在資訊爆炸的時代,「大數據平台」已成為支撐政府治理與企業轉型的關鍵基礎設施。它不僅是技術術語,更是驅動決策、釋放資料價值的關鍵。本文將深入解析大數據平台的雙重定義,盤點台灣豐富的公開資源,並提供從概念到實踐的企業級建置指南,協助您的數位轉型。
一、 什麼是大數據平台?
大數據平台並非單一概念,它依據建置目的與服務對象,主要可分為兩大型態:對外開放的公共資料集散地與對內整合的企業軟體生態系。理解這兩者的差異,是有效運用數據資源的第一步。
1. 資源共享型大數據平台:政府與公共開放資料的集散入口
這類平台的核心目標是推動資料透明化與公共服務效率提升。由政府或公部門建置,旨在免費提供海量、高品質的民生、經濟、氣象、交通等原始資料集。例如,台灣各級政府會將人口統計、公司登記、空氣品質監測等資料,經過去識別化處理後,開放於特定入口網站。這類平台提供了低門檻、高價值的外部數據來源,非常適合企業進行市場趨勢分析、學術研究,或作為系統開發測試的資料基礎。它解決了過去資料分散、格式不一、不易取得的痛點,成為公眾與企業挖掘社會與商業洞察的重要起點。
2. 系統架構型大數據平台:驅動企業數位轉型的核心軟體生態系
從企業內部IT視角來看,大數據平台是一套處理海量、多樣、高速數據的綜合軟體框架。它絕非單一軟體,而是一個涵蓋資料從產生到產生價值的端到端(End-to-End)解決方案。這個生態系整合了數據採集、分散式儲存、高效能運算、機器學習模型訓練,以及最終的視覺化分析等模組。企業導入此類平台的目的,是為了打破各業務系統(如ERP、CRM、物聯網裝置)形成的「資料孤島」,將碎片化的資訊整合成可供深度分析、支援即時決策的單一資料來源。它是企業實現數據驅動(Data-Driven)文化的技術基石。
3. 數據平台與大數據平台的核心差異:4 大維度全面解析
在評估企業的資料架構時,我們常會區分傳統的數據平台與現代的大數據平台。兩者最根本的技術分野,在於大數據平台必須具備處理 大數據 5V 特性(即資料量 Volume、速度 Velocity、多樣性 Variety、真實性 Veracity 與價值 Value)的能力。以下我們從 4 大維度,全面解析兩者的核心差異。
延伸閱讀:數據平台入門知識,功能與應用一次掌握
二、 全台指標性大數據平台資源盤點
台灣在政府資料開放與特定領域數據應用上已有顯著成果。以下盤點六個指標性平台,提供企業與研究者寶貴的數據資源:
- 政府資料開放平臺:這是掌握全台宏觀趨勢的核心入口。平台彙整來自各部會、縣市政府的數萬筆開放資料集,涵蓋經濟統計、財政、氣象、交通等領域。資料提供API介接與多種檔案格式下載,是進行總體經濟分析或外部環境研究的首選起點。
- 內政大數據平台:此平台深入整合人口、戶政、地政等核心民生數據。對於需要洞察人口結構遷移、不動產市場趨勢、社會福利分布的研究機構、金融業者或地產開發商而言,是極具價值的深度資料來源,可支援精準的趨勢預測與政策分析。
- 臺北市資料大平臺:此平台不僅提供靜態資料集,更與「臺北市城市儀表板」深度結合。平台提供即時的捷運運量、YouBike使用、施工資訊、社會住宅進度等動態數據,並以視覺化圖表與地理圖資呈現,是城市治理與民生服務創新的典範。

- 新北市教育大數據平台:隸屬於教育部的AI人才方舟計畫,此平台整合了學生數位學習軌跡、載具使用、成效評估等數據。目標是透過學習分析技術,邁向適性化教學與公平優質教育,同時提供去識別化資料供學界與產業進行教育科技加值應用與創新研發。
- 中山大學智慧商業大數據平台:此平台結合學術能量與產業需求,專注於驅動高階AI應用與商業創新。它提供經處理、標註的商業情境資料集,並結合機器學習工具,常作為企業進階分析、學術研究,以及培育資料科學與AI人才的實戰環境。
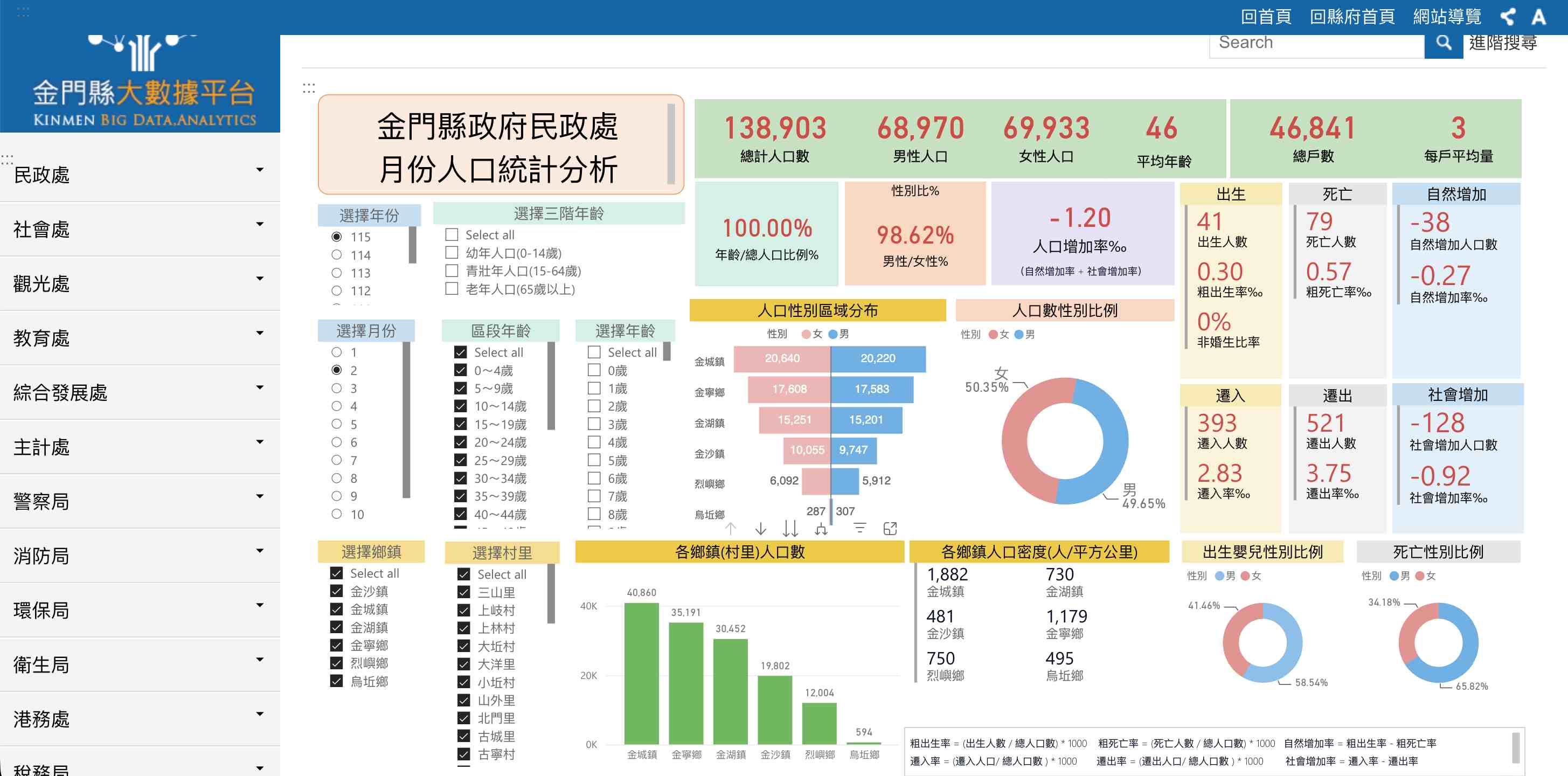
- 金門縣大數據平台:展現了縣市層級在地化數據應用的深度。平台聚焦於縣政管理、觀光發展、交通動態等在地指標,透過整合觀光人次、特產銷售、交通流量等數據,協助地方政府進行精準施政與觀光行銷規劃,是發展區域經濟的重要參考。
三、 企業級私有大數據平台架構解析:從端到端資料管線 (Data Pipeline) 視角出發
建構一個企業級大數據平台,本質上是打造一條高效、穩定、可擴充的資料管線。這條管線將原始資料轉化為商業洞察,可分為三個關鍵階層:
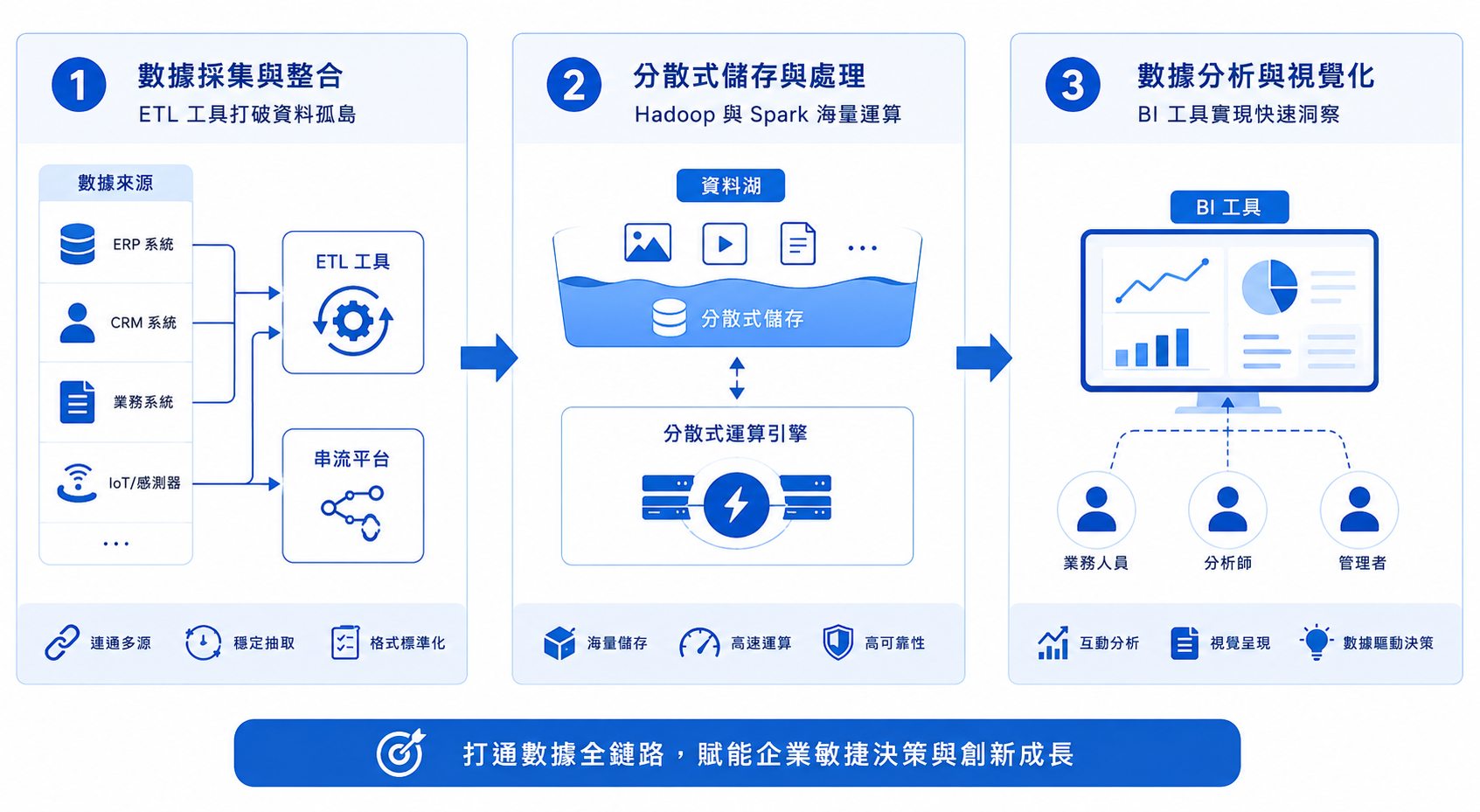
1. 數據採集與整合層 (Data Ingestion):利用 ETL 工具打破跨系統資料孤島
這是資料管線的起點,目標是將分散在各處的異質數據穩定匯入平台。企業通常會使用自動化ETL/ELT工具(如 FineDataLink、Apache NiFi)來定期批次抽取來自ERP、CRM等傳統資料庫的結構化數據。同時,為了處理網站點擊流、物聯網感測器訊號等即時資料,則需引入如 Apache Kafka 這類的分散式串流平台作為資料匯流排。此層的關鍵在於確保資料來源的連通性、抽取的穩定性,以及初步的資料格式標準化,為後續處理奠定基礎。
2. 分散式儲存與處理層 (Storage & Processing):Apache Hadoop 與 Spark 的海量運算
此層是平台的心臟,負責海量資料的儲存與複雜計算。Apache Hadoop HDFS 分散式檔案系統,能以低成本、高可靠的方式儲存PB級的非結構化原始數據,形成「資料湖」的基礎。而 Apache Spark 則憑藉其記憶體內運算特性,成為執行資料清洗、轉換、聚合以及機器學習模型訓練的首選引擎,其速度可比傳統MapReduce快上數十倍。此層技術選型決定了平台處理數據的規模、速度與成本效益。
3. 數據分析與視覺化層 (BI & Analytics):串接前端商業智慧工具實現快速洞察
處理後的數據必須能被終端使用者理解與應用。此層強調大數據平台需具備對接前端商業智慧工具的能力。透過標準介面(如JDBC/ODBC),分析師或事業部人員可以使用如 FineBI 等工具,直接查詢位於Hadoop或Spark上的巨量資料,並將結果以互動式儀表板、圖表或報告形式呈現。這一步真正將技術層的數據處理,轉化為業務層的決策支援,賦能各單位進行數據驅動的敏捷營運。
四、 國際主流企業級大數據平台服務(SaaS/PaaS)比較與選型
對於許多企業而言,自建與維運開源大數據集群門檻過高。採用國際主流的雲端或託管服務(SaaS/PaaS)成為更高效、可靠的選項。以下是三大類型的代表性服務:
1. Google Cloud BigQuery 與 Amazon EMR:雲端原生的資料倉儲與開源框架
這兩者代表了不同的雲端服務模式。Google BigQuery 是無伺服器(Serverless)、全託管的企業級資料倉儲,使用者無需管理底層架構,即可使用SQL進行極高速的PB級查詢,適合專注於分析而非維運的團隊。Amazon EMR 則是託管式的Hadoop與Spark叢集服務,它簡化了開源框架在AWS雲端的部署、管理和擴縮容,讓企業能繼續沿用熟悉的Hadoop生態系工具,同時免除硬體維運負擔。
2. Databricks 與 Cloudera:專為機器學習與混合雲設計的強大運算環境
Databricks 由Apache Spark原創團隊成立,提供以協作筆記本為核心的統一資料分析平台。它深度優化Spark效能,並整合MLflow等機器學習生命週期管理工具,深受資料科學家與工程師團隊青睞。Cloudera 則提供強大的企業級資料平台(CDP),尤其擅長混合雲與多雲部署,強調企業級的資料治理、安全性與合規性,適合有嚴格資料管控需求的大型組織。
3. Oracle Big Data 與 IBM InfoSphere:企業級高可用性與 AI 數據治理平台
傳統企業軟體巨頭也提供了現代化的大數據解決方案。Oracle Big Data 服務整合了雲端資料庫、資料湖倉與內建AI能力,強調與既有Oracle環境的高整合度與高效能。IBM InfoSphere 系列則著重於端到端的資料整合、品質管理與觀測,其強大的資料治理與譜系追蹤功能,能確保數據在大型複雜企業環境中的可信度與可追溯性,滿足金融、醫療等高度監管行業的需求。
四、 現代大數據平台的技術演進趨勢:湖倉一體與 AI 賦能
大數據技術持續演進,當前兩大主流趨勢正重新定義平台的架構與互動方式:
1. 邁向資料湖倉 (Data Lakehouse) 的架構升級:兼具低成本儲存與高效能分析
資料湖倉被視為下一代大數據基礎設施的標準架構。它旨在融合資料湖的低成本、靈活儲存非結構化數據的優勢,與資料倉儲的高效能SQL查詢與強事務一致性優勢。透過如Apache Iceberg、Delta Lake等開放表格格式,企業可以在同一套儲存(如雲端物件儲存)上,同時運行低成本的大數據處理與高併發的互動式分析,簡化架構、降低成本,並消除數據孤島。
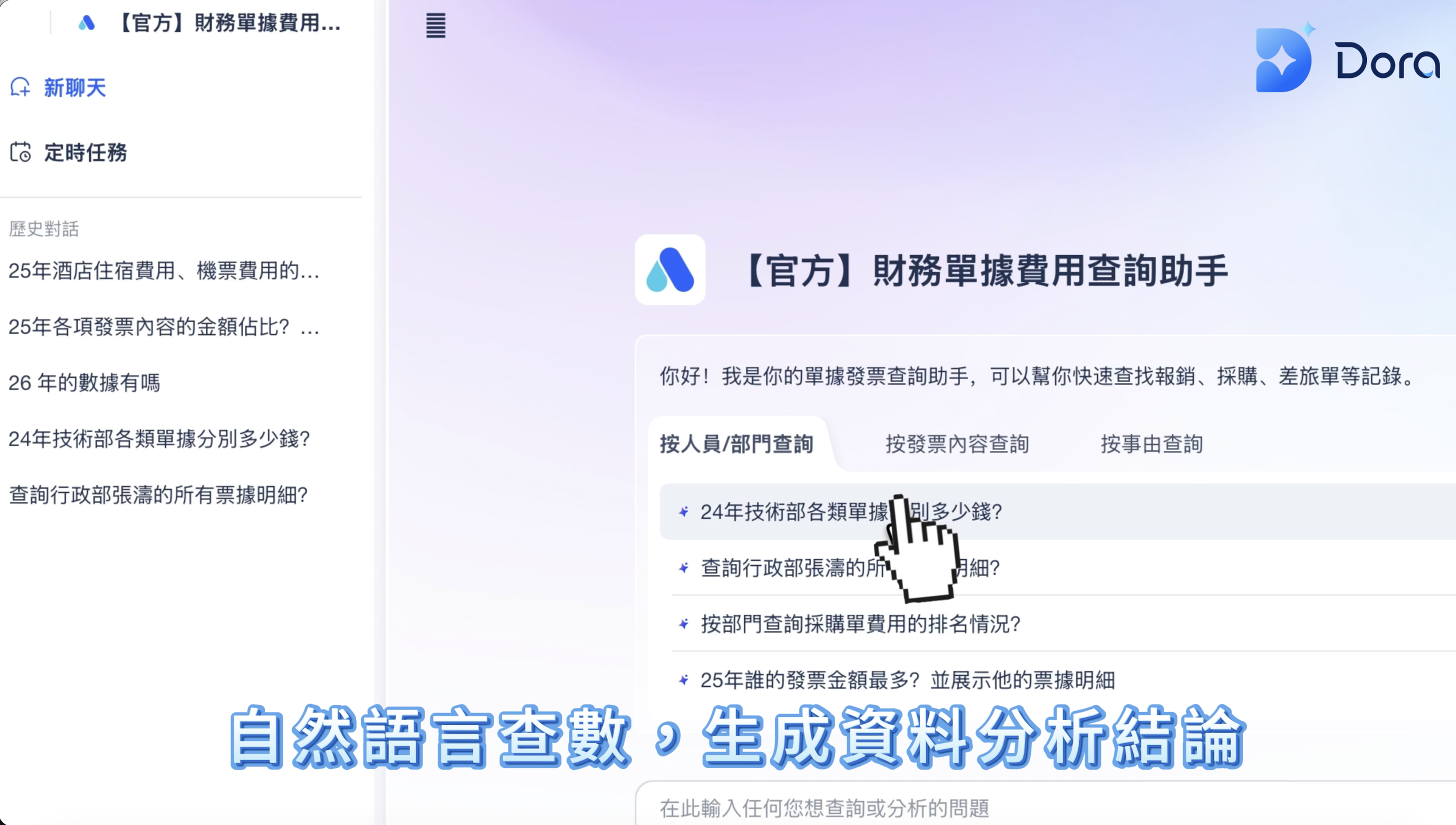
2. 結合 AI 數據智慧體 (AI Agent):實現自然語言對話式的自動化洞察
前端應用正經歷革命性的變化。現代大數據平台開始整合大型語言模型,使用者不再需要學習複雜的SQL或程式語法。透過AI助手(例如帆軟的Dora),事業部人員只需以自然語言對話(如「幫我找出上季度銷售額下降最快的三個產品類別及其原因」),AI就能自動解析意圖、生成查詢、執行分析並產出圖表與文字解讀。這將大幅降低數據使用的門檻,實現真正普及的「全民數據分析」。
常見問題
主要區別在於處理數據的規模、架構和應用深度。大數據平台專為處理PB級的海量、多樣、高速數據而設計,採用分散式運算架構,並能支援實時分析與機器學習應用。一般數據平台則主要處理TB級以下的結構化數據,多用於批次處理和描述性商業智慧。
台灣政府提供了多個免費的公開數據入口,例如彙整全台各部會資料的「政府資料開放平臺」,深入民生數據的「內政大數據平台」,以及提供即時市政數據的「臺北市資料大平臺」。這些平台涵蓋了經濟、人口、交通、教育等多個領域。
對於缺乏專業技術團隊的企業,建議優先考慮採用全託管的雲端大數據服務,例如 Google BigQuery 或 Amazon EMR。這類服務免去了底層基礎設施的維運負擔,讓企業能專注於數據分析與業務應用,是更高效務實的選擇。
完全可以。只要企業在平台前端部署了自助式商業智慧工具,例如 FineBI,事業部人員即可透過直觀的拖拉拽介面或自然語言查詢,直接分析億級數據並產出視覺化圖表,無需編寫任何程式碼。
一個完整的企業級大數據平台通常包含三層核心架構:數據採集與整合層(使用如Kafka的串流工具)、分散式儲存與處理層(如Hadoop HDFS與Spark),以及數據分析與視覺化層(串接如FineBI等BI工具),形成端到端的資料處理管線。







免費資源下載