

카이제곱검정은 관찰된 데이터와 기대되는 데이터의 차이를 분석하는 통계 검정입니다. 이 방법을 사용하면 주사위가 공정한지, 약물 효과와 성별이 관련이 있는지, 또는 지역별로 상품 선호도가 같은지 직접 확인할 수 있습니다. 예를 들어, 집안일 수행 빈도를 조사하여 남편과 아내가 주로 하는 일이 다른지 알아볼 수 있습니다. 이러한 분석을 FineBI와 같은 도구로 시각화하면 결과를 쉽게 이해할 수 있습니다.
카이제곱검정은 범주형 데이터의 관측 빈도와 기대 빈도 사이의 차이가 통계적으로 의미가 있는지 판단하는 방법입니다. 이 검정은 교차표를 활용해 실제 데이터가 특정 확률 모형을 얼마나 잘 따르는지 평가합니다.
예를 들어, 요일별로 방문하는 고객 수가 기존의 기대 비율과 같은지 확인하고 싶을 때 카이제곱검정을 사용할 수 있습니다.
이 검정의 공식은 다음과 같습니다.
χ² = Σ (관측값 - 기대값)² / 기대값
이 공식을 사용하면 각 범주별로 관측값과 기대값의 차이를 계산하고, 그 합을 통해 전체 데이터의 차이를 한눈에 볼 수 있습니다.
카이제곱검정은 적합도 검정, 독립성 검정, 동질성 검정으로 나뉩니다.
아래 표에서 각 검정의 특징과 실제 예시를 확인할 수 있습니다.
카이제곱검정은 t-test와 달리 명목형 변수 간의 분포 차이나 독립성을 검정하는 데 적합합니다. 복잡한 평균 비교 없이 다양한 범주형 데이터 분석에 활용할 수 있습니다.
이 방법은 정규성 등 까다로운 조건이 필요하지 않아 실무에서 자주 사용됩니다.
카이제곱검정은 상자의 내용 구성이 알려져 있을 때, 관측된 자료를 이 상자로부터 무작위 추출한 결과로 볼 수 있는지 그 판단 근거를 제공합니다. 여러 범주에 걸쳐 관측된 도수와 기대도수의 차이는 카이제곱통계량으로 측정합니다.
카이제곱검정의 절차는 다음과 같습니다.
카이제곱검정에서 사용되는 검정통계량은 카이제곱분포를 따릅니다.
카이제곱분포는 여러 개의 독립적인 표준정규분포 확률변수를 각각 제곱한 후 합산하여 정의됩니다. 이때 자유도는 표본 내 독립적인 정보의 수를 의미합니다.
예를 들어, 표본 크기가 n일 때 자유도는 n-1로 계산됩니다.
카이제곱검정은 분할표에서 관측 빈도와 기대 빈도를 비교하여 가설을 검정합니다.
검정통계량이 카이제곱분포에서 발생하기 어려운 값이면, 즉 p-value가 작으면 영가설을 기각합니다.
이렇게 카이제곱분포와 카이제곱검정은 수학적으로 연결되어 있습니다.
귀무가설(H0): 범주형 데이터가 나타날 확률이 다 같습니다(차이가 없습니다).
대립가설(H1): 범주형 데이터가 나타날 확률이 같지 않습니다(차이가 있습니다).
카이제곱분포는 항상 0 이상의 값을 가지며, 자유도에 따라 분포의 모양이 달라집니다.
이 분포는 카이제곱검정에서 검정통계량의 분포로 활용됩니다.
따라서, 카이제곱검정의 결과를 해석할 때 자유도와 유의수준을 함께 고려해야 합니다.
적합도 검정은 실제 데이터가 특정 이론적 분포나 모델을 얼마나 잘 따르는지 평가하는 방법입니다.
예를 들어, 주사위가 공정한지 확인하거나, 설계한 프로세스 모델이 현실의 이벤트 로그와 얼마나 일치하는지 검증할 때 이 검정을 사용할 수 있습니다.
프로세스 마이닝 분야에서는 적합도 검정을 통해 모델의 타당성을 수량화하고, 실제 데이터와 모델 간의 적합도를 네 가지 기준(적합성, 정확성, 일반화, 단순성)으로 평가합니다.
이 검정을 활용하면, 설계한 프로세스가 실제 업무 흐름을 잘 반영하는지 확인할 수 있습니다.
FineBI와 같은 BI 도구를 사용하면, 적합도 검정 결과를 시각적으로 표현하여 데이터와 모델의 차이를 한눈에 파악할 수 있습니다.
적합도 검정은 현실 데이터와 이론 모델의 차이를 수치로 보여주기 때문에, 데이터 기반 의사결정에 매우 유용합니다.
적합도 검정이 자주 사용되는 사례는 다음과 같습니다.
독립성 검정은 한 모집단 내 두 범주형 변수 사이에 연관성이 있는지 확인하는 방법입니다.
예를 들어, 성별과 흡연 여부가 서로 관련이 있는지, 연령대와 SNS 선호도가 독립적인지 분석할 수 있습니다.
이 검정에서는 하나의 모집단에서 무작위로 표본을 추출하고, 두 변수로 분류하여 관계를 평가합니다.
FineBI를 활용하면, 교차표와 시각화 차트를 통해 변수 간의 연관성을 쉽게 파악할 수 있습니다.
동질성 검정은 여러 모집단에서 특정 범주형 변수의 분포가 동일한지 비교하는 방법입니다.
예를 들어, 지역별로 상품 선호도가 같은지, 소득 수준별로 지지 정당 분포가 동일한지 확인할 때 사용합니다.
여러 집단에서 각각 표본을 추출한 후, 각 집단의 분포가 같은지 검정합니다.
FineBI에서는 다양한 집단의 데이터를 통합하여, 집단 간 분포 차이를 시각적으로 비교할 수 있습니다.
아래 표는 독립성 검정과 동질성 검정의 주요 차이점을 정리한 것입니다.
독립성 검정과 동질성 검정 모두 카이제곱검정을 사용하며, 각 셀의 기대 빈도가 5 이상이어야 신뢰할 수 있습니다.
FineBI와 같은 BI 도구에서는 카이제곱검정 결과를 다양한 차트와 대시보드로 시각화할 수 있습니다.
이렇게 하면, 변수 간 관계나 집단 간 분포 차이를 빠르게 파악하고, 실무 의사결정에 바로 활용할 수 있습니다.
여러분이 실제 업무에서 데이터를 분석할 때, 카이제곱검정은 다양한 상황에서 유용하게 쓰입니다. 예를 들어, 마케팅 부서에서는 지역별로 상품 선호도가 차이가 있는지 알고 싶을 때 이 검정을 사용합니다. 인사팀에서는 부서별로 직원 만족도 설문 결과가 다르게 나타나는지 확인할 수 있습니다.
병원에서는 연령대와 질병 발생률 사이에 관계가 있는지 분석할 때도 카이제곱검정이 필요합니다.
이처럼 여러분은 범주형 데이터가 두 집단이나 변수 간에 차이가 있는지, 또는 서로 연관이 있는지 빠르게 파악할 수 있습니다.
실무에서 카이제곱검정을 적용하는 절차는 다음과 같습니다.
팁: 카이제곱검정은 표본이 충분히 크고, 각 셀의 기대 빈도가 5 이상일 때 신뢰도가 높아집니다.
FineBI를 사용하면 카이제곱검정 과정을 더욱 쉽고 빠르게 진행할 수 있습니다.
여러분은 다양한 데이터 소스를 FineBI에 연결하여 데이터를 한 곳에서 관리할 수 있습니다.
FineBI는 드래그 앤 드롭 방식으로 데이터를 준비하고, 범주형 변수로 손쉽게 분류할 수 있습니다.
실시간으로 데이터를 분석하고, 결과를 시각화 차트나 대시보드로 바로 확인할 수 있습니다.
FineBI에서 카이제곱검정 데이터 분석 절차는 아래 표와 같습니다.
FineBI의 시각화 기능을 활용하면, 분석 결과를 다양한 차트로 표현할 수 있습니다.
여러분은 대시보드를 통해 팀원과 결과를 공유하고, 실시간으로 피드백을 받을 수 있습니다.
또한, FineBI의 협업 기능을 이용하면 여러 부서가 동시에 데이터를 분석하고, 중복 작업을 줄일 수 있습니다.
Note: FineBI는 모바일 앱을 지원하므로, 언제 어디서나 분석 결과를 확인할 수 있습니다.
실시간 알림 기능을 통해 중요한 변화도 즉시 파악할 수 있습니다.
카이제곱검정에서 가장 먼저 해야 할 일은 관측값과 기대값을 정확히 이해하는 것입니다.
관측값은 실제로 조사나 실험을 통해 얻은 각 범주별 빈도수를 의미합니다. 예를 들어, 설문조사에서 남성과 여성의 응답 수가 각각 60명, 40명이라면 이 값들이 관측값입니다.
기대값은 두 변수가 서로 독립적이라고 가정할 때, 각 범주에서 기대되는 빈도수입니다. 기대값은 다음과 같이 계산할 수 있습니다.
기대값 = (해당 행의 총합 × 해당 열의 총합) ÷ 전체 총합
예를 들어, 전체 응답자가 100명이고, 남성이 60명, 특정 답변을 선택한 사람이 30명이라면, 남성이 그 답변을 선택할 것으로 기대되는 값은 (60 × 30) ÷ 100 = 18명입니다.
기대값은 일반적으로 5 이상이어야 검정 결과가 신뢰할 수 있습니다. 기대값이 너무 작으면 결과 해석에 주의가 필요합니다.
카이제곱검정의 공식은 다음과 같습니다.
χ² = Σ (관측값 - 기대값)² / 기대값
이 공식은 각 범주별로 관측값과 기대값의 차이를 제곱한 뒤, 기대값으로 나누어 모두 더하는 방식입니다.
이 과정을 통해 실제 데이터와 기대되는 데이터 간의 차이를 수치로 나타낼 수 있습니다.
계산 단계는 다음과 같습니다.
예시로, 두 집단의 데이터가 아래와 같다고 가정해봅시다.
각 셀의 계산은 다음과 같습니다.
따라서, 카이제곱 통계량은 1.25 + 1.25 = 2.5가 됩니다.
피어슨 잔차(Pearson residual)는 (관측값 - 기대값) ÷ √기대값으로 계산합니다. 이 값이 크면 해당 셀에서 관측값과 기대값의 차이가 크다는 의미입니다.
카이제곱 통계량이 클수록 관측값과 기대값의 차이가 크다는 뜻이며, 이는 두 변수 간에 독립성이 없을 가능성을 시사합니다.
카이제곱검정에서 자유도는 결과 해석에 매우 중요한 역할을 합니다.
자유도는 다음과 같이 계산합니다.
예를 들어, 2행 3열 표라면 자유도는 (2-1) × (3-1) = 2입니다.
자유도는 카이제곱 분포의 모양을 결정합니다.
카이제곱 통계량과 자유도를 알면, p-value를 구할 수 있습니다.
p-value는 귀무가설이 참일 때, 관측된 결과가 우연히 나올 확률을 의미합니다.
주의: p-value는 귀무가설이 참이라는 전제하에 계산됩니다. 표본 크기가 너무 작거나 너무 크면 결과 해석에 신중해야 합니다. 여러 번 검정을 수행할 때는 보정 방법(Bonferroni 등)을 적용해야 신뢰성을 높일 수 있습니다.
카이제곱검정은 범주형 데이터의 분포 차이나 변수 간 독립성을 평가할 때 매우 유용합니다.
계산 과정에서 관측값, 기대값, 자유도, p-value를 정확히 이해하면 신뢰성 있는 결론을 얻을 수 있습니다.
통계 분석에서 가장 먼저 해야 할 일은 가설을 세우는 것입니다.
여러분은 항상 두 가지 가설을 생각해야 합니다.
첫 번째는 귀무가설(H0)입니다. 귀무가설은 "차이가 없다" 또는 "변수 간에 관계가 없다"는 주장입니다.
두 번째는 대립가설(H1)입니다. 대립가설은 "차이가 있다" 또는 "변수 간에 관계가 있다"는 주장입니다.
분석 결과에서 p-value가 0.05보다 크면 귀무가설을 채택합니다. 예를 들어, p-value가 0.586이라면 "교육방법에 따른 만족도 차이가 없다"는 귀무가설을 받아들입니다. 반대로 p-value가 0.00017처럼 0.05보다 작으면 귀무가설을 기각하고 대립가설을 지지합니다. 이때는 "관찰빈도와 기대빈도가 다르다"고 판단합니다.
p-value는 귀무가설이 맞다고 가정할 때, 지금과 같은 데이터가 나올 확률입니다. p-value가 0.05보다 작으면 통계적으로 유의미하다고 해석합니다.
이 기준은 자유도와 카이제곱값에 따라 달라질 수 있습니다. 보통 0.05라는 유의수준을 사용하며, 이는 95% 신뢰수준에서 가설을 평가한다는 의미입니다.
분석 결과를 해석할 때는 몇 가지 주의해야 할 점이 있습니다.
분석 방법이 잘못되면 연구 결과의 신뢰도가 떨어지고, 논문이나 보고서의 타당성도 흔들릴 수 있습니다.
카이제곱값이 크다고 해서 항상 변수 간에 강한 관련성이 있다고 볼 수 없습니다.
분석을 할 때 다음과 같은 한계와 오해에 주의해야 합니다.
결과를 해석할 때는 단순히 p-value나 카이제곱값만 보지 말고, 표본 크기, 변수 특성, 비교 대상 등을 꼼꼼히 확인해야 합니다.
아래 표는 자주 발생하는 오해와 한계를 정리한 것입니다.
여러분은 항상 분석 목적과 데이터 특성을 고려해 올바른 해석을 해야 합니다.
FineBI를 사용하면 복잡한 범주형 데이터를 한눈에 파악할 수 있습니다.
여러분은 다양한 데이터 소스를 FineBI에 연결하여, 교차표나 분할표를 쉽게 생성할 수 있습니다.
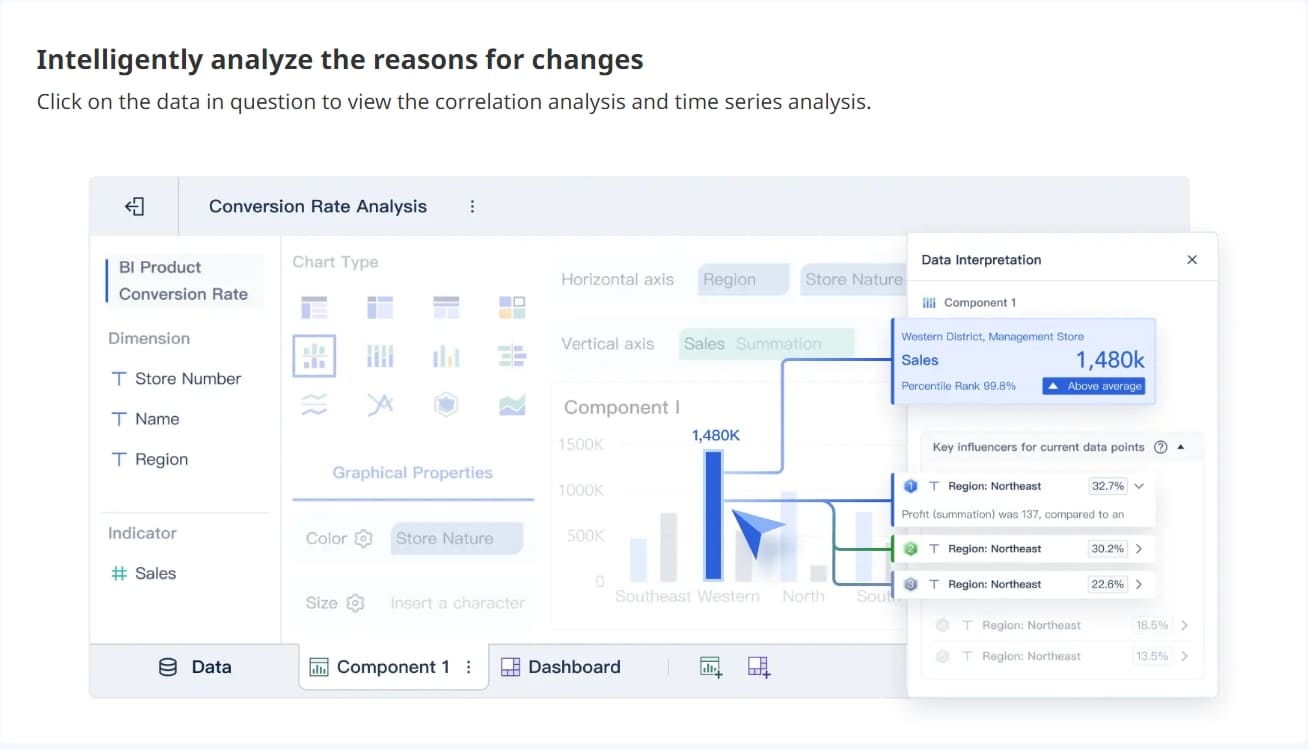
분석 결과를 막대그래프, 원형차트, 히트맵 등 다양한 시각화 도구로 표현하면, 변수 간의 관계나 분포 차이를 직관적으로 확인할 수 있습니다.
예를 들어, 고객의 연령대별 상품 선호도를 시각화하면, 어떤 연령층이 특정 상품을 더 선호하는지 빠르게 파악할 수 있습니다.
FineBI의 드래그 앤 드롭 기능을 활용하면, 복잡한 수식 없이도 원하는 차트를 만들 수 있습니다.
시각화된 결과는 팀원과 공유하거나 대시보드에 추가하여, 누구나 쉽게 데이터를 해석할 수 있습니다.
비즈니스 환경에서는 빠른 의사결정이 중요합니다.
FineBI는 실시간 데이터 분석 기능을 제공하여, 데이터가 업데이트될 때마다 즉시 결과를 확인할 수 있습니다.
여러분은 실시간으로 데이터가 변할 때마다 분석 결과와 시각화 차트가 자동으로 갱신되는 것을 볼 수 있습니다.
예를 들어, 마케팅 캠페인 중에 지역별 판매 데이터가 실시간으로 들어오면, FineBI에서 즉시 분포 변화를 분석할 수 있습니다.
이렇게 하면, 시장 변화에 빠르게 대응하고, 신속하게 전략을 조정할 수 있습니다.
실시간 알림 기능을 활용하면, 중요한 변화가 발생할 때 즉시 통보를 받을 수 있습니다.
FineBI는 팀 단위 협업을 지원합니다.
여러분은 분석한 데이터셋이나 대시보드를 동료와 쉽게 공유할 수 있습니다.
동료가 만든 분석 결과를 참고하거나, 기존 대시보드를 복제해 추가 분석을 진행할 수도 있습니다.
이 기능을 활용하면, 여러 부서가 동시에 데이터를 검토하고, 중복 작업을 줄일 수 있습니다.
또한, 모바일 앱을 통해 언제 어디서나 분석 결과를 확인하고 의견을 나눌 수 있습니다.
협업 기능을 통해 데이터 기반 의사결정의 속도와 정확도를 높일 수 있습니다.
FineBI는 데이터 통합, 시각화, 실시간 분석, 협업 기능을 통해 여러분이 신뢰성 있는 인사이트를 빠르게 도출할 수 있도록 돕습니다.
이러한 환경에서 여러분은 데이터 기반의 의사결정을 더욱 효과적으로 내릴 수 있습니다.
여러분은 데이터를 분석할 때 빠르고 쉽게 차이를 확인할 수 있습니다. 카이제곱검정은 범주형 변수의 관계를 신속하게 파악하는 데 매우 실용적입니다. 설문 결과나 집단별 분포를 비교할 때, 이 방법을 활용하면 통계적으로 의미 있는 차이가 있는지 바로 알 수 있습니다. 여러분은 실무에서 다양한 상황에 적용하여 데이터 기반 결정을 내릴 수 있습니다.
FanRuan
https://www.fanruan.com/ko-kr/blogFanRuan은 FineReport의 유연한 리포팅, FineBI의 셀프서비스 분석, FineDataLink의 데이터 통합 기능을 바탕으로 전 산업 분야에 걸쳐 강력한 BI 솔루션을 제공합니다. FanRuan의 올인원 플랫폼은 조직이 원시 데이터를 실행 가능한 인사이트로 전환하여 비즈니스 성장을 실현할 수 있도록 강력하게 지원합니다.
카이제곱검정은 범주형 데이터에 적합합니다. 예를 들어, 성별, 지역, 선호도처럼 구분이 명확한 데이터를 분석할 때 사용할 수 있습니다.
기대값이 5 미만인 셀이 많으면 결과 신뢰도가 낮아집니다. 이럴 때는 데이터를 합치거나, 피셔의 정확 검정 같은 다른 방법을 고려하세요.
FineBI에서 데이터를 불러온 후, 교차표를 만들고 카이제곱검정 기능을 사용하세요. 결과를 다양한 차트로 시각화할 수 있습니다.
카이제곱검정은 범주형 데이터의 분포 차이나 독립성을 분석합니다. t-검정은 평균의 차이를 비교할 때 사용합니다. 데이터 유형에 따라 적합한 검정을 선택하세요.
p-value가 0.05보다 크면 귀무가설을 기각하지 않습니다. 즉, 변수 간에 통계적으로 유의미한 차이가 없다고 해석할 수 있습니다.
네, FineBI는 실시간 데이터 분석을 지원합니다. 데이터가 업데이트되면 분석 결과와 시각화 차트도 자동으로 갱신됩니다.
FineBI의 협업 기능을 사용하세요. 대시보드나 분석 결과를 팀원과 쉽게 공유할 수 있습니다. 모바일 앱으로도 언제든 확인할 수 있습니다.
자유도 = (행의 수 - 1) × (열의 수 - 1)
예를 들어, 3행 2열 표라면 자유도는 (3-1)×(2-1)=2입니다.






