently. They allow you to process data in bulk, reducing the computational load during peak hours. Tools like Apache Hadoop and Apache Spark are commonly used for batch processing. These tools enable you to perform complex transformations and analyses on massive datasets without compromising performance.
Key Advantage: Batch pipelines ensure scalability and cost-effectiveness, making them suitable for organizations with predictable data processing needs.
Real-time data pipelines process data as it arrives, enabling you to gain insights and take action instantly. This type is essential for scenarios where timely information is critical, such as monitoring financial transactions for fraud or tracking user behavior on a website.
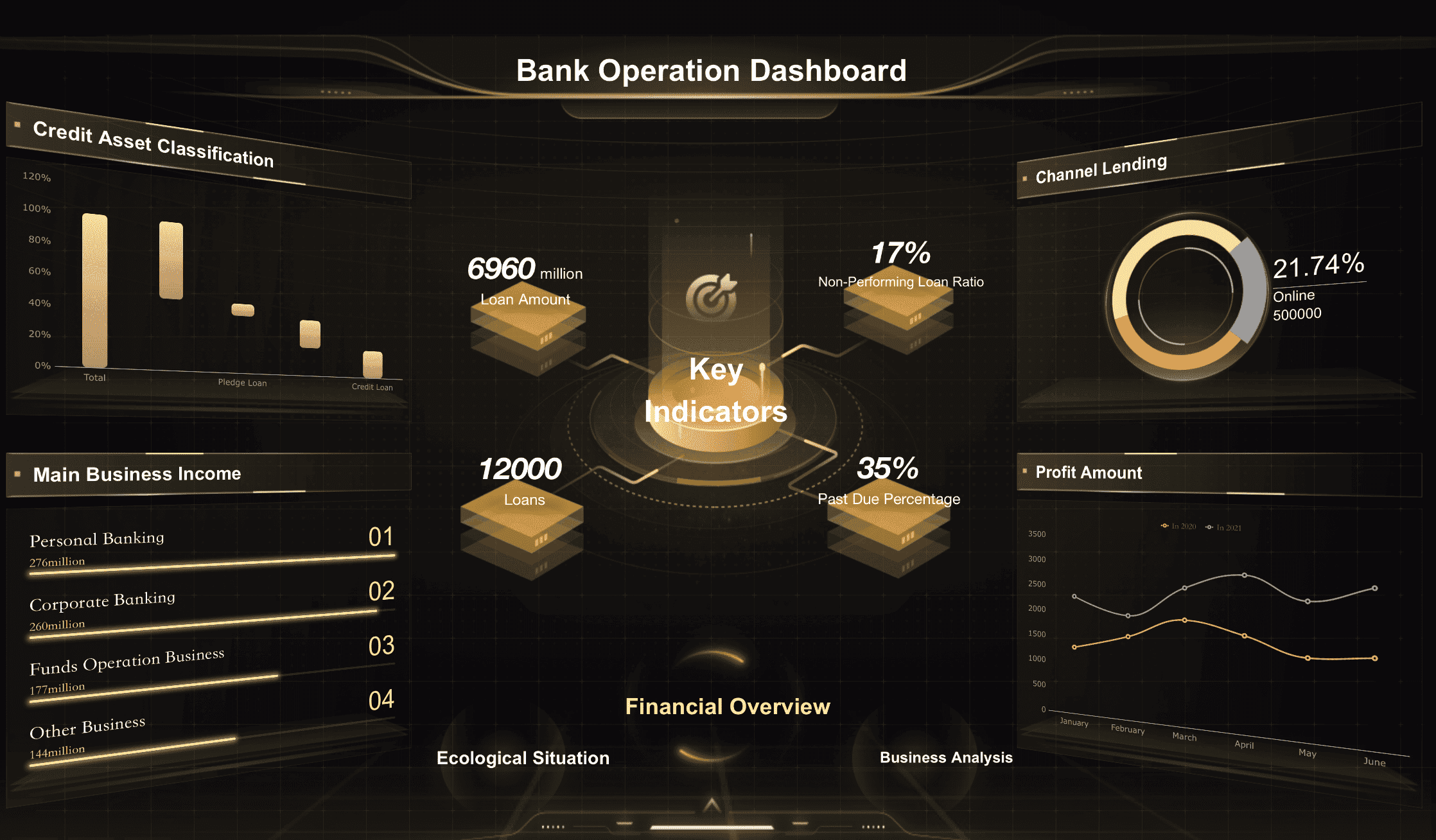
Real-time pipelines rely on technologies like Apache Kafka, Flink, and Google Cloud Dataflow. These tools support continuous data streaming, ensuring that your pipeline can handle high-velocity data without delays. For instance, an e-commerce platform might use a real-time pipeline to update inventory levels and provide personalized recommendations to customers in seconds.
Key Advantage: Real-time pipelines empower you to make data-driven decisions quickly, enhancing responsiveness and operational efficiency.
Hybrid data pipelines combine the strengths of batch and real-time processing. This type offers flexibility, allowing you to process data in real time while also handling large-scale batch tasks. Hybrid pipelines are particularly useful when your organization deals with diverse data sources and varying processing requirements.
For example, a hybrid pipeline might process real-time sensor data from IoT devices while simultaneously running batch jobs to analyze historical trends. Tools like Apache Beam support hybrid pipelines by providing a unified framework for both batch and streaming data.
Key Advantage: Hybrid pipelines provide versatility, enabling you to address both immediate and long-term data processing needs effectively.
By selecting the right type of big data pipeline, you can optimize your data workflows and ensure that your organization remains agile and informed.
Cloud-based data pipelines have revolutionized how you manage and process large datasets. These pipelines operate on cloud platforms, offering unmatched scalability, flexibility, and cost-efficiency. By leveraging cloud infrastructure, you can handle massive data volumes without investing in physical hardware or worrying about maintenance.
Key Insight: Cloud-based pipelines simplify data workflows by providing on-demand resources and seamless integration with other cloud services.

Several tools and platforms make it easier to build and manage cloud-based pipelines:
These tools provide pre-built templates, automation features, and robust security measures, making them ideal for modern data workflows.
Cloud-based data pipelines play a crucial role in various industries:
Fact: According to research, efficient data pipelines ensure data quality, scalability, and timely decision-making, which are essential for business intelligence.
By adopting cloud-based data pipelines, you can streamline your data processes, reduce costs, and gain actionable insights. These pipelines empower you to stay competitive in a data-driven world.
Understanding the architecture of a big data pipeline helps you grasp how data flows seamlessly from raw collection to actionable insights. Each stage in the architecture plays a vital role in ensuring efficiency, scalability, and accuracy.

A big data pipeline follows a structured workflow that begins with data collection and ends with delivering insights. The process starts with data ingestion, where raw data from multiple sources, such as IoT devices, social media platforms, or transaction logs, enters the pipeline. This data then undergoes preprocessing to clean and organize it for further use. After preprocessing, the pipeline stores the data securely in databases, data lakes, or warehouses.
The next step involves data transformation, where the raw or semi-structured data is converted into a structured format suitable for analysis. Finally, the pipeline delivers the processed data to analytical tools or visualization platforms, enabling you to make informed decisions. For example, retailers often use this workflow to analyze real-time customer interactions for personalized recommendations while simultaneously forecasting inventory needs based on historical data.
Fact: Streaming data pipelines can populate data lakes or warehouses in real time, allowing businesses to act on insights before they lose value.
The architecture of a big data pipeline consists of several interconnected stages, each designed to handle specific tasks:
Example: Observability pipelines collect logs, metrics, and traces from various sources, processing the data in real time. This approach helps you analyze and enrich data as it flows through the pipeline.
Building an efficient big data pipeline requires the right tools and technologies. Each stage of the pipeline benefits from specialized solutions that enhance performance and scalability:
Hybrid processing architectures, which combine batch and real-time processing, have become increasingly popular. These architectures allow you to address diverse data requirements effectively. For instance, you can process real-time sensor data while analyzing historical trends in parallel.
Insight: Cloud-based tools simplify pipeline management by offering on-demand resources and seamless integration with other services.
By understanding the architecture of a big data pipeline, you can design workflows that align with your organization’s goals. This knowledge empowers you to handle complex datasets efficiently and extract meaningful insights.

Big data pipelines enable you to harness real-time analytics, transforming how e-commerce and marketing operate. By processing data as it arrives, you can monitor customer behavior, track sales trends, and adjust strategies instantly. For example, streaming data pipelines allow you to analyze website traffic in real time. This capability helps you identify popular products, optimize pricing, and deliver personalized recommendations.
Tools like Google Cloud Dataflow excel in real-time data processing. They provide serverless ETL capabilities, ensuring seamless integration with other services. With these tools, you can automate data workflows, reducing manual effort and improving accuracy. For instance, an e-commerce platform might use a pipeline to update inventory levels dynamically, ensuring customers see only available products.
Fact: Real-time analytics improve customer experiences by delivering timely insights, enabling businesses to respond to market demands faster.
In manufacturing, big data pipelines play a crucial role in predictive maintenance. By analyzing sensor data from equipment, you can identify potential issues before they lead to costly downtime. This proactive approach minimizes disruptions and extends the lifespan of machinery.
Streaming data pipelines process sensor data continuously, providing actionable insights in real time. For example, a factory might use AWS Data Pipeline to monitor temperature and vibration levels in machines. When anomalies occur, the system triggers alerts, allowing you to address problems immediately. Automated pipelines also streamline data integration, combining information from multiple sources for a comprehensive view of operations.
Key Insight: Predictive maintenance reduces operational costs and enhances efficiency, making it a valuable application of big data pipelines.
Fraud detection relies heavily on the speed and accuracy of data analysis. Big data pipelines empower you to detect suspicious activities in real time, protecting your organization and customers from financial losses. By processing transaction data as it occurs, you can identify patterns that indicate fraud, such as unusual spending behaviors or unauthorized access attempts.

Technologies like Google Cloud Dataflow and Apache Kafka support high-throughput data streaming, ensuring timely detection of fraudulent activities. These tools integrate seamlessly with machine learning models, enhancing their ability to predict and prevent fraud. For instance, a bank might use a pipeline to analyze credit card transactions, flagging anomalies for further investigation.
Example: Financial institutions leverage big data pipelines to comply with regulations, improve security, and build customer trust.
By adopting big data pipelines, you can unlock powerful use cases across industries. Whether you aim to enhance customer experiences, optimize operations, or safeguard assets, these pipelines provide the tools and insights needed to succeed.
Streaming platforms rely on big data pipelines to deliver personalized recommendations that enhance user experiences. These pipelines process vast amounts of data in real time, ensuring that every suggestion aligns with individual preferences. By analyzing viewing habits, search queries, and user interactions, you can create tailored content recommendations that keep audiences engaged.
Big data pipelines collect and process user data from multiple sources, such as app activity, watch history, and ratings. Tools like Google Cloud Dataflow and AWS Data Pipeline automate this process, ensuring seamless data transformation. These tools handle both batch and real-time data, making it possible to update recommendations instantly as user behavior changes.
Example: A streaming platform might use a pipeline to analyze a user’s recent viewing history. If the user watches several action movies, the system can recommend similar titles or trending action films.

Several tools play a crucial role in building recommendation systems:
These technologies work together to create a seamless pipeline that delivers actionable insights. By leveraging these tools, you can build a recommendation engine that adapts to user preferences dynamically.
Streaming platforms like Netflix and Spotify use big data pipelines to power their recommendation engines. Netflix analyzes viewing habits to suggest shows and movies, while Spotify curates playlists based on listening history. These personalized experiences not only delight users but also set these platforms apart in a competitive market.
Fact: According to industry research, platforms with effective recommendation systems see higher user engagement and longer session durations.
By implementing big data pipelines, you can transform raw user data into meaningful insights. This capability allows you to deliver personalized recommendations that resonate with your audience, driving engagement and loyalty.
Building a big data pipeline comes with its own set of challenges. These obstacles can impact the efficiency, scalability, and reliability of your data workflows. Understanding these challenges helps you prepare better strategies to overcome them.

Handling large datasets often requires significant computational power and storage. Cloud platforms like AWS, Azure, and Google Cloud offer scalable solutions, but costs can escalate quickly if not managed properly. You need to monitor resource usage and optimize your pipeline to avoid unnecessary expenses. For example, automating data transformation tasks reduces manual intervention and improves efficiency, as highlighted by Data Engineers at AWS.
"Data pipelines automate data transformation tasks, allowing data engineers to focus on finding business insights."
To manage costs effectively, consider using tools that provide pay-as-you-go pricing models. These tools allow you to scale resources based on your needs, ensuring you only pay for what you use. Additionally, optimizing data workflows by removing redundant processes can help reduce resource consumption.
Big data pipelines often involve multiple components, such as data ingestion, preprocessing, storage, and transformation. Integrating these components seamlessly can be complex. You may face challenges in ensuring that each stage works efficiently without bottlenecks. According to Data Engineers at Dremio, automation plays a crucial role in simplifying these processes. Learn more about data integration platforms.
"Data pipelines should use automation to reduce manual work."
Using automation tools like Apache Airflow or cloud-based services simplifies the orchestration of tasks. These tools help you manage dependencies and ensure smooth data flow. However, you must also address implementation hurdles, such as configuring tools correctly and ensuring compatibility between systems. Testing your pipeline thoroughly before deployment minimizes errors and ensures reliability.

Data quality is critical for generating accurate insights. Inconsistent or incomplete data can lead to flawed analyses and poor decision-making. You need to implement robust preprocessing steps to clean and standardize your data. This includes removing duplicates, handling missing values, and ensuring uniform formats.
Scalability also plays a role in maintaining data quality. As noted by Data Engineers at Nexla, scalable tools are essential for processing large datasets effectively. Without scalability, your pipeline may struggle to handle increasing data volumes, leading to delays and errors.
"Scalability of data pipeline tools is crucial for processing large amounts of data."
To ensure consistency, consider using data validation tools that check for errors at each stage of the pipeline. Regular audits of your data workflows also help identify and resolve issues proactively.
Scalability and performance are essential for building a robust big data pipeline. As your data grows, your pipeline must handle increasing volumes without compromising speed or efficiency. Optimizing these aspects ensures that your pipeline remains reliable and cost-effective, even under heavy workloads.

Cloud platforms like AWS, Azure, and Google Cloud offer unmatched scalability. They allow you to adjust resources dynamically based on your data processing needs. For example, you can scale up during peak data loads and scale down during quieter periods. This flexibility ensures consistent performance without overloading your systems.
"Cloud platforms provide flexibility and scalability for modern data projects," according to Data Engineers at Fission Labs.
Using cloud-based solutions also eliminates the need for expensive physical infrastructure. You can focus on optimizing your pipeline rather than managing hardware. Tools like Google Cloud Dataflow and AWS Data Pipeline simplify this process by automating resource allocation.
Automation plays a critical role in enhancing performance. By automating repetitive tasks like data transformation and validation, you reduce manual intervention and speed up workflows. Automation tools such as Apache Airflow and Apache NiFi help you orchestrate complex processes efficiently.
"Data pipelines should use automation to reduce manual work," emphasize the Data Engineering Team at Dremio.
For instance, automating data cleaning ensures that your pipeline processes raw data quickly and accurately. This approach not only saves time but also minimizes errors, allowing you to focus on deriving insights from your data.
Efficient resource management is key to maintaining performance. Overusing resources can lead to higher costs, while underutilization may cause delays. Monitoring tools like AWS CloudWatch and Google Cloud Monitoring help you track resource usage and identify bottlenecks.
"Scalability of data pipeline tools is crucial for processing large amounts of data," highlight Data Engineers at Nexla.
You can optimize resource usage by implementing load balancing and caching mechanisms. Load balancing distributes tasks evenly across servers, preventing overloads. Caching stores frequently accessed data temporarily, reducing the need for repeated processing.
Selecting the right tools ensures that your pipeline can handle growing data volumes. Frameworks like Apache Spark and Apache Flink excel in processing large datasets efficiently. These tools support both batch and real-time data, making them ideal for diverse use cases.
For example, Apache Spark performs in-memory processing, which speeds up data transformations. This capability is particularly useful for real-time applications like fraud detection or personalized recommendations.

Regular testing and monitoring help you identify performance issues before they escalate. Tools like Datadog and Prometheus provide real-time insights into your pipeline’s health. By analyzing metrics such as latency and throughput, you can make informed decisions to improve performance.
"Data pipelines automate data transformation tasks, allowing data engineers to focus on finding business insights," note Data Engineers at AWS.
Testing your pipeline under different conditions ensures that it performs well during peak loads. Stress testing, for instance, simulates high data volumes to evaluate scalability. This proactive approach helps you address potential issues and maintain reliability.
By implementing these strategies, you can optimize the scalability and performance of your big data pipeline. A well-optimized pipeline not only handles growing data demands but also delivers faster insights, empowering you to make data-driven decisions with confidence.
Big data pipelines rely on a variety of tools and technologies to ensure efficient data movement, processing, and analysis. Each tool serves a specific purpose, helping you build robust and scalable pipelines tailored to your needs.

Data ingestion tools play a critical role in collecting raw data from multiple sources and feeding it into your pipeline. These tools handle high volumes of data, ensuring smooth and uninterrupted data flow.
"Streaming data pipelines process data in real-time, allowing companies to act on insights before they lose value." Tools like Kafka make this possible by enabling ultra-low latency data ingestion.
By using these tools, you can ensure that your pipeline captures data efficiently, whether in real-time or batch mode.
Data processing tools transform raw data into meaningful insights. These tools handle tasks like cleaning, filtering, and aggregating data, preparing it for analysis or visualization.
"Companies with real-time data pipelines can update information continuously, enabling faster data processing and more accurate decisions." Tools like Spark and Hadoop empower you to achieve this by automating complex data workflows.
These processing tools ensure that your pipeline delivers clean, organized, and actionable data, ready for downstream applications.
Cloud-based solutions have revolutionized big data pipelines by offering unmatched scalability, flexibility, and cost-efficiency. These tools simplify the management of large datasets, allowing you to focus on deriving insights rather than maintaining infrastructure.

"Streaming architecture is ideal for businesses requiring ultra-low latency for their transactions." Cloud-based solutions like Dataflow make this achievable by providing real-time processing capabilities.
By leveraging cloud-based tools, you can build scalable pipelines that adapt to your organization’s growing data needs. These solutions also reduce operational costs, as you only pay for the resources you use.
Using the right tools and technologies ensures that your big data pipeline operates efficiently and reliably. Whether you need to ingest data from diverse sources, process it for insights, or scale your operations with cloud-based solutions, these tools provide the foundation for success.
When building a big data pipeline, you face a critical decision: Should you choose open-source tools or proprietary solutions? Each option offers unique advantages and challenges. Understanding these differences helps you select the right tools for your specific needs.

Open-source tools provide flexibility and cost-effectiveness. These tools allow you to customize features to fit your requirements. They also eliminate licensing fees, making them an attractive choice for organizations with limited budgets.
"Streaming data pipelines process data in real-time, allowing companies to act on insights before they lose value." Open-source tools like Kafka make this possible by enabling ultra-low latency data ingestion.
However, open-source tools require skilled professionals for setup and maintenance. Without proper expertise, managing these tools can become challenging.
Proprietary tools offer convenience and reliability. These tools come with dedicated support teams, user-friendly interfaces, and integrated features. They are ideal for organizations that prioritize ease of use and quick deployment.
"Companies with real-time data pipelines can update information continuously, enabling faster data processing and more accurate decisions." Proprietary tools excel in delivering this efficiency through their robust infrastructure.
Despite their benefits, proprietary tools involve licensing fees and vendor lock-in. These factors can increase costs and limit flexibility.

Your choice depends on your organization’s goals, budget, and technical expertise. Consider the following factors:
For example, an online retailer might use open-source tools like Apache Kafka to monitor real-time sales and inventory. This approach ensures flexibility and cost savings. On the other hand, a healthcare provider might choose Google Dataflow for its seamless integration with other Google Cloud services, ensuring reliable and secure data processing.
By weighing the pros and cons of open-source and proprietary tools, you can build a big data pipeline that aligns with your needs. Both options empower you to process data efficiently, enabling faster insights and better decision-making.

Big data pipelines are evolving rapidly, driven by the increasing demand for real-time insights and efficient data processing. One significant trend is the rise of streaming-first architectures. These architectures prioritize real-time data processing over traditional batch methods. Businesses now rely on streaming platforms to analyze customer behavior instantly. For example, streaming platforms like Netflix use tools such as Apache Druid to process and analyze user data in real time. This approach allows them to understand viewer preferences and deliver personalized recommendations.
Another trend is the integration of serverless technologies into pipeline workflows. Serverless solutions reduce the need for managing infrastructure, enabling you to focus on building and optimizing your pipeline. Tools like Google Cloud Dataflow exemplify this shift by offering fully managed services that handle both batch and streaming data seamlessly. These advancements make it easier to scale pipelines while maintaining cost efficiency.
Finally, the adoption of data mesh architectures is transforming how organizations manage data pipelines. Instead of centralizing data processing, data mesh promotes decentralized ownership. Teams can build and manage their own pipelines, ensuring faster and more tailored data workflows. This trend empowers businesses to adapt quickly to changing data needs.
Key Insight: Staying updated with these trends ensures that your pipeline remains competitive and capable of handling modern data challenges.
AI and machine learning are revolutionizing how you optimize big data pipelines. These technologies automate complex tasks, such as anomaly detection, data transformation, and workflow orchestration. For instance, machine learning models can identify patterns in data streams, enabling you to predict and address potential bottlenecks before they occur.

AI also enhances data quality management. By using AI-driven tools, you can detect inconsistencies, fill in missing values, and standardize formats automatically. This ensures that your pipeline delivers accurate and reliable data for analysis. Netflix, for example, leverages AI to analyze user behavior and refine its recommendation algorithms. This capability allows them to create viewer profiles based on demographics and interests, improving user engagement.
Additionally, AI-powered tools simplify pipeline monitoring and maintenance. These tools provide real-time insights into pipeline performance, helping you identify inefficiencies and optimize resource usage. By integrating AI into your pipeline, you can reduce manual intervention, improve scalability, and enhance overall efficiency.
Fact: AI and machine learning not only streamline pipeline operations but also unlock new possibilities for innovation and growth.
Edge computing is reshaping the landscape of big data pipelines by bringing data processing closer to the source. This approach reduces latency, enhances security, and minimizes bandwidth usage. For example, IoT devices in manufacturing plants can process sensor data locally, enabling real-time decision-making without relying on centralized systems.

Edge computing also supports real-time analytics in industries like e-commerce and healthcare. By processing data at the edge, you can deliver instant insights and actions. Streaming platforms benefit significantly from this technology. They can analyze user interactions directly on devices, ensuring faster and more personalized recommendations. Visual Flow highlights how data streaming platforms enable swift actions based on customer behavior, a capability enhanced by edge computing.
Moreover, edge computing complements cloud-based pipelines by offloading certain tasks to local devices. This hybrid approach ensures that your pipeline remains efficient and scalable, even as data volumes grow. By adopting edge computing, you can enhance the responsiveness and reliability of your data workflows.
Takeaway: Edge computing empowers you to process data faster and closer to its source, making your pipeline more agile and effective.
A big data pipeline is a powerful system that transforms raw data into actionable insights. It plays a crucial role in modern organizations by enabling efficient data management and analysis. You’ve seen how its components—like ingestion, preprocessing, storage, and transformation—work together to handle vast datasets. The different types of pipelines, from batch to real-time, cater to diverse needs across industries. Despite challenges like complexity and scalability, tools and strategies make building effective pipelines achievable. As data continues to drive innovation, adopting these pipelines will help you stay competitive. Start exploring tools and methods to create your own pipeline today.
Click the banner below to experience FineDataLink for free and empower your enterprise to convert data into productivity!

Mastering Data Pipeline: Your Comprehensive Guide
How to Build a Python Data Pipeline: Steps and Key Points

The Author
Howard
Data Management Engineer & Data Research Expert at FanRuan
Related Articles

12 Best Data Visualization Tools for 2026: Features, Pricing, Pros and Cons
$1 are software platforms that turn raw data into charts, dashboards, maps, and interactive visual stories for analysis and decision making. 12 best data visualization tools for 2026 at a glance
Lewis Chou
Apr 23, 2026

Top 8 Data Visualization softwares You Should Try in 2025
Compare the top 8 data visualization software for 2025, including FineReport, Tableau, Power BI, and more to find the best fit for your business needs.
Lewis
Dec 19, 2025
10 Must-Have Data Visualization Tools for Modern Businesses
Compare the top 10 data visualization tools for 2025 to boost business insights, streamline analytics, and empower smarter decision-making.
Lewis
Dec 17, 2025



