In today’s data-driven world, the rapid growth of big data and the increasing demand for real-time insights have made efficient data management more critical than ever. Data pipelines and ETL pipelines are two essential frameworks for handling data, each designed to address distinct business needs. A data pipeline is primarily focused on the seamless transfer of data between systems, often enabling real-time processing to support dynamic decision-making. On the other hand, an ETL pipeline specializes in extracting, transforming, and loading data, ensuring it is clean, structured, and ready for storage or analysis—particularly for use in applications like business intelligence. While both play vital roles, understanding their unique purposes and advantages is key to selecting the right approach for your data strategy.

Data Pipeline vs ETL: What Is a Data Pipeline?
Definition and Purpose of a Data Pipeline
A data pipeline is an essential system that facilitates the seamless transfer of data from one location to another.
In today's data-driven enterprises, data pipelines serve as the backbone of modern data ecosystems, enabling real-time data flow and seamless integration across diverse platforms. Unlike traditional systems, which often rely on batch processing with significant latency, data pipelines offer unparalleled flexibility and the ability to handle real-time data streams. This makes them indispensable for businesses seeking to optimize operations, enhance decision-making, and maintain a competitive edge.
For instance, studies show that 95% of enterprises leverage data pipelines for real-time monitoring and analytics, highlighting their critical role in supporting agile, data-informed strategies.

Key Components of a Data Pipeline Architecture
Data Sources
Data pipelines commence at data sources, which vary widely from databases and APIs to cloud storage and IoT devices. Each source emits raw data necessitating collection and transit. For instance, a retail company may extract data from diverse platforms such as its e-commerce site, customer relationship management (CRM) system, and inventory databases. The pipeline aggregates this data, ensuring comprehensive availability for subsequent processes.
Data Movement (Real-time vs Batch Processing)
The movement of data within the pipeline can be categorized into real-time or batch processing, depending on operational demands:
- Real-time processing: This method moves data instantaneously as it is produced, making it suitable for applications like monitoring stock prices or tracking user interactions on digital platforms.
- Batch processing: In contrast, this technique accumulates data over a set period and processes it collectively. It is effectively utilized for generating routine reports such as daily sales or for periodic updates to a data warehouse.
Both methods offer distinct benefits: real-time processing provides immediate results, whereas batch processing is more efficient for handling voluminous data sets.
Incorporating Key Technologies
To enhance the functionality of data pipelines, integrating essential technologies like Apache Kafka can enable efficient real-time data streams. Similarly, incorporating message queues facilitates orderly data handling, while data caching techniques can significantly speed up access to frequently requested data, optimizing both processing efficiency and speed.

Data Destinations
The culmination of the data pipeline is the delivery of data to its intended destination, which could be data warehouses, analytics platforms, or other types of storage systems. For example, a business might route its processed data to a business intelligence tool for detailed visualization or further analysis. This stage of the pipeline guarantees that the data not only arrives in an accurate format but also in the right location, primed for its end-use.
Data Pipeline Types and Their Applicability Across Scenarios
Characteristics and Applications of Data Pipelines
Data pipelines adeptly manage a spectrum of data formats, from structured and semi-structured to unstructured, enabling compatibility with various data types such as JSON files, relational databases, and video streams. This adaptability not only simplifies integration but also ensures system-wide compatibility. A significant advantage of data pipelines is their support for real-time and continuous data flow, which allows for decision-making with the most current information available. For example, a logistics company might utilize a data pipeline to monitor shipments in real time, enhancing delivery timeliness and operational efficiency.
Types of Data Pipelines and Industry Applications
Data pipelines are designed to cater to specific data processing needs, with each type offering unique benefits suited to different business scenarios:
- Streaming Pipelines: Ideal for scenarios that demand real-time insights, such as monitoring social media trends or tracking IoT sensor data. These pipelines provide minimal latency, allowing for instantaneous responses to data inputs. Platforms like Striim are instrumental in efficiently designing and managing streaming pipelines.
- Batch Pipelines: Suited for operations that can tolerate a delay in processing, such as the generation of monthly financial reports or nightly updates to a data warehouse. Batch pipelines are capable of managing large data volumes with high accuracy and consistency. Tools like Matillion ETL Pipeline Tools are tailored for batch processing, optimizing data preparation for analysis.
- Hybrid Pipelines: These pipelines merge the advantages of both streaming and batch processing, offering versatility for businesses that require a blend of real-time data and in-depth historical analysis. For instance, a retail company may implement a hybrid pipeline to monitor sales in real time while also performing seasonal trend analyses.
Comparative Analysis with Tabular Presentation
To further elucidate, below is a table comparing the features and benefits of real-time processing, batch processing, and hybrid data pipelines:
| Processing Type | Features | Benefits | Ideal Use Case |
|---|---|---|---|
| Real-time | Immediate data transfer | Enhances decision-making speed | E-commerce order tracking |
| Batch | Scheduled data handling | Efficient for large data volumes | Logistics data analysis |
| Hybrid | Combination of real-time and batch | Flexibility and efficiency | Businesses needing agility and thorough analysis |
This structured overview helps businesses understand the specific advantages of each type of data pipeline and select the most suitable one based on their operational needs and data handling requirements. For example, In the e-commerce sector, real-time data pipelines are crucial for managing order flows efficiently, whereas logistics companies might rely on batch pipelines for daily data analysis to optimize operations.
Data Pipeline Tool Comparison and Selection Recommendations
In the realm of data management, selecting the right tools is crucial for efficient data pipeline architecture. This section provides a detailed comparison of popular data pipeline tools such as Apache Kafka, Airflow, Striim, and Google Cloud Dataflow, highlighting their features, real-time support capabilities, ease of use, and integration abilities.
- Apache Kafka: Renowned for its high throughput and reliability, Kafka is ideally suited for managing large volumes of real-time data streams. It excels in scenarios where speed and scalability are critical, making it a top choice for enterprises that require robust data ingestion capabilities.
- Airflow: Apache Airflow is best recommended for complex workflow orchestration. It provides a programmable environment to design, schedule, and monitor workflows with ease. Airflow's user-friendly interface and extensive plugin support make it adaptable for diverse integration scenarios, particularly where task dependencies are complex.
- Striim: Striim specializes in real-time data integration and streaming analytics. It offers continuous data processing and integration, enabling businesses to make decisions based on the latest data insights. Its low-latency processing is perfect for scenarios that demand immediate data availability.
- Google Cloud Dataflow: A fully managed service for stream and batch data processing, Dataflow is highly efficient in building and managing data pipelines that require minimal maintenance. It integrates seamlessly with other Google Cloud services, providing a robust solution for enterprises deeply integrated into the Google ecosystem.
Tool Comparison Table
| Tool | Real-Time Support | Ease of Use | Integration Capabilities | Overall Functionality Score | Learning Curve |
|---|---|---|---|---|---|
| Apache Kafka | Excellent | Moderate | High | 9/10 | Steep |
| Airflow | Good | High | High | 8/10 | Moderate |
| Striim | Excellent | Moderate | Moderate | 8/10 | Moderate |
| Google Cloud Dataflow | Good | High | Excellent | 9/10 | Easy |
Recommendations
For organizations dealing with complex workflows, Airflow provides unparalleled flexibility and ease of use, making it ideal for managing intricate data processing tasks. On the other hand, for those requiring high-volume, real-time data processing, Apache Kafka offers the necessary robustness and scalability. Each tool has its strengths, and the choice will largely depend on specific business requirements and existing technical infrastructure.
Practical Applications of Data Pipelines: Detailed Case Studies
Data pipelines are instrumental in the architecture of modern data ecosystems, facilitating a broad spectrum of applications from real-time analytics to comprehensive data integration and event-driven responses.
Real-time Analytics
Real-time analytics exemplifies the utility of data pipelines by providing immediate insights into business operations. For instance, a logistics company utilizes data pipelines to monitor shipment movements continuously. This real-time tracking enables the company to ensure timely deliveries and optimize resource allocation. After implementing these data pipelines, the company reported a 30% reduction in package processing times due to more efficient routing and dispatching decisions.
Data Integration Across Systems
In scenarios involving disparate systems, data pipelines streamline the integration process by consolidating data from various sources into a unified format. This capability is vital for companies grappling with data silos. For example, an international retail chain employs a data pipeline to amalgamate sales data from all its geographical locations into a central repository, enhancing the accuracy and timeliness of its stock management system. This integration has led to a 20% improvement in inventory turnover, demonstrating the impact of effective data consolidation.

Event-driven Applications
Event-driven applications significantly benefit from the real-time processing prowess of data pipelines. A notable case involves an e-commerce company that uses a data pipeline to instantly update inventory levels as soon as a customer places an order. This responsiveness not only improves customer satisfaction by providing accurate stock information but also reduces the risk of overselling products. The implementation of this pipeline has accelerated order fulfillment by 25%, showcasing the advantages of integrating real-time data flows into e-commerce platforms.
These examples illustrate the transformative effects that data pipelines can have across various sectors, highlighting their role in enhancing operational efficiencies and driving business intelligence.
How FineDataLink Enhances Data Pipelines
FineDataLink stands out as a powerful solution for building and optimizing data pipelines. Its features address common challenges, enabling you to streamline your data workflows.
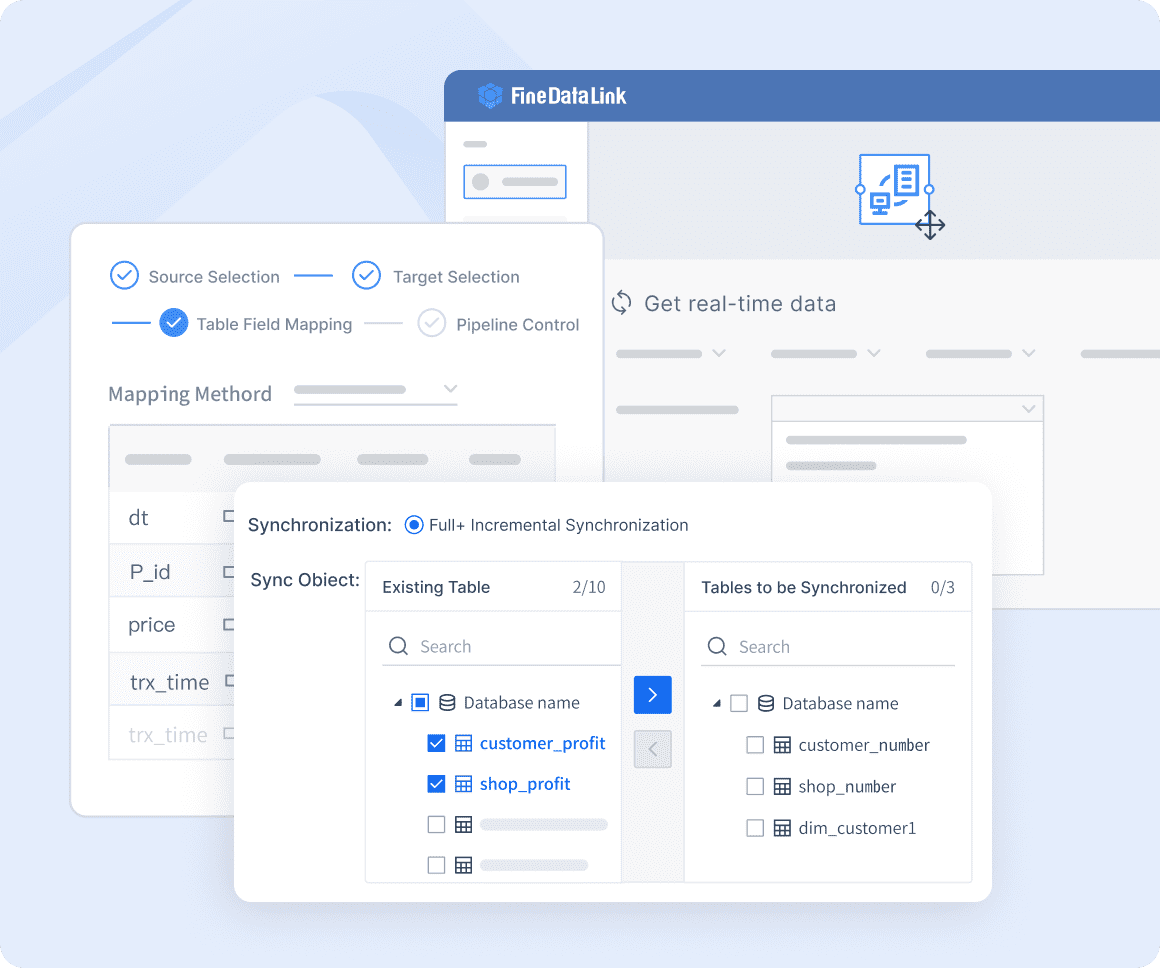
Real-time Data Synchronization
FineDataLink excels in real-time data synchronization, ensuring minimal latency. This feature is invaluable for businesses requiring up-to-date information. Whether you're migrating databases or building a real-time data warehouse, FineDataLink delivers reliable and efficient performance.
Seamless Integration Across 100+ Data Sources
FineDataLink supports integration with over 100 data sources, including SaaS applications and cloud environments. This capability eliminates connectivity limitations, allowing you to consolidate data effortlessly. Its low-code platform simplifies the process, enabling you to focus on strategic initiatives rather than manual tasks.

Data Pipeline vs ETL: What Is an ETL Pipeline?
ETL’s Core Characteristics and Traditional Advantages
The ETL process represents a cornerstone in data management strategies, distinguished by its systematic approach to data preparation and integration. ETL begins with extraction, a phase designed to retrieve raw data from disparate sources such as relational databases, APIs, or flat files. This step ensures comprehensive data collection while preserving the integrity of the original data structure, which is essential for ensuring completeness and accuracy. For example, a retail enterprise might extract sales figures from its point-of-sale systems and customer insights from CRM platforms, consolidating these streams to facilitate analysis.
Following extraction, the transformation phase applies data cleansing, standardization, and enrichment to convert raw datasets into a consistent, analysis-ready format. During this stage, discrepancies are resolved, errors are corrected, and data is formatted to meet specific analytical requirements. Tools like Talend excel in automating such tasks, ensuring data is accurate and actionable for subsequent workflows.
The final phase, loading, transfers the refined data into a target system, such as a data warehouse or business intelligence platform. This step organizes data for efficient querying and reporting, enabling stakeholders to derive insights quickly. For instance, a healthcare organization might employ Informatica to standardize patient records and load them into a centralized repository, facilitating compliance reporting and operational analysis.
ETL pipelines prioritize structured data outputs and are optimized for batch processing, making them indispensable in traditional data warehousing and business intelligence contexts. Their focus on delivering clean, reliable data enhances decision-making capabilities, positioning ETL as a critical enabler of analytical precision and operational efficiency.

Modern ETL Tool Comparison: Talend, Informatica, and Other Key Solutions
In the evolving landscape of data management, selecting the right ETL tool is pivotal for achieving seamless data integration and transformation. This section provides a comparative analysis of prominent ETL tools, focusing on their key features, application scenarios, advantages, and limitations.
Talend: An Open-Source Pioneer for Versatile Applications
Talend is renowned for its open-source architecture and ease of use, making it a preferred choice for small to medium-sized businesses. Its robust capabilities support a wide array of data sources and formats, facilitating diverse use cases such as customer data integration and real-time analytics.
Advantages:
- Cost-effective for smaller organizations due to its open-source model.
- Intuitive interface with a drag-and-drop design for minimal technical expertise.
- Strong community support ensures extensive resources for troubleshooting and enhancement.
Limitations:
- Advanced features require a subscription to Talend’s premium services.
- May not scale efficiently for complex, enterprise-level data workflows.
Informatica: A Comprehensive Solution for Enterprise Needs
Informatica is a market leader in ETL technology, offering a highly scalable and feature-rich platform tailored for large organizations. Its strength lies in handling complex data transformations with precision and reliability, making it ideal for sectors such as finance and healthcare.
Advantages:
- Exceptional performance in managing vast datasets and intricate transformations.
- Robust security protocols to safeguard sensitive data.
- Extensive integration capabilities with cloud platforms and legacy systems.
Limitations:
- High cost of implementation and maintenance.
- Steeper learning curve due to its extensive feature set.
AWS Glue and Google Dataflow: Cloud-Native Innovations
As businesses increasingly migrate to cloud infrastructures, tools like AWS Glue and Google Dataflow have gained traction. These platforms offer serverless architectures and seamless integration with their respective cloud ecosystems, enabling efficient data preparation and transformation.
Advantages:
- Elastic scalability to manage varying workloads.
- Real-time processing capabilities suited for modern analytics requirements.
- Simplified deployment through prebuilt integrations and automated workflows.
Limitations:
- Dependence on specific cloud ecosystems may limit flexibility.
- Licensing and operational costs can escalate with extensive usage.
Comprehensive Comparison Table
To facilitate quick decision-making, the following table highlights the comparative features of Talend, Informatica, AWS Glue, and Google Dataflow:
| Tool | Strengths | Best Use Cases | Challenges |
|---|---|---|---|
| Talend | Open-source, cost-efficient, intuitive design | SMBs, real-time analytics | Limited scalability, premium costs |
| Informatica | Scalable, secure, feature-rich | Enterprise-level data transformations | High cost, steep learning curve |
| AWS Glue | Serverless, cloud-integrated | Cloud data lakes, ETL automation | Ecosystem dependency, usage-based pricing |
| Google Dataflow | Real-time processing, machine learning-ready | IoT analytics, cloud migrations | High operational costs, steep learning curve |
Key Takeaways
- Scalability vs. Cost: While Talend offers affordability and accessibility, Informatica is better suited for large-scale, intricate workflows.
- Cloud Integration: AWS Glue and Google Dataflow stand out for organizations embracing cloud-native approaches.
- Industry Fit: The choice of ETL tool should align with specific industry requirements, such as compliance in healthcare or real-time analytics in retail.
By understanding the strengths and trade-offs of each ETL tool, organizations can tailor their data management strategies to align with business goals and technological infrastructure.
3 Common Use Cases for ETL Pipelines
Data Warehousing
ETL pipelines play a crucial role in building and maintaining data warehouses. They extract raw data from multiple sources, transform it into a consistent format, and load it into a centralized repository. This process ensures that your data warehouse contains clean, structured, and reliable information. For example, a retail company might use an ETL pipeline to consolidate sales, inventory, and customer data into a single warehouse. This enables efficient querying and supports long-term storage for historical analysis. By automating these tasks, ETL pipelines save time and reduce the risk of errors.
Business Intelligence and Reporting
ETL pipelines are indispensable for business intelligence and reporting. They prepare data by cleaning and structuring it, making it ready for visualization and decision-making. For instance, a financial institution might use an ETL pipeline to process transaction data, ensuring accuracy before generating reports. These reports help stakeholders identify trends, monitor performance, and make informed decisions. The structured outputs provided by ETL pipelines simplify the process of creating dashboards and other analytical tools, empowering you to gain actionable insights from your data.
Data Cleaning and Standardization
Data cleaning and standardization are essential for ensuring data quality. ETL pipelines excel in this area by identifying and resolving inconsistencies, removing duplicates, and aligning formats. For example, a healthcare organization might use an ETL pipeline to standardize patient records, ensuring uniformity across different systems. This step is critical for maintaining accurate and reliable data, especially when dealing with large datasets. By automating these processes, ETL pipelines enhance the usability of your data, making it suitable for analysis and other applications.

Emerging Trends in ETL Tools: The Convergence of Cloud Computing and Real-Time Processing
In recent years, the convergence of cloud computing and real-time processing has redefined the capabilities of Extract, Transform, Load (ETL) technologies, enabling more dynamic and scalable data management solutions. Cloud-native ETL tools such as AWS Glue and Google Dataflow have emerged as pivotal components in this transformation, offering extensive scalability, ease of integration, and reduced operational overhead, thereby facilitating more agile and cost-effective data handling strategies.
Furthermore, the integration of real-time stream processing tools like Kafka with ETL processes marks a significant advancement in the field of data architecture. This integration allows organizations to not only handle large streams of data efficiently but also to perform complex transformations in real-time, thereby enhancing decision-making processes and operational efficiency. Such capabilities are critical in environments where timely data insights can lead to competitive advantages and optimized operational workflows.
The synergy between cloud-native ETL tools and real-time processing frameworks thus represents a crucial evolution in data strategy, enabling businesses to harness the full potential of their data assets in a continuously evolving digital landscape. By leveraging these technologies, companies can ensure that their data management processes are not only reactive but also proactive, providing them with the necessary tools to anticipate market changes and adapt swiftly.
How to Choose the Right ETL Tool
In selecting an appropriate ETL tool for enterprise data management, stakeholders must undertake a comprehensive assessment of several pivotal considerations to ensure alignment with organizational needs and capabilities.
Firstly, performance requirements should be meticulously evaluated, encompassing both the volume of data the tool can process and the speed at which it operates. This assessment must consider not only current data processing needs but also anticipate future data growth and the resultant demands on the ETL infrastructure.
Secondly, the diversity of data sources, an increasingly pertinent factor in today's interconnected digital ecosystem, dictates that the chosen ETL tool must seamlessly integrate with a multitude of data inputs ranging from traditional databases to real-time data streams from APIs and IoT devices. This integration capability is crucial for maintaining data integrity and facilitating efficient data flow across disparate systems.
Lastly, budgetary constraints and the level of technical support offered are critical in the decision-making process. The total cost of ownership, including licensing fees, support services, and potential scalability should be aligned with the financial strategies of the organization.
Moreover, robust support from the tool provider guarantees prompt resolution of operational issues, ensuring minimal disruption to data management practices. Thoroughly addressing these key factors will equip decision-makers to select an ETL tool that robustly supports their data transformation and integration needs, enhancing overall business intelligence and operational efficiency.
How FineDataLink Supports ETL Pipelines
Advanced ETL/ELT Capabilities
FineDataLink offers advanced ETL and ELT capabilities that streamline data preparation. Its platform enables you to perform complex transformations with ease, ensuring that your data meets the requirements for storage or analysis. Whether you need to clean, enrich, or reformat data, FineDataLink provides the tools to handle these tasks efficiently. For example, you can use its scheduling features to automate batch processing, reducing manual effort and improving consistency. FineDataLink’s robust functionality ensures that your ETL pipeline operates smoothly, even when managing large volumes of data.
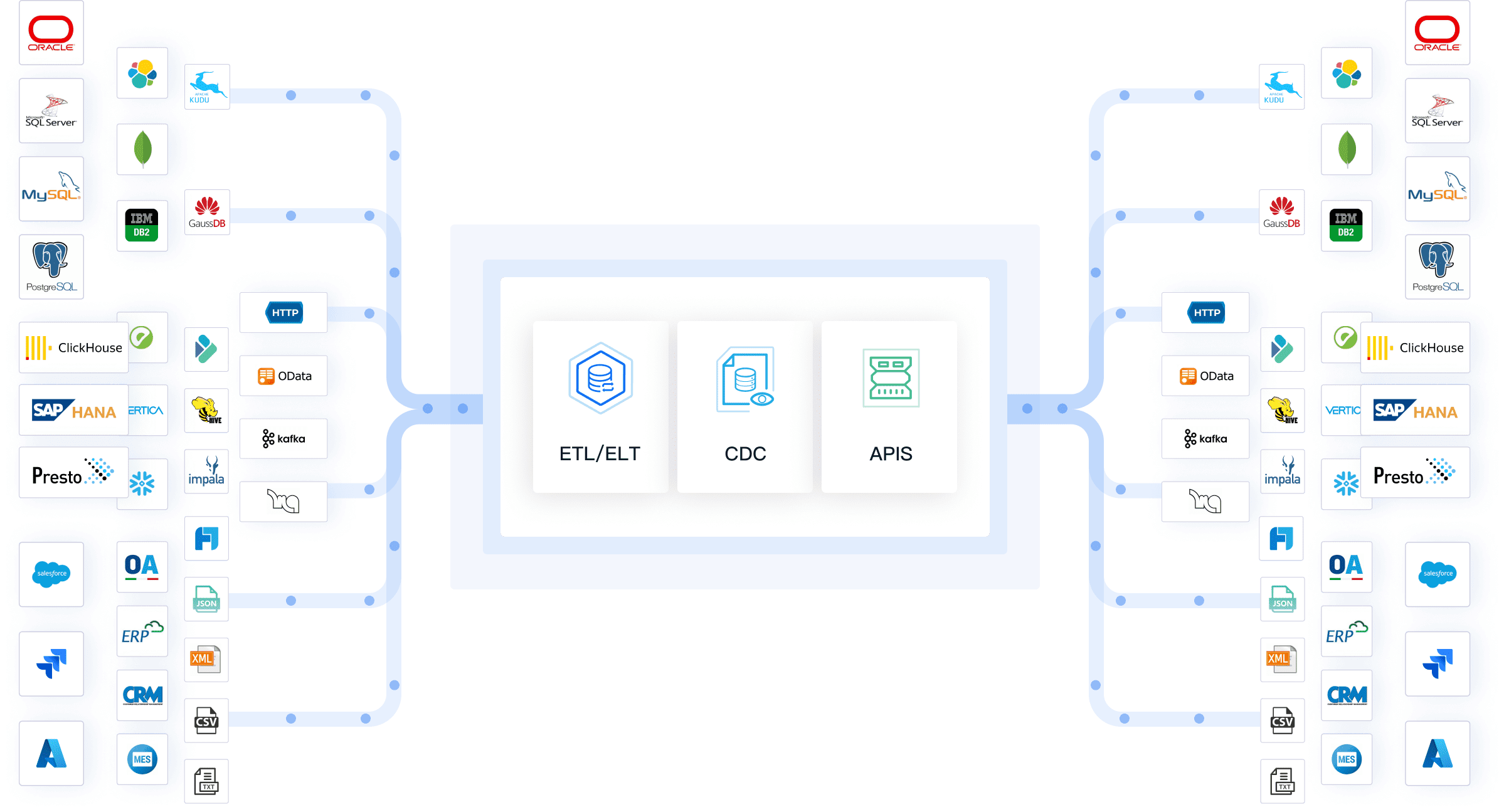
Low-code Platform for Simplified Data Integration
FineDataLink simplifies data integration with its low-code platform. This feature allows you to design and implement ETL pipelines without extensive coding knowledge. Its drag-and-drop interface makes it easy to map data flows, define transformations, and set up workflows. For instance, you can quickly connect to multiple data sources, such as databases and APIs, and configure the extraction process. By reducing complexity, FineDataLink empowers you to focus on strategic tasks rather than technical challenges. This approach enhances productivity and ensures seamless integration across your systems.
Data Pipelines and ETL Pipelines: Key Differences and Practical Applications
Data Transformation
ETL Pipelines: Transformation as a Core Step
In ETL pipelines, transformation is indispensable, playing a central role in preparing data for analytical and storage purposes. The transformation process involves extracting raw data from various sources, which is then cleaned and reformatted to meet specific requirements. This crucial step ensures the data is accurate, consistent, and structured, thus facilitating effective analysis and decision-making. For example, a financial institution might use an ETL pipeline to standardize transaction records by aligning date formats or converting currencies. Tools such as Talend and Informatica are adept at automating these transformations, which not only saves valuable time but also significantly reduces the likelihood of errors. By prioritizing transformation, ETL pipelines are able to deliver data outputs that are not only structured but also highly reliable.
Data Pipelines: Optional Transformation
Contrastingly, data pipelines focus primarily on the efficient movement of data, making transformation an optional component that is tailored to specific needs. For example, a data pipeline might be employed to transfer raw data from IoT devices directly to a cloud storage system without altering its format. This approach provides the flexibility to handle a variety of data types, from structured and semi-structured to unstructured data. Platforms such as Airbyte and FineDataLink facilitate this process by enabling seamless data transfer across multiple sources and destinations. This flexibility allows users to choose whether or not transformation is necessary, depending on the end-use of the data.
Comparative Analysis
To highlight the distinctions further, here's a comparison of how ETL pipelines and data pipelines handle data transformation:
| Feature | ETL Pipelines | Data Pipelines |
|---|---|---|
| Necessity | Mandatory | Optional |
| Function | Clean, reformat, and standardize data | Transfer data with minimal or no modification |
| Benefits | Ensures data accuracy and consistency | Provides flexibility in data usage |
| Use Cases | Financial reporting, compliance audits | Real-time data streaming, machine learning inputs |
| Tools | Talend, Informatica | Airbyte, FineDataLink |
Real-time vs Batch Processing
Data Pipelines: Predominantly Real-time
Data pipelines excel at real-time processing, allowing for the immediate utilization of data as it is generated. This capability is pivotal for applications requiring constant monitoring and quick response, such as tracking stock market fluctuations or analyzing user interactions on websites. For instance, a logistics firm may deploy a data pipeline to monitor shipments continuously, ensuring deliveries are made promptly. Technologies like Striim and FineDataLink enhance this process by specializing in real-time data synchronization, minimizing latency, and providing the latest insights. This enables businesses to make swift, informed decisions based on live data.

ETL Pipelines: Primarily Batch Processing
Conversely, ETL pipelines are designed to handle data in batches, processing information at predefined intervals. This method is ideal for generating regular reports, such as monthly financial summaries, or performing overnight updates to data warehouses. For example, an online retailer might utilize an ETL pipeline to aggregate daily sales data into a structured format suitable for analysis. Platforms like Matillion and Apache NiFi optimize this batch processing, enhancing both efficiency and precision. Although batch processing does not facilitate immediate feedback, it remains an effective strategy for managing extensive data sets with consistency.
Integrating Real-time and Batch Processing
Modern data management increasingly calls for a blend of real-time and batch processing to accommodate diverse business needs. In scenarios demanding rapid response, such as detecting fraud or managing real-time inventory, integrating real-time ETL capabilities can provide a significant advantage. This hybrid approach ensures that businesses are not only well-equipped to handle immediate data challenges but also capable of performing complex, large-scale data analysis with precision.
End Results and Outputs
Data Pipelines: Versatile Outputs
Data pipelines excel in versatility, allowing you to deliver data in its raw state or with minimal transformations tailored to specific needs. This flexibility supports a variety of applications, from real-time data feeds to integration with advanced analytics platforms, providing the adaptability necessary in today's dynamic data environments.

ETL Pipelines: Structured Outputs for Advanced Analysis
ETL pipelines are engineered to produce structured outputs that are indispensable for comprehensive analytical tasks. The meticulous transformation process not only cleanses and standardizes data but also aligns it with the analytical tools' requirements, thereby ensuring integrity and uniformity. For example, healthcare organizations frequently utilize ETL pipelines to process patient records for compliance and reporting purposes. Advanced tools like Talend and Informatica automate the intricate steps of data cleaning and formatting, significantly enhancing efficiency. These structured outputs are crucial as they provide the foundation for generating precise reports and extracting actionable insights, ultimately supporting informed decision-making.
Incorporating Case Studies
A Case Study of a Retail Chain Demonstrates the Impact of Outputs on Business Outcomes. By leveraging a data pipeline, the chain could rapidly integrate sales data across multiple platforms in real-time, enhancing their responsiveness to market trends. Conversely, by using an ETL pipeline, they were able to aggregate and transform sales data into a structured format suitable for detailed trend analysis and inventory management, leading to optimized stock levels and reduced overhead costs.
This nuanced approach to data handling enables organizations to align their data strategy with business objectives, facilitating both immediate operational adjustments and strategic planning based on deep analytical insights.

Complexity and Use Cases
Data Pipelines: Broader Applications
Data pipelines are renowned for their adaptability, making them suitable for a diverse array of applications. They adeptly handle both structured and unstructured data, facilitating fluid data movement across various systems. For example, a retail company may utilize a data pipeline to seamlessly transfer raw sales data from its e-commerce platform to a cloud storage solution. This versatility enables the integration of disparate data sources—ranging from IoT devices and APIs to databases—into a cohesive workflow.
Additionally, data pipelines support both real-time and batch processing, allowing you to tailor the technology to your specific requirements. Real-time pipelines are particularly effective for tasks that require immediate data, such as monitoring social media trends or managing logistics operations. Conversely, batch processing is ideal for generating regular reports or updating data warehouses, with tools like Airbyte enhancing these operations through streamlined data transfer capabilities, ensuring efficient data flow across systems.
ETL Pipelines: Focused on Analytical Needs
ETL pipelines are specifically designed to prepare data for analysis and storage, adhering to a rigorous process that includes extracting raw data, transforming it into a refined format, and loading it into a designated system. This structured approach is crucial for functions that demand high-quality, consistent data, such as business intelligence or compliance reporting.
ETL pipelines are also instrumental in developing and maintaining data warehouses, providing your organization with a dependable historical data repository. For instance, a financial institution might employ an ETL pipeline to amalgamate transaction records from various branches into a single, centralized database. Tools like Talend, Informatica, and Matillion optimize these processes by automating complex transformations and minimizing manual labor.
Moreover, ETL pipelines excel in data cleaning and standardization, adept at identifying and correcting discrepancies, eliminating duplicate entries, and standardizing formats to ensure data accuracy and readiness for analysis. This emphasis on meticulous data transformation establishes ETL pipelines as the preferred choice for organizations that value structured data outputs and analytical accuracy.

How FineDataLink Bridges the Gap
Bridging the Gap with FineDataLink: Real-Time Data and ETL Integration
FineDataLink seamlessly merges the advantages of real-time data pipelines with robust ETL processes. This unique blend allows for instant data synchronization across various systems, alongside necessary complex data transformations. Such dual functionality caters to both immediate operational demands and in-depth analytical needs.
Consider a retail chain utilizing FineDataLink to monitor sales as they occur, while simultaneously analyzing historical sales data to discern emerging trends. This capability is facilitated by a user-friendly, low-code interface that demystifies the creation of complex workflows, making advanced data integration accessible to non-specialists. FineDataLink thus serves as a pivotal tool in overcoming traditional challenges associated with integrating data pipelines and ETL processes, offering a holistic solution for contemporary data management needs.
Scalable Solutions for Varied Data Demands
FineDataLink distinguishes itself with its remarkable scalability, accommodating enterprises of all scopes. From modest data sets to expansive data ecosystems, FineDataLink is designed to adjust to varying scales effortlessly. Its compatibility with over 100 data sources ensures a seamless integration experience, circumventing the common constraints found in conventional systems.
An illustrative case is a manufacturing firm that employs FineDataLink to track key production metrics in real-time and aggregates comprehensive monthly data for detailed performance reviews. Such versatility is bolstered by FineDataLink’s sophisticated ETL/ELT functionalities, which simplify complex data transformations. This adaptability makes FineDataLink an exemplary choice for entities aiming to refine their data handling processes and boost operational efficiency.
Through these applications, FineDataLink not only provides the tools necessary for effective data management but also exemplifies its capacity to enhance business intelligence and operational responsiveness across industries.

Pros and Cons of Data Pipelines and ETL Pipelines
Data Pipelines
Pros:
- Real-time Data Processing: Data pipelines excel in handling real-time data.
- Flexibility with Data Formats: Data pipelines support structured, semi-structured, and unstructured data. This flexibility enables you to work with diverse data types, such as JSON files, relational databases, or even video streams. You can integrate data from multiple sources without worrying about format compatibility.
- Broad Use Cases: Data pipelines adapt to a wide range of applications. Whether you need to transfer raw data to a cloud storage system or enable real-time analytics, they provide the versatility to meet your needs. For example, a retail company might use a data pipeline to monitor sales trends in real time.
- Scalability: Data pipelines handle both small and large-scale data operations. They grow with your business, ensuring that your data workflows remain efficient as your needs evolve.
Cons:
- Complexity in Setup: Setting up a data pipeline can be challenging, especially if you lack technical expertise. You need to configure data sources, define workflows, and ensure seamless integration across systems.
- Limited Focus on Transformation: Data pipelines prioritize data movement over transformation. If your use case requires extensive data cleaning or formatting, you may need additional tools or processes to handle these tasks.
- Resource Intensive: Real-time data pipelines often require significant computational resources. This can increase costs, especially for businesses managing large volumes of data.

ETL Pipelines
Pros:
- Structured Data Outputs: ETL pipelines deliver clean and consistent data.
- Focus on Data Transformation: ETL pipelines excel in transforming raw data into a usable format. They clean, enrich, and standardize data, ensuring accuracy and reliability. This capability is crucial for applications like compliance reporting or business intelligence.
- Batch Processing Efficiency: ETL pipelines handle large datasets efficiently through batch processing. This approach works well for tasks like updating data warehouses or generating monthly financial reports. By automating these processes, ETL pipelines save time and reduce errors.
- Support for Business Intelligence: ETL pipelines enable you to extract insights from various data types and sources. They help you identify new business opportunities by preparing data for analysis. For example, a financial institution might use an ETL pipeline to consolidate transaction records for trend analysis.
Cons:
- Time Lag in Processing: ETL pipelines often rely on batch processing, which introduces delays. If you need real-time insights, this approach may not meet your requirements.
- Rigid Workflow: ETL pipelines follow a structured process. While this ensures consistency, it limits flexibility. You may find it challenging to adapt the pipeline to new data sources or formats without significant reconfiguration.
- Higher Initial Investment: Building and maintaining an ETL pipeline requires specialized tools and expertise. This can increase upfront costs, especially for small businesses or startups.
By understanding the strengths and limitations of both pipeline types, you can choose the one that aligns with your specific data needs. Whether you prioritize real-time processing or structured outputs, selecting the right pipeline ensures efficient and effective data management.
Data pipelines and ETL pipelines address distinct needs in data management. Data pipelines excel in real-time data movement, offering flexibility for diverse applications. ETL pipelines specialize in preparing data for analysis, ensuring structured outputs for tasks like business intelligence. FineDataLink by FanRuan bridges these capabilities, combining real-time synchronization with advanced ETL/ELT processes. Your choice between a data pipeline vs ETL depends on your goals—whether you need immediate insights, data transformation, or analytical precision. Understanding these tools empowers you to design an effective data strategy tailored to your requirements.
Key Takeaways
- Data pipelines focus on moving data between systems in real-time, making them ideal for applications that require immediate insights.
- ETL pipelines specialize in extracting, transforming, and loading data, ensuring it is clean and structured for analysis and reporting.
- Choosing between a data pipeline and an ETL pipeline depends on your specific needs: real-time processing versus structured data preparation.
- Data pipelines offer flexibility in handling various data formats, while ETL pipelines emphasize data transformation for consistency and accuracy.
- FineDataLink provides a solution that combines the strengths of both data pipelines and ETL processes, allowing for seamless integration and real-time synchronization.
- Understanding the key components and characteristics of each pipeline type helps you design an effective data strategy tailored to your organization's requirements.
Click the banner below to experience FineDataLink for free and empower your enterprise to convert data into productivity!

Continue Reading about Data Pipeline
Mastering Data Pipeline: Your Comprehensive Guide
How to Build a Python Data Pipeline: Steps and Key Points




FAQ

The Author
Howard
Data Management Engineer & Data Research Expert at FanRuan
Related Articles

Best Software for Creating ETL Pipelines This Year
Discover the top ETL pipelines tools for 2026, offering scalability, user-friendly interfaces, and seamless integration to streamline your data pipelines.
Howard
Apr 29, 2025

What is Data Pipeline Management and Why It Matters
Data pipeline management ensures efficient, reliable data flow from sources to destinations, enabling businesses to make timely, data-driven decisions.
Howard
Mar 07, 2025

What is a Data Pipeline and Why Does It Matter
A data pipeline automates collecting, cleaning, and delivering data, ensuring accurate, timely insights for analysis and business decisions.
Howard
Mar 07, 2025