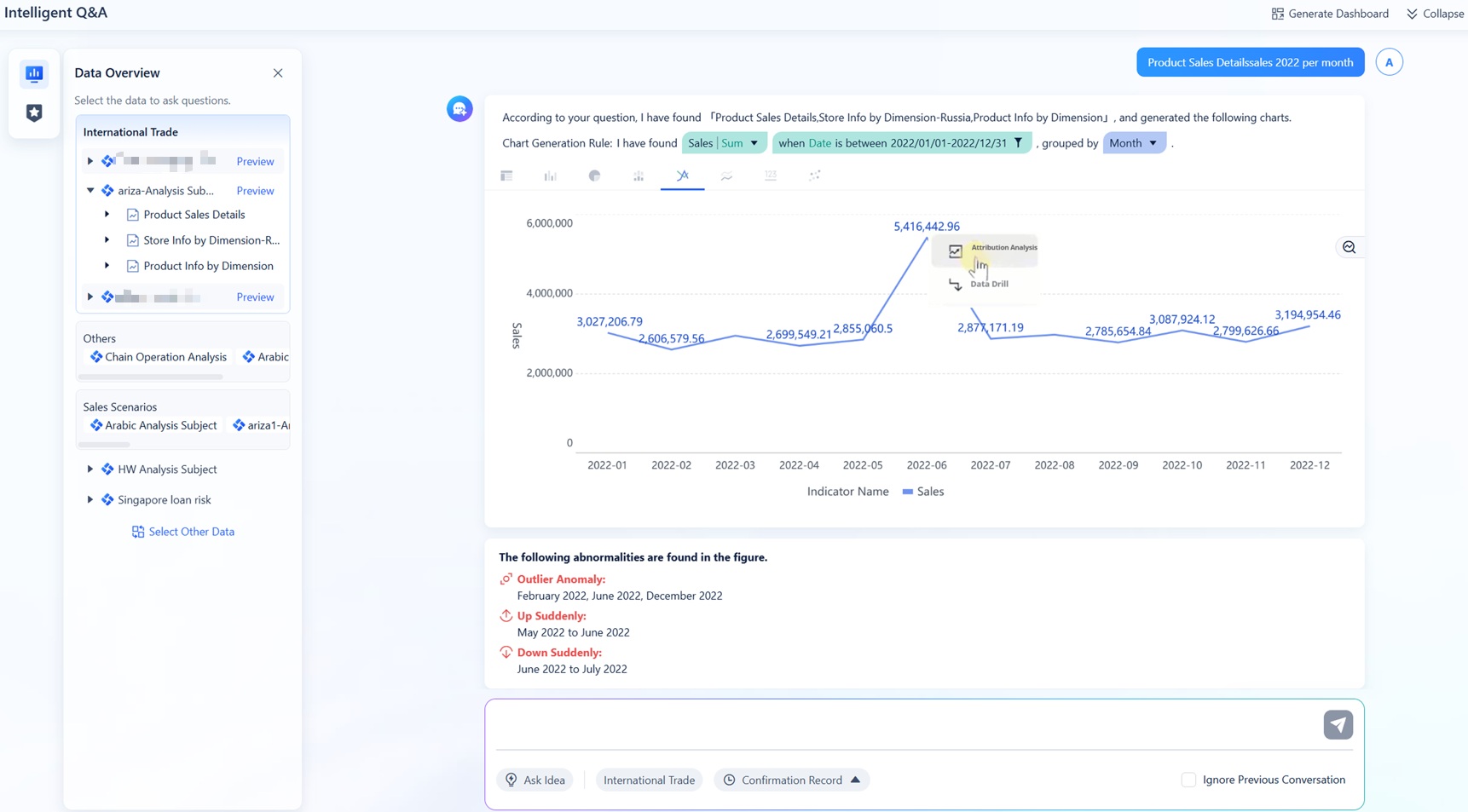
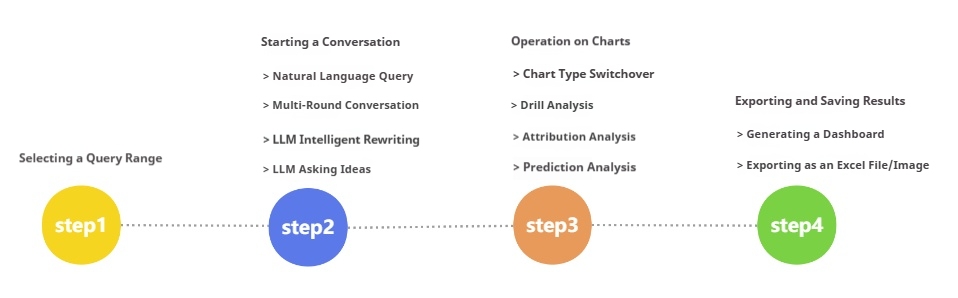
An AI data catalog helps enterprises find, understand, and trust data faster by combining metadata management, governance, lineage, and AI-driven discovery in one governed system. For IT managers, data leaders, and analytics teams, the business value is immediate: less time hunting for tables, fewer decisions made on misunderstood data, and stronger control over compliance, ownership, and access. If your teams are dealing with fragmented documentation, duplicate reports, low trust in metrics, or rising governance pressure, this is the category to understand now.
AI data catalog at a glance
An ai data catalog is a platform that automatically collects and enriches metadata from across your data environment, then uses AI to improve discovery, context, and trust. In plain language, it is the system that tells users what data exists, what it means, where it came from, who owns it, whether it is reliable, and how to use it safely.
That matters because most enterprises do not suffer from a lack of data. They suffer from a lack of usable context. Analysts cannot find the right dataset. Engineers inherit pipelines with poor documentation. Business users see multiple dashboards with conflicting numbers. Governance teams struggle to trace sensitive data across systems. A modern ai data catalog addresses these operational bottlenecks directly.
At a high level, it solves three core problems:
Data discovery: Users can locate relevant datasets, dashboards, metrics, and reports quickly.
Context: Metadata, lineage, glossary terms, usage patterns, and ownership add meaning to raw assets.
Trust: Governance controls, certifications, quality indicators, and permissions reduce risky data use.
A quick distinction is important. A traditional catalog gives you a centralized inventory. A chatbot layer gives you a conversational interface. A true ai data catalog goes further: it continuously improves metadata quality, semantic understanding, lineage visibility, and governance-backed answers across the data stack.
What an AI data catalog is and how it works
A useful way to think about an ai data catalog is as a governed metadata engine with intelligence built in. It does not just store information about data assets. It learns from that information and makes it easier for users to find the right asset, understand business meaning, and act with confidence.
Core capabilities
The strongest ai data catalog platforms typically include several foundational capabilities.
Metadata ingestion across the modern stack
The platform connects to databases, cloud warehouses, data lakes, ETL and ELT pipelines, BI tools, notebooks, and governance systems. It ingests metadata such as schema details, table definitions, column structures, dashboard links, query logs, ownership data, and transformation dependencies.
Without broad ingestion, the catalog becomes incomplete. And incomplete metadata leads to poor search relevance, weak trust signals, and inconsistent governance.
Automated classification, tagging, lineage mapping, and semantic enrichment
Once metadata is collected, AI helps classify assets, detect sensitive fields, suggest tags, connect related business terms, and map upstream-downstream lineage. This is where the catalog starts to move from static repository to active intelligence layer.
Examples include:
Auto-tagging columns likely to contain PII
Suggesting business glossary mappings for fields with unclear names
Detecting duplicate or overlapping datasets
Mapping lineage from source systems to dashboards
Generating draft descriptions for tables and metrics
Search, recommendations, and context-aware answers
Users can search with keywords, business language, or natural-language questions. The best platforms do more than keyword matching. They use metadata, relationships, usage signals, and governance rules to rank results and answer questions with context.
Instead of returning a random list of tables for “customer churn,” an ai data catalog should ideally surface:
The certified churn dataset
The approved KPI definition
The owner or steward
Related dashboards
Freshness and quality status
Downstream dependencies
The AI layer behind the catalog
The “AI” in ai data catalog is not magic. It is a set of techniques applied to metadata, usage behavior, and governance logic to make the catalog more useful and more scalable.
Machine learning and language models for schema, usage, and meaning
AI models can interpret table names, column patterns, descriptions, query behavior, and related documentation to infer meaning. They help identify semantic similarity across assets, recommend glossary links, and improve search relevance over time.
For example, a model may recognize that cust_id, customer_key, and client_identifier likely refer to the same business concept when supported by documentation, usage patterns, and lineage.
Signals from queries, documentation, ownership, and lineage
A mature ai data catalog does not rely on one signal. It combines multiple signals to improve confidence:
Query history and asset popularity
Steward edits and documentation depth
Ownership assignments
Lineage relationships
Business glossary mappings
Data quality alerts
Certification status
This multi-signal approach is what makes recommendations and answers more useful in real enterprise environments.
Guardrails that keep answers grounded
This is the critical difference between useful AI and risky AI. A trustworthy ai data catalog should ground its outputs in approved metadata, permissions, lineage, and governance policies. It should not “guess” when authoritative metadata is missing.
That means answers should reflect:
What the user is allowed to access
Which assets are certified or approved
Whether lineage supports the explanation
Whether freshness or quality issues are present
Whether a human steward has reviewed sensitive classifications
Key metrics (KPIs) for an AI data catalog
Enterprise teams evaluating or running an ai data catalog should track a focused set of KPIs. These metrics help measure whether the platform is improving discoverability, governance, and operational efficiency.
Key Metrics (KPIs)
Metadata coverage rate: Percentage of relevant data systems and assets connected to the catalog.
Documentation completeness: Share of datasets, columns, and dashboards with descriptions, ownership, and glossary mappings.
Lineage coverage: Percentage of critical assets with table-level or column-level lineage mapped.
Search success rate: Percentage of searches that lead to a click, save, or downstream usage action.
Time to data discovery: Average time it takes users to find a usable and trusted asset.
Certified asset adoption: Usage share of approved datasets and dashboards versus uncertified ones.
Auto-classification accuracy: Precision of AI-generated tags such as PII, domain labels, or sensitivity classes.
Steward review turnaround: Time required for humans to review, approve, or correct AI suggestions.
Duplicate asset reduction: Decrease in overlapping reports, datasets, or semantic definitions.
Governance incident rate: Number of access, compliance, or misuse events linked to poorly understood data.
User adoption by role: Active usage among analysts, engineers, data stewards, and business teams.
Feedback correction rate: Volume and resolution speed of user-submitted metadata corrections.
These KPIs are especially helpful during rollout because they connect platform activity to operational outcomes.
How AI data catalog differs from a traditional data catalog
Many buyers assume an ai data catalog is just a legacy catalog with a better search bar. That is too simplistic. Traditional catalogs still provide value, but AI changes the economics and usability of cataloging at scale.
Where traditional catalogs help
Traditional data catalogs are useful for building a centralized inventory of data assets. They typically support:
Asset registration
Ownership tracking
Documentation storage
Glossary terms
Tag-based organization
Basic governance workflows
They are often effective when teams are disciplined enough to keep metadata current. In highly controlled environments, manual curation and rule-based governance can work reasonably well.
The issue is scale. Manual curation struggles in environments with frequent schema changes, fast-moving pipelines, new SaaS sources, and growing self-service analytics demand.
What changes with AI
AI improves both speed and quality when applied correctly.
Faster onboarding of new assets
Instead of waiting for data stewards to manually tag every new table or dashboard, AI can propose descriptions, tags, owners, and glossary mappings as assets appear.
Better semantic search and question answering
Traditional search often depends on exact matches or manually applied labels. AI improves retrieval by understanding business language, synonyms, and usage context.
More adaptive context from usage patterns and lineage
As teams query data, build reports, and update documentation, the ai data catalog can use those signals to refine ranking, recommendations, and metadata quality. It becomes more useful over time, not just larger.
A simple comparison makes the distinction clearer:
Capability
Traditional Data Catalog
AI Data Catalog
Metadata collection
Often scheduled and partly manual
Automated and broader across systems
Tagging and classification
Rule-based or manual
AI-assisted and scalable
Search
Keyword-driven
Semantic and context-aware
Documentation
Human-created only
Human-reviewed, AI-accelerated
Recommendations
Limited
Usage- and lineage-informed
Governance context
Static policies
Dynamic, policy-aware responses
Adoption potential
Depends heavily on discipline
Higher when discovery is fast and intuitive
Why an AI data catalog is not just a chatbot overlay
This is where many evaluations go wrong. A vendor may add a conversational box on top of basic documentation and market it as AI. That may improve the user interface, but it does not create a true ai data catalog.
What a chatbot overlay can do
A chatbot overlay can still provide value in narrow use cases. It can:
Offer a conversational interface over existing documentation
Help users phrase search queries more naturally
Navigate known assets faster
Summarize already-curated descriptions
For organizations with a reasonably strong metadata foundation, this can improve accessibility.
In some analytics environments, it can also be paired with conversational BI experiences. FineChatBI, for example, fits naturally into this discussion as a user-facing layer that can help business users ask questions in plain language and accelerate dashboard exploration. But that kind of conversational experience is most valuable when it sits on top of well-governed, high-quality metadata and trusted analytics assets.
Where a chatbot-only approach falls short
A chatbot-only strategy breaks down quickly in enterprise environments.
Limited grounding when metadata is incomplete
If metadata is stale, fragmented, or missing, the chatbot has little reliable context. It may produce polished but shallow answers, or worse, confident answers that are wrong.
Weak governance without permissions, lineage, and quality signals
A chatbot that does not honor role-based access, asset certification, sensitivity labels, or lineage context introduces risk. This is especially problematic in regulated industries or any environment with strict audit requirements.
Shallow answers without interoperability
Enterprise data ecosystems span cloud warehouses, BI tools, orchestration platforms, notebooks, governance systems, and policy controls. A chatbot sitting on top of one documentation repository cannot unify these layers meaningfully on its own.
What makes a true AI catalog different
A genuine ai data catalog is different because the intelligence is embedded in the operating model of metadata, not just the interface.
A governed metadata foundation
The platform maintains a trusted metadata layer across systems, enriched with lineage, ownership, glossary alignment, classification, certification, and permissions.
Deep integration with discovery and stewardship workflows
The catalog is connected to stewardship tasks, governance reviews, policy enforcement, and asset lifecycle management. It supports ongoing metadata improvement.
Intelligence that improves catalog quality
This is the biggest distinction. A real ai data catalog does not just answer questions. It improves the underlying catalog by detecting gaps, proposing corrections, enriching context, and supporting human review loops.
Business impact and must-have capabilities of an AI data catalog
From a business standpoint, the value of an ai data catalog is not just better search. It is a measurable improvement in speed, trust, governance, and operating efficiency.
Outcomes teams care about
Faster data discovery and time to insight
Analysts spend less time searching and validating. Engineers spend less time answering repetitive “what does this table mean?” questions. Business users gain faster access to trusted assets.
Stronger governance and compliance readiness
With lineage, access controls, auditability, and sensitive data classification in place, organizations can respond more confidently to compliance reviews and internal governance requirements.
Lower operational overhead
Automation reduces the burden of manual documentation, repetitive tagging, and metadata maintenance. Stewards can focus on review and policy enforcement instead of catalog housekeeping.
Must-have capabilities
When evaluating platforms, these are non-negotiable capabilities for enterprise adoption.
Interoperability across the stack
The ai data catalog should work across cloud data platforms, ETL and ELT tools, BI systems, data quality solutions, policy engines, and governance workflows.
Intelligence for ranking, recommendations, anomaly detection, and glossary alignment
AI should improve discovery quality, not just summarize metadata. It should also support issue detection and semantic consistency.
Role-based access, auditability, and human-in-the-loop review
Sensitive decisions should never be fully automated without oversight. The right model is AI-assisted, steward-approved governance.
How to evaluate and adopt an AI data catalog
Buying the wrong platform can leave you with an expensive search box and very little trust. A disciplined evaluation process helps avoid that outcome.
Questions to ask vendors
Use these questions to separate mature platforms from superficial AI claims.
How are AI outputs grounded?
Ask how the system ties answers to metadata, lineage, permissions, certification status, and quality indicators. If the answer is vague, that is a warning sign.
What connectors and interoperability standards are supported?
You need broad coverage across your modern data stack. Connector depth matters as much as connector count.
How is accuracy measured and improved?
Look for a clear process for confidence scoring, steward review, feedback loops, and retraining or rule adjustment.
A practical rollout approach
The best implementations start narrow, prove value, and then expand with governance discipline.
1. Start with high-value domains
Choose a domain where discovery pain is high and ownership is clear, such as customer analytics, finance reporting, or supply chain data.
2. Define success metrics upfront
Track KPIs such as search success, documentation completeness, lineage coverage, certified asset usage, and time to discovery.
3. Establish stewardship early
AI can accelerate metadata work, but stewardship is what makes the system trustworthy. Assign owners, approvers, and escalation paths from day one.
4. Build feedback loops into user workflows
Allow users to flag broken descriptions, wrong classifications, missing lineage, or unclear definitions. Those corrections are how the ai data catalog gets better over time.
5. Compare against both legacy catalogs and chatbot-only tools
Do not evaluate AI in isolation. Test real user tasks: finding a trusted dataset, tracing a dashboard metric to source, identifying sensitive columns, or locating the right owner for a broken report.
Best practices for implementing an AI data catalog
Based on enterprise rollout patterns, these practices consistently produce stronger adoption and better governance outcomes.
1. Prioritize governed use cases before broad rollout
Start with use cases where trust matters: regulated reporting, executive dashboards, customer data, or cross-functional KPIs. This creates visible business value and avoids turning the catalog into a side project.
2. Treat metadata as a product, not an afterthought
Define ownership, freshness expectations, review policies, and escalation workflows for metadata itself. If metadata quality is unmanaged, AI performance will degrade quickly.
3. Use AI for acceleration, not unchecked automation
Auto-generate descriptions, classifications, and glossary matches, but route high-impact or sensitive changes through human review. This keeps velocity high without sacrificing accountability.
4. Integrate discovery with analytics consumption
Make sure the catalog connects naturally to BI workflows, dashboard usage, and business-facing data experiences. This is where products like FineBI and conversational layers such as FineChatBI can complement catalog strategy by making trusted data easier to consume once it has been properly governed and contextualized.
5. Build an adoption program, not just a technical deployment
Train analysts, stewards, engineers, and business users differently. Each role uses the ai data catalog in a different way. Adoption rises when the experience is role-specific and tied to daily work.
Final takeaway
An ai data catalog is not just a nicer search experience and not just a chatbot overlay. It is a governed, interoperable, intelligence-driven metadata system that helps enterprises discover data faster, understand it more clearly, and trust it more consistently.
For decision-makers, the evaluation standard should be simple: does the platform improve the underlying metadata foundation, support governance at scale, and deliver grounded answers that users can trust? If the answer is yes, the business case is strong. If the product only adds conversational polish to weak metadata, it will not solve the core problem.
The enterprises that get this right will reduce data friction, strengthen governance, and accelerate insight across the organization.
An AI data catalog is a governed system that collects metadata from across your data stack and uses AI to make data easier to find, understand, and trust. It helps users see what data exists, what it means, who owns it, and whether it is safe to use.
A chatbot mainly provides a conversational interface, while an AI data catalog improves the underlying metadata, lineage, classification, and governance that power reliable answers. Without that foundation, a chatbot may return incomplete or outdated results.
It strengthens governance by identifying sensitive data, tracking lineage, assigning ownership, and surfacing certifications, freshness, and quality signals. This makes it easier to enforce policies and reduce risky or noncompliant data use.
Key features include broad metadata ingestion, automated tagging and classification, lineage mapping, natural language search, glossary support, ownership tracking, and governance controls. The best tools combine discovery and trust signals in one place.
IT managers, data leaders, analysts, engineers, and governance teams all benefit because they spend less time searching for data and resolving conflicting definitions. Business users also gain faster access to trusted, well-documented datasets and metrics.
Product Trial
FineReport
Pixel-perfect reports · Interactive dashboards · Easy data entry · Digital twins