一、Python大數據是什麼?基礎概念與定義
Python大數據分析是指運用Python語言及其豐富的生態系統,來處理、分析與挖掘龐大且複雜資料集的一套方法論與實務技術。它的核心是將傳統資料分析的能力,擴展至能應對現代企業所面臨的海量、高速與多樣性資料。
1. Python大數據分析的定義與核心概念
Python大數據分析不僅僅是使用Python寫程式,更是整合了資料工程、統計學與機器學習的綜合性流程。根據常見產業實務,其核心概念包含三個層面:一是高效處理能力,能夠操作超越單機記憶體規模的資料;二是可擴展的生態系,擁有從資料擷取、清洗到建模的完整工具鏈;三是洞察轉化,能將分析結果轉為可執行的商業決策。這使得Python成為連接原始數據與商業智慧的重要橋樑。
2. Python在大數據分析中的角色是什麼
Python在大數據分析中扮演著核心工具與整合平台的角色。它之所以關鍵,是因為其簡潔的語法降低了分析門檻,同時強大的開源套件庫提供了堪比專業軟體的運算能力。在資料處理流程中,Python是自動化腳本的核心,能串接從API、資料庫到雲端儲存的各種資料源,並透過一致的介面進行後續分析,大幅提升了數據處理流程的效率與可重複性。
3. Python在大數據分析中可以處理哪些類型的資料
Python能處理的資料類型極為廣泛,主要包括:
- 結構化資料:例如來自關聯式資料庫(如MySQL)、CSV、Excel的表格型資料,是Pandas套件最擅長處理的類型。
- 半結構化資料:像是JSON、XML格式的資料,常見於網頁API回傳的數據。
- 非結構化資料:包括文字文件、社交媒體貼文、圖片、影音等,可透過如NLTK、OpenCV等專門套件進行特徵提取與分析。
這種多樣化的處理能力,讓Python能勝任從傳統財報分析到社群輿情監控等各種現代數據任務。
4. Python大數據分析與傳統資料分析差異
Python大數據分析與傳統分析(如僅使用Excel)的關鍵差異在於規模、自動化與複雜度。傳統分析常受限於單機軟體的處理上限與手動操作;而Python分析則能透過程式腳本自動處理TB級資料,並應用機器學習模型進行預測與分類。此外,Python的分析流程可重現且易於版本控制,確保分析結果的穩定性與可信度,這是傳統手工分析難以達到的。
二、為什麼企業都在用Python做大數據分析?
企業選擇Python進行大數據分析,是因為它提供了最佳的成本效益、開發效率與生態整合性。在追求數據驅動決策的時代,Python能快速將數據轉化為競爭優勢。
1. Python為什麼成為資料分析主流語言
Python成為主流,歸因於其低門檻、高產能與強大的社群支持。相較於Java或C++,Python語法直觀易學,能讓業務端分析師更快上手。同時,如Pandas、NumPy、Scikit-learn等成熟套件,提供了「開箱即用」的專業分析功能,大幅縮短從開發到部署的時間。根據產業觀察,其豐富的開源資源與跨平台特性,也顯著降低了企業的技術導入與維護成本。
2. Python與Excel在資料分析中的差異
Python與Excel的根本差異在於自動化能力、資料規模與分析深度。Excel適合手動、小規模的試算與圖表製作;而Python則能以腳本自動執行重複性工作,處理遠超Excel極限的資料量,並進行複雜的統計檢定與機器學習建模。簡而言之,Excel是優秀的個人分析工具,而Python是建構企業級、可擴充分析流水線的基石。
| 對比維度 | Excel | Python |
|---|---|---|
| 自動化能力 | 需手動操作,適合單次分析 | 可用腳本自動化批量處理 |
| 資料規模 | 適合小型資料(MB級) | 可處理大規模資料(GB~TB級) |
| 分析深度 | 基礎統計與圖表為主 | 支援統計分析、機器學習與預測模型 |
| 重複性任務 | 重複操作成本高 | 可一鍵重跑整個分析流程 |
| 可擴展性 | 擴展性有限 | 可整合API、資料庫與AI模型 |
| 工程能力 | 偏手工工具 | 可構建企業級分析流水線 |
| 可重現性 | 容易因操作改變結果 | 程式化流程,可完整重現 |
3. 哪些產業最依賴Python進行資料分析
幾乎所有數位化轉型的產業都依賴Python,其中以下領域尤為顯著:
- 金融科技(FinTech):用於風險建模、詐騙偵測與演算法交易。
- 電子商務與零售:應用於客戶分群、推薦系統與銷售預測。
- 製造業:進行生產線良率分析、預測性維護與供應鏈優化。
- 醫療生技:協助基因體學資料分析與臨床試驗數據處理。 這些產業的共同點是需要處理高維度、即時性或海量的數據,並從中發掘潛在模式。
4. Python在企業決策中的實際價值
Python在企業決策中的價值是將數據從「事後報表」轉為「事前預警」與「決策支援」。透過自動化資料流水線,管理者能更即時地看到關鍵指標(KPI)變化。更重要的是,透過機器學習模型,Python能提供趨勢預測與情境模擬,例如預測下一季營收或評估行銷活動的潛在影響,讓決策從經驗直覺走向數據驅動。
三、沒有程式背景可以學Python進行資料分析嗎?
完全可以。許多成功的數據分析師來自商學、統計甚至文科背景。關鍵在於找到正確的學習路徑與工具,並將焦點放在解決問題而非鑽研複雜的程式語言特性。
1. 不同背景學習者的適應性分析
不同背景的學習者各有優勢:
- 商管/行銷背景:對業務指標敏感,學習重點應放在如何用Python計算ROI、轉換率等,工具上可先從Pandas與簡易視覺化入手。
- 統計/數學背景:已具備分析思維,需熟悉如何用Python(如Statsmodels套件)實作統計檢定與模型。
- 完全無技術背景:建議從圖形化工具或Google Colab等雲端環境開始,避免初學即陷入本地環境設定的困難,聚焦於理解變數、迴圈與函式等核心概念。
2. 企業數據分析師的典型成長路徑
在企業中,數據分析師的成長通常遵循「工具掌握 → 流程理解 → 業務應用」的路徑:
- 初階:學會使用Python(Pandas, Matplotlib)完成主管指派的取數與製圖任務。
- 中階:能獨立設計分析流程,從資料清洗到產出洞察報告,並能運用基礎機器學習模型(如Scikit-learn)。
- 高階/資料科學家:能主導專案,建立預測模型,並將分析結果產品化(如開發自動化報告系統或決策儀表板)。
3. 學習Python資料分析前需要理解的基礎概念
在開始寫程式前,建議先建立以下思維:
- 資料思維:了解結構化與非結構化資料的差異,以及何謂「髒數據」。
- 流程思維:熟悉「擷取→清洗→分析→視覺化」的標準流程。
- 業務思維:清楚分析的目標是為了回答什麼商業問題,而非為了使用酷炫的技術。 理解這些,能讓後續的程式學習更有方向與效率。
4. 初學者常見學習障礙
初學者最常遇到的障礙包括:
- 環境設定困難:建議直接使用Anaconda發行版或Google Colab雲端環境起步。
- 過度糾結語法細節:應以實用為導向,先學會完成一個小專案(如分析一份銷售資料),過程中自然習得必要語法。
- 遇到錯誤(Bug)即挫折:應將解讀錯誤訊息視為學習的一部分,這是理解程式邏輯的寶貴機會。
四、Python資料分析完整流程:從方法框架到實務操作
一個完整的Python資料分析流程,是將原始數據轉化為決策資訊的系統化旅程。它確保分析的完整性、可重現性與可信度。
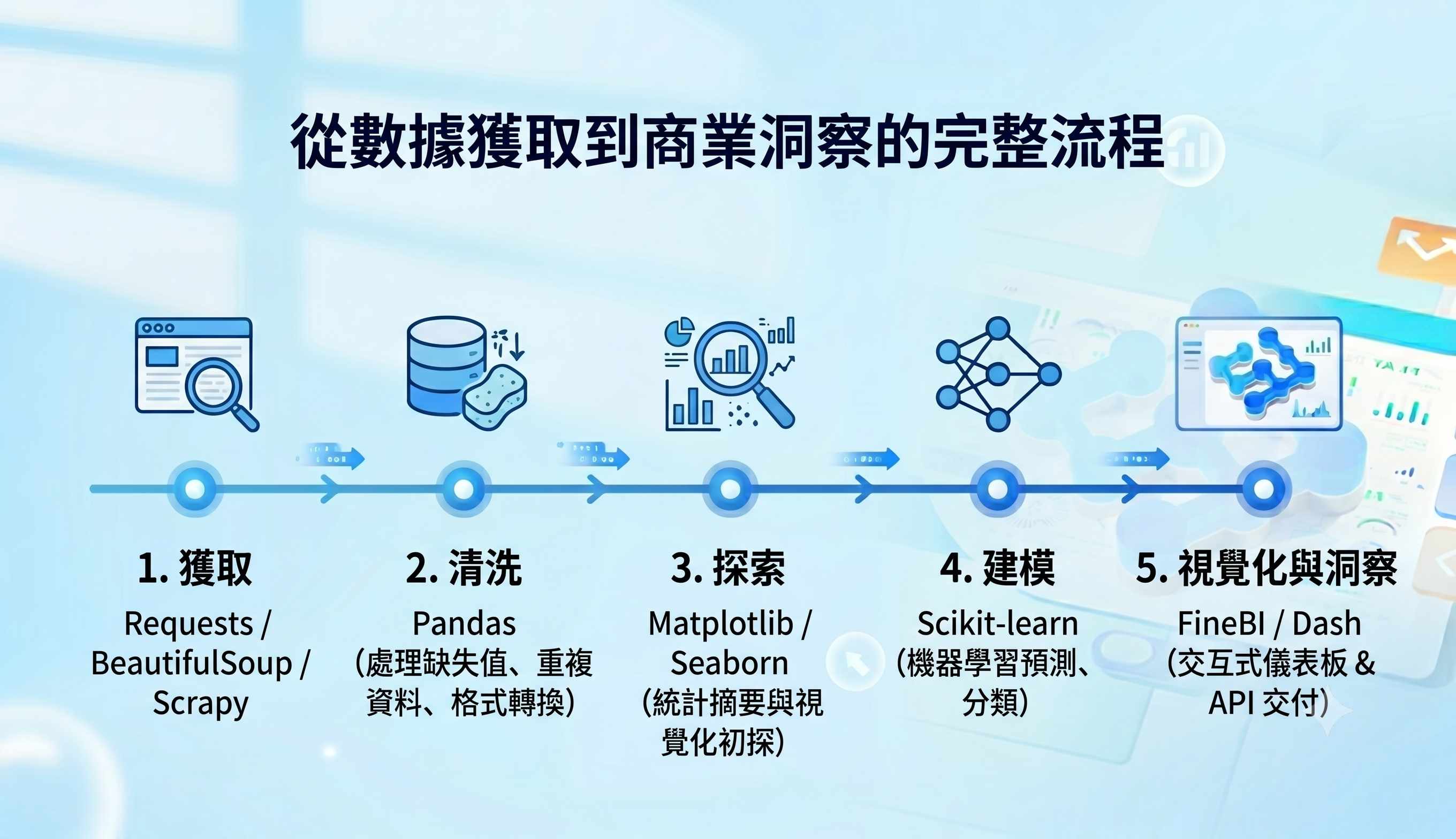
1. 資料分析的完整流程總覽
標準流程是一個迭代循環,主要包括五個階段:
- 資料擷取:從檔案、資料庫或API取得原始資料。
- 資料清洗與前處理:處理缺失值、異常值,並將資料轉為適合分析的格式。
- 探索式資料分析(EDA):透過統計摘要與視覺化,初步理解資料分佈與關聯。
- 建模與分析:根據問題選擇合適的統計模型或機器學習演算法進行深入分析。
- 視覺化與結果呈現:將複雜的分析結果,轉化為易懂的圖表、儀表板或報告。
2. 如何建立資料來源與擷取機制
建立穩健的資料擷取機制是分析的第一步。Python提供了對應各種來源的工具:
- 本地檔案:使用Pandas的
read_csv(),read_excel()函數。 - 資料庫:使用
sqlalchemy或pymysql等套件進行連接與查詢。 - API:使用
requests套件發送HTTP請求,並解析回傳的JSON資料。 實務上,企業常將此步驟自動化,設定排程腳本定期更新資料,以確保分析基礎的時效性。
3. 資料清洗與前處理的關鍵方法
資料清洗通常佔據分析專案最多時間,關鍵任務包括:
- 處理缺失值:可依情境選擇刪除、以平均數/中位數填補,或使用模型預測填補。
- 偵測與處理異常值:透過箱形圖或標準差方法識別,並決定保留或修正。
- 格式標準化:統一日期格式、去除字串空白、將類別資料進行標籤編碼或獨熱編碼。 使用Pandas進行這些操作非常高效,是資料品質的關鍵守門員。
4. 探索式資料分析(EDA)的基本步驟與分析思路
EDA的目的是「讓數據自己說話」。基本步驟為:
- 使用
.describe()、.info()瞭解資料概況。 - 繪製直方圖、箱形圖檢視單變量分佈。
- 繪製散佈圖、相關熱力圖觀察變數間關係。
- 進行分組聚合(GroupBy),比較不同群體的差異。 這個階段不預設立場,而是透過視覺化發現值得深入探詢的模式或問題。
5. 機器學習建模在資料分析中的應用方式
機器學習建模讓分析從「描述過去」邁向「預測未來」。常見應用方式包括:
- 預測問題:如使用線性迴歸、時間序列模型預測營收、股價。
- 分類問題:如使用邏輯迴歸、決策樹判斷客戶是否會流失、交易是否為詐騙。
- 分群問題:如使用K-Means對客戶進行市場區隔。 在實務中,會將資料分為訓練集與測試集,並以準確率、召回率等指標評估模型效能,避免過度擬合。
6. 數據視覺化與結果呈現
最終的視覺化與呈現決定了分析的影響力。要點如下:
- 圖表選擇:趨勢用折線圖,比較用長條圖,組成比例用圓餅圖,關聯用散佈圖。
- 工具應用:Matplotlib用於客製化繪圖,Seaborn提供更美觀的統計圖表,Plotly則適合製作互動式儀表板。
- 呈現邏輯:報告應遵循「結論先行 → 支持論據 → 行動建議」的結構,讓管理者能快速抓住重點並做出決策。
五、Python資料分析生態系統解析:企業最常用的核心套件
Python資料分析的強大,建立在數個核心套件之上。它們各有專精,共同構成了一個高效的資料處理與分析工作流。
1. NumPy:高效處理大型數據矩陣
NumPy是Python科學計算的基石,它提供了高效能的多維陣列物件與數學函式庫。在數據分析中,NumPy擅長執行向量化運算,能讓複雜的數學操作(如矩陣乘法、統計計算)速度提升百倍以上。它是Pandas與許多機器學習套件的底層依賴,理解其陣列操作是進行高效能分析的基礎。
2. Pandas:資料清洗與數據轉換
Pandas是數據分析師的「瑞士刀」。其核心資料結構DataFrame(類似Excel表格)讓資料的篩選、分組、合併與樞紐分析變得極為直觀。實務上,超過70%的資料清洗與整理工作可透過Pandas完成,例如使用groupby進行銷售額按月份彙總,或用merge整合來自不同來源的客戶資料表。
3. Requests:串接API自動擷取數據
在現代數據生態中,許多資料來自網路API。Requests套件讓Python能夠簡單地與網路服務溝通,自動化擷取即時數據,例如股價、天氣資訊或社交媒體公開數據。這使得分析腳本能定期更新資料來源,保持分析的時效性與動態性。
4. Matplotlib與Seaborn:建立商業分析圖表
Matplotlib是Python最基礎的繪圖庫,提供高度的客製化能力,能繪製任何形式的圖表。Seaborn則建構於Matplotlib之上,以更簡潔的語法提供美觀的統計圖表,並內建了許多複雜視覺化(如熱力圖、成對關係圖)的實現。兩者結合,能滿足從快速探索到最終報告美編的所有圖表需求。
- Python數據分析工具分層架構
| 層級 | 工具 | 用途 |
|---|---|---|
| 數據處理層 | Pandas / NumPy | 清洗與計算 |
| 數據獲取層 | Requests / SQL | API與資料庫 |
| 分析建模層 | Scikit-learn | 機器學習 |
| 視覺化層 | Matplotlib / Seaborn | 圖表展示 |
六、Python大數據演算法實戰:企業最常用的機器學習模型
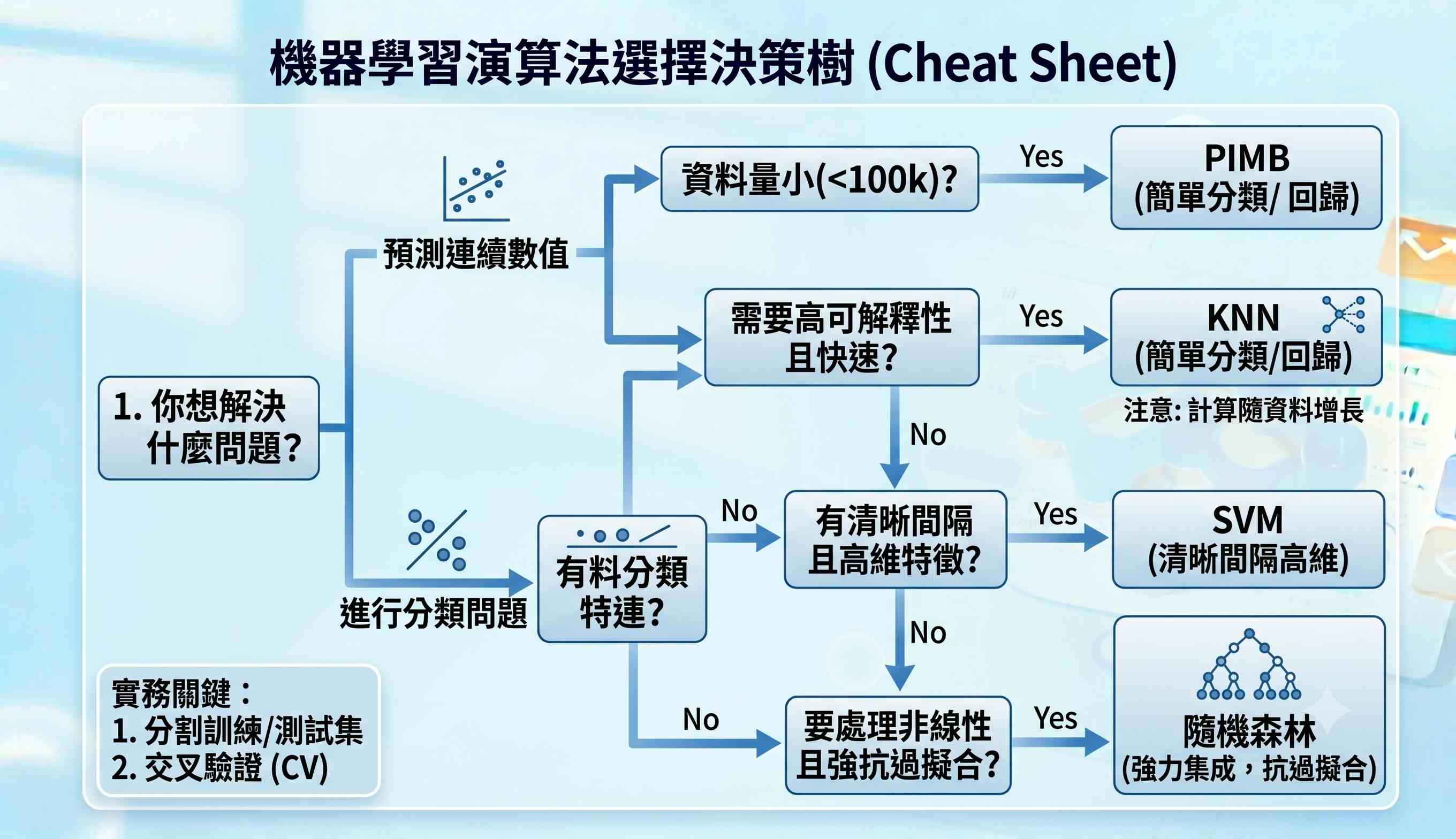
在企業實戰中,並非所有機器學習模型都同等重要。以下四種演算法因其解釋性、穩定性與實用性,成為最常被應用的核心模型。
1. KNN演算法:客戶分群與推薦系統應用
KNN(K-Nearest Neighbors,K最近鄰)是一種直觀的分類與迴歸演算法。在商業應用上,它常被用於:
- 客戶分群:根據消費行為、人口屬性找出相似的客戶群體。
- 推薦系統:基於「與你喜好相似的人也喜歡…」的原理,推薦商品或內容。 其實施簡單,不需複雜的訓練過程,適合作為初階智慧應用的起點。
2. 決策樹(Decision Tree):商業決策分析基礎
決策樹模型透過一系列「若…則…」的規則對數據進行分類或預測。其最大優勢是模型結果易於解釋,可以直觀地看到影響決策的主要因素與門檻值,例如「若客戶年齡大於30歲且消費金額超過1000元,則歸類為高價值客戶」。這使得它非常適合用於需要向業務部門解釋分析邏輯的場景。
3. 隨機森林(Random Forest):提升預測準確率的方法
隨機森林是決策樹的進化版,它透過建立多棵決策樹並綜合其結果來做出預測。這種方法能有效降低單一決策樹容易產生的過度擬合問題,從而提高模型的穩定性與準確度。在企業中,它被廣泛用於需要高可信度預測的任務,如信用評分、客戶流失預警等。
4. SVM支援向量機:高準確度分類問題實戰
SVM(Support Vector Machine,支援向量機)擅長在高維度空間中尋找最佳的超平面來區分不同類別的數據。它在特徵維度高但樣本數相對不多的情境下表現出色,例如文本分類(判斷客戶評論為正面或負面)或生物資訊學中的基因分類。雖然模型解釋性較低,但其分類邊界的精確度常優於其他方法。
七、Python分析完成後如何落地決策?
分析的最終價值在於驅動行動。將Python的分析成果無縫整合到日常決策流程中,是現代企業數據應用的關鍵一步。
1. 分析結果如何轉成決策介面
將Python的分析成果落地,一個高效方式是輸出至專業的商業智慧(BI)工具,例如**FineBI**。具體做法是:Python完成數據清洗、特徵工程甚至建模後,將處理好的乾淨資料集輸出至資料庫或檔案,再由FineBI讀取並製作成交互式儀表板。這讓業務主管不需接觸程式碼,就能透過點選、篩選等方式,直觀地探索數據、追蹤KPI,並基於最新分析結果做出決策。
2. AI數據分析工具的應用方式
新興的AI數據分析平台(如**Dora)提供了另一條更敏捷的路徑。這類工具可作為企業的AI數位員工**,它能承接Python等工具產生的分析模型與業務規則(封裝為Skill),讓管理者或業務人員直接透過自然語言提問,例如「分析本月營收下降的原因」。Dora這類平台會自動調用背後的數據與模型,進行維度拆解、歸因分析,並生成文字摘要與圖表,大幅降低了使用數據分析的門檻,讓分析洞察能更快速地融入每日工作流。

FAQs
Python結合適當的工具(如Pandas搭配效能優化、Dask處理大於記憶體資料),能有效處理從MB到TB級的數據。對於PB級以上的超大型數據,通常會結合分散式運算框架(如PySpark)來完成。對大多數企業而言,Python的生態系已能涵蓋90%以上的數據分析需求。
完全可以。許多成功的分析師來自非程式背景。建議從解決一個具體的小問題開始(例如分析自己的消費記錄),使用Google Colab等免安裝環境,並聚焦於學習Pandas資料操作與基礎視覺化。實作導向的學習遠比鑽研理論語法更有效。
主要差異在於自動化、規模與擴展性。Excel適合手動、小規模的靜態分析與圖表;Python則透過腳本實現全自動化流程,能處理海量數據,並整合機器學習進行預測性分析。Excel是個人工工具,Python則用於建構企業級、可重複的分析系統。
初學者應掌握核心四大套件:NumPy(數學運算)、Pandas(資料處理)、Matplotlib/Seaborn(視覺化)與Scikit-learn(機器學習)。隨著需求深入,可再學習Requests(API串接)、SQLAlchemy(資料庫操作)等。整合開發環境推薦使用Jupyter Notebook或VS Code。
若以求職為目標,應能獨立完成端到端分析專案,例如:從API取得資料、清洗與EDA、建立預測模型,並輸出儀表板結果。這代表你具備實務問題解決能力,而不只是語法知識。
常見挑戰包括資料品質問題(缺失與錯誤數據)、運算效能瓶頸(需優化或分散式工具)、模型解釋難度(如何讓非技術人員理解結果),以及分析成果落地問題(如何真正影響業務決策)。這些都需要技術與業務理解的結合。







免費資源下載